一种基于多维残差网络的脊柱CT图像识别方法
一种基于多维残差网络的脊柱ct图像识别方法
技术领域
1.本发明涉及一种脊柱ct图像识别方法,特别涉及一种基于多维残差网络的脊柱ct图像识别方法。
背景技术:
2.目前,在医学领域,深度学习主要应用在医学图像识别、医学图像分割和计算机辅助疾病诊断三个方面,减少医护人员重复繁重的工作量,为智慧医疗提供便利。2016年yunliangcai等人提出了一种使用变换式深度卷积网络(tdcn)的多模式椎骨识别框架。tdcn自动提取模态并进行自适应,高判别,构成不变特征以供识别。使用基于tdcn的识别系统可以同时识别位置,标记mr和ct中的椎骨结构姿势。系统已成功通过多模式数据集的测试用于腰椎和整个脊柱扫描,具有很高的准确性和稳定性。2017年anjanysekuboyina等人提出了一个具有深层网络的两阶段方法,对腰椎区域进行定位并将其分为多个类别。该实验在xvertseg数据集上性能达到了90%以上的平均dice系数,此外还强调了该实验处理脊椎严重畸形的能力。2018年rensjanssens等人提出了一种基于卷积神经网络(cnn)的级联方法,用于从ct数据中自动分割腰椎,该实验在公开数据集上进行评估,该方法获得了平均dice系数为95.77
±
0.81%,平均对称表面距离为0.37
±
0.06mm,实验效果显著。这些方法大多数都结合了执行体素分类或对椎体质心或边界框进行回归来生成椎骨,并使用全局模型来完善各个预测,丢弃异常值并找到整体上可行的解决方案。这些模型通常是图形化的隐马尔可夫模型,如2015年,chengwen chu,daniel l.belav等人提出了一个全自动、统一的射频回归和分类框架,解决了ct图像或mr图像中区域定位和分割两个重要问题,在10个ct数据和23个3d mri数据上验证和评估了拟议的框架,达到与最新方法相当的细分效果。同年,针对另一模型——组织形状模型,bromiley等人描述了一种用于在包含任意脊柱区域3dct卷中进行全自动椎骨定位和分割的系统,目的是识别骨质疏松性骨折。
3.现有的大多数深度学习脊柱病态识别系统大部分是通过单通道或多通道的二维卷积神经网络(2dcnn)来实现的,尽管通过2dcnn在一定程度上能实现识别病态脊柱的功能。但实际上,医学影像尤其是ct影像,一般为存储格式为dicom、analyze和nifti等的三维图像,在此情况下,使用2dcnn无疑是将医学图像进行降维处理,在一定程度上忽视了空间信息,在识别病态脊柱上存在一定的偏差。另一方面,随着训练层数的增加,深度学习一般会越来越难,有些网络在开始收敛时,还可能出现退化的问题,导致准确率很快达到饱和,出现层数越深、错误率越高的现象。
4.现有技术针对脊柱ct得病态识别基本都是使用二维卷积神经网络,在很大程度上会丢失空间信息,降低准确率。而且现有的有关脊柱的数据集过少,没有办法大批量训练,就导致容错率就更低了。
技术实现要素:
5.本发明为解决公知技术中存在的技术问题而提供一种基于多维残差网络的脊柱
ct图像识别方法。
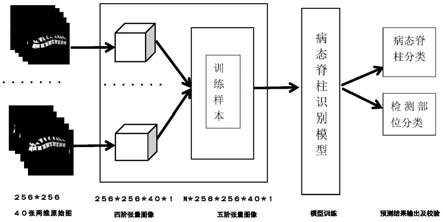
6.本发明为解决公知技术中存在的技术问题所采取的技术方案是:一种基于多维残差网络的脊柱ct图像识别方法,建立基于多维残差神经网络的病态脊柱识别模型;对训练样本设置标签并进行升维处理,使之维度与多维残差神经网络相匹配;使用处理后的训练样本对病态脊柱识别模型进行训练;然后将待识别的脊柱ct图像进行升维,使之维度与多维残差神经网络相匹配;由病态脊柱识别模型输出识别特征。
7.进一步地,多维残差神经网络采用resnet20、resnet34或resnet50。
8.进一步地,病态脊柱识别模型包括依次连接的多个卷积层、压平层及全连接层。
9.进一步地,多维残差神经网络的维度为5~6维。
10.进一步地,对训练样本依次通过reshape函数和concatenate函数实现升维。
11.进一步地,对待识别的脊柱ct图像依次通过reshape函数和concatenate函数实现升维。
