一种基于多任务学习的代表性AU区域提取的微表情识别方法
本发明涉及一种基于多任务学习的代表性au区域提取的微表情识别方法,属于深度学习和模式识别
技术领域:
。
背景技术:
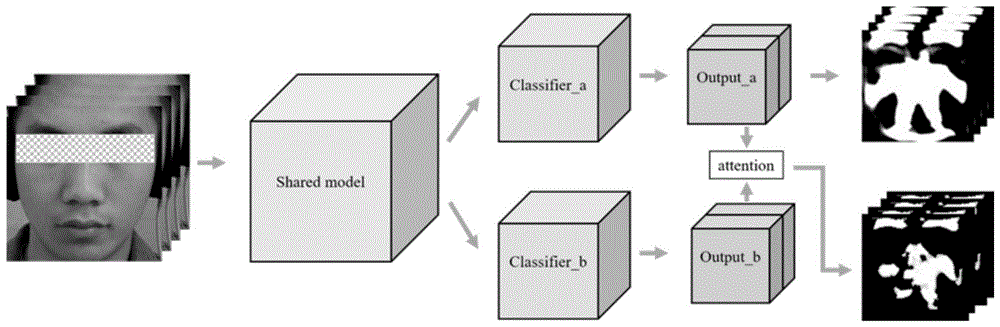
:对面部情绪的研究开始于charlesdarwin,他指出了情绪产生的主要规则,详细介绍了不同情绪的外在表现以及情绪与神经系统的关系,奠定了情绪研究的基础。ekman和friesen在观察某重度抑郁症病人隐藏自杀意图的视频时,发现了含有绝望表情的画面,画面仅持续了2/25秒的时间,ekman等人因此将这段短暂的表情命名了微表情。微表情与普通的宏表情不同,微表情是一种持续时间短且无意识做出的面部表情,它暴露了人们试图隐藏的真实情绪,一般来说,微表情的持续时间在1/25到1/5秒,因此在正常表达中很难被发现。一段微表情可以分为起始帧、过渡帧、高潮帧、过渡帧、结束帧。面部表情有7种基本情绪,即:开心、惊讶、愤怒、厌恶、恐惧和伤心和蔑视。ekman提出了面部动作编码系统(facialactioncodingsystem,facs),定义了不同的面部表情对应的动作单元(actionunit,au),他根据facs设计了一套微表情识别的训练工具(microexpressiontrainingtool,mett),实验结果证明:观察者仅需要一个半小时的时间,就能将微表情识别准确率提高30%~40%,这为微表情识别技术的发展提供了可能。微表情的特征提取方法有基于光流的方法、基于纹理描述的方法、基于深度学习的方法。基于光流的方法适合处理运动图像,描述了物体在图像运动的速度变化。光流法有两个前提假设:成像表面是平坦的,入射光照射到表面的亮度呈均匀分布;反射率的变化是平滑的,光照在物体上没有不连续性。lucas等人假设光流在局部像素区域内是恒定的,并使用最小二乘法计算局部区域内所有像素的基本光流方程。刘永进提出主方向均值光流(maindirectionalmeanopticalflow,mdmo),根据关键点将人脸划分为许多感兴趣区域,结合局部运动信息及其空间的位置变化,计算每个感兴趣区域内的归一化特征。由于mdmo使用的平均操作会造成特征空间中原有结构的丢失,刘永进又提出了稀疏mdmo(sparsemdmo),基于样本点的稀疏性,将特征空间中的距离与图正则化稀疏编码相结合,得到稀疏mdmo特征。liong等人提出使用光学应变将运动信息进行时空聚合,对特征直方图进行加权,来调整空间块的重要性。happy等人提出了光流方向模糊直方图(fuzzyhistogramofopticalfloworientations,fhofo),直方图根据光流的幅值进行加权,基于模糊成员函数将累积运动方向投影到的不同直方图区间中,fhofo特征对表情强度和光照变化具有鲁棒性。徐峰提出了面部动态映射(facialdynamicsmap,fdm),计算相邻帧的稠密光流进行像素级的对齐,统计时空特征内最主要的运动方向,这种方法对运动的尺度具有较强的鲁棒性,既能提取大范围运动的面部特征,也能提取面部细微的运动变化。基于纹理描述的方法包括lbp、lbp-top、stlbp-ip、distlbp-rip、stclqp、lbp-sip等。等人提出局部二值模式(localbinarypattern,lbp),将人脸区域进行分块,在每一个小块内对比周围像素和中心像素的大小,如果周围像素值大于或等于中心像素值,则取值为1,否则取值为0,将形成的二进制值转换成十进制值作为该像素的lbp值,lbp特征具有灰度不变性,等人还将lbp值生成特征直方图,将人脸特征进一步增强。由于lbp特征的半径长度是固定的,对于尺寸和纹理变化不具有很强的鲁棒性,因此topi等人对lbp进行了改进,将小块从正方形变为圆形,并且选择最小的值作为lbp值,使得特征具有旋转不变性,增强了特征对不同尺寸和纹理的适应性。由于lbp特征根据不同的旋转尺度可以产生多种lbp值,ojala等人提出基于等价模式(uniformpattern)的lbp,将二进制数中0和1的转变大于三次的特征归为一个等价类,极大地减小了lbp的种类。赵国英提出基于三正交平面的lbp(localbinarypatternsonthreeorthogonalplanes,lbp-top)特征,从xy、xt和yt三个平面提取lbp特征,然后将特征拼接起来,提取了时间和空间方向的纹理特征。黄晓华提出基于时空积分投影的lbp(spatiotemporallocalbinarypatternwithintegralprojection,stlbp-ip),假设第一帧图像为中性帧,将其他帧的人脸与第一帧进行差分,从三个平面计算积分投影并生成直方图,然后在直方图上计算一维lbp值,最后将三个平面直方图的特征拼接作为stlbp-ip特征。后来,黄晓华提出distlbp-rip(discriminativespatiotemporallocalbinarypatternwithrevisitedintegralprojection),不需要假设第一帧为中性帧,在人脸图像使用鲁棒主成分分析(robustprincipalcomponentanalysis,rpca)提取细微的运动信息,在此基础进行水平和垂直积分投影,提取微表情的形状特征,结合lbp进一步提取图像的外观和运动信息,使用拉普拉斯分数来选择具有代表性的组特征,以增强微表情的判别能力。黄晓华针对lbp-top不能很好地提取局部结构特征的问题,提出了基于时空的完全局部量化模式(spatiotemporalcompletedlocalquantizedpatterns,stclqp),从时间和空间方向提取基于正负符号、幅值和方向信息,根据fisher准则构成具有判别性的编码本。王艳丹提出基于六个正交点的lbp(localbinarypatternwithsixintersectionpoints,lbp-sip),将xy、xt和yt方向上三条相交直线的六个邻域点计算lbp-top,能够有效减小计算复杂度。随着深度学习的飞速发展,近年来出现了越来越多基于深度学习的微表情识别方法。王甦菁提出tlcnn(transferringlong-termconvolutionalneuralnetwork),使用迁移学习的思想将宏表情对卷积神经网络进行预训练,然后输入微表情进行网络的微调,最后将微表情序列输入到长短时记忆网络(longshorttermmemorynetwork,lstm)网络中学习微表情序列的动态变化。dtscnn(dualtemporalscaleconvolutionalneuralnetwork)首次将双流网络用于微表情识别问题,将微表情序列分别插值到65帧和129帧,然后在相邻帧之间计算光流变化,接着将光流值通过神经网络进行训练,选择最后一个池化层的输出作为样本的特征,将两路样本送入支持向量机中,选择两个支持向量机中最高的概率值作为样本预测的最终概率。