一种基于目标变换回归网络的精确目标跟踪方法
1.本发明属于计算机视觉技术领域,涉及单目标跟踪技术,具体为一种基于目标变换回归网络的精确目标跟踪方法。
背景技术:
2.作为计算机视觉中的基本任务,视觉物体跟踪旨在为视频中的一个任意一般物体估计它在每一帧中出现的空间位置并标出物体边框。大体上,目前的视觉物体跟踪可以被分为物体分类和边框回归两个子任务。
3.为了构建一个精确的跟踪器,边框回归的设计是至关重要的。当前的跟踪方法按照回归分支来进行分类的话主要可以分为两种:简洁的预测和直接回归。对于前一类,早前的相关滤波方法和孪生网络方法例如siamfc等主要采用了多尺度预测的方法来粗略的估计目标的尺度。接下来,atom方法提出了一个特别设计的iou预测网络来挑选出多个预选框中得分最高的并且进行微调,从而得到比较精确的框。对于第二类直接回归的方法,一系列siamese方法例如siamrpn、siamrpn++等采用了一种基于锚框的rpn(region proposal net)网络来直接回归预设的锚框。另外,近期的一些无锚框跟踪器通过一个简单的网络直接预测每个点的目标大小。无锚框跟踪器不仅简单直接,而且取得了不错的跟踪效果,因此逐渐称为目前比较流行的一种方法。然而,当前的这些无锚框方法例如siamfc++、ocean等依然不够精确,这是由于待跟踪的目标在后续帧中可能会发生形变等。
技术实现要素:
4.本发明要解决的问题是:在视频目标跟踪中,存在如何将视频第一帧中给定的目标信息整合到回归分支中,并保持其精确的边界信息并且及时地处理形变问题。现有跟踪器的回归分支用来承担回归出目标精确的边界框的任务,目前的一些无锚框的回归方法主要采用了逐通道的相关性表达来融合第一帧的目标特征信息,或者基于第一帧目标特征指导的注意力模块来调制回归分支的表达,尽管这些方法将第一帧的目标信息引入了回归分支,然而却没有保留足够充分的目标信息用于精确回归,也缺少了处理目标形变的机制。因此,本发明的设计目标就是将第一帧信息引入回归分支来指导目标框的回归,并且要保留充分的目标信息和处理目标形变的机制用于精确回归。
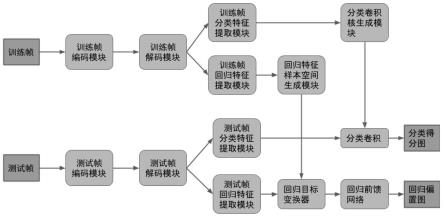
5.本发明的技术方案为:一种基于目标变换回归网络的精确目标跟踪方法,构建目标变换回归网络,包括分类分支和回归分支,训练网络时,分别提取训练帧和测试帧的分类特征和回归特征,由分类特征训练对目标特征的识别,由回归特征训练对目标框的的生成,输出的目标框即跟踪结果,其中对测试帧的回归特征先经一个回归目标变换器transformer增强特征后,再结合训练帧的回归特征训练对目标框的生成;训练好的网络用于在线跟踪,以待跟踪视频的第一帧的目标分类特征信息引入回归分支中,后续视频帧作为测试帧,经目标变换回归网络得到目标框用于跟踪。
6.作为进一步的改进,在跟踪过程中挑选出部分已经跟踪完的视频帧作为分类分支
的在线训练样本以及回归分支的在线更新样本,来更新分类分支和回归分支的网络参数。
7.作为优选方式,所述回归目标变换器transformer具体为:首先将测试帧的回归特征经过一个1*1卷积产生查询向量,同时将训练帧的回归特征经过两个1*1卷积分别产生键向量和值向量用作查询,将查询向量经过矩阵转置之后与键向量相乘,再用该相乘结果与值向量进行相乘得到增强特征,最后将测试帧的原始回归特征与增强特征相加,从而在保留初始信息的基础上使特征得到变换增强。
8.作为优选方式,所述跟踪方法包括生成训练样例阶段、网络配置阶段、离线训练阶段以及在线跟踪阶段:
9.3)生成训练样例阶段,在离线训练过程中生成训练样例,首先对离线训练数据集中每个视频的每一帧图像进行目标区域抖动处理,然后裁剪出抖动处理后的目标搜索区域,从每个视频帧序列的前半部分抽取三帧作为训练帧,从每个视频帧序列的后半部分抽取一帧作为测试帧,对测试帧标注目标框作为验证帧,对于每个验证帧生成一个以目标框的中心为中心的高斯标签图作为验证集的分类分支标签,并且记录下每帧验证帧中目标框的中心距离目标框的四个边界的距离,作为离线训练过程中回归分支的标签;
