使用点对点连接的通道卷积引擎的分组卷积的制作方法
使用点对点连接的通道卷积引擎的分组卷积
1.发明背景
2.使用神经网络可以解决一整类复杂的人工智能问题。由于这些问题通常是计算和数据密集型的,硬件解决方案通常有利于提高神经网络的性能。人工智能问题的解决方案通常可以使用基于硬件的解决方案来更快地解决,这些基于硬件的解决方案优化了传统卷积运算的求解。创建与求解传统卷积运算兼容的硬件平台,同时还显著提高求解其他不同类型卷积运算(包括分组卷积运算)的性能和效率,是一项技术挑战。因此,存在对一种硬件和数据路径解决方案的需求,该解决方案提高了有效计算解决某些复杂人工智能问题所需的分组卷积(grouped convolution)运算的能力,而不会引入显著的复杂性和限制。
3.附图简述
4.在以下详细描述和附图中公开了本发明的各种实施例。
5.图1是示出使用神经网络解决人工智能问题的系统的实施例的框图。
6.图2是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。
7.图3是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。
8.图4是示出用于使用神经网络解决人工智能问题的通道卷积引擎的实施例的框图。
9.图5是示出用于解决分组卷积问题的过程的实施例的流程图。
10.图6是示出通过在处理元件之间分配卷积运算来解决分组卷积问题的过程的实施例的流程图。
11.图7是示出通过在处理元件之间分配卷积运算来解决分组卷积问题的过程的实施例的流程图。
12.图8是示出使用通道卷积处理器执行卷积运算以解决分组卷积问题的过程的实施例的流程图。
13.图9是示出用于解决分组卷积问题的示例卷积数据输入矩阵的图。
14.图10是示出用于解决分组卷积问题的逐组(groupwise)卷积权重矩阵的示例集合的图。
15.图11是示出用于求解分组卷积运算的示例数据元素组矩阵和相应的逐组卷积权重矩阵的图。
16.详细描述
17.本发明可以以多种方式实现,包括作为过程;装置;系统;物质的组成;体现在计算机可读存储介质上的计算机程序产品;和/或处理器,例如被配置为执行存储在耦合到处理器的存储器上和/或由该存储器提供的指令的处理器。在本说明书中,这些实现或者本发明可以采取的任何其他形式可以被称为技术。通常,在本发明的范围内,可以改变所公开的过程的步骤顺序。除非另有说明,否则被描述为被配置成执行任务的诸如处理器或存储器的组件可以被实现为在给定时间被临时配置为执行任务的通用组件或者被制造为执行任务的特定组件。如本文所使用的,术语“处理器”指的是被配置成处理数据(例如计算机程序指令)的一个或更多个设备、电路和/或处理核心。
18.下面提供了本发明的一个或更多个实施例的详细描述以及示出本发明原理的附图。结合这些实施例描述了本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求限定,并且本发明包括许多替代、修改和等同物。为了提供对本发明的全面理解,在以下描述中阐述了许多具体细节。这些细节是出于示例的目的而提供的,并且本发明可以根据权利要求来实施,而不需要这些具体细节中的一些或全部。为了清楚起见,没有详细描述在与本发明相关的技术领域中已知的技术材料,以免不必要地模糊本发明。
19.公开了一种用于解决分组卷积问题的分布式硬件加速器系统。在各种实施例中,该系统包括具有多个处理元件的硬件加速器架构。每个处理元件都能够使用诸如通道卷积引擎的卷积引擎独立地求解卷积运算。使用点对点缩减网络,一个处理元件的卷积结果可以被提供给另一个处理元件,并且两个卷积结果可以被缩减为单个结果。在各种实施例中,缩减操作将两个卷积引擎的卷积结果合计(sum)在一起,而不需要任一处理元件将其自己的卷积结果写入存储器,然后从存储器读取结果来计算总和(sum)。减少了存储器写入的次数,从而提高了功率效率。通过将与组中的每个通道相关联的卷积运算分配给不同的处理元件,来将分组卷积的计算分布在多个处理元件上。例如,在四个通道上计算的分组卷积被分配在四个处理元件上,每个处理元件计算四个通道之一的部分结果。使用缩减网络将四个部分结果合计在一起。
20.在一些实施例中,每个卷积引擎可以被配置成并行处理多个卷积运算。例如,配置有32个向量单元的通道卷积处理器单元可以并行处理32个不同的卷积运算。通过利用配置有多个向量单元的卷积引擎,可以并行求解多个分组卷积。例如,对于32个不同组(其中每个组的深度为四个通道)中的每个组,每个组的第一通道可由第一处理元件处理,每个组的第二通道可由第二处理元件处理,每个组的第三通道可由第三处理元件处理,并且每个组的第四通道可由第四处理元件处理。每个通道卷积处理器单元的每个向量单元为32个不同组中的不同组计算部分分组卷积结果,并且使用缩减网络将适当的部分结果合计在一起。以这种方式,可以使用四个处理元件并行求解每个分组卷积在四个通道上被计算的多个分组卷积。类似地,在不同数量的通道上计算的分组卷积可以使用不同适当数量的处理元件来并行求解。通过将单个组的通道分配在多个处理元件上并利用缩减网络来缩减结果,即使是在少量通道上计算的分组卷积也可以有效地利用可用的硬件加速器系统资源。通过有效地利用硬件计算资源,特别是与传统的通用处理器和/或标准矩阵处理器硬件相比,实现了显著的性能优势。相比于使用通用处理器和传统硬件配置,本文公开的硬件系统的专用硬件和数据路径配置实现了显著的性能提高和资源效率增益。
21.在一些实施例中,处理器系统包括多个处理元件,其中多个处理元件中的每个处理元件包括卷积处理器单元。例如,分布式硬件加速器系统包括多个通信地连接的处理元件,并且每个处理元件包括缩减单元和具有卷积处理器单元的卷积引擎。处理元件除了具有构成缩减网络的对等连接之外,还可以连接到共享总线(shared bus)或类似的通信网络。例如,处理元件可以经由绕过共享通信总线的缩减网络来连接到上游和下游处理元件。每个处理元件的卷积引擎可以并行执行多个卷积运算,例如多个通道卷积运算。
22.在一些实施例中,多个卷积处理器单元中的每个卷积处理器单元被配置成执行逐组卷积的一部分。例如,每个处理元件的卷积引擎能够通过利用通道卷积运算来执行逐组卷积的一部分。来自卷积数据矩阵内的组的每个通道和相应的逐组卷积权重矩阵的相应通
道被分配给不同的处理元件及其相应的卷积处理器单元。对于每个分配的处理元件,来自卷积数据矩阵内不同组的多个通道和来自相应的不同逐组卷积权重矩阵的它们相应的通道也可以被分配给该处理元件。对于每个处理元件,不同组的分配通道是卷积数据矩阵中数据元素的一部分,并且对应于位于卷积数据矩阵的不同通道(或深度)处的子矩阵或矩阵切片(matrix slice)。在一些实施例中,每个子矩阵或矩阵切片在其各自的组内具有相同的相对通道(或深度)。例如,来自卷积数据矩阵的通道1、5、9、13、17、21、25和29的数据元素的子矩阵可以被分配给特定处理元件,该特定处理元件能够通过其卷积处理器单元并行处理八个卷积运算。来自通道1、5、9、13、17、21、25和29的数据元素的子矩阵对应于它们相应组中的每一个中的第一通道,其中这些组中每个组的深度为四个通道。类似地,来自卷积数据矩阵的通道2、6、10、14、18、22、26和30的数据元素的子矩阵可以被分配给第二处理元件及其相应的卷积处理器单元。来自通道3、7、11、15、19、23、27和31的数据元素的子矩阵被分配给第三处理元件,并且来自通道4、8、12、16、20、24、28和32的数据元素的子矩阵被分配给第四处理元件。在存在附加组的情况下,例如,存在与来自卷积数据矩阵的通道33
‑
64的数据元素相对应的下一个八个组的集合的情况下,该下一个八个组可以按通道以分布式的方式被分配给另一集合的四个处理元件。分配相应的逐组卷积权重矩阵的相应通道,以将权重矩阵通道与卷积数据矩阵的适当数据元素相匹配。