hu等人提出的multi-task(multi-taskmicro-expressionrecognitioncombiningdeepandhandcraftedfeatures)结合了手工特征和深度特征,逐帧对图像进行gabor变换,使用lgbp-top(localgaborbinarypatternfromthreeorthogonalpanels)特征将空间和时间的信息相结合,深度特征使用alexnet网络提取,最后融合深度特征和手工特征融入支持向量机中分类。escstf基于时空的小尺度特征学习方法,使用卷积神经网络对不同状态的表情特征进行编码,随后使用lstm学习微表情的时序特征。quang等人提出基于capsulenet的微表情识别方法首先对微表情视频序列进行预处理,提取10个感兴趣区域,并计算区域内当前帧与起始帧、结束帧之间的像素差,找到高潮帧的位置,然后送入capsulenet网络中进行分类。peng等人(frommacrotomicroexpressionrecognition:deeplearningonsmalldatasetsusingtransferlearning)使用迁移学习,用宏表情预训练resnet网络,在微表情上进行微调,获得了很不错的实验结果。li等人提出apex_me探索只使用高潮帧进行微表情识别,首先使用欧拉视频放大(eulerianvideomagnification,evm)对微表情的运动细节进行放大,将微表情视频序列分解为不同的空间频带,对所有的频带使用时间滤波器,然后将滤波后的频带求和,生成放大之后的视频序列,接着计算视频序列的lbp值,将微表情视频序列分块并进行3d傅里叶变换,借助高通滤波器获得每一块的高频特征,选择高频特征之和最大的块作为高潮帧,最后挑选高潮帧及其前后两帧输入到vgg网络中进行微表情样本的分类。elrcn计算微表情序列的光流图和光学应变图,与原始图像在通道维拼接输入到vgg网络分类。verma等人提出learnet(lateralaccretivehybridnetwork)通过在网络中合并增生层,以增生的方式完善表情特征,且该体系结构结合了卷积层之间的交叉解耦关系,有助于保留细微的面部肌肉变化信息。xia等人提出一种新型深度递归卷积网络,能够捕获微表情序列的时空变形,该深度模型由几个提取特征的循环卷积层和一个用于识别的全连接层组成,同时,在深度网络中联合使用了时间数据扩充策略和平衡丢失策略,一定程度上克服了训练样本有限和不平衡的缺点。wu等人使用时域采样变形(temporalsamplingdeformation,tsd)对序列帧数进行归一化,提出的tsnn(three-streamcombining2dand3dconvolutionalneuralnetworkformicro-expressionrecognition)网络融合了2d和3d卷积神经网络,用于对微表情特征进行分类。该网络还具有中间聚合(intermediatefusion,if)和延迟聚合(latefusion,lf)两种类型,能够同时自动学习微表情的时间和空间特征。nie等人提出基于性别的双流多任务网络(dual-streammulti-taskgender-basedmicro-expressionrecognition,geme)通过结合身份的性别特征对微表情进行识别,提高了微表情识别的准确性。nora等人提出afer(brief-basedfacedescriptor:anapplicationtoautomaticfacialexpressionrecognition),在人脸局部使用二元鲁棒独立特征(binaryrobustindependentelementaryfeatures,brief),用来提取局部区域的表情特征,实现占用了比较小的内存,并且实验效率比较高。lei等人提出graph-tcn网络(graph-temporalconvolutionalnetwork,graph-tcn),首先根据人脸的关键点定义图结构,然后使用graph-tcn网络在两个通道内分别提取节点特征和边缘特征进行分类。最近几年开始出现基于au的微表情识别。xie等人提出的agacn将au和微表情的标签相结合,基于人脸的肌肉运动及其关系信息对不同的au进行建模,由于微表情训练样本有限和不平衡的缺点,xie等人还提出了一种数据增强方法,有效地提高了微表情识别的性能,但是,由于au的数量较多,引入图卷积网络需要考虑多个au节点之间的关系,计算量比较大,导致实验效率低下。puneetgupta提出了merastcmerastc缓解了微表情容易过拟合的问题,结合au、关键点和外观特征对微表情视频序列细微的形变进行编码,提出一种新的中性人脸归一化方法来加快微表情识别的效率,但是该方法需要视频序列中含有中性帧,因此具有比较大的局限性。lo等人提出了mergcn,经过3d卷积神经网络提取au特征,然后使用图卷积网络发现au节点之间的依赖关系来帮助微表情的分类,该方法使用全部au构建图卷积网络,没有选择最具代表性的au,使得计算成本较高。技术实现要素:针对现有技术的不足,本发明提供一种基于多任务学习的代表性au区域提取的微表情识别方法。发明概述:一种基于多任务学习的代表性au区域提取的微表情识别方法,包括数据集预处理及划分、基于au掩膜特征提取网络的au掩膜提取、微表情特征提取和分类识别四个部分。本发明考虑了不同au对微表情识别的贡献,通过基于多任务学习的微表情au掩膜特征提取网络同时提取全部au区域和代表性au区域,并且通过通道注意力和空间注意力机制借助全部au区域信息提取代表性au区域。为了解决微表情样本不足的问题,本发明提出跨模态四元组损失,借助宏表情的信息,将宏表情和微表情组成四元组,增加了训练样本的数量,提高了微表情的识别性能。术语解释:1、多任务学习:多任务学习将多个相关的任务使用共享模型同时训练,利用每个任务中学到的知识,帮助模型更好地学习其他任务,从而提高多个任务的实验结果,获得比训练单一任务更好的效果。2、facs:全称为facialactioncodingsystem(面部动作编码系统),是一种基于面部表情对人类面部运动进行分类的系统,facs通过面部外观的细微瞬时变化来编码单个面部肌肉的运动,是对情绪的物理表达进行系统分类的通用标准。由于主观性和时间消耗问题,facs已被建立为计算机自动系统,可以检测视频中的面部,提取面部的几何特征,然后生成每个面部运动的时间轮廓。3、au:全称为actionunit(动作单元),是单个肌肉或一组肌肉的基本动作。4、dlib视觉库:dlib是一个现代c++工具包,包含许多开源的机器学习算法和工具,用于在c++中创建复杂的软件来解决现实世界问题。它被工业界和学术界广泛应用于机器人、嵌入式设备、移动电话和大型高性能计算环境等领域。5、68个关键特征点:68个关键点主要分布在下颌线、右眼眉、左眼眉鼻子、右眼、左眼、嘴外轮廓、嘴内轮廓,可以由dlib视觉库检测,检测效果如图2所示,标注为1-68。6、tim插值算法:于2011年提出的视频序列插值方法,通过构建一个低维流形,将视频帧中提取的视觉特征投射到一条连续确定性曲线上,并且可以将曲线上的任意点映射回图像空间,适合于时间插值。7、farneback光流算法:一种稠密光流计算方法,光流法的前提假设包括:相邻帧之间亮度恒定且物体的运动变化微小,局部区域内像素点具有相同的运动趋势。