互联网文本实体识别方法、系统、电子设备及存储介质与流程
1.本发明涉及文本数据处理领域,具体涉及到一种互联网文本实体识别方法、系统、电子设备及存储介质。
背景技术:
2.实体识别是文本序列标注型任务中一个很重要的部分,其中文全称为“命名实体识别”,英文名称为“ner”,主要目的是实现文本中人名、组织名、专有名次、地名、作品名等信息的识别与提取。
3.随着互联网的发展,互联网承载的文本数据也日益剧增,实体识别在越来越多的场景中需求日益迫切。对实体识别模型的识别效果和运算性能都提出更好更快的要求。
4.目前业内对实体识别的普遍做法是通过人工对文本进行海量的标注,然后以标注语料为依托,使用bert/bilstm/textcnn等神经网络模型与crf算法相结合实现ner模型,使用模型对需要ner识别的文本进行识别和结果输出。
5.业界的普遍做法不但需要在起初使用大量的人力标注大量的文本,而且在模型初步使用后还需要持续投入人力进行badcase跟进记录和重新标注;在实际项目持续投入的人力成本过高。使用的模型基本都是神经网络和crf算法的结合,所以在运行中普遍对运行环境要求较高,需要高性能gpu运行环境,在互联网每日产生文本数据海量的情况下,模型需要大量的高性能服务器来满足处理性能的要求,运行所需的服务器成本过高。
技术实现要素:
6.有鉴于此,本发明实施例提供了一种互联网文本实体识别方法、系统、电子设备及存储介质,以以解决现有技术中实体识别运行成本过高的问题。
7.为此,本发明实施例提供了如下技术方案:
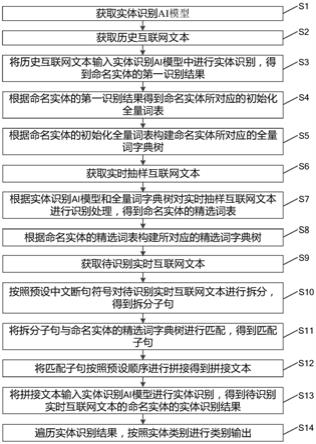
8.根据第一方面,本发明实施例提供了一种互联网文本实体识别方法,包括:获取实体识别ai模型;获取历史互联网文本;将所述历史互联网文本输入所述实体识别ai模型中进行实体识别,得到命名实体的第一识别结果;根据命名实体的第一识别结果得到命名实体所对应的初始化全量词表;根据命名实体的初始化全量词表构建命名实体所对应的全量词字典树;获取实时抽样互联网文本;根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表;根据命名实体的精选词表构建所对应的精选词字典树;获取待识别实时互联网文本;按照预设中文断句符号对所述待识别实时互联网文本进行拆分,得到拆分子句;将所述拆分子句与命名实体的精选词字典树进行匹配,得到所述匹配子句;将所述匹配子句按照预设顺序进行拼接得到拼接文本;将所述拼接文本输入所述实体识别ai模型进行实体识别,得到待识别实时互联网文本的命名实体的实体识别结果;遍历所述实体识别结果,按照实体类别进行类别输出。
9.可选地,根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表的步骤中,包括:步骤s71:按照预设迭代数量对实时抽样互联
网文本进行迭代拆分,得到当前迭代实时抽样互联网文本;步骤s72:将所述当前迭代实时抽样互联网文本输入所述实体识别ai模型中进行实体识别,得到当前迭代的命名实体的第二识别结果;步骤s73:将所述当前迭代实时抽样互联网文本与命名实体的全量词字典树进行匹配,得到当前迭代的命名实体的实体抽样匹配结果;步骤s74:对当前迭代的命名实体的第二识别结果和所对应的实体抽样匹配结果进行处理得到当前迭代精选词;步骤s75:将当前迭代精选词存储至命名实体的精选词表中,并返回步骤s71。
10.可选地,步骤s74:对当前迭代的命名实体的第二识别结果和所对应的实体抽样匹配结果进行处理得到当前迭代精选词的步骤中,包括:对当前迭代的命名实体的第二识别结果和实体抽样匹配结果进行处理得到命名实体中每一个实体的共现度计算值和类tf
‑
idf值;根据每一个实体的共现度计算值和类tf
‑
idf值对第二识别结果进行筛选,得到命名实体的当前迭代精选词。
11.可选地,根据每一个实体的共现度计算值和类tf
‑
idf值对第二识别结果进行筛选,得到命名实体的当前迭代精选词的步骤中,包括:判断当前实体的共现度计算值是否大于预设共现度或者类tf
‑
idf值是否大于预设tf
‑
idf值;若共现度计算值小于或者等于预设共现度或者类tf
‑
idf值小于或者等于预设tf
‑
idf值,则去除第二识别结果中的当前实体;若共现度计算值大于预设共现度或者类tf
‑
idf值大于预设tf
‑
idf值,则保留第二识别结果中的当前实体;将第二识别结果中所有保留下来的实体作为命名实体的当前迭代精选词。
12.可选地,步骤s73:将所述当前迭代实时抽样互联网文本与命名实体的全量词字典树进行匹配,得到当前迭代的命名实体的实体抽样匹配结果的步骤之后,还包括:步骤s76:将当前迭代的命名实体的第二识别结果逐条与所对应的初始化全量词表进行对比,找到第二识别结果中与初始化全量词表不匹配的实体词;步骤s77:将所述不匹配的实体词添加至对应的初始化全量词表中。
13.可选地,获取实体识别ai模型的步骤中,包括:获取标注文本,并将所述标注文本作为训练集;采用bilstm+crf的神经网络结构对所述训练集进行训练,得到实体识别ai模型。
14.可选地,根据命名实体的第一识别结果得到命名实体所对应的初始化全量词表的步骤中,包括:对命名实体的第一识别结果进行长尾错误识别,得到命名实体所对应的长尾识别错误;对长尾识别错误进行去重处理,得到命名实体所对应的初始化全量词表。