23.在一些实施例中,每个卷积处理器单元被配置为通过将卷积数据矩阵中的一部分数据元素中的每个数据元素与多个卷积权重矩阵中的相应逐组卷积权重矩阵中的相应数据元素相乘来确定相乘结果。例如,对于一个组的每个通道及与其对应的分配给卷积处理器单元的权重矩阵通道,来自该组和权重矩阵的适当数据元素被相乘以确定相乘结果。在一些实施例中,执行向量乘法运算以将组矩阵切片的每个数据元素与权重矩阵切片的适当数据元素相乘。例如,对于两个3x3矩阵,确定九个相乘结果。在一些实施例中,卷积数据矩阵中被相乘的数据元素部分是属于卷积数据矩阵内的多个不同通道和多个不同组。例如,对来自卷积数据矩阵的不同通道和来自卷积数据矩阵内的不同组的数据元素执行每个向量乘法运算。
24.在一些实施例中,每个卷积处理器单元被配置为,对于多个通道中的每个特定通道,将属于同一特定通道的相乘结果中的至少一些合计在一起,以为特定通道确定相应的通道卷积结果数据元素。例如,由卷积处理器单元执行的每个向量乘法运算的单独相乘结果被合计在一起,以确定通道卷积结果数据元素。在一些实施例中,将相乘结果合计在一起是点积运算。在各种实施例中,每个卷积处理器单元的每个分配通道的各相乘结果被合计在一起。例如,处理八个不同通道的卷积处理器单元确定八个不同的通道卷积结果数据元素。
25.在一些实施例中,多个处理元件被配置为对来自包括在多个卷积处理器单元中的一组不同卷积处理器单元的通道卷积结果数据元素的一部分进行合计,以确定逐组卷积结果数据元素。例如,对于卷积数据矩阵内的每一组,使用不同处理元件的卷积处理器单元确定的相应通道卷积结果数据元素被合计在一起,以确定逐组卷积结果数据元素。在一些实施例中,合计操作可以分布在多个处理元件上,并且使用缩减网络来执行。例如,每个处理元件处的缩减单元可以在将运行总和传输到下游处理元件的缩减单元之前,将其卷积引擎结果与上游结果(如果适用)合计在一起。对于每个组,在每个后续的下游处理元件处更新
运行总和,直到对应于该组的所有通道的通道卷积结果已经被考虑并且最终的逐组卷积结果被确定。上游处理元件和下游处理元件经由缩减网络的对等连接来链接。在各种实施例中,最终总和是逐组卷积结果数据元素。因为每个缩减单元可以对运行总和的向量进行操作,所以可以并行确定多个逐组卷积结果数据元素。
26.图1是示出使用神经网络解决人工智能问题的系统的实施例的框图。例如,系统100可被应用以使用神经网络来解决诸如图像识别和推荐系统匹配的问题。对应于神经网络不同层的卷积运算可以通过将计算工作载荷分配给系统100的不同处理元件来求解。具体地,可以通过执行分布式通道卷积运算来将分组卷积运算映射到系统100。在所示的例子中,系统100包括多个处理元件,例如处理元件101、103、105和109。附加的处理元件被显示在虚线框中。系统100可以利用每个处理元件来执行卷积运算,例如通道卷积运算。在各种实施例中,系统100可以包括更少或更多的处理元件。例如,处理元件的数量可以根据预期的计算和数据要求而按比例增加(scaled up)或减少。在一些实施例中,系统100通信地连接到存储器单元(未示出)。例如,存储器单元可以是末级高速缓存(llc)、共享存储器,和/或可以使用静态随机存取存储器(sram)来实现。
27.在一些实施例中,系统100的处理元件(包括处理元件101、103、105和109)连接到通信总线(未示出)。通信总线可用于传输处理元件指令和可选的指令参数。例如,卷积运算指令和卷积操作数可以经由通信总线被传输到处理元件(例如处理元件101)。在各种实施例中,通过将问题细分成分布式操作(例如通道卷积运算),可以使用系统100来解决大型复杂的人工智能问题。分布式操作可以被分配给不同的处理元件。卷积参数(例如卷积数据矩阵的数据元素和逐组卷积权重矩阵的数据元素)可以被分配给适当分配的处理元件。所分配的分布式运算的结果可以被合并以确定用于更大和更复杂的卷积问题(例如分组卷积问题)的解决方案。在某些情况下,分布式操作被并行和/或在流水线式的阶段中解决。在一些情况下,来自第一处理元件的结果作为输入被馈送到第二处理元件。例如,将第一处理元件的通道卷积结果与第二处理元件的通道卷积结果进行合计。然后,将结果与第三处理元件的通道卷积结果进行合计,以此类推,直到确定了合计结果的最终向量,这对应于确定了分组卷积问题的结果。
28.在各种实施例中,系统100的处理元件(例如处理元件101、103、105和109)各自可以包括卷积处理器单元(未示出)、缩减单元(未示出)以及与另一个处理元件的点对点连接(未示出)。例如,点对点连接将一个处理元件的计算结果提供给下游处理元件的缩减单元。缩减单元接收它的处理元件的结果和上游结果,并将两个结果合并在一起。合并的结果可以经由与后续下游处理元件的单独点对点连接被提供给后续下游处理元件。在一些实施例中,多个处理元件经由多个点对点连接被菊花链式地连接(daisy
‑
chained)在一起,以合并多个处理元件的结果。在各种实施例中,通过经由点对点连接将第一卷积处理器单元的结果传输到第二处理元件的缩减单元,可以将第一处理元件的第一卷积处理器单元的输出与第二处理元件的第二卷积处理器单元的输出进行合计。第二处理元件的缩减单元合并两个卷积处理器单元的输出。
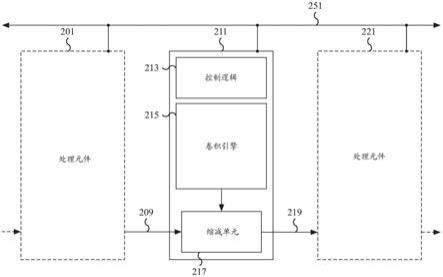
29.图2是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。在所示的例子中,处理元件211包括控制逻辑213、卷积引擎215和缩减单元217。处理元件211经由点对点连接209连接到处理元件201,并且经由点对点连接219连接到处理元件221。处理元
件211还连接到通信总线251。处理元件201和221被显示为虚线框,并且没有示出处理元件201和221的一些细节。指向处理元件201的虚线箭头和从处理元件221引出的虚线箭头是来自附加(可选的)处理元件(未示出)的可选点对点连接。类似于处理元件211,处理元件201和221连接到通信总线251。在一些实施例中,处理元件211是图1的处理元件101、103、105和/或109之一,并且点对点连接209和/或219是连接到图1的另一个处理元件的点对点连接。
30.在一些实施例中,处理元件211的控制逻辑213用于控制处理元件211的操作,包括卷积引擎215和缩减单元217的操作。例如,控制逻辑213可用于确定如何对齐在缩减单元217处接收的数据,包括用什么字节通道(byte lane)来分配不同的数据参数。在一些实施例中,控制逻辑213用于处理由处理元件211经由通信总线251接收的指令。例如,处理元件指令可以包括通道卷积运算指令、通道卷积参数、字节对齐命令等。
31.在一些实施例中,卷积引擎215包括用于执行卷积运算(例如通道卷积运算)的卷积处理器单元。例如,卷积引擎215可以是通道卷积引擎,用于使用来自卷积数据矩阵的数据元素和相应的权重作为参数来执行通道卷积运算。在一些实施例中,卷积引擎215可以接收来自卷积数据矩阵的一部分数据元素和相应的逐组卷积权重矩阵的相应数据元素,以为卷积数据矩阵的特定通道确定通道卷积结果数据元素。处理元件211的卷积引擎215可以部分地用于通过利用相邻的处理元件(例如处理元件201和221)执行分布式通道卷积运算来解决分组卷积问题。在一些实施例中,卷积引擎215可以包括用于加载输入数据元素和写出结果数据元素的输入和/或输出缓冲区。在所示的例子中,卷积引擎215向缩减单元217提供输出结果。