8、被试独立的k折交叉验证法:根据样本的身份将数据集划分为k份,进行k次实验,每次选择其中的一份作为测试集,剩下的k-1份作为训练集,取k次实验准确率的均值作为最终的准确率。现实生活中,测试集的身份往往是训练集中没见到的,因此这种验证方法获得的结果更加接近真实情况。9、softmax:一种激活函数,一般用于多分类问题,softmax将样本输出为每类的概率映射到[0,1]之间,并且各类的概率之和为1。本发明的技术方案如下:一种基于多任务学习的代表性au区域提取的微表情识别方法,包括步骤如下:a、对微表情视频进行预处理,得到包含人脸区域的图像序列及其68个关键特征点;b、根据68个关键特征点,获取au区域的位置,提取au区域内的光流特征,设置代表性au区域的个数,得到最具代表性的au区域;c、数据集划分,根据被试独立的k折交叉验证法将步骤a得到的包含人脸区域的图像序列划分训练集和测试集,得到微表情训练集和微表情测试集;d、将步骤a处理后的人脸图像序列送入au掩膜特征提取网络模型,计算基于像素的交叉熵损失和骰子损失,训练au掩膜特征提取网络模型;e、将步骤a处理后的包含人脸区域的图像序列送入训练好的au掩膜特征提取网络模型,得到全部au区域和代表性au区域的掩膜,选择代表性au区域的掩膜与步骤a处理后的包含人脸区域的图像序列相乘,得到只包含代表性au区域的人脸图像序列;f、使用步骤a的预处理方法处理宏表情视频,得到宏表情的人脸图像序列,将得到的宏表情的人脸图像序列和步骤c得到的微表情训练集送入包含非局部模块的3d-resnet网络模型中,计算交叉熵损失和跨模态四元组损失,训练包含非局部模块的3d-resnet网络模型;g、将步骤c得到的微表情测试集送入训练好的包含非局部模块的3d-resnet网络模型,计算交叉熵损失,得到微表情测试集对应的微表情类别,计算正确分类的样本数占总样本数的比例,作为本次实验的分类准确率;h、重复k次实验,取k次实验的分类准确率的均值作为最终的分类准确率。根据本发明优选的,步骤a中,对微表情视频进行预处理,包括分帧、人脸关键特征点检测、人脸裁剪、tim插值、人脸缩放;1)分帧:根据微表情视频的帧率将微表情视频划分为微表情图像序列;2)人脸关键特征点检测:使用dlib视觉库检测微表情图像序列的68个关键特征点;3)人脸裁剪:根据定位的人68个关键特征点,确定人脸框的位置;水平方向上,以最靠左和最靠右的关键特征点的中点为裁剪后图片的中心点;垂直方向上,首先,确定两眼关键特征点中心到嘴巴关键特征点中心的像素距离,该像素距离占垂直方向的35%,然后,确定顶部和底部的位置,顶部距离到两眼关键特征点中心的距离占垂直方向的30%,底部到嘴巴关键特征点中心的距离占垂直方向的35%,最后,框选出人脸并裁剪。4)tim插值:使用tim插值算法对步骤3)人脸裁剪后的微表情图像序列进行插值,设置插值的帧数,得到指定帧数的图像序列;5)人脸缩放:设置图像的宽和高,按比例将步骤4)得到的图像序列的每一帧图像进行缩放,得到设置的宽和高的图像序列。根据本发明优选的,步骤b中,根据68个关键特征点,确定辅助点的位置,假设左上角为坐标原点,眼部区域辅助点包括辅助点0、辅助点1、辅助点2、辅助点4、辅助点5、辅助点6的横坐标分别与标注为17、19、21、22、24、26的关键特征点的横坐标相同,设置参数δ,参数δ表示眉毛上部肌肉与眉毛的距离,取值范围一般在高的8%到15%之间,眼部区域辅助点包括辅助点0、辅助点1、辅助点2、辅助点4、辅助点5、辅助点6的纵坐标为其横坐标减小δ;其余辅助点分别为两个关键特征点的中点,其余辅助点包括:辅助点3为标注为2的关键特征点与标注为4的关键特征点的中点、辅助点7为标注为3的关键特征点与标注为29的关键特征点的中点、辅助点8为标注为13的关键特征点与标注为29的关键特征点的中点、辅助点9为标注为4的关键特征点与标注为33的关键特征点的中点、辅助点10为标注为12的关键特征点与标注为33的关键特征点的中点、辅助点11为标注为2的关键特征点与标注为41的关键特征点的中点、辅助点12为标注为14的关键特征点与标注为46的关键特征点的中点、辅助点13为标注为5的关键特征点与标注为59的关键特征点的中点、辅助点14为标注为6的关键特征点与标注为58的关键特征点的中点、辅助点15为标注为8的关键特征点与标注为57的关键特征点的中点、辅助点16为标注为10的关键特征点与标注为56的关键特征点的中点、辅助点17为标注为11的关键特征点与标注为59的关键特征点的中点;au区域的求取过程为:连接标注为17的关键特征点、标注为19的关键特征点、辅助点0、辅助点1,得到第1个au区域;连接标注为19的关键特征点、标注为21的关键特征点、辅助点1、辅助点2,得到第2个au区域;连接标注为22的关键特征点、标注为24的关键特征点、辅助点3、辅助点4,得到第3个au区域;连接标注为24的关键特征点、标注为26的关键特征点、辅助点4、辅助点5,得到第4个au区域;连接标注为39的关键特征点、标注为41的关键特征点、辅助点7、辅助点11,得到第5个au区域;连接标注为42的关键特征点、标注为46的关键特征点、辅助点8、辅助点12,得到第6个au区域;连接标注为21的关键特征点、标注为22的关键特征点、27的关键特征点、29的关键特征点、39的关键特征点、42的关键特征点、辅助点7、辅助点8,得到第7个au区域;连接标注为2的关键特征点、标注为3的关键特征点、辅助点7、辅助点11,得到第8个au区域;连接标注为29的关键特征点、标注为33的关键特征点、辅助点7、辅助点9,得到第9个au区域;连接标注为29的关键特征点、标注为33的关键特征点、辅助点8、辅助点10,得到第10个au区域;连接标注为13的关键特征点、标注为14的关键特征点、辅助点8、辅助点12,得到第11个au区域;连接标注为33的关键特征点、标注为59的关键特征点、辅助点9、辅助点13,得到第12个au区域;连接标注为33的关键特征点、标注为55的关键特征点、辅助点10、辅助点17,得到第13个au区域;连接标注为5的关键特征点、标注为6的关键特征点、标注为58的关键特征点、标注为59的关键特征点,得到第14个au区域;连接标注为10的关键特征点、标注为11的关键特征点、标注为55的关键特征点、标注为56的关键特征点,得到第15个au区域;连接标注为6的关键特征点、标注为8的关键特征点、标注为10的关键特征点、辅助点14、辅助点15、辅助点16,得到第16个au区域。使用farneback光流算法提取au区域内的光流特征,光流特征包括幅值特征和角度特征,幅值特征指的是相邻两帧图像某一像素处同一物体的移动距离,角度特征指的是相邻两帧图像某一像素处同一物体的移动方向,计算每个au区域内的光流幅值之和,即对au区域内的全部像素点处的光流幅值求和,并按照从大到小的顺序排序,设置代表性au区域的个数n,其中前n个光流幅值之和对应的au区域为最具代表性的au区域。根据本发明优选的,步骤c中,根据被试独立的k折交叉验证法,将步骤a得到的包含人脸区域的图像序列根据样本的身份划分为k份,进行k次实验,每次选取一份作为测试集,其余部分作为训练集,得到k组微表情训练集和测试集。