一种基于Mask-RCNN的非机动车驾驶员正背面匹配方法
本发明涉及图像匹配领域,尤其涉及一种基于mask-rcnn的非机动车驾驶员正背面匹配方法。
背景技术:
在城市文明建设中一个突出的问题如何有效地管制马路上的违法行为,比如机动车闯红灯,占用非机动车道等。对于存在违法行为的机动车,我们可以通过摄像头拍摄到的照片提取出其车牌号。然而,这种方法无法应用于非机动车。这是因为非机动车只在车辆的后面有车牌,如果摄像头捕获的是非机动车的正面照,则无法获取其的车牌号。一种有效的方式是我们将非机动车的正面照与其背面照进行匹配。然而现有的图像匹配方法都是基于大面积的相同特征,比如行人的正面的匹配。对于非机动车驾驶员的正面和背面,由于没有大量重复的特征,无法之间使用现有的图像匹配方法。因此,有必要提出一个可以匹配非机动车正背面照的方法。
技术实现要素:
本发明要克服现有技术的上述缺点,提供一种基于mask-rcnn的非机动车驾驶员正背面匹配方法。
本发明利用摄像头拍摄图片的时间,采用mask-rcnn实体分割,和神经网络特征表示技术来匹配非机动车驾驶员正面和背面。本发明利用图片的拍摄时间是保证两个待匹配的驾驶员穿着没有改变;利用mask-rcnn提取出图片中的驾驶员和非机动车,以排除周围物体的干扰;利用多层神经网络的抽象特征提取能力,并串联两个待匹配的图片的特征,以检测这两个特征的相容性。本发明可以辅助违法非机动车的识别,特别是在只拍着到非机动车的正面照而无法获取其后面的车牌信息。
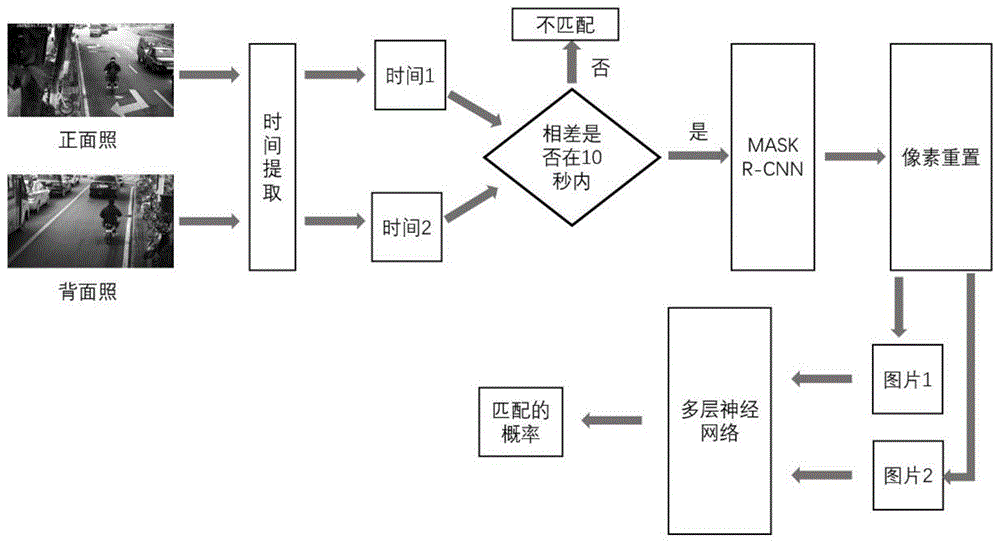
一种基于mask-rcnn的非机动车驾驶员正背面匹配方法,其包括以下步骤:
s1:提取出两幅待匹配图片的拍摄时间;
s2:计算s1中的时间差,若时间在10秒内,则继续匹配;否则匹配不成功;
s3:利用mask-rcnn算法截取出图片中的非机动车及驾驶员;
s4:依据s3中截取的图片对原图片像素重置;
s5:利用多层神经网络对s4中得到的图片进行特征提取、串联和计算是否匹配的概率。
其中步骤s1具体包括:截取出图片中保存拍摄时间的区域;提取图片中的轮廓,对字符图片进行分割,和字符识别。
其中步骤s2具体包括:用y1,m1,d1,h1,n1,s1分别表示图片1拍照的年、月、日、时、分、秒;用y2,m2,d2,h2,n2,s2分别表示图片2拍照的年、月、日、时、分、秒。如满足以下条件,则进行步骤s3;否则认为匹配不成功。其中,&表示并且,||表示数值的绝对值,<表示小于。
(y1=y2)&(m1=m2)&(d1=d2)&|3600*h1+60*n1+s1-3600*h2-60*n2-s2|<10
其中在步骤s3的mask-rcnn算法中,只有有驾驶员坐在非机动车上的区域分类为1,其它区域为0;mask层的输出维度为14*14*1。
其中步骤s4的具体包括:被截取的片段部分保留原图片像素,其它像素值统一置为(255,255,255),即颜色为白色。
其中步骤s5的具体包括:
s5.1:将待匹配的两幅图片经过卷积、最大池化、卷积后,输出各自的特征映射;
s5.2:将由s5.1得到的两个特征进行前后串联,正面图片的特征在前,背面图片的特征在后;
s5.3:将由s5.2得到图特征经过卷积、最大池化和卷积,输出一个多维的向量;
s5.4:将s5.3得到的向量输入到两层全连接层,最后通过一个sigmoid激活函数输出匹配概率。在训练模型时,损失函数定义为:
本发明的方法从限制拍照时间,提取实体,和利用多层神经网络的向量表示三个方面来进行非机动车驾驶员的正背面匹配,具有较高的准确率。
本发明的优点是:辅助违法非机动车的识别,特别是在只拍着到非机动车的正面照而无法获取其后面的车牌信息的情况。
附图说明
图1是本发明方法的流程图。