15.根据第二方面,本发明实施例提供了一种互联网文本实体识别系统,包括:第一获取模块,用于获取实体识别ai模型;第二获取模块,用于获取历史互联网文本;第一处理模块,用于将所述历史互联网文本输入所述实体识别ai模型中进行实体识别,得到命名实体的第一识别结果;第二处理模块,用于根据命名实体的第一识别结果得到命名实体所对应的初始化全量词表;第三处理模块,用于根据命名实体的初始化全量词表构建命名实体所对应的全量词字典树;第三获取模块,用于获取实时抽样互联网文本;第四处理模块,用于根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表;第五处理模块,用于根据命名实体的精选词表构建所对应的精选词字典树;第四获取模块,用于获取待识别实时互联网文本;第六处理模块,用于按照预设中文断句符号对所述待识别实时互联网文本进行拆分,得到拆分子句;第七处理模块,用于将所述拆分子句与命名实体的精选词字典树进行匹配,得到所述匹配子句;第八处理模块,用于将所述匹
配子句按照预设顺序进行拼接得到拼接文本;第九处理模块,用于将所述拼接文本输入所述实体识别ai模型进行实体识别,得到待识别实时互联网文本的命名实体的实体识别结果;第十处理模块,用于遍历所述实体识别结果,按照实体类别进行类别输出。
16.可选地,所述第四处理模块包括:第一处理子模块,用于按照预设迭代数量对实时抽样互联网文本进行迭代拆分,得到当前迭代实时抽样互联网文本;第二处理子模块,用于将所述当前迭代实时抽样互联网文本输入所述实体识别ai模型中进行实体识别,得到当前迭代的命名实体的第二识别结果;第三处理子模块,用于将所述当前迭代实时抽样互联网文本与命名实体的全量词字典树进行匹配,得到当前迭代的命名实体的实体抽样匹配结果;第四处理子模块,用于对当前迭代的命名实体的第二识别结果和所对应的实体抽样匹配结果进行处理得到当前迭代精选词;第五处理子模块,用于将当前迭代精选词存储至命名实体的精选词表中,并返回第一处理子模块。
17.可选地,所述第四处理子模块包括:第一处理单元,用于对当前迭代的命名实体的第二识别结果和实体抽样匹配结果进行处理得到命名实体中每一个实体的共现度计算值和类tf
‑
idf值;第二处理单元,用于根据每一个实体的共现度计算值和类tf
‑
idf值对第二识别结果进行筛选,得到命名实体的当前迭代精选词。
18.可选地,所述第二处理单元包括:判断子单元,用于判断当前实体的共现度计算值是否大于预设共现度或者类tf
‑
idf值是否大于预设tf
‑
idf值;第一处理子单元,用于若共现度计算值小于或者等于预设共现度或者类tf
‑
idf值小于或者等于预设tf
‑
idf值,则去除第二识别结果中的当前实体;第二处理子单元,用于若共现度计算值大于预设共现度或者类tf
‑
idf值大于预设tf
‑
idf值,则保留第二识别结果中的当前实体;第三处理子单元,用于将第二识别结果中所有保留下来的实体作为命名实体的当前迭代精选词。
19.可选地,还包括:第六处理子模块,用于将当前迭代的命名实体的第二识别结果逐条与所对应的初始化全量词表进行对比,找到第二识别结果中与初始化全量词表不匹配的实体词;第七处理子模块,用于将所述不匹配的实体词添加至对应的初始化全量词表中。
20.可选地,所述第一获取模块包括:获取子模块,用于获取标注文本,并将所述标注文本作为训练集;第八处理子模块,用于采用bilstm+crf的神经网络结构对所述训练集进行训练,得到实体识别ai模型。
21.可选地,所述第二处理模块包括:第九处理子模块,用于对命名实体的第一识别结果进行长尾错误识别,得到命名实体所对应的长尾识别错误;第十处理子模块,用于对长尾识别错误进行去重处理,得到命名实体所对应的初始化全量词表。
22.根据第三方面,本发明实施例提供了一种电子设备,包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的计算机程序,计算机程序被至少一个处理器执行,以使至少一个处理器执行上述第一方面任意一项描述的互联网文本实体识别方法。
23.根据第四方面,本发明实施例提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机指令,计算机指令用于使计算机执行上述第一方面任意一项描述的互联网文本实体识别方法。
24.本发明实施例技术方案,具有如下优点:
25.本发明实施例提供了一种互联网文本实体识别方法、系统、电子设备及存储介质,