32.在一些实施例中,缩减单元217是用于缩减两个数据输入的硬件单元。在所示的例子中,缩减单元217从卷积引擎215接收第一输入操作数,并经由点对点连接209从处理元件201接收第二输入操作数。在各种实施例中,来自卷积引擎215的第一输入操作数是卷积运算结果,而第二输入操作数是来自处理元件201的处理结果。在一些实施例中,来自处理元件201的处理结果可以是由处理元件201执行的卷积运算的结果,和/或是使用处理元件201的相应缩减单元(未示出)合并处理元件201的卷积运算结果而得到的结果。一旦缩减单元217接收到两个输入操作数,缩减单元217就经由点对点连接219将缩减结果提供给处理元件221。在各种实施例中,缩减单元217将两个输入合并(或缩减)成单个输出。在一些实施例中,缩减运算是缩减单元217的两个输入的合计运算。对两个输入的其他运算以及运算的组合也可能是合适的,例如逻辑运算(与(and)、或(or)、异或(xor)等)、移位运算、减法运算等。然后,输出可以经由点对点连接被提供给下游处理元件。在一些实施例中,一个或两个输入可以被移位,使得每个输入被保留但被不同地对齐。例如,缩减单元217可以移位一个输入以将两个输入级联在一起。作为示例,两个8字节的输入可以被合并成一个16字节的输出结果。类似地,两个16字节的输入可以被合并成一个32字节的输出结果。在各种实施例中,根据计算上下文,不同的输入数据大小(例如,4字节、8字节、16字节等)和对齐选择方案(alignment option)可能是合适的。
33.在一些实施例中,对于处理元件211,点对点连接209和219分别是来自处理元件201的网络连接和到处理元件221的网络连接。点对点连接209用于向处理元件211的缩减单元217提供处理元件201的卷积运算结果和/或缩减单元(未示出)的结果。点对点连接219用
于将处理元件211的缩减单元217的结果提供给处理元件221的缩减单元(未示出)。在各种实施例中,处理元件可以包括与上游处理元件的连接(例如用于处理元件211的点对点连接209)和/或与下游处理元件的连接(例如用于处理元件211的点对点连接219)。通过利用点对点连接,卷积引擎的卷积计算结果不需要通过通信总线251传输。避免了总线协议和总线通信的其他相关开销。
34.图3是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。在所示的例子中,处理元件301包括控制逻辑303、卷积引擎305、多路复用器307、加法器311、点对点连接309和点对点连接313。处理元件301连接到通信总线351,经由点对点连接309连接到上游处理元件(未示出),以及经由点对点连接313连接到下游处理元件(未示出)。在一些实施例中,处理元件301是图2的处理元件211,并且控制逻辑303、卷积引擎305、点对点连接309、点对点连接313和通信总线351分别是图2的控制逻辑213、卷积引擎215、点对点连接209、点对点连接219和通信总线251。在一些实施例中,多路复用器307和加法器311被包括作为图2的缩减单元217的一部分。
35.在各种实施例中,控制逻辑303和卷积引擎305的功能如关于图2的控制逻辑213和卷积引擎215所述。例如,控制逻辑303处理处理元件指令,包括经由通信总线351接收的卷积运算指令。类似地,卷积引擎305接收卷积运算,并对卷积数据矩阵的数据元素和相应的权重执行卷积运算(例如通道卷积运算)。在所示的例子中,卷积引擎305的输出被提供给多路复用器307。
36.在一些实施例中,多路复用器307可以用于重新对齐卷积引擎305的输出。例如,一个8字节的计算结果可以被移位8字节,并存储为32字节的填充值(padded value)。在各种实施例中,重新对齐的输出是用零填充的,使得重新对齐的输出可以与附加的8字节结果合并。例如,使用32字节的值,四个8字节的卷积引擎结果可以使用一系列四个所公开的处理元件被合并在一起。在各种实施例中,多路复用器307用于将多路复用器307的输入移位配置的位数。位数可以是字节对齐的和/或8位的倍数(例如,8字节、16字节、24字节等)。例如,16字节的卷积结果可以被移位16字节。在一些实施例中,卷积引擎结果被移位的位数由处理元件指令指定。例如,为了使用加法器311对两个输入进行合计,指定的位数可以是0位,导致经过多路复用器307的输入不改变。在一些实施例中,多路复用器307的大小与卷积引擎305的输出大小相匹配。例如,计算32字节结果的卷积引擎被配置有可接收32字节输入的多路复用器。在各种实施例中,多路复用器307的输入大小和输出大小相同。例如,接收32字节卷积结果的多路复用器输出重新对齐的32字节输出。在一些实施例中,多路复用器307使用用于重新对齐数据的另一个合适的硬件单元来实现。重新对齐的卷积结果被提供给加法器311。
37.在一些实施例中,加法器311从多路复用器307接收卷积结果(可能是重新对齐的),以及经由点对点连接309接收第二输入。第二输入可以是上游处理元件的处理结果。例如,处理结果可以是卷积结果或多个缩减(或合计)卷积结果。加法器311将两个接收的输入合并(或缩减)成单个输出结果。在一些实施例中,两个结果由加法器311加在一起,以有效地将输入合计在一起。例如,用零填充的多路复用器结果被添加到经由点对点连接309提供的输入。然后,经由点对点连接313将结果提供给下游处理元件(未示出)。
38.在一些实施例中,加法器311是向量加法器,并且执行向量加法器运算。例如,加法
器311接收两个向量(每个向量具有多个元素)并将每个输入向量的相应元素合计在一起。加法器结果是加法结果的向量。作为一个示例,两个输入可以各自是32元素的向量。加法器311将每个输入向量的各个元素合计在一起,以确定32个加法结果。32个加法结果可以存储为向量结果,并经由点对点连接313向下游传输。虽然在该示例中向量的大小是32个元素,但是根据硬件配置,也可以应用另一种向量大小。
39.在各种实施例中,处理元件之间的点对点连接(例如点对点连接309和/或313)用于缩减卷积引擎结果,而不需要首先将卷积结果写入存储器,这避免了潜在的昂贵的存储器操作。此外,通过使用点对点连接将多个处理元件链接在一起,可以使用每个处理元件的相应加法器单元将链中每个卷积引擎的输出合计在一起。
40.图4是示出用于使用神经网络解决人工智能问题的通道卷积引擎的实施例的框图。在所示的例子中,通道卷积引擎400包括数据输入单元403、通道权重输入单元405、通道卷积处理器单元407和输出单元409。在一些实施例中,通道卷积引擎400是硬件集成电路,例如专用集成电路(asic),并且包括硬件组件数据输入单元403、通道权重输入单元405、通道卷积处理器单元407和输出单元409。与通用处理器相比,通道卷积引擎400使用专用硬件集成电路来设计和实现,以更有效地执行与执行卷积运算和/或使用神经网络解决人工智能问题相关的一个或更多个特定计算任务。与使用通用处理器相比,专用硬件实现了显著的性能提高和资源效率增益。在一些实施例中,通道卷积引擎400是图2的卷积引擎215和/或图3的卷积引擎305。在各种实施例中,通道卷积引擎400用于执行分布式通道卷积运算,以解决更大的分组卷积问题。
41.在所示的示例中,通道卷积处理器单元407包括多个向量计算单元,该多个向量计算单元至少包括向量单元411和421。在各种实施例中,通道卷积处理器单元407从数据输入单元403接收数据输入向量(未示出),并从通道权重输入单元405接收通道权重输入向量(未示出)。例如,在一些实施例中,数据输入向量由数据输入单元403生成,其对应于3d激活数据输入矩阵的2d子矩阵,其中每个2d子矩阵对应于3d激活数据输入矩阵的不同通道。通道权重输入向量由通道权重输入单元405生成,并且对应于不同的权重矩阵。在各种实施例中,3d激活数据输入矩阵的2d子矩阵和通道权重矩阵可以是3x3矩阵或其他适当的大小。2d子矩阵可以来自卷积数据矩阵内多个不同组的多个不同通道,或者来自多个不同的卷积权重矩阵。激活数据输入矩阵和权重输入矩阵的数据元素可以被存储并从存储器(未示出)中检索。