10.4)网络配置阶段,提取测试帧和训练帧的分类特征图和回归特征图,根据训练帧的分类特征图生成分类分支的可适应卷积核f
cls
,以可适应卷积核f
cls
作为分类卷积的卷积核,作用于测试帧的分类特征图,经过分类卷积操作之后产生分类得分置信图m
cls
;同时将训练帧的回归特征图作为指导回归分支的目标特征样本,测试帧的回归特征图经过一个回归目标变换器transformer后,回归产生中心点到目标边界距离回归偏置图m
reg
,用于表示目标的中心点距离物体的四个边界的距离,根据置信图m
cls
找到得分最高的点,然后在m
reg
中找出该点对应的四个偏置距离,即输出测试帧上目标的目标框;
11.3)离线训练阶段,对于分类分支的离线训练使用dimp提出的类合页损失lbhinge loss作为损失函数,对于回归分支使用iou损失函数,结合由验证帧得到的标签,使用sgd优化器,通过反向传播算法来更新整个网络参数,不断重复步骤2),直至达到迭代次数;
12.4)在线跟踪阶段,首先裁剪出待跟踪视频的第一帧图像中的目标框搜索区域作为模板,然后将模板帧扩充为一个包含30帧图像的在线训练数据集,作为训练帧f
train
,将待跟踪视频中后续待跟踪的帧作为测试帧f
test
,以f
train
输入步骤2)的网络,得到f
test
上的目标框,实现目标跟踪。
13.作为优选方式,步骤4)的跟踪过程中,从已经跟踪完的帧序列中每25帧挑选出一个分类得分最高的帧和已经跟踪得到的目标框作为标签添加到在线训练数据集中,用于更新分类分支的可适应卷积核f
cls
及回归分支的目标特征样本。
14.本发明与现有技术相比有如下优点。
15.本发明提出了一种基于目标变换回归网络的跟踪方法(target transformed regression tracker,treg)。这种方法采用了一种基于目标指导回归变换器的边框回归的简洁跟踪框架,在保证物体跟踪效率的同时提升了跟踪的准确度。
16.本发明设计了一种可在线更新的目标指导的回归变换器来将第一帧的目标信息融入测试帧的回归分支中,并且在边框回归中引入了在线更新的机制。相比现有的无锚框跟踪方法,本发明的跟踪方法能对跟踪过程中的物体变形有更好的适应能力,有效地提升目标回归的精度。
17.本发明在视觉物体跟踪任务上取得了很好的准确性,提升了物体回归的精度。相较于现有方法,本发明提出的treg跟踪方法在多个视觉跟踪测试基准数据集中都体现了好的跟踪成功率和定位准确度。
附图说明
18.图1是本发明所使用的系统框架图。
19.图2是本发明提出的训练帧分类特征提取模块示意图。
20.图3是本发明提出的训练帧回归特征提取模块示意图。
21.图4是本发明提出的测试帧分类特征提取模块示意图。
22.图5是本发明提出的测试帧回归特征提取模块示意图。
23.图6是本发明提出的基于目标的回归特征变换器过程示意图。
具体实施方式
24.本发明的目标是构建一个精确的目标跟踪器使其能够较好地建模目标的形变、姿态和视角等的变化。从现有技术的分析中,可以发现对于构建精确跟踪器的核心是如何将第一帧中给定的目标信息整合到回归分支中从而保持其精确的边界信息并且及时地处理形变问题。受到自然语言处理中比较流行的transformer机制的启发,本发明提出了一种基于第一帧目标指导的类似于transformer结构来进行无锚框的目标回归的方法,命名为treg(target transformed regression tracker)。本发明在回归分支中设计的目标指导的transformer回归模块以一种点对点的方式将第一帧的目标特征信息引入边框回归中,从而能提供精确的回归边界框。此外,本发明中提出了一种简洁而有效的在线模板更新策略,能够适应物体的外观和尺度变化,从而实现更精确的跟踪。