其中,该方法包括:获取实体识别ai模型;获取历史互联网文本;将所述历史互联网文本输入所述实体识别ai模型中进行实体识别,得到命名实体的第一识别结果;根据命名实体的第一识别结果得到命名实体所对应的初始化全量词表;根据命名实体的初始化全量词表构建命名实体所对应的全量词字典树;获取实时抽样互联网文本;根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表;根据命名实体的精选词表构建所对应的精选词字典树;获取待识别实时互联网文本;按照预设中文断句符号对所述待识别实时互联网文本进行拆分,得到拆分子句;将所述拆分子句与命名实体的精选词字典树进行匹配,得到所述匹配子句;将所述匹配子句按照预设顺序进行拼接得到拼接文本;将所述拼接文本输入所述实体识别ai模型进行实体识别,得到待识别实时互联网文本的命名实体的实体识别结果;遍历所述实体识别结果,按照实体类别进行类别输出。上述步骤,将历史互联网数据输入实体识别ai模型中得到初始化全量词表;然后,将实时抽样互联网文本输入到实体识别ai模型中进行实体识别,同时将实时抽样互联网文本与初始化全量词表进行字典树匹配,将上述两种方式得到的结果进行比较得到精选词表,通过实时抽样互联网文本不断精选更多的词;之后,根据精选词表将拆成子句后的待识别实时互联网文本进行逐句筛选,只留下可能含有实体的句子,从而大幅度降低需要计算的文本量,达到降低计算成本提高计算速度的目的。同时由于精选词表和根据精选词表查询过滤这两步减少了大量的噪音文本和垃圾文本,使得最终送入模型的文本干净且上下文清晰,相比于将文本直接送入模型正确率和召回都有较大提升。
附图说明
26.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
27.图1为本发明实施例的互联网文本实体识别方法的一个具体示例的流程图;
28.图2为本发明实施例的互联网文本实体识别方法的另一个具体示例的流程图;
29.图3为本发明实施例的互联网文本实体识别方法的另一个具体示例的流程图;
30.图4为本发明实施例的互联网文本实体识别系统的一个具体示例的框图;
31.图5为本发明实施例的电子设备的示意图。
具体实施方式
32.下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
33.目前业内对实体识别的普遍做法是通过人工对文本进行海量的标注,然后以标注语料为依托,使用bert/bilstm/textcnn等神经和网络模型与crf算法相结合实现ner模型,使用模型对需要ner识别的文本进行识别和结果输出。
34.现有技术中的实体识别方法存在以下问题。
35.(1)人工成本过高
36.业界的普遍做法不但需要在起初使用大量的人力标注大量的文本,而且在模型初步使用后还需要持续投入人力进行badcase跟进记录和重新标注。在实际项目持续投入的人力成本过高。
37.(2)迭代成本过高
38.业界的普遍做法在项目上线后,会定期针对积累的badcase进行进行模型的迭代训练,由于badcase基本都是长尾错误,所以模型的迭代不能确保快速高效并且100%的解决badcase。这其中要消耗大量的人力物力来完成对badcase的纠错。每次迭代的成本过高
39.(3)模型优化缓慢
40.业界的普遍做法在模型持续优化过程中,依靠badcase积累和模型针对badcase迭代训练在优化模型的识别效果。但是由于badcase的积累缓慢和badcase存在长尾效应会导致优化过程中优化缓慢。现实项目中可能经过半年的迭代模型识别效果从95.1%提升到了95.4%。
41.(4)运行环境要求高,运行成本过高
42.业界的普遍做法中使用的模型基本都是神经网络和crf算法的结合,所以在运行中普遍对运行环境要求较高,需要高性能gpu运行环境,在互联网每日产生文本数据海量的情况下,模型需要大量的高性能服务器来满足处理性能的要求,运行所需的服务器成本过高。
43.鉴于上述问题,本实施例中提供了一个占用人工成本较少、迭代成本低、运行badcase容易迭代纠正且正确率和召回率优化快、运行环境要求低运行速度快的ner识别方法。
44.本发明实施例提供了一种互联网文本实体识别方法,如图1所示,该方法包括步骤s1
‑
s14。
45.步骤s1:获取实体识别ai模型。
46.作为示例性的实施例,利用一定数量的标注后文本,具体数量可以是30万条,采用bilstm+crf的神经网络结构进行训练,得到实体识别的ai模型,该模型可以有效的识别出文本中人名、组织名、专有名次、地名、作品名等信息。本实施例对实体识别ai模型仅作示意性说明,并不以此为限,在其它实施例中,也可以是其它实体识别模型,如hmm、crf或者bilstm等,根据需要合理设置即可。
47.步骤s2:获取历史互联网文本。
48.作为示例性的实施例,抽取20亿条历史互联网文本数据,历史互联网文本的数量可根据实际需要合理设置,本实施例对此仅作示意性说明。
49.步骤s3:将历史互联网文本输入实体识别ai模型中进行实体识别,得到命名实体的第一识别结果。
50.作为示例性的实施例,抽取20亿条的历史互联网文本数据,然后利用上一步的实体识别ai模型对这20亿数据进行人名/组织名/专名/作品名等实体进行识别,得到第一识别结果。
51.具体地,第一识别结果包括的是对20亿文本进行识别后的,在不关心识别结果是否正确的情况下对所有结果在人名/组织名/专名/作品名属性下分别进行去重得到各自的第一识别结果。
52.实体识别ai模型可以对多种类型的实体进行识别,如人名、作品名、组织名、地址名等,故第一识别结果为包含各种类别的命名实体的识别结果,如包括人名第一识别结果、作品名第一识别结果、组织名第一识别结果、地址名第一识别结果,每一种类别的实体对应一个实体识别结果。
53.步骤s4:根据命名实体的第一识别结果得到命名实体所对应的初始化全量词表。