42.在一些实施例中,每个生成的数据输入向量和通道权重输入向量对可以作为参数被传递给通道卷积处理器单元407的向量计算单元,例如向量单元411和421中的一个。例如,通道卷积处理器单元407的向量单元可以使用数据输入向量和通道权重输入向量对来确定通道卷积结果数据元素,例如点积结果。在一些实施例中,通道卷积处理器单元407包括32个向量单元和/或另一合适数量的向量单元。向量单元的数量可以基于缓存行(cache line)大小,例如,缓存行大小或缓存行大小的倍数。例如,缓存行倍数可以是1,向量单元的数量可以等于缓存行大小。每个向量单元可以采用对应于两个向量的数据元素作为参数,并且每个向量单元可以产生单元素结果。以3x3矩阵为例,每个向量单元采用两个9元素的向量作为参数,一个向量对应于激活数据输入矩阵的一个子矩阵,并且一个向量对应于一个权重矩阵。跨通道卷积处理器单元407的所有向量单元获取,得到的结果是通道卷积结果
的向量,并且可以对应于通道卷积结果矩阵的数据元素。在一些实施例中,激活数据输入矩阵的不同部分在额外的迭代中被处理。例如,通道卷积处理器单元407可以使用相同的权重矩阵来确定通道卷积结果矩阵的附加数据元素。在一些实施例中,通道卷积处理器单元407针对每次迭代的输出可以是输出向量,并且在输出单元409处被接收。在一些实施例中,在输出单元409处接收的输出向量是32元素的向量。尽管在上面的示例中,对于每次迭代使用3x3矩阵来处理32个通道,但是在适当的情况下,可以配置由通道卷积引擎400处理的元素和矩阵的大小。例如,元素可以是4位、8位、2字节、4字节或其他适当的大小。类似地,激活数据输入矩阵的子矩阵和通道权重矩阵可以是3x3、5x5或另一适当的大小。在一些实施例中,由通道卷积处理器单元407计算的结果是用于计算更大的分组卷积问题的通道卷积结果。例如,来自通道卷积处理器单元407的结果与来自不同通道卷积处理器单元的通道卷积结果被合计在一起,以确定逐组卷积结果。
43.在一些实施例中,通道卷积处理器单元407被配置成接收多对输入矩阵。每对输入矩阵包括数据输入矩阵和对应的权重矩阵。每个数据输入矩阵对应于激活数据输入矩阵的一部分的特定通道,并由数据输入单元403处理。每个权重输入矩阵对应于要应用于该通道的权重矩阵,并由通道权重输入单元405处理。数据输入单元403、通道权重输入单元405和输出单元409可以使用硬件寄存器(例如触发器(flip
‑
flop)电路)来实现,用于向/从通道卷积处理器单元407传送多个输入和输出元素。在一些实施例中,从存储器中检索对应于每个数据输入向量的元素,并经由数据输入单元403将其加载到通道卷积处理器单元407的对应向量单元(例如向量单元411或421)中。例如,具有32个向量单元的通道卷积处理器单元可以经由数据输入单元403加载对应于激活数据输入矩阵的32个不同通道的32个数据输入元素向量。在一些实施例中,不同的通道属于卷积数据矩阵内的不同组。类似地,从存储器中检索对应于每个权重输入向量的元素,并经由通道权重输入单元405将其加载到通道卷积处理器单元407的对应向量单元(例如向量单元411或421)中。例如,具有32个向量单元的通道卷积处理器单元可以经由通道权重输入单元405加载对应于32个不同权重矩阵的32个通道权重输入元素向量。权重矩阵可以对应于来自不同3d卷积权重组(或滤波器组)的通道。在一些实施例中,当确定了与激活数据输入矩阵的部分相对应的结果时,加载附加数据元素,用于用相同的权重矩阵处理激活数据输入矩阵的附加部分。例如,数据输入单元403加载附加的所需数据元素,并生成对应于激活数据输入矩阵的新部分的新数据输入向量,用于确定附加的通道卷积结果。当数据输入向量改变以对应于激活数据输入矩阵的新部分时,权重输入向量可以保持不变并且可以重复使用,从而显著提高卷积运算的效率。在各种实施例中,图4的箭头表示数据移动通过通道卷积引擎400的组件的方向。例如,箭头可以对应于多元素宽通信/数据总线和/或数据线。在各种实施例中,在输出单元409处接收的输出向量结果被传输到缩减单元,在缩减单元中,该结果可以与另一个向量输入合并。在一些实施例中,未示出通道卷积引擎400的附加组件。
44.在各种实施例中,通道卷积处理器单元407的每个向量单元(例如向量单元411或421)接收两个向量操作数,并且可以执行一个或更多个向量运算。例如,向量单元可以计算两个输入操作数的点积,并将结果作为输出向量的一个元素输出到输出单元409。在各种实施例中,向量单元的输出结果对应于通道卷积结果数据元素。在一些实施例中,通道卷积处理器单元407的每个向量单元(例如向量单元411或421)包括乘法单元和加法器单元。例如,
向量单元411包括向量乘法单元413和向量加法器单元415,并且向量单元421包括向量乘法单元423和向量加法器单元425。
45.在一些实施例中,通道卷积引擎400的多个实例可以一起操作来处理激活数据输入矩阵的不同部分。例如,每个处理元件和相应的通道卷积引擎可以检索激活数据输入矩阵和相应的权重矩阵中的分配给它的数据元素。在一些实施例中,不同的处理元件共享权重矩阵,并且共享的权重矩阵的数据元素可以被广播到适当的处理元件以提高存储器效率。处理元件的每个通道权重输入单元使用其自己的通道卷积处理器单元对激活数据输入矩阵的分配部分执行通道卷积运算。每个处理元件的结果可以被传输到缩减单元,例如图2的缩减单元217。在一些实施例中,一系列缩减单元被用来将相应通道卷积处理器单元的结果合计在一起,以确定分组卷积结果。
46.图5是示出用于解决分组卷积问题的过程的实施例的流程图。例如,使用支持按通道卷积的硬件,将分组卷积问题分布在较少数量的输入通道上。在各种实施例中,硬件系统包括多个处理元件和适当的硬件卷积引擎,用于求解分布式卷积运算并合并结果。分组卷积问题可以被分解成多个通道卷积运算,并且使用缩减网络将通道卷积运算的结果合计在一起。在一些实施例中,图5的过程使用硬件系统(例如图1的系统100)来实现。
47.在501,接收分组卷积运算。分组卷积运算包括操作数,例如3d卷积数据矩阵和逐组卷积权重矩阵。在各种实施例中,分组卷积运算可能需要计算少量通道上的分组卷积,这些通道不能被有效地映射到矩阵乘法处理器。例如,在一些实施例中,可能仅在四个输入通道上计算分组卷积问题,而每个处理元件可以同时处理32个输入通道。这种不匹配导致计算资源的利用不足。为了有效地执行分组卷积运算,该问题被分解成多个较小的运算,例如多个通道卷积运算。
48.在503,分解分组卷积运算。例如,在501接收的分组卷积运算被分解成更小的子问题。每个子问题利用单个处理元件可以处理的卷积运算,例如通道卷积运算。例如,向配置有能够计算32通道卷积数据元素结果的卷积引擎的处理元件被分配了原始分组卷积问题的一部分。在各种实施例中,一个子问题的输出可以用另一个子问题的输出来缩减,例如,通过将结果合计在一起。在一些实施例中,子问题可以被并行和/或在流水线式的阶段中解决。
49.在505,分配分解的运算。例如,503的分解的分组卷积运算的每个子问题被分配给处理元件。在各种实施例中,硬件系统的多个处理元件各自接收要解决的子问题。接收到的子问题可以利用原始分组卷积参数的子集,例如来自在501指定的3d卷积数据矩阵和逐组卷积权重矩阵的一部分数据元素的。在一些实施例中,处理元件还可以接收由另一个处理元件计算的结果作为输入,例如,用于将卷积结果的两个集合合计在一起(或进行缩减)。分布式运算可以由分配的处理元件并行求解,以实现显著的性能提高。
