一种基于多客户端协同的分布式文件系统、方法和客户端与流程
本发明涉及文件处理技术领域,特别涉及一种基于多客户端协同的分布式文件系统、方法和客户端。
背景技术:
在大数据时代,数据量呈指数爆炸式增长,对存储系统提出了很大的挑战。目前常见的元数据的组织管理方式主要有三种:(1)集中式元数据管理;(2)分布式元数据管理;(3)无元数据管理。为实现数据访问的高吞吐率,许多系统采用专用的元数据服务器,当用户访问系统时,先从元数据服务器中获得访问许可、文件元数据信息,如数据位置和文件属性,然后直接访问文件内容。此外,一些系统为了摒弃单一元数据带来的隐患,采用无元数据的架构。由于存储需求的快速增长,随着文件数增长到一定规模后,系统面临一系列问题,主要包括:1)元数据目录遍历性能瓶颈,比如ls某个目录时需要等待的时间特别长。2)写文件慢。主要是因为客户端写完文件后都是通过网络直接上传到服务器,已有的解决方案实现了基于文件级的去重,可以减小上传所需的带宽,但缺少数据块级的去重。3)缺少多客户端之间的数据实时访问。当某个文件正在写入时,其他客户端要访问该文件需要等待文件同步到服务器端才可以访问。
技术实现要素:
为此,需要提供一种基于多客户端协同的分布式文件系统,用以解决现有分布式文件系统的元数据访问慢、文件实时写入慢、多客户端实时数据无法完整访问等问题。具体技术方案如下:
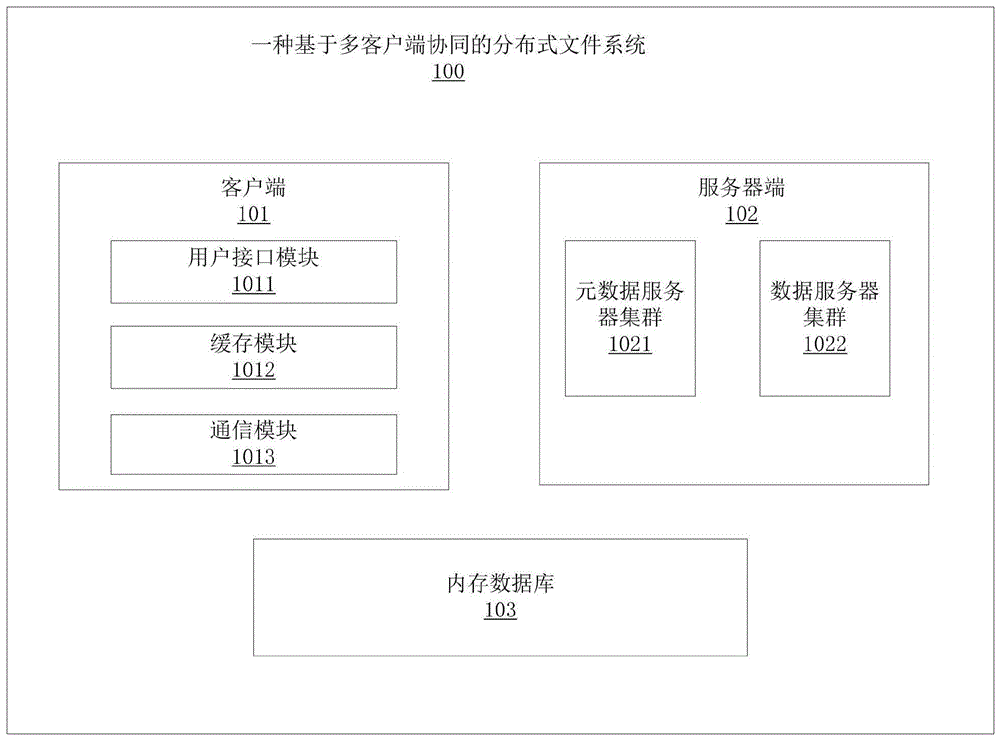
一种基于多客户端协同的分布式文件系统,包括:服务器端、客户端和内存数据库;
所述服务器端包括:元数据服务器集群和数据服务器集群,所述元数据服务器集群和数据服务器集群分别单独提供独立的卷给客户端挂载使用;
所述客户端包括:用户接口模块、缓存模块和通信模块,所述客户端的文件为分块写入;
所述内存数据库用于:记录上传数据服务器的文件的数据块分块信息和分布信息。
进一步的,所述元数据服务器为ssd磁盘;
所述数据服务器为sata磁盘;
所述内存数据库采用key-value技术。
进一步的,所述元数据服务器集群基于gluster分布式文件系统建立一个metadata卷;
所述数据服务器集群基于gluster分布式文件系统建立一个realdata卷;
所述客户端的缓存模块采用lru算法。
为解决上述技术问题,还提供了一种基于多客户端协同的分布式文件方法,具体技术方案如下:
一种基于多客户端协同的分布式文件方法,包括步骤:
客户端响应数据写入指令,按预设规则对数据进行分块;
将分块后的数据写入至缓存层;
当客户端本地缓存使用空间超过定义的阀值,客户端后台将自动启动文件数据上传数据服务器进程,当客户端响应分块后的数据上传至数据服务器的指令时,判断内存数据库中是否存在该数据块的指纹记录,若不存在该数据块的指纹记录,则将该条数据块信息插入至内存数据库中,并上传该条数据块至数据服务器;
若存在该数据块的指纹记录,则在内存数据库中更新记录,将该数据块引用计数增1,并不上传该条数据块至数据服务器。
进一步的,还包括步骤:
客户端响应文件读取指令,通过元数据服务器获取文件的元数据信息、文件上传数据服务器完成状态和创建该文件所在的客户端信息;
若所述文件上传数据服务器完成状态为未完成,则根据所述创建该文件所在的客户端信息与所述创建该文件所在的客户端建立连接,获取所述创建该文件所在的客户端上的最新文件内容。
进一步的,还包括步骤:
若所述文件上传数据服务器完成状态为完成,则根据所述文件的标识信息查询内存数据库,获取文件当前的分块信息及数据块所在数据服务器信息;
