VVP文件的预分析方法、计算机可读存储介质与流程
vvp文件的预分析方法、计算机可读存储介质
技术领域
1.本发明涉及vvp文件内容的分析技术,尤其涉及一种vvp文件的预分析方法。
背景技术:
2.在对门级电路进行仿真处理的过程中,对verilog(verilog hdl,一种硬件描述语言,可以表示逻辑电路图)的分析必不可少。
3.vvp文件作为iverilog(icarus verilog的简称,号称“全球第四大”数字芯片仿真器,也是一个完全开源的仿真器)独有的文件,具有独特的分析价值。vvp是该开源通用eda工具中所生成的一种类汇编可执行格式,其程序本身是一种解释器,只是以.vvp文件作为输入。vvp输入文件的生成由 /tgt
‑
vvp 负责。因此,尽管语法可读,但是对于使用者来说,读起来并不是很方便,在这一环节会导致仿真效率较低。
技术实现要素:
4.为了解决现有技术中处理的vvp文件让使用者读起来不方便的技术问题,本发明提出一种vvp文件的预分析方法、计算机可读存储介质。
5.本发明提出的vvp文件的预分析方法,包括:步骤1,对vvp文件的官方文档进行解析,以生成vvp文件的识别规则;步骤2,根据所述识别规则对vvp文件的语句进行语法分析,将经过语法分析识别出来的字段根据其类别备注相应的类别标签并存储为索引;步骤3,根据所述索引读取所述vvp文件的语句,找到所述vvp文件所有逻辑门以及逻辑门之间的驱动与被驱动关系并输出。
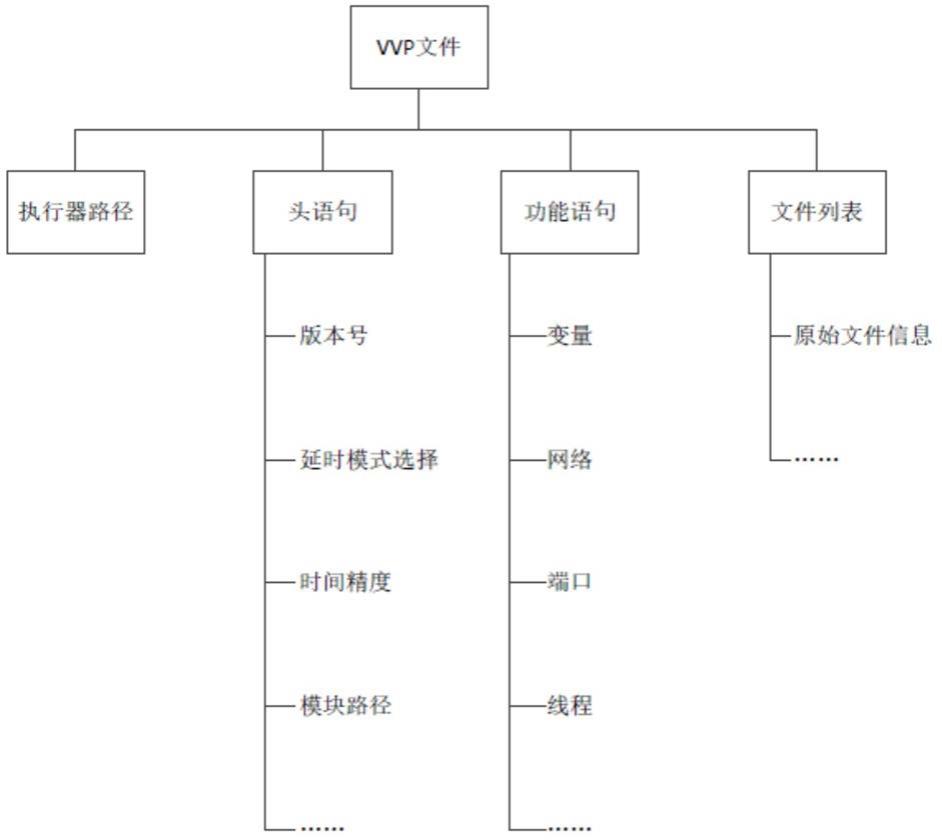
6.进一步,所述步骤1中对vvp文件的官方文档进行解析具体为将vvp文件划分为执行器路径、头语句、多个模块以及文件列表。
7.进一步,所述步骤3包括:步骤3.1,根据所述索引找到包含逻辑门的一条语句,将该语句作为当前语句,该逻辑门作为当前逻辑门;步骤3.2,在当前语句中查找当前逻辑门的输入信息;步骤3.3,在当前语句以外的其他语句中查找当前逻辑门的输出信息;步骤3.4,查看当前语句所在的模块;步骤3.5,将步骤3.2至步骤3.4所查找到的内容整理形成当前逻辑门的逻辑单元并输出至json文件,返回步骤3.1读取所述vvp文件的下一条语句,直至所有逻辑门的逻辑单元被输出。
8.进一步,所述类别标签包括:header、label、opcode、operand、comment、filename。
9.进一步,所述步骤3.5中将步骤3.2至步骤3.4所查找到的内容整理形成当前逻辑门的逻辑单元并输出具体包括:当找到类别标签为opcode且字段的内容为.functor的语句时将其作为包含逻辑
门的一条语句,且该语句为当前语句,.functor所指向的逻辑门为当前逻辑门;读取当前逻辑门的label,并按预设格式输出到json文件;读取当前语句的第一个operand,在该operand中空格之前的内容按预设格式输出当前逻辑门的functor类型,然后按预设格式输出第一个operand中空格之后的内容为所对应的输入位宽;读取当前语句的第二个operand一直到分号前的内容作为当前逻辑门的输入并按预设格式输出到json文件;在其他含有.functor的语句的operand列表中搜索当前逻辑门的label,若匹配,则该匹配的逻辑门作为被驱动的逻辑门,取出被驱动的逻辑门的label,输出到json文件中当前逻辑门的驱动列表中;查看当前语句所在的模块,并按预设格式输出到json文件中。
10.进一步,所述索引具体为将所述识别出来的字段与其对应的类别标签通过键值对进行存储。
11.进一步,所述识别规则包括:构成label的语法规则,构成opcode的语法规则,构成operand的语法规则,构成vvp文件中每一条语句的语法规则,构成头语句的语法规则。
12.进一步,所述识别规则分别采用铁路图表示。
13.本发明提出的计算机可读存储介质,用于存储计算机程序,当所述计算机程序被至少一个处理器运行时,执行上述技术方案所述的vvp文件的预分析方法。