根据本发明优选的,步骤d中,将预处理后的人脸图像序列送入au掩膜特征提取网络模型,au掩膜特征提取网络模型包括共享模型、分类器a及分类器b;为了更好地提取到具有代表性的au区域,使用双流的多任务学习进行au掩膜特征提取网络模型的训练,一流进行au区域和背景的粗糙二分类任务,另外一流进行代表性au区域和背景的精细二分类任务。具体来说,一流将输入的微表情图像序列输入到共享模型(sharedmodel)、分类器a(classifier_a),进行粗糙二分类,若当前像素属于au区域的所在区域,则标记为前景,否则为背景;另外一流输入到共享模型、分类器b(classifier_b)中,进行精细二分类,若当前像素属于最具代表性的au区域所在区域,则标记为前景,否则为背景。进一步优选的,共享模型的网络结构为3d-fusionnet,共享模型包括编码器和解码器,共享模型的输入为c×l×w×h的图像序列,c为图像序列的通道数,l为图像序列的帧数,w、h分别为图像的宽和高;编码器包括3个下采样模块和1个桥接模块,每个下采样模块均包括3d卷积层、批归一化层、relu层以及最大池化层;经过下采样模块后的低分辨率特征,能够比较好地提取目标au在人脸图像的语义信息。解码器包括3个上采样模块,每个上采样模块均包括转置3d卷积层、3d卷积层、批归一化层以及relu层;使用3d卷积是为了从图像序列中直接提取样本的空间和时序特征。在编码器、解码器内部以及编码器和解码器之间均使用残差结构。残差结构能够很好地解决网络退化的问题,使网络更容易优化,同时将编码器低分辨率信息和解码器的高分辨率信息相加能够为分割au前景和背景提供更为精细的特征。进一步优选的,分类器a和分类器b的网络结构相同,均包括两个3d卷积层和一个relu层。共享模型输出的特征,经过分类器a进行au区域和背景的粗分类,为了更加方便地划分前景和背景特征,使用两个通道分别表示前景通道和背景通道,在前景通道中,处于au区域的像素点标记为1,否则,处于背景区域的像素点标记为0;在背景通道中,处于背景区域的像素点标记为1,其余部分标记为0;分类器b的输出前景为代表性au区域的组合,其余部分为背景区域;需要注意的是,分类器b的输出图像特征的大小和输入图像的大小相同,输出图像特征的通道数变为2。进一步优选的,为了进一步结合粗分类和细分类两个任务提取到的信息,使用空间注意力机制和时间注意力机制将分类器a的输出的和分类器b的输出加权,作为最终的掩膜特征:output_a为分类器a的输出,output_b为分类器b的输出,将output_a的两个通道分开,前景通道记为pau,表示像素点属于au区域的概率,背景通道记为p背景,表示像素点属于背景部分的概率;为了得到每个通道的注意力权重,将pau和p背景变形成(l×w×h,1)的向量,output_b变形成(2,l×w×h)的向量,将这两个向量相乘,l1归一化得到注意力通道权重的值,通道注意力的实现如下式(1)、式(2)、式(3)、式(4)所示:wau=[λau,0·output_b,λau,1·output_b](3)w背景=[λ背景,0·output_b,λ背景,1·output_b](4)式(1)、式(2)、式(3)、式(4)中,re()表示变形操作,λau表示au特征在前景通道和背景通道的权值向量,λ背景表示背景特征在前景通道和背景通道的权值向量,且λau∈r2×1,λ背景∈r2×1,λau,i表示λau的第i个值,λ背景,i表示λ背景的第i个值,i∈{0,1},wau、w背景分别是指pau、p背景通道注意力加权之后的特征;将通道注意力加权之后的特征wau、w背景与output_a相结合,具体的实现如式(5)所示:feature′(c,l,w,h)=pau(l,w,h)wau(c,l,w,h)+pau(l,w,h)w背景(c,l,w,h)(5)式(5)中,feature′(c,l,w,h)∈rc×l×w×h,c∈{0,1},l∈{0,1,...,l-1},w∈{0,1,...,w-1},h∈{0,1,...,h-1},feature′(c,l,w,h)经过一个卷积核为1×1×1的3d卷积层,得到最终的au掩膜特征,pau(l,w,h)指的是样本在第l帧的(w,h)像素处属于au的概率,wau(c,l,w,h)指的是经过au特征加权后的样本在第c个通道、第l帧的(w,h)像素处的特征值,w背景(c,l,w,h)指的是经过背景特征加权后的样本在第c个通道、第l帧的(w,h)像素处的特征值。进一步优选的,在粗糙二分类即粗分类任务中,由于人脸的前景和背景比例相对均衡,因此,使用基于像素的交叉熵损失函数lcross,如式(6)所示:式(6)中,yc,l,w,h表示像素点(c,l,w,h)处的标签,c∈{0,1},分别代表前景通道和背景通道,output_ac,l,w,h表示粗分类任务的输出像素点(c,l,w,h)处为前景或背景的概率,经过神经网络的梯度反向传播,使得交叉熵损失不断减小。进一步优选的,在精细二分类即细分类任务中,由于人脸的代表性au区域比背景占比小,因此,使用骰子损失(diceloss)函数s,骰子损失不需要给不同类别样本分配权重,来建立前景和背景像素点之间的平衡,该损失是一个基于骰子系数s的函数,骰子系数是一个范围在0到1之间的数值,用来衡量两个样本之间的相似程度,如式(7)所示:式(7)中,n=c×l×w×h,pi表示细分类任务输出的某一像素在代表性au区域的预测概率,gi表示像素是否在代表性au区域的真值,δ是平滑参数,用来防止分母为0,默认取值为1;骰子损失函数的目的是最大化基于骰子系数的目标函数,损失函数ldice如式(8)所示:ldice=1-s(8)最后的损失为二者损失的和,如式(9)所示:ltotal=lcross+ldice(9)。根据本发明优选的,步骤e中,将步骤a处理后的包含人脸区域的图像序列送入训练好的au掩膜特征提取网络,分类器a输出全部au区域的掩膜,分类器b输出代表性au区域的掩膜,选择代表性au区域的掩膜与预处理后的包含人脸区域的图像相乘,得到只包含代表性au区域的人脸图像序列。根据本发明优选的,步骤f中,使用步骤a的预处理方法处理宏表情视频,得到宏表情的人脸图像序列,将宏表情的人脸图像序列和步骤c得到的微表情训练集送入包含非局部模块的3d-resnet网络模型中;基础的3d-resnet网络由resnet(2d)修改而成,3d-resnet网络考虑了时间维度上帧间的运动信息,能更好地捕获序列的时间和空间特征。包含非局部模块的3d-resnet网络模型由多个残差块串联而成,残差块为基本块;基本块的结构分两路,输入特征一路经过两个卷积核为3×3×3的3d卷积层和relu层提取特征,输入特征另一路经过卷积核为1×1×1的3d卷积层调整通道数,最后将两路提取的特征按元素相加,经过relu层,即得到基本块的输出。