25.本发明提出了一种基于目标变换回归网络的精确目标跟踪方法。经过在trackingnet-train、lasot-train、coco-train、got-10k-train四个训练数据集上进行离线训练,在otb100、nfs、uav123、vot2018、lasot-test、trackingnet-test六个测试集上测试达到了高准确率和追踪成功率,具体使用python3.7编程语言,pytorch1.2深度学习框架实施。
26.图1是本发明所构建的目标变换回归网络示意图,包括分类分支和回归分支,训练网络时,分别提取训练帧和测试帧的分类特征和回归特征,由分类特征训练对目标特征的识别,由回归特征训练对目标框的的生成,输出的目标框即跟踪结果,其中对测试帧的回归特征先经一个回归目标变换器transformer增强特征后,再结合训练帧的回归特征训练对目标框的生成;训练好的网络用于在线跟踪,以待跟踪视频的第一帧的目标分类特征信息引入回归分支中,后续视频帧作为测试帧,经目标变换回归网络得到目标框用于跟踪。本发明通过设计的完全端到端训练的全卷积网络,生成目标分类和目标回归模板,来指导分类和回归任务以及在线更新分类和回归模板的策略,实现目标追踪任务。
27.本发明的基于目标的回归目标变换器transformer如图6所示,首先将测试帧回归特征经过一个1*1卷积产生查询向量,同时将训练帧回归特征经过两个1*1卷积分别产生键向量和值向量用作查询。将查询向量经过矩阵转置之后与键向量相乘,接下来再用该结果与值向量进行相乘,从而使得相关性高的像素得到增强,相关性低的像素被抑制。最后将原
始特征与增强后的特征相加,从而在保留初始信息的基础上使特征得到变换增强。
28.作为一种具体实施方式,本发明的神经网络包括一个通过imagenet预训练好的resnet50骨干网络、一个由图2~5所示子网络组成的分类和回归特征提取网络、一个可学习的分类卷积层和图6所示的基于目标的回归目标变换器transformer。整个方法包括生成训练样例阶段、网络配置阶段、离线训练阶段以及在线跟踪阶段,具体实施步骤如下:
29.1)数据的准备阶段,即训练样例阶段。在离线训练过程中,在离线训练过程中生成训练样例,首先对离线训练数据集中每个视频的每一帧图像进行目标区域抖动处理,然后裁剪出抖动处理后的目标搜索区域,从每个视频帧序列的前半部分抽取三帧作为训练帧,从每个视频帧序列的后半部分抽取一帧作为测试帧,对测试帧标注目标框作为验证帧,对于每个验证帧生成一个以目标框的中心为中心的高斯标签图作为验证集的标签,并且记录下每帧验证帧中目标框的中心距离目标框的四个边界的距离,作为离线训练过程中回归分支的标签。
30.2)模型的配置阶段,即网络配置阶段,具体如下。
31.2.1)提取测试帧的编码特征:首先使用resnet-50的block-1、block-2、block-3和block-4作为编码器进行提取特征,对测试帧f
test
∈rb×3×
288
×
288
提取特征得到提取特征得到其中上标e2的含义是编码层block-2提取的特征,e3的含义是编码层block-3提取的特征,e4的含义是编码层block-4提取的特征,下标test表示测试帧,b代表batch size的大小,其中包括卷积层和池化层,卷积层是3*3和1*1两种卷积核,分别用来提取更高维度的特征和对特征维度进行变换,每个卷积层的卷积核采取随机初始化的方式进行初始化。
32.2.2)提取测试帧的解码特征:提取测试帧的解码特征:使用一个卷积核为1*1的卷积层作用于步骤2.1)得到的输入通道数为1024,输出通道数为256,得到了第一层解码特征特征层大小为256*18*18。对步骤2.1)得到的经过一个1*1的卷积层,输入通道数为512,输出通道数为256,使其通道数目变成256;然后用一个双线性插值层对第一层得到的解码特征进行2倍的上采样操作,然后将上面两个特征层,即通道变换后的结果和2倍上采样操作后的结果相加之后进行一次卷积操作,卷积核为1*1,从而得到第二层的解码特征特征层大小为256*36*36。对步骤2.1)得到的经过一个1*1的卷积层,输入通道数为256,输出通道数为256,使其通道数目变成256;然后用一个双线性插值层对第二层的解码特征进行2倍的上采样操作,然后再将这两个特征层,即通道变换后的结果和2倍的上采样后的结果相加之后进行一次卷积操作,卷积核为1*1,从而得到第三层的解码特征特征层大小为256*72*72。
