基于深度学习的英语阅读推荐实现方法与流程
本发明涉及智慧学习领域,尤其涉及基于深度学习的英语阅读推荐实现方法。
背景技术:
经检索,中国专利号cn109977408a公开了基于深度学习的英语阅读分级和读物推荐系统的实现方法,该方法虽然操作简单,但是无法对用户的阅读喜好进行判断更新;英语是按照分布面积而言最流行的语言,它是学习最广泛的第二语言,是近60个主权国家的官方语言或官方语言之一,是全球化时代绝大多数国际型活动的首选工作语言。作为公认的使用最普遍的国际通用语言或全球通用语,英语被广泛地运用于会议、期刊和图书出版、新闻传播等方面,在此情形之下,世界各地的高等教育院校和教育机构多数都开设了包括学历教育和非学历教育等不同形式的英语教学课程,聘请和培训各类英语师资承担教学任务,英语教材和教辅材料更是种类繁多,形式多样,与此同时,各种类型的社会办学机构也纷纷推出英语教学课程,与英语水平测试相关的各种培训班更是随处可见;因此,发明出基于深度学习的英语阅读推荐实现方法变得尤为重要;
首先,现有的基于深度学习的英语阅读推荐实现方法对用户阅读喜好判断无法更新,当用户阅读时间过长后,容易推荐用户已经不感兴趣的英语读物,影响用户阅读体验,同时浪费用户阅读时间,其次,现有的基于深度学习的英语阅读推荐实现方法无法对用户可阅读的英语读物进行准确的推荐,降低了平台推荐的准确性,降低用户阅读效率;为此,我们提出基于深度学习的英语阅读推荐实现方法。
技术实现要素:
本发明的目的是为了解决现有技术中存在的缺陷,而提出的基于深度学习的英语阅读推荐实现方法。
为了实现上述目的,本发明采用了如下技术方案:
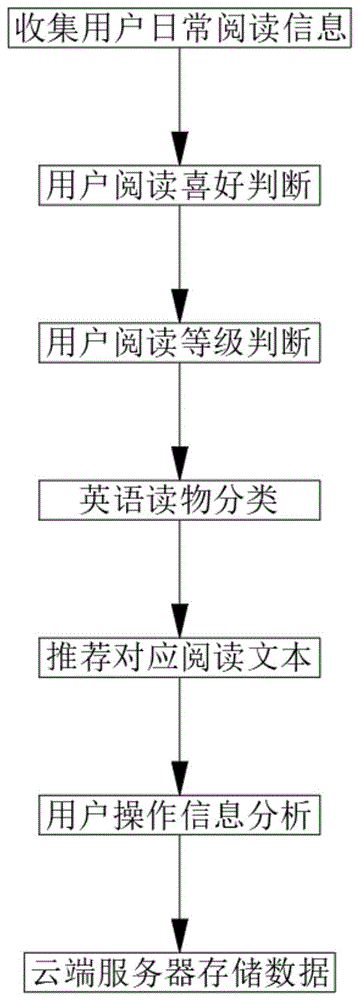
基于深度学习的英语阅读推荐实现方法,该推荐方法具体步骤如下:
(1)收集用户日常阅读信息:阅读平台收集用户的阅读信息并处理生成基础数据;
(2)用户阅读喜好判断:判断系统对基础数据进行阅读喜好判断并处理生成喜好数据;
(3)用户阅读等级判断:分析系统对基础数据进行阅读等级判断并处理生成等级数据;
(4)英语读物分类:将数据库中的英语读物进行分类标记并处理生成配对数据;
(5)推荐对应阅读文本:收集喜好数据、等级数据与配对数据进行相关英语读物推荐;
(6)用户操作信息分析:对用户后续操作信息进行收集与分析并处理生成对比数据;
(7)云端服务器存储数据:收集对比数据与基础数据进行对比分析生成用户数据并进行存储。
进一步地,步骤(1)中所述阅读平台通过分析用户日常浏览痕迹对用户日常阅读信息进行收集并处理生成基础数据,其中,阅读平台为阅读网站或阅读软件中的一种。
进一步地,步骤(2)中所述判断系统通过喜好判断模块对基础数据进行判断分析并处理生成喜好数据,其具体判断分析步骤如下:
步骤一:分析基础数据并记录用户浏览不同类型英语读物的次数,不同类型包括虚幻文体与纪实文体;
步骤二:记录用户浏览虚幻文体的次数n与浏览纪实文体次数i,n,i都为自然数,同时对一定浏览量中n与i分别所占百分比进行计算。
进一步地,步骤(3)中所述分析系统通过阅读等级分析模块对基础数据进行分析判断并处理生成等级数据,其具体分析判断步骤如下:
第一步:分析基础数据并对用户日常阅读等级进行分析判断并进行记录;