54.作为示例性的实施例,命名实体的识别结果中会因为模型的长尾识别错误,对各种实体分别进行去重后各个实体词表会出现大量错误结果,把这种含有大量错误识别结果的词表叫做全量词表。长尾识别错误指的是,ai模型识别时,在大数据场景下会有丰富多样的识别错误情况。造成总的全量词表在去重后大部分是识别错误的错误实体词。例如张三丰出现了100次都识别正确了,但是骂银行、李四等、鍏充簬闱掑矝楂等等这些偶尔出现一次但是会错误识别为人名的情况。最终词表中会是:
55.张三丰
56.骂银行
57.李四等
58.鍏充簬闱掑矝楂
59.一个正确实体词,三个错误实体词。把这种现象叫做长尾识别错误。
60.本实施例中,将第一识别结果中包含大量错误识别结果的词表称为初始化全量词表。初始化全量词表中包含多种类别的全量词表,如人名初始化全量词表、作品名初始化全量词表、组织名初始化全量词表等。
61.具体地,根据相应类别的第一识别结果得到对应类别的初始化全量词表,如根据人名第一识别结果得到人名初始化全量词表;根据作品名第一识别结果得到作品名初始化全量词表;根据组织名第一识别结果得到组织名初始化全量词表。
62.步骤s5:根据命名实体的初始化全量词表构建命名实体所对应的全量词字典树。
63.作为示例性的实施例,根据命名实体的不同类别的初始化全量词表构建相应类别的全量词字典树。具体地,全量词字典树包括多种命名实体类别的字典树,如人名全量词字典树、作品名全量词字典树、组织名全量词字典树等。本实施例中,根据相应类别的初始化全量词表得到对应类别的全量词字典树,如根据人名初始化全量词表得到人名全量词字典树;根据作品名初始化全量词表得到作品名全量词字典树;根据组织名初始化全量词表得到组织名全量词字典树等。
64.步骤s6:获取实时抽样互联网文本。
65.作为示例性的实施例,实时抽样互联网文本为每日随机抽取预设抽样数量的文本数据,如从大量当天互联网文本数据(如3亿条以上)中随机抽取2000万条数据作为实时抽样互联网文本,本实施例对此仅作示意性描述,不以此为限。
66.步骤s7:根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表。
67.作为示例性的实施例,将实时抽样互联网文本输入到实体识别ai模型中得到该模型识别出的实体的识别结果。将实时抽样互联网文本与全量词字典树进行匹配查询,得到实时抽样互联网文本的匹配结果。根据上述两种方式识别出的结果进行共现度计算和类tf
‑
idf计算,得到共现度和类tf
‑
idf值,然后,根据上面两个数值对识别出的实体词进行筛
选,保留类tf
‑
idf值大于3.25或者人名共现度在0.7以上的实体词,将保留下来的实体词作为命名实体的精选词表,留待线上拉取时使用。
68.具体地,精选词表包括多种实体类别所对应的词表,如人名实体类别对应人名精选词表、作品名实体类别对应作品名精选词表、组织名实体类别对应组织名精选词表等。
69.步骤s8:根据命名实体的精选词表构建所对应的精选词字典树。
70.作为示例性的实施例,根据命名实体的不同类别的精选词表构建相应类别的精选词字典树。具体地,精选词字典树包括多种命名实体类别的字典树,如人名精选词字典树、作品名精选词字典树、组织名精选词字典树等。本实施例中,根据相应类别的精选词表得到对应类别的精选词字典树,如根据人名精选词表得到人名精选词字典树;根据作品名精选词表得到作品名精选词字典树;根据组织名精选词表得到组织名精选词字典树等。
71.步骤s9:获取待识别实时互联网文本。
72.作为示例性的实施例,待识别实时互联网文本为当天所有的互联网文本数据。
73.步骤s10:按照预设中文断句符号对待识别实时互联网文本进行拆分,得到拆分子句。
74.作为示例性的实施例,首先将需要识别的每一篇文本按照预设中文断句符号,拆成一个个小子句,这些被拆分成的一个个小字句组成拆分子句。预设中文断句符号可以是逗号(,)、句号(。)、疑问号(?)、感叹号(!)等;本实施例对中文断句符号仅作示意性说明,不以此为限。
75.具体的,中文断句符号拆分成小子句的一个具体示例如下。
76.在收到央视记者送出的鲜花时,某某发出了灵魂“拷问”:就一朵吗?说完自己也笑了起来。最后,外交天团的“男神”们也送上了节日祝福“彩蛋”。
77.拆分后文本:
78.在收到央视记者送出的鲜花时
79.某某发出了灵魂“拷问”80.就一朵吗
81.说完自己也笑了起来
82.最后
83.外交天团的“男神”们也送上了节日祝福“彩蛋”84.步骤s11:将拆分子句与命名实体的精选词字典树进行匹配,得到所述匹配子句。
85.作为示例性的实施例,将拆分子句与命名实体的精选词字典树进行匹配查询,将有匹配结果的子句子保留下来,有匹配结果指的是子句子中包含有精选词字典树中的精选词,将这些保留下来的子句子作为匹配字句。
86.步骤s12:将匹配子句按照预设顺序进行拼接得到拼接文本。
87.作为示例性的实施例,预设顺序为子句子在原文本中的先后顺序。将匹配子句按照原文本中的前后顺序拼接在一起。
88.例如,原句由【第一句,第二句,第三句,第四句】顺序组成,这个时候经过匹配查询,第一句和第三句留下来了,那么留下来的拼接结果就是【第一句,第三句】。