33.2.3)提取测试帧的分类特征:如图4所示,将步骤2.2)得到的解码特征经过一个卷积层,该卷积层采用3*3的卷积核,步长为1,输入通道数为256,输出通道数为256,接着经过一个组标准化层group normalization,该标准化层的组为32,再经过一个relu激活层。将得到的特征再经过两个可形变卷积(deformable convolution),可形变卷积的卷积核大小为3*3,步长为1,输入通道数和输出通道数都是256,并且在两个可形变卷积之间设
有一个组标准化层group normalization和一个relu激活层,其中组标准化层的组大小为32,从而得到测试帧的分类特征图该特征图的大小为256*72*72。
34.2.4)提取测试帧的回归特征:如图5所示,将步骤2.2)得到的解码特征经过一个卷积层,该卷积层采用3的卷积核,步长为1,输入通道数为256,输出通道数为256,接着过一个组标准化层group normalization,该标准化层的组为32,再经过一个relu激活层。将得到的特征再经过两个可形变卷积(deformable convolution),可形变卷积的卷积核大小为3,步长为1,输入通道数和输出通道数都是256,并且在第一个可形变卷积之后跟上一个组标准化层group normalization和一个relu激活层,其中组标准化层的组大小为32,在第二个可形变卷积之后加一个relu激活层,输出回归特征,将得到的回归特征2倍上采样,再将和上采样后的结果拼接之后输入到一个1*1的卷积层中变换通道,该卷积层的输入通道数为512,输出通道数为256,得到测试帧的回归特征图特征图的大小为256*72*72。
35.2.5)提取训练帧的编码特征:同测试帧的方案,首先使用resnet-50的block-1、block-2、block-3和block-4作为编码器进行提取特征,对多个训练帧f
train
∈rb×3×3×
288
×
288
提取特征得到其中上标e2的含义是编码层block-2提取的特征,e3的含义是编码层block-3提取的特征,e4的含义是编码层block-4提取的特征,下标train表示训练帧,b代表batch size的大小,其中包括卷积层和池化层,卷积层是3*3和1*1两种卷积核,分别用来提取更高维度的特征和对特征维度进行变换,每个卷积层的卷积核采取随机初始化的方式进行初始化。
36.2.6)提取训练帧的解码特征:同测试帧提取解码特征的方案,得到第一层解码特征特征层大小为256*18*18,第二层的解码特征特征层大小为256*36*36,以及第三层的解码特征特征层大小为256*72*72。
37.2.7)提取训练帧的分类特征:如图2所示,将步骤2.6)得到的解码特征经过一个卷积层,该卷积层采用大小3的卷积核,步长为1,输入通道数为256,输出通道数为256,接着过一个组标准化层group normalization,该标准化层的组为32,再经过一个relu激活层。将得到的特征再经过两个可形变卷积(deformable convolution),可形变卷积的卷积核大小为3,步长为1,输入通道数和输出通道数都是256,并且在第一个可形变卷积之后跟上一个组标准化层group normalization和一个relu激活层,其中组标准化层的组大小为32,从而得到训练帧的分类特征图该特征图的大小为256*72*72。