客户端与所述数据块所在数据服务器建立连接,获取所有数据块。
进一步的,所述“客户端响应数据写入指令,按预设规则对数据进行分块”前具体还包括步骤:
通过客户端的用户接口模块将写入请求发送给元数据服务器集群;
所述元数据服务器集群接收所述写入请求,记录对应文件的元数据信息,并返回确认信息至客户端;
客户端接收所述确认信息,并开始响应数据写入指令。
进一步的,所述客户端的缓存模块采用lru算法。
进一步的,所述“并上传该条数据块至数据服务器”后,还包括步骤:
当文件的所有分块数据完成上传处理,客户端对应更新该文件在元数据服务器上传状态信息。
为解决上述技术问题,还提供了一种客户端,具体技术方案如下:
一种客户端,所述客户端包括:用户接口模块、缓存模块和通信模块;
通过客户端的用户接口模块将写入请求发送给元数据服务器集群;
客户端接收所述元数据服务器集群返回的确认信息,并开始响应数据写入指令,按预设规则对数据进行分块,将分块后的数据写入至缓存层;
当客户端本地缓存使用空间超过定义的阀值,客户端后台将自动启动文件数据上传数据服务器进程,当客户端响应分块后的数据上传至数据服务器的指令时,客户端根据内存数据库中是否存在该数据块的指纹记录执行不同操作;
所述“客户端根据内存数据库中是否存在该数据块的指纹记录执行不同操作”,具体还包括步骤:
若不存在该数据块的指纹记录,则将该条数据块信息插入至内存数据库中,并上传该条数据块至数据服务器;
若存在该数据块的指纹记录,并不上传该条数据块至数据服务器。
当文件的所有分块数据完成上传处理,客户端对应更新该文件在元数据服务器上传状态信息。
本发明的有益效果是:一种基于多客户端协同的分布式文件系统,包括:服务器端、客户端和内存数据库;所述服务器端包括:元数据服务器集群和数据服务器集群,所述元数据服务器集群和数据服务器集群分别单独提供独立的卷给客户端挂载使用,从而实现文件与文件的目录信息的完全分离,进而加快元数据查询访问。所述客户端包括:用户接口模块、缓存模块和通信模块,通过增加缓存模块,解决了实时数据写入慢的问题。所述客户端的文件为分块写入,实现了基于数据块的去重上传功能,节省带宽。所述内存数据库用于:记录文件的数据块分块信息和分布信息。所述多客户端协同,解决多客户端实时数据无法完整访问问题。
附图说明
图1为具体实施方式所述一种基于多客户端协同的分布式文件系统的模块示意图;
图2为具体实施方式所述一种基于多客户端协同的分布式文件系统的示意图;
图3为具体实施方式所述一种基于多客户端协同的分布式文件方法写入数据的流程图;
图4为具体实施方式所述一种基于多客户端协同的分布式文件方法读取数据的流程图;
图5为具体实施方式所述内存数据库集群高一致性方法示意图;
图6为具体实施方式所述一种客户端的模块示意图。
附图标记说明:
100、一种基于多客户端协同的分布式文件系统,
101、客户端,
1011、用户接口模块,
1012、缓存模块,
1013、通信模块,
102、服务器端,
1021、元数据服务器集群,
1022、数据服务器集群,
103、内存数据库,
600、客户端。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
请参阅图1至图2,首先对本实施方式中会涉及到的一些缩略语做以下说明:
raft:工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。