89.步骤s13:将拼接文本输入实体识别ai模型进行实体识别,得到待识别实时互联网文本的命名实体的实体识别结果。
90.作为示例性的实施例,将拼接文本输入实体识别ai模型进行实体识别,得到识别结果。
91.步骤s14:遍历所述实体识别结果,按照实体类别进行类别输出。
92.作为示例性的实施例,遍历最终的实体识别结果,按照实体类别逐类别输出。
93.上述步骤,将历史互联网数据输入实体识别ai模型中得到初始化全量词表;然后,将实时抽样互联网文本输入到实体识别ai模型中进行实体识别,同时将实时抽样互联网文本与初始化全量词表进行字典树匹配,将上述两种方式得到的结果进行比较得到精选词表,通过实时抽样互联网文本不断精选更多的词;之后,根据精选词表将拆成子句后的待识别实时互联网文本进行逐句筛选,只留下可能含有实体的句子,从而大幅度降低需要计算的文本量,达到降低计算成本提高计算速度的目的。同时由于精选词表和根据精选词表查询过滤这两步减少了大量的噪音文本和垃圾文本,使得最终送入模型的文本干净且上下文清晰,相比于将文本直接送入模型正确率和召回都有较大提升。
94.作为示例性的实施例,步骤s7根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表的步骤中,包括步骤s71
‑
s75。
95.步骤s71:按照预设迭代数量对实时抽样互联网文本进行迭代拆分,得到当前迭代实时抽样互联网文本。
96.本实施例中,实时抽样互联网文本为每日随机抽取2000万条文本数据,预设迭代数量设置为100万,则每100万条数据进行一次迭代。例如,2000万条文本数据按照100万条进行一次迭代,则需要拆分为20次。本实施例中的预设迭代数量仅作示意性说明,不以此为限,在实际应用中,根据实际数据合理设置即可。
97.步骤s72:将当前迭代实时抽样互联网文本输入实体识别ai模型中进行实体识别,得到当前迭代的命名实体的第二识别结果。
98.本实施例中,将当前迭代实时抽样互联网文本输入实体识别ai模型中,输出当前迭代实时抽样互联网文本的识别结果,将上述识别结果作为当前迭代的命名实体的第二识别结果。
99.步骤s73:将当前迭代实时抽样互联网文本与命名实体的全量词字典树进行匹配,得到当前迭代的命名实体的实体抽样匹配结果。
100.本实施例中,将当前迭代实时抽样互联网文本与由全量词表构建的字典树进行匹配查询,分别记录匹配结果,上述匹配结果则为当前迭代的命名实体的实体抽样匹配结果。
101.步骤s74:对当前迭代的命名实体的第二识别结果和所对应的实体抽样匹配结果进行处理得到当前迭代精选词。
102.本实施例中,步骤s704具体包括步骤s741
‑
s742。
103.步骤s741:对当前迭代的命名实体的第二识别结果和实体抽样匹配结果进行处理得到命名实体中每一个实体的共现度计算值和类tf
‑
idf值。
104.具体地,利用第二识别结果和实体抽样匹配结果进行共现度计算,具体计算公式:
105.实体在第二识别结果中出现的次数/实体在实体抽样匹配结果中出现的次数。
106.例如,人名实体“张三”在第二识别结果中出现3次,在实体抽样匹配结果中出现4次,那么张三这个词的共现度为3/4,即0.75。
107.类tf
‑
idf是结合tf
‑
idf算法的原理专门为本方法中的自动化筛选实体词场景而
设计的tf
‑
idf变型体。具体计算公式为:
108.tf=共现度(某个实体词);
109.count=ai识别出的实体词的文本数量;
110.df=ai识别出某个实体词文本数。
111.类tf
‑
idf=tf*ln[count/(df+1)]
[0112]
例如:
[0113]
本轮迭代中实体抽样匹配结果不为空的文本共计有100条,张三在第二识别结果中出现3次,在实体抽样匹配结果中出现4次。
[0114]
首先利用张三这个词共现度作为张三这个词的tf值,故tf值为0.75,然后idf=ln[100/(4+1)],最终类tf
‑
idf计算结果为2.247。
[0115]
步骤s742:根据每一个实体的共现度计算值和类tf
‑
idf值对第二识别结果进行筛选,得到命名实体的当前迭代精选词。
[0116]
具体地,步骤s742包括步骤s7421
‑
s7424。
[0117]
步骤s7421:判断当前实体的共现度计算值是否大于预设共现度或者类tf
‑
idf值是否大于预设tf
‑
idf值。
[0118]
具体地,若当前实体的共现度计算值不大于预设共现度或者类tf
‑
idf值不大于预设tf
‑
idf值,则执行步骤s7422;若当前实体的共现度计算值大于预设共现度或者类tf
‑
idf值大于预设tf
‑
idf值,则执行步骤s7423。
[0119]
本实施例中,预设共现度设置为0.7,预设tf
‑
idf值设置为3.25。
[0120]
本实施例中,对上述预设值仅作示意性描述,不以此为限制,在其它实施例中,可根据实际需要合理设置预设共现度和预设tf
‑
idf值的具体数值。
[0121]
步骤s7422:若共现度计算值小于或者等于预设共现度或者类tf
‑
idf值小于或者等于预设tf
‑
idf值,则去除第二识别结果中的当前实体。
[0122]
具体地,共现度计算值小于或者等于预设共现度则说明这个词出现在文本内容中时是实体词的概率小;类tf
‑
idf值小于或者等于预设tf