38.2.8)提取训练帧的回归特征:如图3所示,将步骤2.6)得到的解码特征经过一个卷积层,该卷积层采用3的卷积核,步长为1,输入通道数为256,输出通道数为256,接着过一个组标准化层group normalization,该标准化层的组为32,再经过一个relu激活层。将得到的特征再经过两个可形变卷积(deformable convolution),可形变卷积的卷积核大小为3,步长为1,输入通道数和输出通道数都是256,并且在第一个可形变卷积之后跟上一
个组标准化层group normalization和一个relu激活层,其中组标准化层的组大小为32,在第二个可形变卷积之后加一个relu激活层。同时将步骤2.6)得到的解码特征进行同样的网络,并且将得到的特征上采样,上采样的倍数为2。将上面得到的两个特征图拼接之后输入到一个1*1的卷积层中,该卷积层的输入通道数为512,输出通道数为256,从而得到测试帧的回归特征图该特征图的大小为256*72*72。
39.2.9)生成分类分支的可适应卷积核:将步骤2.7)得到的分类特征图首先输入到一个卷积层和一个感兴趣区域池化层roi pooling中,卷积层的卷积核大小为3*3,步长为1,输入通道和输出通道数都是256,roi pooling层的大小为4*4,步长为16,从而得到一个初始的可适应卷积核该卷积核的大小为256*4*4。接下来将用高斯牛顿法进行优化,从而得到最终的分类分支的可适应卷积核f
cls
。
40.2.10)得到训练帧回归特征样本空间:将步骤2.8)得到的回归特征图首先输入到一个感兴趣区域池化层roi pooling中,roi pooling层的大小为5*5,从而得到一个用于指导测试帧回归的目标特征样本f
reg
,该目标特征样本空间的大小为7*256*5*5。
41.2.11)得到分类置信图:以步骤2.9)得到的可适应卷积核f
cls
作为分类卷积的卷积核,将分类卷积作用于步骤2.3)得到的测试帧的分类特征图经过该卷积操作之后产生最终的分类得分置信图m
cls
,该置信图的大小为72*72,得分越高的点表示该点是目标中心的置信度越高。
42.分类置信图m
cls
的具体计算方式为:
43.记分类卷积为conv1,其卷积核为步骤2.9)得到的可适应卷积核f
cls
,
[0044][0045]
2.12)通过目标回归变换器transformer得到回归偏置距离:以步骤2.10)得到的回归特征样本空间f
reg
作为指导,通过一个基于该样本空间的transformer作用于步骤2.4)得到的测试帧的回归特征图从而将训练样本的回归信息引入到测试帧中,经过卷积操作之后产生最终的中心点到目标边界距离回归偏置图m
reg
,该回归图的大小为4*72*72,分别表示目标的中心点距离物体的四个边界的距离,其中,
[0046]mreg
∈r4×
72
×
72
。
[0047]
根据步骤2.11)得到的置信图m
cls
找到得分最高的点,然后在m
reg
中找出该点对应的四个偏置距离即可得到最终的目标框。
[0048]
3)离线训练阶段,对于分类分支的离线训练使用dimp提出的类合页损失lbhinge loss作为损失函数,对于回归分支使用iou损失函数,结合由验真帧得到的标签,使用sgd优化器,通过反向传播算法来更新整个网络参数,不断重复步骤2),直至达到迭代次数;
[0049]
4)在线跟踪阶段,首先裁剪出待跟踪视频的第一帧图像中的目标框搜索区域作为模板,然后将模板帧扩充为一个包含30帧图像的在线训练数据集,作为训练帧f
train
,将待跟踪视频中待跟踪的帧作为测试帧f
test
,以f
train
输入步骤2)的网络,得到f
test
上的目标框。
[0050]
作为优选方式,在跟踪过程中,从已经跟踪完的帧序列中每25帧挑选出一个分类得分最高的帧和已经跟踪得到的目标框作为标签添加到在线训练数据集中,用于更新分类
分支的可适应卷积核f
cls
及回归分支的目标特征样本内存。