50.在507,合并来自分布式运算的结果。例如,每个分布式运算的结果被缩减和合并,以确定在501接收的分组卷积运算的最终结果。在一些实施例中,首先通过菊花链式地连接处理元件并利用如本文所述的处理元件之间的点对点连接来部分地缩减结果。缩减的结果可以被更有效地写入,以避免不必要的存储器写入,从而实现显著的性能提高。在各种实施例中,使用硬件系统的分布式处理元件求解的缩减结果最终被合并在一起(例如通过写入到共享存储器位置),以确定在501接收的分组卷积运算的最终结果。
51.图6是示出通过在处理元件之间分配卷积运算来解决分组卷积问题的过程的实施例的流程图。例如,通过将卷积运算分配给不同的处理元件并缩减分布式结果,来解决分组卷积问题。在一些实施例中,3d卷积数据矩阵和逐组卷积权重矩阵的不同部分被分配并传输到不同的处理元件。每个相应处理元件的卷积引擎处理接收到的输入参数以确定卷积结果。在一些实施例中,每个分组卷积结果数据元素是通过使用缩减网络将由多个处理元件确定的卷积结果合计在一起而确定的。在一些实施例中,步骤601在图5的503和/或505处执行,步骤603和605在图5的505处执行,和/或步骤607在图5的507处执行。在一些实施例中,图6的过程使用硬件系统(例如图1的系统100)来实现。
52.在601,数据输入元素被分配并传输到处理元件。例如,卷积数据矩阵中的一部分数据元素的数据元素被分配给每个合格的处理元件。分配给特定处理元件的数据元素可以来自卷积数据矩阵内的不同通道和不同组。例如,对于在四个通道上计算的分组卷积,每个组的第一通道可以被分配给第一处理元件,每个组的第二通道可以被分配给第二处理元件,每个组的第三通道可以被分配给第三处理元件,并且每个组的第四通道可以被分配给第四处理元件。在每个处理元件及其各自的卷积引擎可以处理32个输入矩阵的情况下,每个处理元件被分配来处理32个不同组的适当通道。相同的过程适用于在不同数量的通道上计算的分组卷积。根据需要,可以将附加的组分配给不同的处理元件集合。
53.在603,权重输入元素被广播给处理元件。例如,组成权重输入元素并对应于在601分配的数据输入元素的数据元素被广播到适当的处理元件。在一些实施例中,权重输入元素是来自不同卷积权重组(或滤波器组)的数据元素。例如,对于在四个通道上计算的分组卷积以及处理元件(每个处理元件配置有能够处理32个输入矩阵的卷积引擎),32个不同的权重组被广播到这些处理元件。32个不同权重组中的每一个的第一通道在第一处理元件处被接收,32个不同权重组中的每一个的第二通道在第二处理元件处被接收,32个不同权重组中的每一个的第三通道在第三处理元件处被接收,并且32个不同权重组中的每一个的第四通道在第四处理元件处被接收。这四个处理元件对应于步骤601的例子中的四个处理元件。相同的过程适用于在不同数量的通道上计算的分组卷积。根据需要,可以将附加的组分配给不同的处理元件集合。
54.在一些实施例中,相同的权重数据元素被广播给多个处理元件。例如,32个不同权重组中的每一个的第一通道可以被多个处理元件接收和利用。尽管处理元件接收相同的权重,但是在601分配给每个处理元件并由每个处理元件接收的卷积数据矩阵的相应数据元素是不同的。例如,不同的处理元件被分配来处理卷积数据矩阵的不同部分,例如卷积数据矩阵的不同行部分。通过向多个处理元件广播相同的权重数据元素,显著提高了用于向处理元件进行权重输入的数据传输的效率。
55.在605,执行局部卷积运算,并且在处理元件之间缩减结果。例如,每个处理元件对接收到的数据和权重元素执行卷积运算,例如通道卷积运算。每个处理元件可以计算多个局部卷积结果,以确定局部卷积结果的向量。每个局部卷积结果可以对应于部分结果,其与一个或更多个其他处理元件的局部结果一起使用以确定逐组卷积结果数据元素。例如,使用缩减网络来缩减跨多个处理元件计算的部分结果,以确定逐组卷积结果数据元素。
56.在一些实施例中,通过在缩减网络上传输局部卷积结果并在该网络的每个节点处执行运行合计(running sum)来对部分结果进行合计。例如,对于在四个通道上计算的分组
卷积,第一部分分组卷积结果由第一处理元件计算,第二部分分组卷积结果由第二处理元件计算,第三部分分组卷积结果由第三处理元件计算,并且第四部分分组卷积结果由第四处理元件计算。每个部分结果对应于四个通道中不同的一个通道。第一部分结果经由缩减网络被传输到第二处理元件,在该缩减网络中,第一部分结果和第二部分结果被合计在一起并缩减为单个结果。第二处理元件经由缩减网络将缩减结果传输到第三处理元件。在第三处理元件处,接收的缩减结果和第三部分结果被合计在一起并缩减为单个结果。该缩减结果经由缩减网络被传输到第四处理元件,在第四处理元件处,它与第四部分结果被合计在一起,以确定逐组卷积结果数据元素。在一些实施例中,上面的示例中的每个处理元件可以为多个组计算逐组卷积结果数据元素,每个组具有四个通道。例如,可以分别处理32对数据和权重输入的四个卷积引擎可以计算32个不同的逐组卷积结果数据元素。虽然示例中使用了四个通道,但是每个组的通道数可以是另一个适当的值。通过利用处理元件之间的点对点连接,至少部分地通过避免不必要的存储器写入来更有效地传输和缩减局部卷积运算。结果是显著提高了在计算逐组卷积结果数据元素方面的性能。
57.在607,处理元件结果被合并。例如,在605计算的逐组卷积结果数据元素被合并在一起,以确定分组卷积运算的最终结果。在一些实施例中,逐组卷积结果数据元素由它们各自的处理元件通过写入到共享位置(例如共享存储器位置)来合并。通过将所有结果写入到共享存储器位置,逐组卷积结果数据元素可以被合并到逐组卷积结果矩阵中。
58.图7是示出通过在处理元件之间分配卷积运算来解决分组卷积问题的过程的实施例的流程图。在各种实施例中,图7的过程由用于执行解决分布在多个处理元件上的分组卷积问题所需的部分计算的每个处理元件来执行。在一些实施例中,至少部分地在图5的503、505和/或507和/或图6的605和/或607处或响应于图5的503、505和/或507和/或图6的605和/或607,执行图7的过程。在一些实施例中,图7的过程由图1的系统100的一个或更多个处理元件来执行。
59.在701,接收局部卷积指令。例如,在处理元件处接收通道卷积指令。在一些实施例中,指令由处理元件的控制逻辑(例如图2的控制逻辑213)处理。在各种实施例中,卷积指令包括特定的卷积运算和卷积参数,该卷积参数指定要对其执行卷积运算的数据元素。在一些实施例中,卷积指令用于使用处理元件的卷积引擎(例如通道卷积引擎)来解决分组卷积问题。
60.在一些实施例中,接收对应于局部卷积指令的局部卷积参数。例如,接收卷积数据矩阵的数据元素以及相应的逐组卷积权重矩阵的相应数据元素。元素可以对应于分组卷积问题的多个不同组,并且被分配给处理元件,作为分配用于解决分组卷积问题的计算的一部分。在一些实施例中,在卷积引擎的数据输入单元(例如图4的数据输入单元403)处处理数据元素,并且在卷积引擎的权重输入单元(例如图4的通道权重输入单元405)处处理权重元素。
61.在703,执行局部卷积运算。例如,使用卷积引擎,由处理元件执行局部卷积运算。在一些实施例中,卷积引擎是通道卷积引擎,例如图4的通道卷积引擎400,并且执行通道卷积运算。在一些实施例中,例如,由卷积引擎的不同向量单元并行执行多个卷积运算。每个向量单元能够输出卷积运算结果。例如,具有32个向量单元的通道卷积引擎可以输出32个通道卷积结果。在一些实施例中,这些结果在输出单元(例如图4的输出单元409)处作为输
出结果的32元素向量被输出。卷积输出结果被传输到局部缩减单元,例如图2的缩减单元217。