12.进一步地,对训练样本设置多个标签。
13.进一步地,病态脊柱识别模型的分类损失函数选择二元分类器;每个输出的标签作为一个独立的伯努利分布,并且单独惩罚每一个输出节点。
14.进一步地,二元分类器采用如下表达式:
[0015][0016]
式中,l
mui
表示多标签损失函数;n为样本数量;i
i
表示第i个标签的值,当目标图像符合标签特征时,i
i
=1;反之,i
i
=0;p(i
i
)是第i个标签特征为真的概率。
[0017]
进一步地,采用verse2019数据集作为训练样本集,将数据集中的ct图像由nii格式转换为png格式,并将已生成的图像转化为256
×
256像素,从ct图像中删除不需要的噪声像素,同时保留ct图像的特征像素,进行多标签标记。
[0018]
本发明具有的优点和积极效果是:
[0019]
通过构建多维残差网络架构,一方面,残差网络具有在训练多层次神经网络,准确率不退化的特点,在训练样本数目较小的前提下,可以很好的训练出较为理想的实验结果;另一方面,由于ct医学影像多为3d甚至更多维的数据集合,通过训练3d卷积神经,能很好地保留ct医学影像的空间信息,更综合更准确地识别影像特征。
[0020]
在图像的分类和识别领域,传统的单标签分类旨在解决一个示例只属于一个类别的问题。然而,在更加复杂的分类任务中,如ct医学影像等一些实际应用中,常常会出现一个医学图像同时属于多个类别,这个时候多标签就能很好地实现同时识别一个医学图像的不同特征表现,通过构建多标签识别模型,可以更多方位、多维度地分析ct医学影像的特征。
附图说明
[0021]
图1是本发明的一种对训练样本两次升维处理的工作流程图。
具体实施方式
[0022]
为能进一步了解本发明的发明内容、特点及功效,兹列举以下实施例,并配合附图
详细说明如下:
[0023]
请参见图1,一种基于多维残差网络的脊柱ct图像识别方法,建立基于多维残差神经网络的病态脊柱识别模型;对训练样本设置标签并进行升维处理,使之维度与多维残差神经网络相匹配;使用处理后的训练样本对病态脊柱识别模型进行训练;然后将待识别的脊柱ct图像进行升维,使之维度与多维残差神经网络相匹配;由病态脊柱识别模型输出识别特征。
[0024]
多维残差神经网络可采用现有技术中适用的残差神经网络,进一步地,多维残差神经网络优选采用resnet20、resnet34或resnet50。
[0025]
进一步地,病态脊柱识别模型可包括依次连接的多个卷积层、压平层及全连接层。卷积层优选为5至21层。
[0026]
多维残差神经网络的维度可为5~9维。进一步地,多维残差神经网络的维度优选为5至6维。
[0027]
对训练样本可采用现有技术中的升维方法进行升维,进一步地,对训练样本可依次通过reshape函数和concatenate函数实现升维。先通过reshape函数进行变换,再经过concatenate函数变换,实现对训练样本两次升维。
[0028]
reshape函数是numpy中将指定的矩阵变换成特定维数矩阵一种函数,且矩阵中元素个数不变,函数可以重新调整矩阵的行数、列数、维数。函数语法为b=reshape(a,newshape,order='c')是指返回一个指定维数的的n维数组。
[0029]
concatenate函数可根据指定的维度,对一个元组、列表中的序列或者数组进行连接。
[0030]
对待识别的脊柱ct图像可采用现有技术中的升维方法进行升维,进一步地,对待识别的脊柱ct图像可依次通过reshape函数和concatenate函数实现升维。可先通过reshape函数进行变换,再经过concatenate函数变换,实现对待识别的脊柱ct图像两次升维。
[0031]
对训练样本可采用现有技术中的标签标识方法进行标识;可对训练样本标识一种以上标签,进一步地,对训练样本优选设置多个标签。可采用verse2019数据集作为训练样本集,可将数据集中的ct图像由nii格式转换为png格式,并将已生成的图像转化为256
×