根据本发明优选的,非局部操作可以捕获网络的长时依赖,是一种简洁高效的通用小组件,非局部操作的表示形式如式(10)、式(11)、式(12)所示:g(xj)=wgxj(12)式(10)、式(11)、式(12)中,x为输入图像序列的特征,j为输入特征所有可能的位置索引,i为输出位置索引,y为输出特征,尺寸与输入图像序列的大小相同,xi指的是图像序列在输出位置i处的特征,xj指的是图像序列在输出位置j处的特征,yi指的是输出特征在位置索引j处的值,c(x)为响应因子,g()为映射函数,g(xj)计算了xj处经过映射之后的特征,式(12)中的wg为可学习的权重矩阵;函数f(xi,xj)用于计算xi和xj的相似度;如式(10)、式(11)、式(12)的非局部操作包装成一个非局部模块,非局部模块的定义如式(13)所示:zi=wzyi+xi(13)式(13)中,wz为权重矩阵,zi为xi经过非局部操作之后的特征,式(13)采用了残差块结构,残差块的结构设计没有破坏原始的网络结构,其输入输出大小相同,因此可以方便地合并到许多现有的架构中。残差块结构包括4个1×1×1的3d卷积层,用于对特征的通道进行升维或者降维,包含非局部模块的3d-resnet网络模型包括依次串联的5个残差块,非局部模块添加包含非局部模块的3d-resnet网络模型中的第4个残差块中,即在3d-resnet的conv4_x部分,具体来说,第4个残差块的输入特征先经过3d卷积+bn+relu和3d卷积+bn操作,然后,将其输出的特征进行非局部操作,得到非局部操作之后的特征,接着将非局部操作之后的特征输入包含非局部模块的3d-resnet网络模型中的第5个卷积模块(conv5_x)进行后续的操作。采取在线的跨模态四元组选择策略,选择宏表情相近的情绪类型作为异类样本,将一类微表情作为锚样本,在宏表情中选择同类情绪的样本作为宏表情正样本,在微表情中选择同类情绪的样本作为微表情正样本,选择宏表情中与之相近的情绪类型的样本作为宏表情负样本,构成跨模态四元组样本对,样本对之间满足以下约束,如下式(14)、式(15)、式(16)所示:式(14)、式(15)、式(16)中,f(x)表示样本x在3d-resnet网络的倒数第二个全连接层的输出,xa表示锚样本,表示与锚样本情绪相同的宏表情样本,表示与锚样本情绪相同的微表情样本,xn表示与锚样本情绪相近的宏表情样本,αi为边界参数,i∈{1,2,3};f(xa)代表xa在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,f(xn)代表xn在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出。将上述约束整合起来,跨模态四元组损失的目标函数lcross-quad如式(17)所示:式(17)中,输入样本经过包含非局部模块的3d-resnet网络模型,输出样本的预测标签,记为a,a∈rn,n为表情的类别数,样本的真实标签表示成独热编码(one-hotencoding)的形式,记为y,y∈rn,具体来说,若样本属于第j类,则将真实标签y的第j位设置为1,其余位设置位为0,代表第i个锚样本,代表第i个与锚样本情绪相近的宏表情样本,代表第i个与锚样本情绪相同的微表情样本,代表第i个与锚样本情绪相近的宏表情样本,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出。接着,使用交叉熵损失函数lsoftmax评估预测标签和真实标签之间的差距,如式(18)所示:式(18)中,ai为样本预测为第i类的概率,i∈{1,2,...,n},yi为真实标签y在第i位的值;训练阶段总的损失函数为softmax交叉熵损失和跨模态四元组损失的和,如式(19)所示。ltotal=lsoftmax+lcross-quad(19)根据本发明优选的,步骤g中,将步骤c得到的微表情测试集样本送入包含非局部模块的3d-resnet网络模型,使用交叉熵损失函数lsoftmax计算交叉熵损失,得到样本对应的微表情类别,计算正确分类的样本数占总样本数的比例,作为分类准确率。根据本发明优选的,步骤h中,为了保证实验结果的准确性,采用被试独立的k折交叉验证法,重复k次实验,取k次实验的分类准确率的均值作为最终的分类准确率。本发明的有益效果在于:1、本发明利用代表性au区域的信息来帮助微表情识别,从au掩膜特征提取网络提取出微表情图像序列的代表性au区域,然后将掩膜特征信息与原样本信息相乘,得到加权后的微表情特征序列,去除了与表情无关的冗余信息。2、本发明提出跨模态四元组损失,借助宏表情的信息,将宏表情和微表情组成四元组,增加了训练样本的数量,提高了微表情识别的性能。附图说明图1为本发明au掩膜特征提取网络模型的结构示意图;图2为68个关键特征点的示意图;图3为人脸裁剪后的辅助点和68个关键点特征点的示意图;图4为16个au区域的位置示意图;图5为共享模型3d-fusionnet的网络结构示意图;图6(a)为通道注意力机制模块的结构示意图;图6(b)为空间注意力机制模块的结构示意图;图7为3d-resnet网络的结构示意图;图8为基本块的结构示意图;图9为非局部模块的网络结构示意图;图10为不同刺激强度对应的情绪示意图;图11为跨模态四元组损失函数的约束可视化示意图;图12为mmew数据库的准确率曲线示意图;图13为mmew数据库的损失曲线示意图;图14为mmew数据库粗分类任务的实验示例图;图15为mmew数据库粗分类任务的实验示例图;图16为最优参数下的混淆矩阵示意图。具体实施方式下面通过实施例并结合附图对本发明做进一步说明,但不限于此。实施例1一种基于多任务学习的代表性au区域提取的微表情识别方法,包括步骤如下:a、对微表情视频进行预处理,得到包含人脸区域的图像序列及其68个关键特征点;b、根据68个关键特征点,获取au区域的位置,提取au区域内的光流特征,设置代表性au区域的个数,得到最具代表性的au区域;c、数据集划分,根据被试独立的k折交叉验证法将步骤a得到的包含人脸区域的图像序列划分训练集和测试集,得到微表情训练集和微表情测试集;d、将步骤a处理后的人脸图像序列送入au掩膜特征提取网络模型,计算基于像素的交叉熵损失和骰子损失,训练au掩膜特征提取网络模型;e、将步骤a处理后的包含人脸区域的图像序列送入训练好的au掩膜特征提取网络模型,得到全部au区域和代表性au区域的掩膜,选择代表性au区域的掩膜与步骤a处理后的包含人脸区域的图像序列相乘,得到只包含代表性au区域的人脸图像序列;f、使用步骤a的预处理方法处理宏表情视频,得到宏表情的人脸图像序列,将得到的宏表情的人脸图像序列和步骤c得到的微表情训练集送入包含非局部模块的3d-resnet网络模型中,计算交叉熵损失和跨模态四元组损失,训练包含非局部模块的3d-resnet网络模型;g、将步骤c得到的微表情测试集送入训练好的包含非局部模块的3d-resnet网络模型,计算交叉熵损失,得到微表情测试集对应的微表情类别,计算正确分类的样本数占总样本数的比例,作为本次实验的分类准确率;h、重复k次实验,取k次实验的分类准确率的均值作为最终的分类准确率。