62.在705,接收上游卷积结果。例如,经由点对点连接接收上游处理元件的处理结果。处理结果可以是使用上游处理元件的卷积引擎确定的卷积结果的向量。在一些实施例中,处理结果是合并来自多个上游处理元件的结果的上游缩减单元的结果。在各种实施例中,上游卷积结果在缩减单元(例如图2的缩减单元217)处被接收。
63.在707,缩减局部卷积结果和上游卷积结果。例如,将由在703执行的局部卷积运算计算的局部卷积结果与在705接收的上游卷积结果进行合并。在一些实施例中,通过使用缩减单元(例如图2的缩减单元217)将两个输入合计在一起,来缩减局部结果和上游结果。在各种实施例中,并行地缩减对应于卷积数据矩阵内不同通道和不同组的多个卷积结果。
64.在709,转发缩减的结果。在一些实施例中,缩减的结果经由点对点连接被转发到下游处理元件。下游处理元件可以将缩减的结果与由下游处理元件的卷积引擎计算的卷积引擎结果合并。通过将缩减的结果直接转发到下游处理元件,所需的存储器写入的次数被最小化,并实现了性能的提高和功率需求的降低。
65.图8是示出使用通道卷积处理器执行卷积运算以解决分组卷积问题的过程的实施例的流程图。例如,数据输入向量与权重输入向量一起被加载到通道卷积处理器单元的向量单元中,以确定通道卷积结果数据元素结果。每个数据输入向量是三维卷积数据输入矩阵的一部分的二维子矩阵切片。每个权重输入向量是与三维卷积数据输入矩阵的通道相关联的逐组卷积权重矩阵的二维矩阵切片。每个向量单元执行点积结果,以确定对应于部分逐组卷积结果数据元素的通道卷积结果数据元素结果。在各种实施例中,一旦数据输入的初始集合与相应的权重输入被加载到通道卷积处理器单元的向量单元中,卷积数据输入矩阵的后续部分可以通过仅加载卷积数据输入矩阵的增量部分来处理。权重输入矩阵和用于确定前一次卷积结果的数据输入部分能够被重复使用,其好处是提高了效率和性能。
66.在一些实施例中,图8的过程作为图5、图6和/或图7的过程的一部分来执行。例如,在一些实施例中,图8的过程在图5的505和/或507处或响应于图5的505和/或507来执行,和/或步骤801和/或811可以在图6的601处或响应于图6的601来执行,步骤803可以在图6的603处或响应于图6的603来执行,步骤805、807和/或809可以在图6的605处执行,和/或步骤807可以在图6的607处执行。作为另一个例子,在一些实施例中,步骤801、803、809和/或811可以在图7的701处被执行,和/或步骤805和/或807可以在图7的703处被执行。
67.在一些实施例中,图8的过程由处理元件(例如图1的处理元件)并使用通道卷积引擎(例如图4的通道卷积引擎400)来执行。在一些实施例中,通道卷积处理器单元的向量单元的数据输入和权重输入分别由数据输入单元和权重输入单元准备,并且在输出单元处收集通道卷积结果。在一些实施例中,数据输入单元是图4的数据输入单元403,权重输入单元是图4的通道权重输入单元405,并且输出单元是图4的输出单元409。
68.在801,用数据输入的初始集合准备数据输入向量,并将其加载到通道卷积处理器单元的向量单元中。例如,对应于三维卷积数据输入矩阵的矩阵切片的数据元素被准备作为数据输入的初始集合的数据输入向量。在各种实施例中,数据输入的初始集合需要加载每个数据元素。在一些实施例中,每个数据输入向量对应于三维卷积数据输入矩阵的一部分的二维子矩阵或矩阵切片,并且对应于特定通道。每个数据输入向量可以对应于卷积数
据输入矩阵内的不同组。数据输入向量的数量对应于通道卷积处理器单元的向量单元的数量,并且是可以并行处理的通道的数量。在一些实施例中,数据输入向量的数量也对应于当对于卷积数据输入矩阵内的每个组仅从一个通道检索元素时可以并行处理的组的数量。例如,在并行处理32个通道(分别来自32个不同组中的每个组)的情况下,准备好32个数据输入向量,并且在通道卷积处理器单元的每个向量单元中加载一个向量。
69.在一些实施例中,存储在数据输入向量中的每个矩阵是3x3矩阵,并且匹配逐组卷积权重矩阵的相应权重矩阵切片的大小。在各种实施例中,矩阵的大小可以是另一种大小,例如5x5、7x7、9x9、11x11或另一种适当的大小。每个数据输入向量的大小基于矩阵的大小,并且是矩阵的元素数量。例如,对于3x3矩阵,每个数据输入向量有9个数据元素,并且向量单元可以连同9个权重元素一起处理9个数据元素。作为另一个示例,对于5x5矩阵,每个数据输入向量具有25个数据元素,并且向量单元可以连同25个权重元素一起处理25个数据元素。
70.在各种实施例中,一旦准备好,每个数据输入向量被加载到通道卷积处理器单元的适当向量单元中。例如,通道卷积单元的每个向量单元加载有准备好的数据输入向量。准备好的数据输入向量的元素对应于来自卷积数据输入矩阵的单个通道的子矩阵(或矩阵切片)。在各种实施例中,每个数据输入向量的对应数据元素在卷积数据输入矩阵中各自具有相同的宽度和高度位置,但是具有不同的通道位置,并且来自矩阵内的不同组。除了数据输入向量之外,在803,每个向量单元接收对应的权重输入向量。
71.在803,准备好权重输入向量并将其加载到通道卷积处理器单元的向量单元。例如,将对应于与三维卷积数据输入矩阵的不同矩阵切片相关联的权重矩阵切片集合的权重数据元素准备为权重输入向量。在各种实施例中,与卷积数据输入的初始集合相关联的权重元素需要将每个权重数据元素加载到对应的向量单元。在一些实施例中,后续附加卷积数据的处理可以重复使用相同的权重输入数据,而无需附加的处理来准备新的权重输入向量。在一些实施例中,每个权重输入向量对应于与卷积数据输入矩阵的不同通道相关联的不同二维权重矩阵。权重输入向量的数量对应于通道卷积处理器单元的向量单元的数量,并且是可以并行处理的通道的数量。例如,在并行处理32个通道的情况下,准备好32个权重输入向量,并且在通道卷积处理器单元的每个向量单元中加载一个权重输入向量。在一些实施例中,存储在权重输入向量中的每个权重矩阵是3x3权重矩阵切片,并且匹配对应卷积数据子矩阵切片的大小。在各种实施例中,权重矩阵的大小可以是另一种大小,例如5x5权重矩阵切片或另一种适当的大小。每个权重输入向量的大小基于权重矩阵切片的大小,并且是矩阵切片的元素数量。例如,对于3x3的权重矩阵切片,每个权重输入向量具有9个权重数据元素,并且向量单元可以连同9个卷积数据元素一起处理9个权重数据元素。作为另一个示例,对于5x5的权重矩阵切片,每个权重输入向量具有25个权重数据元素,并且向量单元可以连同25个卷积数据元素一起处理25个权重数据元素。
72.在各种实施例中,一旦被准备好,每个权重输入向量基于对应的数据输入向量被加载到通道卷积处理器单元的适当向量单元。例如,通道卷积单元的每个向量单元加载有准备好的权重输入向量。准备好的权重输入向量的元素对应于与来自卷积数据输入矩阵的单个通道的子矩阵相关联的权重矩阵切片。除了权重输入向量之外,在801,每个向量单元接收对应的数据输入向量。
73.在805,执行向量乘法和向量加法运算。利用在801或811从数据输入向量加载并且在803从权重输入向量加载的输入向量,通道卷积处理器单元的每个对应向量单元执行向量乘法和加法运算。数据输入向量中的每个元素与其在权重输入向量中的对应元素相乘。结果是相乘结果的向量。例如,使用3x3的数据和权重矩阵,9个数据元素中的每一个与9个权重元素中的对应的一个相乘,以确定9个相乘结果。在一些实施例中,向量相乘运算由向量单元的向量乘法单元执行。使用向量乘法结果,通过将相乘结果向量中的每个元素相加来计算向量和结果(vector sum result)。在各种实施例中,结果是通道卷积结果数据元素,并且对应于部分逐组卷积结果数据元素。在一些实施例中,使用向量单元的向量加法器单元来确定和。例如,使用加法器树的向量加法器单元可以计算向量元素的和。在一些实施例中,通道卷积处理器单元的每个向量单元使用其对应加载的数据输入向量和权重输入向量来执行点积运算。点积结果是对应于部分逐组卷积结果数据元素的通道卷积结果数据元素。在各种实施例中,使用缩减网络将由不同处理元件计算的多个部分逐组卷积结果数据元素合计在一起,以计算最终的逐组卷积结果数据元素。在一些实施例中,用于执行向量乘法运算的向量乘法单元是诸如图4的向量乘法单元413或423的向量乘法单元,并且用于执行向量加法运算的向量加法器单元是诸如图4的向量加法器单元415或425的向量加法器单元。在一些实施例中,通道卷积处理器单元的每个向量单元并行执行其向量运算。例如,具有32个向量单元的通道卷积处理器单元可以并行计算对应于32个不同通道的32个卷积结果数据元素。