256像素,从ct图像中删除不需要的噪声像素,同时保留ct图像的特征像素,进行多标签标记。
[0032]
病态脊柱识别模型的分类损失函数可采用现有技术中适用的分类损失函数;进一步地,病态脊柱识别模型的分类损失函数可选择二元分类器;每个输出的标签可作为一个独立的伯努利分布,并且单独惩罚每一个输出节点。
[0033]
进一步地,二元分类器可采用如下表达式:
[0034][0035]
式中,l
mui
表示多标签损失函数;n为样本数量;i
i
表示第i个标签的值,当目标图像符合标签特征时,i
i
=1;反之,i
i
=0;p(i
i
)是第i个标签特征为真的概率。
[0036]
下面以本发明的一个优选实施例来进一步说明本发明的工作流程及工作原理:
[0037]
考虑到resnet50在图像识别的优秀表现,残差神经网络选用resnet50。
[0038]
对原生残差网络进行了改进,如图1,将残差网络的输入作了升维操作,将2维的输入信号升维为5维,即将40张256*256的图像升维为n*256*256*40*1的五阶张量图像,如图1中的病态脊柱识别模型输入为五阶张量图像,保证训练图像能很好地处理和训练空间信息,同时设置合适的损失函数,通过对病态脊柱识别模型进行反复训练,达到平衡,提高整体算法的准确性。
[0039]
1、多标签的病态脊柱识别模型的神经网络架构的设计
[0040]
考虑到resnet50在图像识别的优秀表现,通过使用resnet50作为骨干网络。其中,本文主要识别的图像尺寸为256*256*40,病态脊柱识别模型的神经网络依次包括5个卷积层、压平层和全连接层。具体结构如下表所示:
[0041][0042]
注:flatten层,中文释义压平层,其用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。flatten不影响batch(批量)的大小。
[0043]
2、损失函数的设计
[0044]
虽然搭建的病态脊柱识别模型是多标签的病态脊柱的三维识别模型,但在选取损失函数时仍倾向选择二元分类器,主要是多标签分类的目标是将每个输出的标签作为一个独立的伯努利分布,并且希望单独惩罚每一个输出节点。为了更符合病态脊柱识别模型需求,将二元分类器进行相应变形,如下表达式所示:
[0045][0046]
式中,l
mui
表示多标签损失函数;n为样本数量;i
i
表示第i个标签的值,当目标图像符合标签特征时,i
i
=1;反之,i
i
=0;p(i
i
)是第i个标签特征为真的概率。
[0047]
3、训练样本编辑及预处理
[0048]
选用verse2019数据集,数据集包括来自141位患者的160例脊柱多识别计算机断层扫描(mdct)图像系列。在此阶段,首先将数据集中的ct图像由nii格式转换为png格式,并将已生成的图像转化为256
×
256像素,从ct图像中删除不需要的噪声像素,同时保留ct图像的特征像素,进行多标签标记,方便后期训练使用。
[0049]
4、训练病态脊柱模型:由于采用多维残差网络的网络框架,能更深层次的加大训练力度及深度,全方位分析图形特征,采用多标签训练样本对病态脊柱识别模型进行训练,通过损失函数及其权重设置提高模型的准确率,使病态脊柱识别模型同时实现病态脊柱与非病态脊柱、识别部位等双标签的识别任务。
[0050]
5、病态脊柱自动识别:病态脊柱识别模型训练完成后,将患者的病态脊柱ct文件经过与训练样本同样方式的预处理后,输入到病态脊柱识别模型中,对患者的病态脊柱进行识别,病态脊柱识别模型会输出患者的病态脊柱在各个标签下的可能性,最终实现用病态脊柱识别模型对患者的病态脊柱ct文件进行病情诊断。
[0051]
以上所述的实施例仅用于说明本发明的技术思想及特点,其目的在于使本领域内的技术人员能够理解本发明的内容并据以实施,不能仅以本实施例来限定本发明的专利范围,即凡本发明所揭示的精神所作的同等变化或修饰,仍落在本发明的专利范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1