实施例2根据实施例1所述的一种基于多任务学习的代表性au区域提取的微表情识别方法,其区别在于:步骤a中,对微表情视频进行预处理,包括分帧、人脸关键特征点检测、人脸裁剪、tim插值、人脸缩放;1)分帧:根据微表情视频的帧率将微表情视频划分为微表情图像序列;2)人脸关键特征点检测:使用dlib视觉库检测微表情图像序列的68个关键特征点;如眼睛、鼻尖、嘴角点、眉毛以及人脸各部分的轮廓点,检测效果如图2所示;3)人脸裁剪:根据定位的人68个关键特征点,确定人脸框的位置;水平方向上,以最靠左和最靠右的关键特征点的中点为裁剪后图片的中心点;垂直方向上,首先,确定两眼关键特征点中心到嘴巴关键特征点中心的像素距离,该像素距离占垂直方向的35%,然后,确定顶部和底部的位置,顶部距离到两眼关键特征点中心的距离占垂直方向的30%,底部到嘴巴关键特征点中心的距离占垂直方向的35%,最后,框选出人脸并裁剪。4)tim插值:使用tim插值算法对步骤3)人脸裁剪后的微表情图像序列进行插值,,设置插值的帧数为16,得到插值为16帧的图像序列。5)人脸缩放:设置图像的宽和高,按比例将步骤4)得到的图像序列的每一帧图像进行缩放为224×224,得到224×224的图像序列。步骤b中,根据68个关键特征点,确定辅助点的位置,假设左上角为坐标原点,眼部区域辅助点包括辅助点0、辅助点1、辅助点2、辅助点4、辅助点5、辅助点6的横坐标分别与标注为17、19、21、22、24、26的关键特征点的横坐标相同,设置参数δ为30,眼部区域辅助点包括辅助点0、辅助点1、辅助点2、辅助点4、辅助点5、辅助点6的纵坐标为其横坐标减小δ;其余辅助点分别为两个关键特征点的中点,其余辅助点包括:辅助点3为标注为2的关键特征点与标注为4的关键特征点的中点、辅助点7为标注为3的关键特征点与标注为29的关键特征点的中点、辅助点8为标注为13的关键特征点与标注为29的关键特征点的中点、辅助点9为标注为4的关键特征点与标注为33的关键特征点的中点、辅助点10为标注为12的关键特征点与标注为33的关键特征点的中点、辅助点11为标注为2的关键特征点与标注为41的关键特征点的中点、辅助点12为标注为14的关键特征点与标注为46的关键特征点的中点、辅助点13为标注为5的关键特征点与标注为59的关键特征点的中点、辅助点14为标注为6的关键特征点与标注为58的关键特征点的中点、辅助点15为标注为8的关键特征点与标注为57的关键特征点的中点、辅助点16为标注为10的关键特征点与标注为56的关键特征点的中点、辅助点17为标注为11的关键特征点与标注为59的关键特征点的中点;其规则为表1所示。图3给出了辅助点和68个关键特征点的位置。表1辅助点37891011121314151617关键特征点123134122145681011关键特征点242929333341465958575659表2给出了au区域的拐点,表2中每一个关键点拐点指的是对应标号的关键特征点,关键特征点的位置由dlib视觉库得到,每一个辅助点拐点指的是对应标号的辅助点,辅助点位置的确定方法已在上一段中阐述,按照表2的规则将每一个区域编号的全部关键点和辅助点连接起来,连线框选的区域即au区域的位置,最后将人脸划分为16个au区域,au区域的位置示意图如图4所示。表2具体是指:连接标注为17的关键特征点、标注为19的关键特征点、辅助点0、辅助点1,得到第1个au区域;连接标注为19的关键特征点、标注为21的关键特征点、辅助点1、辅助点2,得到第2个au区域;连接标注为22的关键特征点、标注为24的关键特征点、辅助点3、辅助点4,得到第3个au区域;连接标注为24的关键特征点、标注为26的关键特征点、辅助点4、辅助点5,得到第4个au区域;连接标注为39的关键特征点、标注为41的关键特征点、辅助点7、辅助点11,得到第5个au区域;连接标注为42的关键特征点、标注为46的关键特征点、辅助点8、辅助点12,得到第6个au区域;连接标注为21的关键特征点、标注为22的关键特征点、27的关键特征点、29的关键特征点、39的关键特征点、42的关键特征点、辅助点7、辅助点8,得到第7个au区域;连接标注为2的关键特征点、标注为3的关键特征点、辅助点7、辅助点11,得到第8个au区域;连接标注为29的关键特征点、标注为33的关键特征点、辅助点7、辅助点9,得到第9个au区域;连接标注为29的关键特征点、标注为33的关键特征点、辅助点8、辅助点10,得到第10个au区域;连接标注为13的关键特征点、标注为14的关键特征点、辅助点8、辅助点12,得到第11个au区域;连接标注为33的关键特征点、标注为59的关键特征点、辅助点9、辅助点13,得到第12个au区域;连接标注为33的关键特征点、标注为55的关键特征点、辅助点10、辅助点17,得到第13个au区域;连接标注为5的关键特征点、标注为6的关键特征点、标注为58的关键特征点、标注为59的关键特征点,得到第14个au区域;连接标注为10的关键特征点、标注为11的关键特征点、标注为55的关键特征点、标注为56的关键特征点,得到第15个au区域;连接标注为6的关键特征点、标注为8的关键特征点、标注为10的关键特征点、辅助点14、辅助点15、辅助点16,得到第16个au区域。使用farneback光流算法提取au区域内的光流特征,光流特征包括幅值特征和角度特征,幅值特征指的是相邻两帧图像某一像素处同一物体的移动距离,角度特征指的是相邻两帧图像某一像素处同一物体的移动方向,计算每个au区域内的光流幅值之和,即对au区域内的全部像素点处的光流幅值求和,并按照从大到小的顺序排序,设置代表性au区域的个数n=5,其中前n个光流幅值之和对应的au区域为最具代表性的au区域。步骤c中,根据被试独立的5折交叉验证法,将步骤a得到的包含人脸区域的图像序列根据样本的身份划分为5份,进行5次实验,每次选取一份作为测试集,其余部分作为训练集,得到k组微表情训练集和测试集。步骤d中,将预处理后的人脸图像序列送入au掩膜特征提取网络模型,au掩膜特征提取网络模型包括共享模型、分类器a及分类器b;au掩膜特征提取网络的整体流程如图1所示。为了更好地提取到具有代表性的au区域,使用双流的多任务学习进行au掩膜特征提取网络模型的训练,一流进行au区域和背景的粗糙二分类任务,另外一流进行代表性au区域和背景的精细二分类任务。具体来说,一流将输入的微表情图像序列输入到共享模型(sharedmodel)、分类器a(classifier_a),进行粗糙二分类,若当前像素属于16个au区域的所在区域,则标记为前景,否则为背景;另外一流输入到共享模型、分类器b(classifier_b)中,进行精细二分类,若当前像素属于最具代表性的5个au区域所在区域,则标记为前景,否则为背景。共享模型的网络结构为3d-fusionnet,如图5所示,图5中,c_in为输入通道数,c_out为输出通道数。共享模型包括编码器和解码器,其具体的内部网络参数如表3所示。共享模型的输入为c×l×w×h的图像序列,c为图像序列的通道数,l为图像序列的帧数,w、h分别为图像的宽和高;在本实施例中输入大小设置为3×16×224×224编码器包括3个下采样模块和1个桥接模块,每个下采样模块均包括3d卷积层、批归一化层、relu层以及最大池化层;经过下采样模块后的低分辨率特征,能够比较好地提取目标au在人脸图像的语义信息。