[0051]
下面以一个实施例具体说明网络配置阶段。使用resnet-50的前四个block作为编码层的网络结构提取编码特征,网络中载入imagenet预训练模型的参数,然后分别对训练帧和测试帧进行解码操作提取解码特征。接下来分别对训练帧和测试帧提取分类特征和回归特征,如图2所示,对训练帧,将经过解码器后得到的解码特征输入到卷积层中,再执行两个可形变卷积操作,每个卷积操作之间有一个组标准化层和relu激活层,从而可以得到训练帧的分类特征,分类特征图的大小为256*72*72。同样如图3、图4、图5所示,将训练帧和测试帧经过解码器后得到的特征,经过图中几个卷积层、可形变卷积层、组标准化和激活函数层。训练帧的回归特征图大小为1024*72*72,测试帧的分类特征图和回归特征图的大小都为256*72*72。
[0052]
在训练帧中生成分类可优化模型,将训练帧的分类特征输入到初始可优化模型生成器中,该初始模型生成器可产生初始的粗略模型。然后将测试帧的分类特征执行一个卷积操作,其卷积核即为上面得到的可优化分类模型,这样即可得到72*72的分类得分图。对于回归分支,将训练帧的回归特征样本空间和测试帧的回归特征输入到图6中设计的基于目标的回归特征变换器transformer中产生变换的回归特征,最终经过几个卷积层作为前馈网络产生4*72*72的回归偏置距离图。在分类得分图中找出得分最高的点作为目标的中心点,并且在回归偏置距离图中找出该点的四个值即为中心点距离目标四个边界的距离,这样就得到了最终的目标框。
[0053]
离线训练阶段,对于分类分支的离线训练使用dimp提出的类合页损失lbhinge loss作为损失函数,对于回归分支使用了iou损失函数,使用sgd优化器,设置batchsize为40,总的训练轮数设置为100,学习率在25,45轮处学习率除以10,衰减率设置为0.2,在8块rtx 2080ti上训练,通过反向传播算法来更新整个网络参数,不断重复步骤2.1)至步骤2.12),直至达到迭代次数。
[0054]
在线跟踪阶段,将训练帧序列和测试帧输入到网络中,在初始参数的基础上得到最终的目标框。
[0055]
首先裁剪出待跟踪视频的第一帧图像中的目标框搜索区域作为模板,然后将模板帧扩充为一个包含30帧图像的在线训练数据集,作为训练帧f
train
,将待跟踪视频中待跟踪的帧作为测试帧f
test
,以f
train
输入步骤2)的网络,得到f
test
上的目标框,在跟踪过程中,从已经跟踪完的帧序列中每25帧挑选出一个分类得分最高的帧和已经跟踪得到的目标框作为标签添加到在线训练数据集中,用于更新分类分支的可适应卷积核f
cls
及回归分支的目标特征样本空间f
reg
。
[0056]
根据本发明方法进行跟踪测试,对测试集中每个视频的第一帧进行和训练集相同的操作,首先裁剪出目标大小5倍的区域,然后缩放为288*288,并且对第一帧进行旋转、平移和加噪声等数据增强得到30个训练样本,通过增强后的训练数据进行在线训练和更新,在接下来每一帧进行跟踪的过程中,每隔25帧进行一次在线训练以及回归分支的在线更新,并且挑选出分类得分最高一帧加入到在线训练集中。在测试数据集上,跟踪的效率为30fps,在跟踪精度上,在otb100数据集上auc达到了71.4%,pre达到了94.5%;在nfs数据集上,auc达到了66.6%;在uav123数据集上,auc达到了66.9%,pre达到了88.4%;在vot2018数据集上,eao达到了0.492,robustness达到了0.098,accuracy达到了0.612;在
trackingnet数据集上,succ达到了78.5%,pre达到了75.0%;在lasot数据集上,suc达到了64.0%,本发明方法在上述测试数据集上的指标超过了当前效果最好的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1