第二步:根据用户日常阅读的读物中词汇量、词汇常见度、句型种类以及不同句型出现次数将用户阅读等级分为简单、普通以及困难并分别标记为a、b与c;
第三步:记录阅读a的次数a,记录阅读b的次数b,记录阅读c的次数c;
第四步:计算一定浏览量内a、b以及c分别所占的百分比。
进一步地,步骤(4)中所述数据库通过分类模块对存储的英语读物进行分类标记并处理生成配对数据,其具体分类标记步骤如下:
s1:将数据库中所存储的英语读物按照虚幻文体与纪实文体进行分类并分别标记为x与y;
s2:将x的阅读难度按照词汇量、词汇常见度、句型种类以及不同句型出现次数分为简单、普通以及困难并分别标记为j、k与l;
s3:将y的阅读难度按照词汇量、词汇常见度、句型种类以及不同句型出现次数分为简单、普通以及困难并分别标记为u、i与o。
进一步地,步骤(5)中所述n、i、a、b以及c经过整合判断后,阅读平台开始向用户推荐对应英语读物,其具体整合判断步骤如下:
ⅰ、当n>i时,进行第二次判断分析,其具体判断分析步骤如下:
ss1:当a>b>c或a>c>b时,阅读平台向用户推荐j类的英语读物;
ss2:当b>a>c或b>c>a时,阅读平台向用户推荐k类的英语读物;
ss3:当c>a>b或c>b>a时,阅读平台向用户推荐l类的英语读物;
ss4:当a=b=c时,阅读平台向用户随机推荐j、k或l类的英语读物;
ⅱ、当i>n时,进行第二次判断分析,其具体判断分析步骤如下:
sss1:当a>b>c或a>c>b时,阅读平台向用户推荐u类的英语读物;
sss2:当b>a>c或b>c>a时,阅读平台向用户推荐i类的英语读物;
sss3:当c>a>b或c>b>a时,阅读平台向用户推荐o类的英语读物;
sss4:当a=b=c时,阅读平台向用户随机推荐u、i或o类的英语读物;
ⅲ、当n=i时,进行第二次判断分析,其具体判断分析步骤如下:
ssss1:当a>b>c或a>c>b时,阅读平台向用户随机推荐j或u类的英语读物;
ssss2:当b>a>c或b>c>a时,阅读平台向用户随机推荐k或i类的英语读物;
ssss3:当c>a>b或c>b>a时,阅读平台向用户随机推荐l或o类的英语读物;
ssss4:当a=b=c时,阅读平台向用户随机推荐j、k、l、u、i或o类的英语读物。
进一步地,步骤(6)中所述用户对推荐的读物进行阅读或不阅读的操作由阅读平台进行操作记录并处理生成对比数据。
进一步地,步骤(7)中所述对比数据与基础数据通过阅读平台进行整合分析后重新对用户喜爱阅读的英语读类别进行别判断并处理生成用户数据,将用户数据按照数据字典的定义进行转换处理生成存储数据并上传至云端服务器进行存储。
相比于现有技术,本发明的有益效果在于:
1、该基于深度学习的英语阅读推荐实现方法,数据库通过分类模块对存储的英语读物按照虚幻文体与纪实文体进行分类并分别标记为x与y,将x的阅读难度按照词汇量、词汇常见度、句型种类以及不同句型出现次数分为简单、普通以及困难并分别标记为j、k与l,将y的阅读难度按照词汇量、词汇常见度、句型种类以及不同句型出现次数分为简单、普通以及困难并分别标记为u、i与o,将英语读物按照不同体裁与难易度进行划分后方便阅读平台根据用户阅读喜好推荐对应英语读物,提高平台推荐的准确性,提高用户阅读效率;