解码器包括3个上采样模块,每个上采样模块均包括转置3d卷积层、3d卷积层、批归一化层以及relu层;使用3d卷积是为了从图像序列中直接提取样本的空间和时序特征。在编码器、解码器内部以及编码器和解码器之间均使用残差结构。残差结构能够很好地解决网络退化的问题,使网络更容易优化,同时将编码器低分辨率信息和解码器的高分辨率信息相加能够为分割au前景和背景提供更为精细的特征。表3分类器a和分类器b的网络结构相同,均包括两个3d卷积层和一个relu层。分类器a和分类器b的内部参数如表4所示。共享模型输出的特征,经过分类器a进行au区域和背景的粗分类,为了更加方便地划分前景和背景特征,使用两个通道分别表示前景通道和背景通道,在前景通道中,处于au区域的像素点标记为1,否则,处于背景区域的像素点标记为0;在背景通道中,处于背景区域的像素点标记为1,其余部分标记为0;分类器b的输出前景为代表性au区域的组合,其余部分为背景区域;需要注意的是,分类器b的输出图像特征的大小和输入图像的大小相同,输出图像特征的通道数变为2。表4为了进一步结合粗分类和细分类两个任务提取到的信息,使用空间注意力机制和时间注意力机制将分类器a的输出的和分类器b的输出加权,作为最终的掩膜特征:图6(a)为通道注意力机制模块的结构,output_a为分类器a的输出,output_b为分类器b的输出,将output_a的两个通道分开,前景通道记为pau,表示像素点属于au区域的概率,背景通道记为p背景,表示像素点属于背景部分的概率;为了得到每个通道的注意力权重,将pau和p背景变形成(l×w×h,1)的向量,output_b变形成(2,l×w×h)的向量,将这两个向量相乘,l1归一化得到注意力通道权重的值,通道注意力的实现如下式(1)、式(2)、式(3)、式(4)所示:wau=[λau,0·output_b,λau,1·output_b](3)w背景=[λ背景,0·output_b,λ背景,1·output_b](4)式(1)、式(2)、式(3)、式(4)中,re()表示变形操作,λau表示au特征在前景通道和背景通道的权值向量,λ背景表示背景特征在前景通道和背景通道的权值向量,且λau∈r2×1,λ背景∈r2×1,λau,i表示λau的第i个值,λ背景,i表示λ背景的第i个值,i∈{0,1},wau、w背景分别是指pau、p背景通道注意力加权之后的特征;图6(b)为空间注意力机制模块的结构,将通道注意力加权之后的特征wau、w背景与output_a相结合,具体的实现如式(5)所示:feature′(c,l,w,h)=pau(l,w,h)wau(c,l,w,h)+pau(l,w,h)w背景(c,l,w,h)(5)式(5)中,feature′(c,l,w,h)∈rc×l×w×h,c∈{0,1},l∈{0,1,...,l-1},w∈{0,1,...,w-1},h∈{0,1,...,h-1},feature′(c,l,w,h)经过一个卷积核为1×1×1的3d卷积层,得到最终的au掩膜特征,pau(l,w,h)指的是样本在第l帧的(w,h)像素处属于au的概率,wau(c,l,w,h)指的是经过au特征加权后的样本在第c个通道、第l帧的(w,h)像素处的特征值,w背景(c,l,w,h)指的是经过背景特征加权后的样本在第c个通道、第l帧的(w,h)像素处的特征值。在粗糙二分类即粗分类任务中,由于人脸的前景和背景比例相对均衡,因此,使用基于像素的交叉熵损失函数lcross,如式(6)所示:式(6)中,yc,l,w,h表示像素点(c,l,w,h)处的标签,c∈{0,1},分别代表前景通道和背景通道,output_ac,l,w,h表示粗分类任务的输出像素点(c,l,w,h)处为前景或背景的概率,经过神经网络的梯度反向传播,使得交叉熵损失不断减小。在精细二分类即细分类任务中,由于人脸的代表性au区域比背景占比小,因此,使用骰子损失(diceloss)函数s,骰子损失不需要给不同类别样本分配权重,来建立前景和背景像素点之间的平衡,该损失是一个基于骰子系数s的函数,骰子系数是一个范围在0到1之间的数值,用来衡量两个样本之间的相似程度,如式(7)所示:式(7)中,n=c×l×w×h,本实施例中n=2×16×224×224,pi表示细分类任务输出的某一像素在代表性au区域的预测概率,gi表示像素是否在代表性au区域的真值,δ是平滑参数,用来防止分母为0,本实施例中取值为1。骰子损失函数的目的是最大化基于骰子系数的目标函数,损失函数ldice如式(8)所示:ldice=1-s(8)最后的损失为二者损失的和,如式(9)所示:ltotal=lcross+ldice(9)。步骤e中,将步骤a处理后的包含人脸区域的图像序列送入训练好的au掩膜特征提取网络,分类器a输出全部au区域的掩膜,分类器b输出5个代表性au区域的掩膜,选择代表性au区域的掩膜与预处理后的包含人脸区域的图像相乘,得到只包含5个代表性au区域的人脸图像序列。步骤f中,使用步骤a的预处理方法处理宏表情视频,得到宏表情的人脸图像序列,将宏表情的人脸图像序列和步骤c得到的微表情训练集送入包含非局部模块的3d-resnet网络模型中;基础的3d-resnet网络由resnet(2d)修改而成,3d-resnet网络考虑了时间维度上帧间的运动信息,能更好地捕获序列的时间和空间特征。3d-resnet网络的具体结构如图7所示,图中n为微表情的类别数。内部参数如表5所示。表53d-resnet网络使用了残差的思想,网络由多个相似的残差块串联组成,残差块可以分为基本块(basicblock)和瓶颈块(bottleneckblock)两种,基本块(basicblock)的结构如图8所示。包含非局部模块的3d-resnet网络模型由多个残差块串联而成,残差块为基本块;其中,图8为基本块的结构,基本块的结构分两路,输入特征一路经过两个卷积核为3×3×3的3d卷积层和relu层提取特征,输入特征另一路经过卷积核为1×1×1的3d卷积层调整通道数,最后将两路提取的特征按元素相加,经过relu层,即得到基本块的输出。非局部操作可以捕获网络的长时依赖,是一种简洁高效的通用小组件,非局部操作的表示形式如式(10)、式(11)、式(12)所示:g(xj)=wgxj(12)式(10)、式(11)、式(12)中,x为输入图像序列的特征,j为输入特征所有可能的位置索引,i为输出位置索引,y为输出特征,尺寸与输入图像序列的大小相同,xi指的是图像序列在输出位置i处的特征,xj指的是图像序列在输出位置j处的特征,yi指的是输出特征在位置索引j处的值,c(x)为响应因子,g()为映射函数,g(xj)计算了xj处经过映射之后的特征,式(12)中的wg为可学习的权重矩阵;函数f(xi,xj)用于计算xi和xj的相似度;如式(10)、式(11)、式(12)的非局部操作包装成一个非局部模块,非局部模块的定义如式(13)所示:zi=wzyi+xi(13)式(13)中,wz为权重矩阵,zi为xi经过非局部操作之后的特征,式(13)采用了残差块结构,残差块的结构设计没有破坏原始的网络结构,其输入输出大小相同,因此可以方便地合并到许多现有的架构中。非局部模块的具体网络结构如图9所示。