74.在807,输出结果。例如,通过在805执行向量乘法和加法运算确定的卷积结果从通道卷积处理器单元输出。在一些实施例中,确定卷积结果(例如,对应于卷积数据输入矩阵内32个不同通道和/或组的32个卷积结果)的向量,因为通道卷积处理器单元包括被配置为并行工作的多个向量单元。结果的向量作为输出向量结果而输出,例如输出到输出单元(例如图4的输出单元409)。输出单元可用于将输出向量结果写入到缩减单元,例如图2的缩减单元217。在一些实施例中,在不需要缩减的情况下,输出被写入到存储器位置。在各种实施例中,在缩减单元处,通过将在805确定的结果与在上游处理元件处计算的结果合计在一起来缩减结果。
75.在809,确定附加数据输入是否待被处理。例如,当沿着宽度维度水平遍历卷积数据输入矩阵的分配部分时,确定是否存在卷积数据输入矩阵的分配部分的附加列。类似地,当沿着卷积数据输入矩阵的分配部分的高度维度垂直遍历时,确定是否存在附加行。在卷积数据输入矩阵的分配部分的附加数据输入待被处理的情况下,处理进行到811。在没有附加数据输入待被处理的情况下,处理结束。
76.在811,使用增量数据输入的数据输入向量被准备好,并被加载到通道卷积处理器单元的向量单元。例如,加载对应于卷积数据输入矩阵的分配部分的下一列(或行)数据的增量数据。当沿着宽度维度水平遍历时,卷积数据输入矩阵的分配部分的附加列被加载。类似地,当沿着高度维度垂直遍历时,卷积数据输入矩阵的分配部分的附加行被加载。该增量数据与从801或811的前一次迭代加载的数据一起使用(在一定程度上,数据元素与前一次迭代重叠,并且可以重复使用),以准备输入数据向量。例如,当水平遍历时,来自前一次迭代的第二列和第三列的数据被移位到第一列和第二列,并与新加载的第三列组合以创建新的数据输入向量。新的数据输入向量对应于水平移位卷积数据输入矩阵的子矩阵切片。在
一些实施例中,新的数据输入向量对应于沿着宽度维度滑动卷积数据的相关卷积矩阵。类似地,当垂直遍历时,来自前一次迭代的第二行和第三行的数据被移位到第一行和第二行,并与新加载的第三行组合以创建新的数据输入向量。新的数据输入向量对应于垂直移位卷积数据输入矩阵的子矩阵切片。在一些实施例中,新的数据输入向量对应于沿着高度维度滑动卷积数据的相关卷积矩阵。在各种实施例中,只有数据输入的初始集合需要加载数据元素的整个矩阵切片,并且在801执行。在811,仅需要增量数据元素。
77.在各种实施例中,对应于卷积数据输入矩阵的分配部分的新子矩阵或矩阵切片的新数据输入向量被加载到相应的向量单元。现有的权重输入向量可以重复使用,因为相对通道维度没有改变。通过仅加载新的增量卷积数据并重复使用权重数据元素,在执行卷积运算时,实现了显著的性能提高。
78.图9是示出用于解决分组卷积问题的示例卷积数据输入矩阵的图。在所示的例子中,三维卷积数据输入矩阵900包括三维子矩阵组901、903、905和909。在一些实施例中,通过将计算分布在多个处理元件上,使用卷积数据输入矩阵900来执行分组卷积问题。卷积数据输入矩阵900被划分成是分组卷积参数的组。作为示例,描绘了四个示例组901、903、905和909。在各种实施例中,图10中示出了对应的逐组卷积权重矩阵。在一些实施例中,卷积数据输入矩阵900是使用图5
‑
8的过程并由诸如图1的系统100的硬件系统来处理的激活数据矩阵或卷积数据输入矩阵。
79.在一些实施例中,卷积数据输入矩阵900的数据元素的一部分被分配给每个处理元件以用于执行卷积运算。例如,卷积数据输入矩阵900内的多个不同组中的每个组的第一通道可以被分配给第一处理元件。在一些实施例中,第一通道可以包括至少组901、903、905和909的第一通道。组901、903、905和909的每个第一通道是组的子矩阵或矩阵切片。继续该示例,卷积数据输入矩阵900内的多个不同组中的每个组的第二通道可以被分配给第二处理元件。类似地,第三通道可以被分配给第三处理元件,并且第四通道可以被分配给第四处理元件。在每个组的深度为四个通道的情况下,只需要四个处理元件来处理整个组。在各种实施例中,可以并行处理的组的数量基于处理元件的卷积引擎的配置。对于具有配置有32个向量单元的卷积引擎的处理元件,每个处理元件可以并行处理32个不同的组。因此,对于深度为四个通道的组,四个处理元件(每个处理元件配置有32个向量单元)可以并行处理32个组。在图9的示例中,示出了32个组中的4个。剩余的28个组位于组901、903、905和909的数据元素的相同高度和宽度位置,但是位于不同的通道深度。虽然示例中使用了四个通道,但根据情况,这些组可以有更少或更多的通道。类似地,卷积引擎可以配置有不同数量的向量单元来并行处理不同数量的组。在各种实施例中,即使当在少量通道上计算分组卷积时,所公开的技术和硬件平台也继续有效地利用硬件资源。
80.在所示的例子中,组901、903、905和909被描绘为具有特定的高度和宽度并且位于特定的xyz位置。使用所公开的技术,相似的组被分配给不同的处理元件。例如,组的不同行可以被分配给处理元件的不同组。作为另一个例子,组的不同列可以被分配给处理元件的不同组。类似地,在卷积数据输入矩阵900的深度超过处理元件的单个组的容量的情况下,处理元件的附加组可以被分配给沿着卷积数据输入矩阵900的深度的附加组。
81.在一些实施例中,卷积数据输入矩阵900内的组,例如组901、903、905和909,各自具有与相关联的三维逐组卷积权重矩阵相同的宽度、高度和深度(通道)维度。例如,组901、
903、905和909可以各自具有3x3x4的维度,其中每个矩阵切片具有3x3的维度。一个组的每个矩阵切片表示一个通道卷积处理器单元在一次迭代(或循环)期间可以处理的数据元素。在一些实施例中,后续迭代(或循环)通过沿着卷积数据输入矩阵900的宽度(或高度)维度水平地(或垂直地)滑动用作卷积参数的矩阵切片但保持相同的通道来处理数据元素的附加列(或行)。
82.在一些实施例中,组901、903、905和909表示用于一组处理元件的通道卷积引擎的数据输入的初始集合。同一组处理元件的数据输入的后续集合可以包括沿着宽度(或高度)维度而移位的组(未示出)。在一些实施例中,对于每个分别分配的处理元件,在图8的801准备好组901、903、905和909,并且在图8的811准备好后续移位的组。在各种实施例中,这些通道卷积引擎各自是图4的通道卷积引擎400。
83.在各种实施例中,通过数据输入单元(例如图4的数据输入单元403)将组的每个矩阵切片准备为通道卷积引擎的通道卷积处理器单元的参数。矩阵切片可以由数据输入单元通过将二维矩阵切片线性化为用于通道卷积处理器单元的向量单元的一维向量,而转换为对应的数据输入向量。在各种实施例中,使用通道优先布局(channel
‑