14.本发明实现了自动vvp文件的解析,并生成带有逻辑关系的json文件输出,使得使用者可以清楚门级电路的每一个逻辑单元的驱动与被驱动关系,解决了verilog hdl文件的rtl级描述转化为门级电路网格表达的难题。
附图说明
15.下面结合实施例和附图对本发明进行详细说明,其中:图1是本发明所分析得到的vvp文件结构。
16.图2是本发明构成label的语法规则的铁路图。
17.图3是本发明构成opcode的语法规则的铁路图。
18.图4是本发明构成operand的语法规则的铁路图。
19.图5是本发明构成vvp文件中每一条语句的语法规则的铁路图。
20.图6是本发明构成头语句的语法规则的铁路图。
21.图7是本发明的逻辑单元的输出示例。
22.图8是本发明的索引存储示意图。
具体实施方式
23.为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
24.由此,本说明书中所指出的一个特征将用于说明本发明的一个实施方式的其中一个特征,而不是暗示本发明的每个实施方式必须具有所说明的特征。此外,应当注意的是本
说明书描述了许多特征。尽管某些特征可以组合在一起以示出可能的系统设计,但是这些特征也可用于其他的未明确说明的组合。由此,除非另有说明,所说明的组合并非旨在限制。
25.下面结合附图以及实施例对本发明的原理进行详细说明。
26.本发明提出的vvp文件预分析方法,需要先基于对vvp文件的官方文档进行解析,生成相应的vvp文件的识别规则。不同的vvp文件具有不同的官方文档,通过对vvp文件的官方文档的分析,本发明发现可以将vvp文件的内容进行分类划分,如图1所示,vvp文件的内容可以划分为四个部分,第一行为执行器路径,之后是头语句,以冒号开头;后面是各个模块(scope),每一个模块中包含各种功能语句,文件末尾存在文件列表,用来存放原始文件信息。
27.vvp文件中的各个模块是由多条语句所组成,每个scope块中包含变量定义、端口信息、功能语句以及事件族语句等,然后本发明发现每条语句的组成成分可以分为标签(label)、指令(opcode)、运算(operand)、注释(comment)、文件列表(filename)等。基于本发明对vvp官方文档的解析所发现的规律,生成相应的vvp文件的识别规则,在本实施例中,识别规则包含了构成label的语法规则、构成opcode的语法规则、构成operand的语法规则、构成vvp文件中每一条语句的语法规则,构成头语句的语法规则。并且本发明把这些语法规则通过语法的铁路图来进行表示,使得vvp文件的语法更为直观。通过这些规则可以自动识别相应字段的类别,从而对其进行归类,存储为索引,以便于在后期查找门单元之间逻辑关系时,可以快捷找到对应的内容。
28.图2为通过铁路图表达构成label的语法规则,其中label starter 代表构成 label 的起始符号( 因为label不能以数字和小数点开头),digit 代表数字(0~9), letter代表字母( aa
‑
zz ),special symbol 代表特殊符号($<>_./)。
29.图3为通过铁路图表达构成opcode的语法规则,其中"% or ." 代表 opcode 的起始标志为
ꢀ“
%
”ꢀ
(百分号) 或
ꢀ“
." (小数点) ,special symbol 代表特殊符号 ($<>_./),letter代表字母( aa
‑
zz )。
30.图4为通过铁路图表达构成operand的语法规则,其中digit 代表数字(0~9), letter代表字母( aa
‑
zz ),special symbol 代表特殊符号($<>_./),operand可以由数字、字母或者是特殊符号任意一种开始表示,然后后续的内容可以是数字、字母以及特殊符合之间的任意组合。