redis:一种基于键值对(key-value)数据库,其中value可以为string、hash、list、set、zset等多种数据结构,可以满足很多应用场景。
lru:(leastrecentlyused),最常见一种链表保存缓存数据算法,根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
以下对一种基于多客户端协同的分布式文件系统100的具体实施方式展开说明:
实施例1:
如图1和图2所示,一种基于多客户端协同的分布式文件系统100,包括:服务器端102、客户端101和内存数据库103;所述服务器端102包括:元数据服务器集群1021和数据服务器集群1022,所述元数据服务器集群1021和数据服务器集群1022分别单独提供独立的卷给客户端101挂载使用;所述客户端101包括:用户接口模块1011、缓存模块1012和通信模块1013,所述客户端101的文件为分块写入;所述内存数据库103用于:记录上传数据服务器的文件的数据块分块信息和分布信息。
其中元数据服务器集群1021主要用于维护元数据并负责控制垃圾回收、负载均衡等功能,元数据服务器采用ssd磁盘,加快数据的访问速度;数据服务器集群1022负责保存数据以及接收处理数据i/o请求,数据服务器采用sata磁盘,提供大容量存储。特别地,元数据服务器和数据服务器集群1022分别单独提供独立的卷,提供给客户端101挂载使用,从而实现文件和文件的目录信息的完全分离。元数据服务器只存储一个文件的标识信息,通过该标识结合内存数据库103,获取文件当前的分块信息以及文件分块所在的数据服务器信息。作为一种可行的方案,这里可以基于gluster分布式文件系统,元数据集群建立一个metadata卷,数据服务器集群1022建立一个realdata卷。
用户接口模块1011提供客户端101挂载功能,客户端101可通过该模块分别挂载元数据卷和数据存储卷。缓存模块1012提供数据缓存服务,客户端101本地数据写入时将会先写到该层中,之后再进行上传。通过增加缓存模块1012,解决了数据写入慢的问题。缓存模块1012使用ssd磁盘,因此要求客户端101至少配置一块ssd磁盘。所述客户端101的缓存模块1012采用lru算法。通信模块1013主要处理客户端101与服务器以及内存数据库103之间的通信。
所述分块信息,包括每个数据块归属的文件标识信息,数据块指纹信息,数据块引用计数信息等;所述分布信息,指每个数据块存在哪个存储服务器上等信息。该数据库采用基于key-value的内存数据库103技术,同时结合raft协议,实现高可用性。
一种基于多客户端101协同的分布式文件系统,包括:服务器端102、客户端101和内存数据库103;所述服务器端102包括:元数据服务器集群1021和数据服务器集群1022,所述元数据服务器集群1021和数据服务器集群1022分别单独提供独立的卷给客户端101挂载使用,从而实现文件与文件的目录信息的完全分离,进而加快元数据查询访问。所述客户端101包括:用户接口模块1011、缓存模块1012和通信模块1013,通过增加缓存模块1012,解决了实时数据写入慢的问题。所述客户端101的文件为分块写入,实现了基于数据块的去重上传功能,节省带宽。所述内存数据库103用于:记录文件的数据块分块信息和分布信息。所述多客户端101协同,实现多客户端101实时数据无法完整访问问题。
实施例2
实际应用中,基于所述一种基于多客户端101协同的分布式文件系统进行数据上传的实施方式如下:
当有数据写入时,首先通过客户端101的用户接口模块1011将写入请求发送给元数据服务器集群1021,如文件的属主、时间、以及文件大小、创建此文件客户端101、文件上传数据服务器完成状态等信息。需要注意的是,文件大小只是记录在文件扩展属性中的信息,没有具体文件数据,不占用磁盘空间。元数据服务器集群1021收到该请求后,记录下该文件的元数据信息,并返回给客户端101确认消息。客户端101收到确认消息后,开始数据写入,首先将数据按分块(如4m)方式写入到本地缓存模块1012,待写入到一定大小时,进行数据上传。在上传时,使用数据去重传输的方法,首先访问内存数据库103中是否存在此数据块的指纹信息记录,如果不存在,则将此条数据块信息插入到内存数据中,然后上传该数据块到数据服务器中;如果存在,则只是在数据库中更新下记录,将数据块引用计数增加1,而不再进行上传数据。直至客户端101上整个文件全部写完,从而完成整个文件的上传。客户端101的缓存模块1012采用lru算法进行管理,当缓存满时,老的数据首先会被清除。
新的数据块信息插入到内存数据时,数据信息存取方式采用key-value方式,key为数据块名,value值包含了数据块的所属文件标识信息,数据块指纹信息,数据块引用计数信息,以及数据块存入数据服务器的分布信息。
服务器端102收到数据块写入请求后,将数据块进行落盘。
客户端101将整个文件的数据块全部上传,然后更新元数据该文件上传状态信息,从而完成整个文件的上传。
实施例3
实际应用中,基于所述一种基于多客户端101协同的分布式文件系统进行数据读取的实施方式如下:
当客户端101读取数据时,首先访问元数据服务器,获取文件的标识信息。之后通过文件的标识信息,客户端101查询内存数据库103,获取文件当前的分块信息,获取数据块所在数据服务器信息,然后客户端101分别跟文件的数据块所在的数据服务器建立链接,最终获取所有数据块。之后再在客户端101上合成数据,完成整个文件的拉取。
实施例4
实际应用中,基于所述一种基于多客户端101协同的分布式文件系统进行数据读取时,还会出现一个特殊情况,如下:
当文件在写入过程中,如果有其他客户端101访问该文件,则首先会访问元数据库集群获取文件的元数据信息,以及此文件上传数据服务器完成状态,以及创建该文件所在的客户端101信息。如果,该文件未完成上传数据服务器,此时其他客户端101根据获取的创建该文件所在的客户端101信息,跟此客户端101通信,以此获取该客户端101上最新的文件内容。
如:通过多客户端101之间的信息协同,实现多客户端101实时数据快速访问。传统分布式文件系统中,客户端101访问数据时都需要向服务器端102进行询问,之后从数据服务器上拉取数据。然而对于多客户端101实时访问数据的场景下,如果客户端a101正在写某一个文件,而此时客户端b101想要访问这个文件,由于客户端a101尚未写完该文件,导致该文件的内容未能上传到服务器中,此时客户端b101无法从服务器访问到该文件的内容。本专利中提出的方法,通过在客户端101上增加缓存模块1012,以及用于全局的元数据服务器,可以实现数据的实时访问。具体的,客户端a101的文件已经写入本地缓存模块1012,但未上传到数据服务器,当客户端b101访问该文件时,先从全局的元数据服务器获取此文件上传完成状态、以及创建此文件的客户端a101信息,如果此文件未完成上传,则客户端b101直接跟客户端a101建立链接,直接访问该文件,从而实现了文件的实时访问。