残差块结构包括4个1×1×1的3d卷积层,用于对特征的通道进行升维或者降维,为矩阵乘法操作,为矩阵元素相加操作。包含非局部模块的3d-resnet网络模型包括依次串联的5个残差块,非局部模块添加在包含非局部模块的3d-resnet网络模型中的第4个残差块中,即在3d-resnet的conv4_x部分,具体来说,第4个残差块的输入特征先经过3d卷积+bn+relu和3d卷积+bn操作,然后,将其输出的特征进行非局部操作,得到非局部操作之后的特征,接着将非局部操作之后的特征输入包含非局部模块的3d-resnet网络模型中的第5个卷积模块(conv5_x)进行后续的操作。如图9所示,输出特征x经过1×1×1的3d卷积、变形以及softmax操作之后,计算出输入特征中的自相关性信息,也就是说,得到了每帧中每个像素对其他所有帧所有像素的关系。对于刺激源的强度,人们会产生不同的情绪,如图10所示。当刺激源出现时,人们往往会先表现出惊讶情绪,如果事情有意义,就会产生满意情绪,进一步来说,如果事情对人产生了有利影响,就会产生开心情绪;如果事情没有产生攻击或威胁,并且对事情不喜欢或不同意,会让人产生厌恶情绪,如果事情对人产生了一定的攻击或威胁,就会产生愤怒情绪,如果事情给人造成了比较大的压力,超过了人的承受范围,会产生恐惧情绪,如果事情造成了无法挽回的结果,就会产生伤心情绪。从图10可以看出,随着刺激源强度的变化,人们可能从一种情绪转变成另一种情绪,且不同情绪存在与之相近的情绪,如表6所示。表6采取在线的跨模态四元组选择策略,选择宏表情相近的情绪类型作为异类样本,根据表6的选择策略,将一类微表情作为锚样本,在宏表情中选择同类情绪的样本作为宏表情正样本,在微表情中选择同类情绪的样本作为微表情正样本,选择宏表情中与之相近的情绪类型的样本作为宏表情负样本,构成跨模态四元组样本对,样本对之间满足以下约束,如下式(14)、式(15)、式(16)所示:式(14)、式(15)、式(16)中,f(x)表示样本x在3d-resnet网络的倒数第二个全连接层的输出,xa表示锚样本,表示与锚样本情绪相同的宏表情样本,表示与锚样本情绪相同的微表情样本,xn表示与锚样本情绪相近的宏表情样本,αi为边界参数,i∈{1,2,3};f(xa)代表xa在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,f(xn)代表xn在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出。图11给出了上述约束的可视化,图中,anchor代表锚样本,mac_neg代表与锚样本相邻标签的宏表情样本,mic_pos代表与锚样本同类的微表情样本,mac_pos代表与锚样本同类的宏表情样本。通过约束,保证锚样本和同类宏表情样本特征的距离小于锚样本和相邻情绪的宏表情样本特征的距离,锚样本和同类微表情特征的距离小于锚样本和同类宏表情特征的距离,锚样本和同类微表情特征样本的距离小于锚样本和相邻情绪的宏表情样本特征的距离。将上述约束整合起来,跨模态四元组损失的目标函数lcross-quad如式(17)所示:式(17)中,输入样本经过包含非局部模块的3d-resnet网络模型,输出样本的预测标签,记为a,a∈rn,n为表情的类别数,样本的真实标签表示成独热编码(one-hotencoding)的形式,记为y,y∈rn,具体来说,若样本属于第j类,则将真实标签y的第j位设置为1,其余位设置位为0,代表第i个锚样本,代表第i个与锚样本情绪相近的宏表情样本,代表第i个与锚样本情绪相同的微表情样本,代表第i个与锚样本情绪相近的宏表情样本,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出,代表在包含非局部模块的3d-resnet网络模型的倒数第二个全连接层的输出。接着,使用交叉熵损失函数lsoftmax评估预测标签和真实标签之间的差距,如式(18)所示:式(18)中,ai为样本预测为第i类的概率,i∈{1,2,...,n},yi为真实标签y在第i位的值;训练阶段总的损失函数为softmax交叉熵损失和跨模态四元组损失的和,如式(19)所示。ltotal=lsoftmax+lcross-quad(19)步骤g中,将步骤c得到的微表情测试集样本送入包含非局部模块的3d-resnet网络模型,使用交叉熵损失函数lsoftmax计算交叉熵损失,得到样本对应的微表情类别,计算正确分类的样本数占总样本数的比例,作为分类准确率。步骤h中,为了保证实验结果的准确性,采用被试独立的5折交叉验证法,重复5次实验,取5次实验的分类准确率的均值作为最终的分类准确率。本实施例在mmew数据库上进行实验,包含300个微表情视频片段和900个宏表情视频片段,视频是由山东大学的36名学生或老师,在实验室环境观看视频诱发产生,视频的帧率为90fps,分辨率为1920×1080,数据库包含6类基本的表情,分别为开心、惊讶、愤怒、厌恶、恐惧和伤心。本实施例将视频经过预处理得到人脸图像序列。提取人脸的关键点信息,得到人脸的au区域标签,计算每个au区域内的光流幅值之和,选取5个最具代表性的au区域。将样本输入到au掩膜特征提取网络中,网络将3d卷积层和全连接层的权重使用高斯分布初始化,偏置初始化为0,批归一化层的权重初始化为1,偏置初始化为0。优化器采用随机梯度下降(stochasticgradientdescent,sgd)方法,动量(momentum)设置为0.9,权重衰减值设置为0.0005,学习率初始值设置为0.001,每20个训练周期之后,学习率下降为原来的0.98,批大小(batchsize)设置为8。本实施例在ubuntu18.04.5操作系统上完成,使用了4块nvidiatitanv显卡。算法采用python语言实现,网络结构使用pytorch1.7.1框架。本实施例采用像素准确率的评价准则,如式(20)所示。式(20)中,正类代表au所在的前景区域,负类代表背景区域。tp为正确预测为正类的像素数,fp为负类错误预测为正类的像素数,tn为正确预测为负类的像素数,fn为正类错误预测为负类的像素数。本实施例给出了粗分类任务和细分类任务的像素准确率,如表7所示。mmew数据库的粗分类像素准确率达到了93.6%,细分类像素准确率为69.2%。表7数据库粗分类的像素准确率细分类的像素准确率mmew93.6%69.2%图12和图13分别为本实施例在au掩膜特征提取网络的准确率和损失曲线,其中,task1代表粗分类任务,task2代表细分类任务。图14和图15给出了示例样本在粗分类和细分类的au区域提取结果。最终mmew数据库的微表情识别率为63.2%,图16给出了最优参数下的混淆矩阵,从图16中可以看出,厌恶、开心、惊讶、愤怒四类表情大部分能够识别正确。表8给出了几种实验方法与本发明在mmew数据库上的实验结果。表8从表8可以看出,本发明提出的算法在mmew数据库上取得了最优的效果,这是因为本发明提取了具有代表性的au区域,去除了与微表情无关的冗余信息,因此,具有更好的效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1