31.图5为通过铁路图表达构成vvp文件中每一条语句的语法规则,其中一条语句可以仅由一个 label 组成;也可以由opcode、label、operand组成。每一条语句";"后都可以添加注释(comment)。
32.图6为通过铁路图表达构成头语句的语法规则,其中头语句以 ":" (冒号)开头,可以仅由 letter (aa~zz) 组成;也可以由digit、letter、special symbol组 成。每一条语句";"后都可以添加 comment (注释)。
33.通过上述语法规则的铁路图,实现了对语法的可视化操作,更加便于使用者的理解。
34.在得到上述vvp文件的识别规则之后,根据这些识别规则对vvp文件的语句进行语法分析,然后将经过语法分析识别出来的字段根据其类别备注相应的类别标签并存储为索
引。在本实施例中,索引以键
‑
值对的方式进行存储,类别标签可以包括:header、label、opcode、operand、comment、filename,索引存储后的表现形式可以如图8所示,图8显示的是一条vvp语句经过分析后的输出结果,其中type为类别标签,string为具体的内容。
35.具体实现时,以python语言为例,通过设计一个parser类以及对应的token类,通过parser类完成词法分析功能和对各个token的格式化输出,即在parser类中对分出来的token进行制作,之后再返回token值,使得返回的token值可以形成索引。下面是对parser类及token类编写的解释,其中parser类完成的功能是读取输入进来的文本并进行语法分析。
36.在得到可以读懂vvp文件内容的索引之后,根据索引读取vvp文件的语句,找到vvp文件所有逻辑门以及逻辑门之间的驱动与被驱动关系并输出。
37.具体实施时,包括以下步骤:步骤3.1,根据所述索引找到包含逻辑门的一条语句,将该语句作为当前语句,该逻辑门作为当前逻辑门;步骤3.2,在当前语句中查找当前逻辑门的输入信息;步骤3.3,在当前语句以外的其他语句中查找当前逻辑门的输出信息;步骤3.4,查看当前语句所在的模块;步骤3.5,将步骤3.2至步骤3.4所查找到的内容整理形成当前逻辑门的逻辑单元并输出至json文件,返回步骤3.1读取所述vvp文件的下一条语句,直至所有逻辑门的逻辑单元被输出。
38.上述步骤通过两个迭代循环来找到所有逻辑门之间的驱动与被驱动关系。具体在实施时,以找到一个逻辑门与其他逻辑门的驱动与被驱动关系所形成的逻辑单元为例。当找到类别标签为opcode且字段的内容为.functor的语句时将其作为包含逻辑门的一条语句,且该语句为当前语句,.functor所指向的逻辑门为当前逻辑门,读取当前逻辑门的label,然后按预设格式输出到json文件;读取当前语句的第一个operand,在该operand中空格之前的内容按预设格式输出当前逻辑门的functor类型,然后按预设格式输出第一个operand中空格之后的内容为所对应的输入位宽;读取当前语句的第二个operand一直到分号前的内容作为当前逻辑门的输入并按预设格式输出到json文件;在其他含有.functor的语句的operand列表中搜索当前逻辑门的label,若匹配,则该匹配的逻辑门作为被驱动的逻辑门,取出被驱动的逻辑门的label,输出到json文件中当前逻辑门的驱动列表中;查看当前语句所在的模块,并按预设格式输出到json文件中。
39.图7为经过本发明分析之后,最终输出形成的具有逻辑关系的每个逻辑门的详细信息以及对应的模块。基于图7所输出的结果将会更加有助于使用者去理解vvp文件,有助于提高研发效率。
40.本发明还保护对应的计算机可读存储介质,该计算机可读存储介质用来存储计算机程序,当计算机程序运行时执行上述的vvp文件预处理方法。
41.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1