需要说明的是,在本实施方式中,以上所有的数据库集群均为基于key-value,实现高可用的文件快速检索查询。本实施方式中提出的key-value数据库集群是一种基于raft协议的redis数据库集群。该集群集合了redis内存数据库103的优点,以key-value方式提供数据快速检索,同时可以利用raft协议,实现高可用性。
实施例5
再如图5所示,本实施方式的内存数据库103高可用方法如下:
1)该高可用内存数据库103由3台服务器组成,三台服务器中一台为主服务器,另外两台为副服务器。主服务器的选取采用投票方法,假设在本实例中,服务器a被选为主服务器,服务器b和服务器c选为副服务器。
2)此时,客户端101的请求由服务器a进行响应。
3)服务器a响应完客户端101的请求后,会将客户端101发来的文件信息同步给服务器b和c。
4)当服务器a发生故障时,通过raft算法,假设本实例中最终选举服务器b作为主服务器。此时,客户端101将与服务器b重新建立连接。
5)服务器b将最新的文件信息同步给服务器c。
6)当服务器a恢复后,服务器b会将最新的数据同步给服务器a,实现数据库的一致性。
请参阅图2至图5,在本实施方式中,一种基于多客户端协同的分布式文件方法可应用在如图2所示的一种基于多客户端协同的分布式文件系统上。
具体实施方式如下:
实施例6
请参阅图3,进行数据的写入:
步骤s301:客户端响应数据写入指令,按预设规则对数据进行分块。该步骤前还可包括步骤:通过客户端的用户接口模块将写入请求发送给元数据服务器集群;所述元数据服务器集群接收所述写入请求,记录对应文件的元数据信息,如文件的属主、时间、以及文件大小、创建此文件客户端、文件上传数据服务器完成状态等信息。需要注意的是,文件大小只是记录在文件扩展属性中的信息,没有具体文件数据,不占用磁盘空间。元数据服务器集群收到该请求后,记录下该文件的元数据信息,并返回确认信息至客户端;客户端接收所述确认信息,并开始响应数据写入指令。
步骤s302:将分块后的数据写入至缓存层。如每块为4m写入到本地缓存模块。
步骤s303:当客户端本地缓存使用空间超过定义的阀值,客户端后台将自动启动文件数据上传数据服务器进程,进行数据上传。响应分块后的数据上传至数据服务器的指令,判断内存数据库中是否存在该数据块的指纹记录。
步骤s304:若存在该数据块的指纹记录,则在内存数据库中更新记录,将该数据块引用计数增1,并不上传该条数据块至数据服务器。
步骤s305:若不存在该数据块的指纹记录,则将该条数据块信息插入至内存数据库中,并上传该条数据块至数据服务器。客户端的缓存模块采用lru算法进行管理,当缓存满时,老的数据首先会被清除。启动线程实时扫描该数据库,根据文件的打开和关闭时间状态,向服务器更新数据。
新的数据块信息插入到内存数据时,数据信息存取方式采用key-value方式,key为数据块名,value值包含了数据块的所属文件标识信息,数据块指纹信息,数据块引用计数信息,以及数据块存入数据服务器的分布信息。
步骤s306:服务器端收到数据块写入请求后,将数据块进行落盘。
步骤s307:客户端将整个文件的数据块全部上传,然后更新元数据该文件上传状态信息,从而完成整个文件的上传。
实施例7
请参阅图4,进行数据的读取:
步骤s401:客户端响应文件读取指令,通过元数据服务器获取文件的元数据信息、文件上传数据服务器完成状态和创建该文件所在的客户端信息。
步骤s402:所述文件上传数据服务器完成状态是否为已完成。
若是,则执行步骤s403:则根据所述文件的标识信息查询内存数据库,获取文件当前的分块信息及数据块所在数据服务器信息。