first layout)存储卷积数据输入矩阵900,并且使用通道优先布局存储器读取来检索相关联的组,例如组901、903、905和909。例如,卷积数据输入矩阵900的在宽度、高度和通道位置(1,1,1)处的数据元素与在宽度、高度和通道位置(1,1,2)处的数据元素被相邻地存储,并且这两个数据元素可以用单次存储器读取和/或缓存行存储器读取一起读取。对于32数据元素的缓存行,数据元素(1,1,1)至(1,1,32)可以在单次存储器读取中读取。后续读取可以加载宽度、高度和通道位置(1,2,1)至(1,2,32)处的数据元素。
84.图10是示出用于解决分组卷积问题的逐组卷积权重矩阵的示例集合的图。在所示的例子中,逐组卷积权重矩阵1001、1003、1005和1009是更大的逐组卷积权重矩阵集合的一部分,用于使用激活或卷积数据输入矩阵(例如图9的卷积数据输入矩阵900)内的组来解决分组卷积问题。逐组卷积权重矩阵的总数量可以匹配沿适用的卷积数据输入矩阵的通道维度的组数量。逐组卷积权重矩阵的子集与卷积数据参数内的多个选定组(例如图9的组901、903、905和909)相匹配,并被分配给处理元件集合以用于执行卷积运算。卷积运算由处理元件集合及其各自的卷积引擎执行。在一些实施例中,每个卷积引擎是通道卷积引擎,例如图4的通道卷积引擎400,并且处理元件是图1的系统100的处理元件。在所示的示例中,每个逐组卷积权重矩阵(例如逐组卷积权重矩阵1001、1003、1005和1009)的宽度、高度和深度(通道)维度匹配卷积数据输入矩阵内每个对应组(例如图9的组901、903、905和909)的宽度、高度和深度(通道)维度。例如,在一些实施例中,每个逐组卷积权重矩阵1001、1003、1005和1009具有3x3x4的维度,并且卷积数据输入矩阵的每个对应组(例如图9的组901、903、905和909)也具有3x3x4的维度。
85.在各种实施例中,逐组卷积权重矩阵的集合(例如逐组卷积权重矩阵1001、1003、1005和1009)的权重矩阵切片被准备作为通道卷积处理器单元的参数。例如,逐组卷积权重矩阵的单个通道是权重矩阵切片。每个权重矩阵切片是通道卷积引擎的通道卷积处理器单元的向量单元的权重输入参数。具有多个向量单元的通道卷积处理器单元能够处理多个权重矩阵切片。在一些实施例中,每个权重矩阵切片对应于来自不同逐组卷积权重矩阵的单个通道。例如,具有32个向量单元的通道卷积处理器单元可以处理来自32个不同的逐组卷
积权重矩阵的32个不同的权重矩阵切片。从32个不同的逐组卷积权重矩阵中的每一个中选择一个通道。每个逐组卷积权重矩阵对应于卷积数据输入矩阵内的不同组,并且逐组卷积权重矩阵的每个权重矩阵切片对应于卷积数据输入矩阵内的组的矩阵切片。对于深度为四个通道的逐组卷积权重矩阵,可以配置四个不同的处理元件来处理四个不同通道中的每一个。在每个处理元件的通道卷积处理器单元配置有32个向量单元的情况下,四个处理元件可以处理32个不同的逐组卷积权重矩阵和卷积数据输入矩阵内的对应组。尽管在该示例中使用了通道深度为四和配置有32个向量单元的通道卷积处理器单元,但是不同的通道深度和不同的通道卷积处理器单元配置也是适用的。
86.在一些实施例中,每个权重矩阵切片由卷积引擎的权重输入单元(例如图4的通道权重输入单元405)处理。权重矩阵切片可以由权重输入单元通过将二维权重矩阵切片线性化为用于通道卷积处理器单元的向量单元的一维向量,而转换为对应的权重输入向量。在一些实施例中,使用深度优先布局(depth
‑
first layout)来存储和检索逐组卷积权重矩阵1001、1003、1005和1009。在一些实施例中,类似于卷积数据输入矩阵内的对应组的布局,沿着深度维度一个紧接一个地(back
‑
to
‑
back)存储逐组卷积权重矩阵。例如,逐组卷积权重矩阵1001、1003、1005和1009的宽度和高度位置(1,1)处的数据元素彼此相邻地存储。在一些实施例中,(1,1)处的数据元素可以用单次存储器读取和/或缓存行存储器读取一起读取。后续读取可以加载逐组卷积权重矩阵1001、1003、1005和1009的宽度和高度位置(1,2)处的数据元素。
87.图11是示出用于求解分组卷积运算的示例数据元素组矩阵和对应的逐组卷积权重矩阵的图。在所示的例子中,数据元素组矩阵1100是来自卷积数据输入矩阵内的3x3x4矩阵组。在一些实施例中,数据元素组矩阵1100是图9的卷积数据输入矩阵900内的组,并且可以是图9的组901、903、905或909之一。在所示的例子中,权重矩阵1110是具有对应于数据元素组矩阵1100的权重数据元素的3x3x4逐组卷积权重矩阵。在一些实施例中,权重矩阵1110是图10的逐组卷积权重矩阵1001、1003、1005和1009之一。数据元素组矩阵1100和权重矩阵1110这两个矩阵是用于执行逐组卷积的一对逐组矩阵参数。使用本文公开的技术和硬件,分组卷积运算的计算被分布在多个处理元件上,并且结果被缩减以确定逐组卷积结果。在各种实施例中,使用图5
‑
8的过程和图1
‑
4的硬件来执行分组卷积运算。
88.在所示的例子中,数据元素组矩阵1100和权重矩阵1110各自包括四个3x3矩阵切片,这些矩阵切片中的每个位于不同的深度(或通道)。数据元素组矩阵1100包括分别位于深度1、2、3和4的数据组矩阵切片1101、1103、1105和1107。权重矩阵1110包括分别位于深度1、2、3和4的权重矩阵切片1111、1113、1115和1117。数据组矩阵切片1101被描绘为具有数据元素x
1,1
、x
1,2
、x
1,3
、x
2,1
、x
2,2
、x
2,3
、x
3,1
、x
3,2
和x
3,3
,其中下标表示宽度和高度位置。类似地,权重矩阵切片1111被描绘为具有权重元素w
1,1
、w
1,2
、w
1,3
、w
2,1
、w
2,2
、w
2,3
、w
3,1
、w
3,2
和w
3,3
,其中下标表示宽度和高度位置。共享相似下标的数据组矩阵切片1101的数据元素和权重矩阵切片1111的权重元素彼此对应以用于执行卷积运算。尽管未示出剩余矩阵切片的数据元素和权重元素,但是相同的关联适用于数据元素组矩阵1100和权重矩阵1110的每个矩阵切片对。每个数据组矩阵切片具有用于计算分组卷积的对应权重矩阵切片。例如,数据组矩阵切片1101与权重矩阵切片1111配对。类似地,数据组矩阵切片1103、1105和1107分别与权重矩阵切片1113、1115和1117配对。
89.在一些实施例中,每个矩阵切片对被传输到不同处理元件的卷积引擎。在卷积引擎处,矩阵切片对被处理并被馈送到向量单元,在向量单元中执行卷积运算以确定卷积结果。例如,输入对数据组矩阵切片1101和权重矩阵切片1111的卷积结果在第一处理元件处被求解。输入对数据组矩阵切片1103和权重矩阵切片1113的卷积结果在第二处理元件处被求解。输入对数据组矩阵切片1105和权重矩阵切片1115的卷积结果在第三处理元件处被求解。并且输入对数据组矩阵切片1107和权重矩阵切片1117的卷积结果在第四处理元件处被求解。将四个卷积结果合计在一起,以确定逐组卷积结果数据元素。在一些实施例中,使用处理元件之间具有对等连接的缩减网络来执行合计。在上面的示例中,仅利用了来自四个处理元件中的每一个的卷积处理器单元的单个向量单元。通道卷积处理器单元的每个附加向量单元可以用于处理来自不同对的数据元素组和对应的逐组卷积权重矩阵的附加矩阵切片对。例如,配置有32个向量单元的通道卷积处理器单元可以处理来自32个不同的数据元素组矩阵和对应的逐组卷积权重矩阵的单个通道(或矩阵切片对)。对于在四个通道上计算的分组卷积问题,四个处理元件可以确定32个对应的分组卷积结果数据元素。
90.尽管为了清楚理解的目的已经详细描述了前述实施例,但是本发明不限于所提供的细节。有许多实现本发明的替代方式。所公开的实施例是说明性的,而不是限制性的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1