‑
idf值则说明该词在实体词中的重要度很低。当满足上述条件时说明该词不适合作为精选词。
[0123]
步骤s743:若共现度计算值大于预设共现度或者类tf
‑
idf值大于预设tf
‑
idf值,则保留第二识别结果中的当前实体。
[0124]
具体地,共现度计算值大于预设共现度,则说明这个词出现在文本内容中时是实体词的概率大;类tf
‑
idf值大于等于预设tf
‑
idf值则说明该词在实体词中的重要度高。当满足上述任意一个条件时说明该词适合作为精选词。
[0125]
步骤s744:将第二识别结果中所有保留下来的实体作为命名实体的当前迭代精选词。
[0126]
具体地,将类tf
‑
idf值大于3.25或者人名共现度在0.7以上的实体词留下来,补充进该类别实体的精选后词表中,留待线上拉取时使用。
[0127]
步骤s75:将当前迭代精选词存储至命名实体的精选词表中,并返回步骤s71。
[0128]
本实施例中,将当前迭代精选词存储至命名实体的精选词表中,进行精选词表的更新,本次迭代完成,返回步骤s71进行下一次迭代。
[0129]
上述步骤,通过迭代实现了精准词表的优化和扩充。
[0130]
作为示例性的实施例,步骤s73将当前迭代实时抽样互联网文本与命名实体的全量词字典树进行匹配,得到当前迭代的命名实体的实体抽样匹配结果的步骤之后,还包括步骤s76
‑
s77。
[0131]
步骤s76:将当前迭代的命名实体的第二识别结果逐条与所对应的初始化全量词表进行对比,找到第二识别结果中与初始化全量词表不匹配的实体词。
[0132]
具体地,将各种实体的实体识别ai模型结果逐条与各自全量词表对比,如果不在全量词表中,则记录下来。
[0133]
步骤s77:将不匹配的实体词添加至对应的初始化全量词表中。
[0134]
具体地,在下次迭代开始之前,将不匹配的实体词补充到各自的全量词表中,对全量词表进行更新。
[0135]
通过上述步骤实现了全量词表的补充。
[0136]
作为示例性的实施例,步骤s1获取实体识别ai模型的步骤中,包括步骤s11
‑
s12。
[0137]
步骤s11:获取标注文本,并将所述标注文本作为训练集。
[0138]
具体地,标注文本为30万条标注后的文本数据。当然,在其它实施例中,标注文本的数量还可以根据实际需要合理设置;本实施例对此仅作示意性描述,不以此为限。
[0139]
步骤s12:采用bilstm+crf的神经网络结构对所述训练集进行训练,得到实体识别ai模型。
[0140]
具体地,利用30万条进行标注后文本,采用bilstm+crf的神经网络结构训练用于实体识别的ai模型,该模型可以有效的识别出文本中人名、组织名、专有名次、地名、作品名等信息。本实施例对实体识别ai模型仅作示意性描述,不以此为限。在其它实施例中,具体的实体识别ai模型还可以是其它模型,实体识别ai模型可以识别的实体类别可根据实际需要合理设置。
[0141]
下面简要描述本实施例中的整体过程,如图2和图3所示,图2为线下基于大数据文本进行自动化获取各种实体全量词表,图3为线上基于线下提供的各种实体全量词表对文本进行句子级别的筛选,压缩实体识别需要计算的文本量。
[0142]
本方法由线下和线上两部分组成:线下基于大数据文本进行自动化获取各种实体全量词表;线上基于线下提供的各种实体全量词表对文本进行句子级别的筛选,压缩实体识别需要计算的文本量。
[0143]
1.线下
‑
构建bilstm+crf的实体识别ai模型
[0144]
利用30万条进行标注后文本,采用bilstm+crf的神经网络结构训练用于实体识别的ai模型,该模型可以有效的识别出文本中人名、组织名、专有名次、地名、作品名等信息
[0145]
2.线下
‑
构建初始的全量人名/组织名/专名/作品名等全量词表
[0146]
抽取20亿条的历史互联网文本数据,然后利用上一步的实体识别ai模型对这20亿数据进行人名/组织名/专名/作品名等实体进行识别,识别结果中会因为模型的长尾识别错误,对各种实体分别进行去重后各个实体词表会出现大量错误结果。把这种含有大量错误识别结果的词表叫做全量词表。
[0147]
3.线下
‑
迭代补充全量词表并优化扩充精准词表。
[0148]
迭代过程:
[0149]
首先将一条当天实时互联网文本利用实体识别ai模型进行人名/组织名/专名/作
品名等实体的识别,并分别记录识别结果,计作结果1。然后将这条文本利用人名/组织名/专名/作品名的全量词表构建的字典树进行匹配查询,并分别记录匹配结果,计作结果2。
[0150]
然后每记录100万条结果,进行一次汇总计算,汇总计算主要有三个功能:
[0151]
i.将各种实体的实体识别ai模型结果(无论)逐条与各自全量词表对比,如果不在全量词表中,则记录下来,在下次迭代开始之前补充到各自的全量词表中
[0152]
ii.利用结果1和结果2进行共现度计算,举例说明:
[0153]
张三在结果1种出现3次在结果2中出现4次,那么张三这词的共现度为3/4,即0.75。
[0154]
iii.利用结果1和结果2进行类tf
‑
idf计算,类tf
‑
idf是结合tf
‑
idf算法的原理专门为本专利中的自动化筛选实体词场景而设计的tf
‑
idf变型体。
[0155]