2、该基于深度学习的英语阅读推荐实现方法中用户对推荐的读物进行阅读或不阅读的操作由阅读平台进行操作记录并处理生成对比数据,对比数据与基础数据通过阅读平台进行整合分析后重新对用户喜爱阅读的英语读类别进行别判断并处理生成用户数据,将用户数据按照数据字典的定义进行转换处理生成存储数据并上传至云端服务器进行存储,能够不断的更新用户阅读喜好,提高阅读平台的推荐质量,提高用户阅读体验,节省用户阅读时间。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
图1为本发明提出的基于深度学习的英语阅读推荐实现方法的流程框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
在本发明的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
参照图1,基于深度学习的英语阅读推荐实现方法,该推荐方法具体步骤如下:
(1)收集用户日常阅读信息:阅读平台收集用户的阅读信息并处理生成基础数据;
(2)用户阅读喜好判断:判断系统对基础数据进行阅读喜好判断并处理生成喜好数据;
(3)用户阅读等级判断:分析系统对基础数据进行阅读等级判断并处理生成等级数据;
(4)英语读物分类:将数据库中的英语读物进行分类标记并处理生成配对数据;
(5)推荐对应阅读文本:收集喜好数据、等级数据与配对数据进行相关英语读物推荐;
(6)用户操作信息分析:对用户后续操作信息进行收集与分析并处理生成对比数据;
(7)云端服务器存储数据:收集对比数据与基础数据进行对比分析生成用户数据并进行存储。
步骤(1)中所述阅读平台通过分析用户日常浏览痕迹对用户日常阅读信息进行收集并处理生成基础数据,其中,阅读平台为阅读网站或阅读软件中的一种。
步骤(2)中所述判断系统通过喜好判断模块对基础数据进行判断分析并处理生成喜好数据,其具体判断分析步骤如下:
步骤一:分析基础数据并记录用户浏览不同类型英语读物的次数,不同类型包括虚幻文体与纪实文体;
步骤二:记录用户浏览虚幻文体的次数n与浏览纪实文体次数i,n,i都为自然数,同时对一定浏览量中n与i分别所占百分比进行计算。
步骤(3)中所述分析系统通过阅读等级分析模块对基础数据进行分析判断并处理生成等级数据,其具体分析判断步骤如下:
第一步:分析基础数据并对用户日常阅读等级进行分析判断并进行记录;
第二步:根据用户日常阅读的读物中词汇量、词汇常见度、句型种类以及不同句型出现次数将用户阅读等级分为简单、普通以及困难并分别标记为a、b与c;
第三步:记录阅读a的次数a,记录阅读b的次数b,记录阅读c的次数c;
第四步:计算一定浏览量内a、b以及c分别所占的百分比。
步骤(4)中所述数据库通过分类模块对存储的英语读物进行分类标记并处理生成配对数据,其具体分类标记步骤如下:
s1:将数据库中所存储的英语读物按照虚幻文体与纪实文体进行分类并分别标记为x与y;
s2:将x的阅读难度按照词汇量、词汇常见度、句型种类以及不同句型出现次数分为简单、普通以及困难并分别标记为j、k与l;
s3:将y的阅读难度按照词汇量、词汇常见度、句型种类以及不同句型出现次数分为简单、普通以及困难并分别标记为u、i与o。
步骤(5)中所述n、i、a、b以及c经过整合判断后,阅读平台开始向用户推荐对应英语读物,其具体整合判断步骤如下:
ⅰ、当n>i时,进行第二次判断分析,其具体判断分析步骤如下:
ss1:当a>b>c或a>c>b时,阅读平台向用户推荐j类的英语读物;
ss2:当b>a>c或b>c>a时,阅读平台向用户推荐k类的英语读物;
ss3:当c>a>b或c>b>a时,阅读平台向用户推荐l类的英语读物;
ss4:当a=b=c时,阅读平台向用户随机推荐j、k或l类的英语读物;
ⅱ、当i>n时,进行第二次判断分析,其具体判断分析步骤如下:
sss1:当a>b>c或a>c>b时,阅读平台向用户推荐u类的英语读物;
sss2:当b>a>c或b>c>a时,阅读平台向用户推荐i类的英语读物;
sss3:当c>a>b或c>b>a时,阅读平台向用户推荐o类的英语读物;
sss4:当a=b=c时,阅读平台向用户随机推荐u、i或o类的英语读物;
ⅲ、当n=i时,进行第二次判断分析,其具体判断分析步骤如下:
ssss1:当a>b>c或a>c>b时,阅读平台向用户随机推荐j或u类的英语读物;
ssss2:当b>a>c或b>c>a时,阅读平台向用户随机推荐k或i类的英语读物;
ssss3:当c>a>b或c>b>a时,阅读平台向用户随机推荐l或o类的英语读物;
ssss4:当a=b=c时,阅读平台向用户随机推荐j、k、l、u、i或o类的英语读物。
步骤(6)中所述用户对推荐的读物进行阅读或不阅读的操作由阅读平台进行操作记录并处理生成对比数据。
步骤(7)中所述对比数据与基础数据通过阅读平台进行整合分析后处理生成用户数据,将用户数据按照数据字典的定义进行转换处理生成存储数据并上传至云端服务器进行存储。
本发明的工作原理及使用流程:该基于深度学习的英语阅读推荐实现方法,首先,阅读平台通过分析用户日常浏览痕迹对用户日常阅读信息进行收集并处理生成基础数据,其中,阅读平台为阅读网站或阅读软件中的一种,判断系统通过喜好判断模块对基础数据进行判断分析并处理生成喜好数据,其具体判断分析步骤如下:分析基础数据并记录用户浏览不同类型英语读物的次数,不同类型包括虚幻文体与纪实文体;记录用户浏览虚幻文体的次数n与浏览纪实文体次数i,n,i都为自然数,同时对一定浏览量中n与i分别所占百分比进行计算;分析系统通过阅读等级分析模块对基础数据进行分析判断并处理生成等级数据,其具体分析判断步骤如下:分析基础数据并对用户日常阅读等级进行分析判断并进行记录;根据用户日常阅读的读物中词汇量、词汇常见度、句型种类以及不同句型出现次数将用户阅读等级分为简单、普通以及困难并分别标记为a、b与c;记录阅读a的次数a,记录阅读b的次数b,记录阅读c的次数c;计算一定浏览量内a、b以及c分别所占的百分比;数据库通过分类模块对存储的英语读物进行分类标记并处理生成配对数据,分类模块通过对英语读物的不同体裁以及难易度分成j、k、l、u、i以及o,其中不同体裁包括虚幻文体与纪实文体,不同难易度分为简单、普通以及困难,将n、i、a、b以及c经过整合判断后,阅读平台开始向用户推荐对应英语读物,用户对推荐的读物进行阅读或不阅读的操作由阅读平台进行操作记录并处理生成对比数据,对比数据与基础数据通过阅读平台进行整合分析后重新对用户喜爱阅读的英语读类别进行别判断并处理生成用户数据,将用户数据按照数据字典的定义进行转换处理生成存储数据并上传至云端服务器进行存储。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!