步骤s404:客户端与所述数据块所在数据服务器建立连接,获取所有数据块。
若否,则执行步骤s405:则根据所述创建该文件所在的客户端信息与所述创建该文件所在的客户端建立连接。
步骤s406:获取所述创建该文件所在的客户端上的最新文件内容。
具体如:
客户端a通过用户接口模块向元数据服务器发起文件读出请求。
元数据服务器返回获取文件的标识信息,以及该文件上传数据服务器完成状态。如果该文件未完成上传,则返回该文件正在写入的客户端b。之后,客户端a与客户端b建立连接,获取该文件的信息。如果已经完成上传,则进入以下步骤。
客户端通过文件的标识信息,客户端查询内存数据库,获取文件当前的分块信息,获取数据块所在存储服务器信息。
客户端分别跟数据块所在的存储服务器建立连接,最终获取所有数据块。
在客户端上整合数据块信息,完成整个文件的拉取。
实施例8
再如图5所示,本实施方式的内存数据库高可用方法如下:
1)该高可用内存数据库由3台服务器组成,三台服务器中一台为主服务器,另外两台为副服务器。主服务器的选取采用投票方法,假设在本实例中,服务器a被选为主服务器,服务器b和服务器c选为副服务器。
2)此时,客户端的请求由服务器a进行响应。
3)服务器a响应完客户端的请求后,会将客户端发来的文件信息同步给服务器b和c。
4)当服务器a发生故障时,通过raft算法,假设本实例中最终选举服务器b作为主服务器。此时,客户端将与服务器b重新建立连接。
5)服务器b将最新的文件信息同步给服务器c。
6)当服务器a恢复后,服务器b会将最新的数据同步给服务器a,实现数据库的一致性。
通过客户端响应数据写入指令,按预设规则对数据进行分块;将分块后的数据写入至缓存层;响应分块后的数据上传至数据服务器的指令,判断内存数据库中是否存在该数据块的指纹记录,若不存在该数据块的指纹记录,则将该条数据块信息插入至内存数据库中,并上传该条数据块至数据服务器;若存在该数据块的指纹记录,则在内存数据库中更新记录,将该数据块引用计数增1,并不上传该条数据块至数据服务器。所述客户端的文件为分块写入,实现了基于数据块的去重上传功能,节省带宽。
请参阅图6,在本实施方式中,一种客户端600的具体实施方式如下:
一种客户端600,所述客户端600包括:用户接口模块、缓存模块和通信模块;
通过客户端600的用户接口模块将写入请求发送给元数据服务器集群;
客户端600接收所述元数据服务器集群返回的确认信息,并开始响应数据写入指令,按预设规则对数据进行分块,将分块后的数据写入至缓存层;
客户端600响应分块后的数据上传至数据服务器的指令,客户端600根据内存数据库中是否存在该数据块的指纹记录执行不同操作;
所述“客户端600根据内存数据库中是否存在该数据块的指纹记录执行不同操作”,具体还包括步骤:
若不存在该数据块的指纹记录,则将该条数据块信息插入至内存数据库中,并上传该条数据块至数据服务器;
若存在该数据块的指纹记录,并不上传该条数据块至数据服务器。
当文件的所有分块数据完成上传处理,客户端600对应更新该文件在元数据服务器上传状态信息。
在上述客户端600中,所述客户端600的文件为分块写入,实现了基于数据块的去重上传功能,节省带宽。此外通过增加缓存模块,解决了实时数据写入慢的问题。所述多客户端600协同,实现多客户端600实时数据无法完整访问问题。
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!