类tf
‑
idf的计算举例说明:
[0156]
本轮迭代中结果2不为空的文本共计有100条,张三在结果1种出现3次在结果2中出现4次。
[0157]
首先利用步奏ii中的张三这个词共现度作为张三这个词的tf为0.75,然后idf=log[100/(4+1)],最终类tf
‑
idf计算结果为2.247。
[0158]
4.线下
‑
每次迭代中如何筛选精准词表。
[0159]
将类tf
‑
idf值大于3.25或者人名共现度在0.7以上的实体词留下来,补充进该类别实体的精选后词表中,留待线上拉取是使用。
[0160]
5.线上
‑
文本过滤压缩及实体识别。
[0161]
首先将需要识别的每一篇文本按照中文断句符号,拆成一个个小子句。然后拉取线下计算好的各类实体精选后词表,构建多个字典树,然后进行匹配查询,将有匹配结果的子句子留下来,然后将这些留下来的子句按照顺序拼接在一起送入实体识别ai模型进行人名/组织名/专名/作品名等实体的识别。通过子句拆解和词表查询过滤后,需要处理的文本量在大数据统计下减少量为93%!
[0162]
6.输出
[0163]
遍历最终的实体识别结果,按照实体类别逐类别输出。
[0164]
本实施例中提供了一种具备自优化能力的极速实体识别算法与机制,该算法与机制可以实现线下线上线下协同合作,并切大幅度的消除人工和算力成本,具有下限自动优化协助线上,线上基于线下协助达到低成本快速计算识别的特点。
[0165]
它巧妙的将整个实体识别任务拆分成线上线下两个部分,其中线下部分:通过自动化迭代的流程设计,实现针对每种所需实体进行单独的自动化全量词表筛选。其中线上部分:借助线下提供的各种所需实体的最终词表,然后借助词表将拆成子句后的文本进行逐句筛选,只留下可能含有实体的句子,从而大幅度降低需要计算的文本量,达到降低计算成本提高计算速度的目的。
[0166]
同时由于线下精选词表和线上词表查询过滤这两步减少了大量的噪音文本和垃圾文本,使得最终送入模型的文本干净且上下文清晰,相比于将文本直接送入模型正确率和召回都有较大提升。
[0167]
本方法通过机制和算法的创新设计,提出一种具备自优化能力的极速实体识别算法与机制,并将其应用到需要实体识别的实际业务中去,使得实体识别算法可以快速,高效
并且具备自优化能力,极大减少人工成本和运行成本。
[0168]
在本实施例中还提供了一种互联网文本实体识别系统,该系统用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的系统较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
[0169]
本实施例还提供一种互联网文本实体识别系统,如图4所示,包括:
[0170]
第一获取模块1,用于获取实体识别ai模型;
[0171]
第二获取模块2,用于获取历史互联网文本;
[0172]
第一处理模块3,用于将所述历史互联网文本输入所述实体识别ai模型中进行实体识别,得到命名实体的第一识别结果;
[0173]
第二处理模块4,用于根据命名实体的第一识别结果得到命名实体所对应的初始化全量词表;
[0174]
第三处理模块5,用于根据命名实体的初始化全量词表构建命名实体所对应的全量词字典树;
[0175]
第三获取模块6,用于获取实时抽样互联网文本;
[0176]
第四处理模块7,用于根据实体识别ai模型和全量词字典树对实时抽样互联网文本进行识别处理,得到命名实体的精选词表;
[0177]
第五处理模块8,用于根据命名实体的精选词表构建所对应的精选词字典树;
[0178]
第四获取模块9,用于获取待识别实时互联网文本;
[0179]
第六处理模块10,用于按照预设中文断句符号对所述待识别实时互联网文本进行拆分,得到拆分子句;
[0180]
第七处理模块11,用于将所述拆分子句与命名实体的精选词字典树进行匹配,得到所述匹配子句;
[0181]
第八处理模块12,用于将所述匹配子句按照预设顺序进行拼接得到拼接文本;
[0182]
第九处理模块13,用于将所述拼接文本输入所述实体识别ai模型进行实体识别,得到待识别实时互联网文本的命名实体的实体识别结果;
[0183]
第十处理模块14,用于遍历所述实体识别结果,按照实体类别进行类别输出。
[0184]
可选地,所述第四处理模块包括:第一处理子模块,用于按照预设迭代数量对实时抽样互联网文本进行迭代拆分,得到当前迭代实时抽样互联网文本;第二处理子模块,用于将所述当前迭代实时抽样互联网文本输入所述实体识别ai模型中进行实体识别,得到当前迭代的命名实体的第二识别结果;第三处理子模块,用于将所述当前迭代实时抽样互联网文本与命名实体的全量词字典树进行匹配,得到当前迭代的命名实体的实体抽样匹配结果;第四处理子模块,用于对当前迭代的命名实体的第二识别结果和所对应的实体抽样匹配结果进行处理得到当前迭代精选词;第五处理子模块,用于将当前迭代精选词存储至命名实体的精选词表中,并返回第一处理子模块。
[0185]
可选地,所述第四处理子模块包括:第一处理单元,用于对当前迭代的命名实体的第二识别结果和实体抽样匹配结果进行处理得到命名实体中每一个实体的共现度计算值和类tf
‑
idf值;第二处理单元,用于根据每一个实体的共现度计算值和类tf