图2是本发明提取图片的拍照时间的流程图。
图3是本发明通过mask-rcnn截取实体区域和像素重置的流程图。
图4是本发明通过多层神经网络检测两幅图片是否匹配的流程图。
具体实施方式
下面结合附图,进一步说明本发明的技术方案。
本发明实施实例提供了一种基于maskr-cnn的非机动车驾驶员正背面匹配方法,流程如图1所示,包括以下步骤:
s1:提取两幅待匹配图像的拍照时间,步骤如下:
s1.1:由于图片的拍照时间存放在图片的左上角,我们先截取图片左边的50%和上面的5%处;
s1.2:使用opencv-python库里的canny函数检测图片轮廓,上下阈值分别设为150和200;
s1.3:由于拍照时间存放的位置固定,我们从第一个字符出现的位置开始,每个27个单位截取一个字符,最后只保留年、月、日、时、分、秒,日,比如20190203091041;
s1.4:使用1000张被截取的字符图片训练scikit-learn库里默认的线性svm,最大迭代次数为1000次,并将训练好的模型去识别图片的拍照时间。其中svm是一个分类模型,可把图片分成0-9中的某一类,对应的类别就是图片里的数字。
s2:判断两幅图片的拍照时间差。用y1,m1,d1,h1,n1,s1分别表示图片1拍照的年、月、日、时、分、秒;用y2,m2,d2,h2,n2,s2分别表示图片2拍照的年、月、日、时、分、秒。如满足以下条件,则进行步骤s3;否则认为匹配不成功。其中,&表示并且,||表示数值的绝对值,<表示小于。
(y1=y2)&(m1=m2)&(d1=d2)&|3600*h1+60*n1+s1-3600*h2-60*n2-s2|<10
s3:使用包括maskr-cnn算法标识出非机动车驾驶员。mask-rcnn是一个可以分割出图片里面所需要的实体的算法,其如下步骤:
s3.1:选用5000张非机动车驾驶员的正面照和5000张非机动车驾驶员背面照作为训练集,再各自另选1000张作为验证集;
s3.2:对所有训练集和验证集,标志出需要分割的区域。该区域为驾驶员坐在非机动车上,非机动车包括自行车,电动车和三轮车;
s3.3:搭建mask-rcnn模型。该模型首先通过卷积,池化和rpn网络生成多个候选区域。对每个候选区域,通过roialign层和卷积层后,得到分类误差,box误差和mask误差。其中,只有有驾驶员坐在非机动车上的区域分类为1,其它区域为0。由于对于一个图片我们只需要截取出一个区域,所以mask层的输出维度为14*14*1;
s3.4:使用训练集和验证集训练mask-rcnn模型,并将训练好的模型去分割出其它所有图片的非机动和驾驶员区域。
s4:像素重置。对于每个图片,其在s3中检测出来的区域的像素值不变,其它像素值统一置为(255,255,255),即颜色为白色;
s5:对s4中得到图片进行匹配,步骤如下:
s5.1:对于每个正面图片image1,获取其背面图片image2。将该两张图片通过两层卷积网络和一层最大池化和得到各自的特征feature1,feature2。
s5.2:将s5.1中得到的feature1和feature2前后串联,feature1在前,feature2在后。
s5.3:将s5.2中得到的串联特征通过两个卷积层和池化操作得到1048维特征。
s5.4:将s5.3中得到的1048维特征通过两层全连接层和sigmoid激活函数,输出两个图片成功匹配的概率。在本次实施案例中,我们认为最后输出概率大于0.8时,则表示两个图片匹配成功。在训练神经网络时,我们先采样两个匹配的图片image1和image2,和两个没有匹配的image3和image4。这两组图片的输出匹配概率分别为r1和r2,则造损失函数定义为:
- 还没有人留言评论。精彩留言会获得点赞!