‑
idf值对第二识别结果进行筛选,得到命名实体的当前迭代精选词。
[0186]
可选地,所述第二处理单元包括:判断子单元,用于判断当前实体的共现度计算值是否大于预设共现度或者类tf
‑
idf值是否大于预设tf
‑
idf值;第一处理子单元,用于若共现度计算值小于或者等于预设共现度或者类tf
‑
idf值小于或者等于预设tf
‑
idf值,则去除第二识别结果中的当前实体;第二处理子单元,用于若共现度计算值大于预设共现度或者类tf
‑
idf值大于预设tf
‑
idf值,则保留第二识别结果中的当前实体;第三处理子单元,用于将第二识别结果中所有保留下来的实体作为命名实体的当前迭代精选词。
[0187]
可选地,还包括:第六处理子模块,用于将当前迭代的命名实体的第二识别结果逐条与所对应的初始化全量词表进行对比,找到第二识别结果中与初始化全量词表不匹配的实体词;第七处理子模块,用于将所述不匹配的实体词添加至对应的初始化全量词表中。
[0188]
可选地,所述第一获取模块包括:获取子模块,用于获取标注文本,并将所述标注文本作为训练集;第八处理子模块,用于采用bilstm+crf的神经网络结构对所述训练集进行训练,得到实体识别ai模型。
[0189]
可选地,所述第二处理模块包括:第九处理子模块,用于对命名实体的第一识别结果进行长尾错误识别,得到命名实体所对应的长尾识别错误;第十处理子模块,用于对长尾识别错误进行去重处理,得到命名实体所对应的初始化全量词表。
[0190]
本实施例中的互联网文本实体识别系统是以功能单元的形式来呈现,这里的单元是指asic电路,执行一个或多个软件或固定程序的处理器和存储器,和/或其他可以提供上述功能的器件。
[0191]
上述各个模块的更进一步的功能描述与上述对应实施例相同,在此不再赘述。
[0192]
本发明实施例还提供了一种电子设备,如图5所示,该电子设备包括一个或多个处理器71以及存储器72,图5中以一个处理器71为例。
[0193]
该控制器还可以包括:输入装置73和输出装置74。
[0194]
处理器71、存储器72、输入装置73和输出装置74可以通过总线或者其他方式连接,图5中以通过总线连接为例。
[0195]
处理器71可以为中央处理器(central processing unit,cpu)。处理器71还可以为其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field
‑
programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等芯片,或者上述各类芯片的组合。通用处理器可以是微处理器或者是任何常规的处理器等。
[0196]
存储器72作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序、非暂态计算机可执行程序以及模块,如本申请实施例中的互联网文本实体识别方法对应的程序指令/模块。处理器71通过运行存储在存储器72中的非暂态软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例的互联网文本实体识别方法。
[0197]
存储器72可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据服务器操作的处理装置的使用所创建的数据等。此外,存储器72可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施例中,存
储器72可选包括相对于处理器71远程设置的存储器,这些远程存储器可以通过网络连接至网络连接装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0198]
输入装置73可接收输入的数字或字符信息,以及产生与服务器的处理装置的用户设置以及功能控制有关的键信号输入。输出装置74可包括显示屏等显示设备。
[0199]
一个或者多个模块存储在存储器72中,当被一个或者多个处理器71执行时,执行如图1
‑
3所示的方法。
[0200]
本领域技术人员可以理解,实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指示相关的硬件来完成,被执行的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述互联网文本实体识别方法的实施例的流程。其中,存储介质可为磁碟、光盘、只读存储记忆体(read
‑
only memory,rom)、随机存储记忆体(random access memory,ram)、快闪存储器(flash memory)、硬盘(hard disk drive,缩写:hdd)或固态硬盘(solid
‑
state drive,ssd)等;存储介质还可以包括上述种类的存储器的组合。
[0201]
虽然结合附图描述了本发明的实施方式,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下作出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1