一种基于分层技术的分类模型倾向性检验方法及系统与流程
1.本发明涉及区块链和机器学习领域,具体涉及一种基于分层技术的分类模型倾向性检验方法及系统。
背景技术:
2.在通过使用训练数据训练好一个机器学习分类模型后,通常情况下,一个好的分类模型应当能充分学习到训练数据的本质特征表达,同时在迁移到其他待分类的数据上也有很好的性能表现,即具有较好的泛化性。然而,由于模型性能不仅会受到自身算法设计的合理性的影响还会受到训练数据类别比例的影响,呈现出对某些类别数据识别性能好,对通过使用少数样本训练的数据类识别性能差的现象,如何验证模型是否存在对不同类别数据敏感性差异的问题(即倾向性),对于评估模型泛化性能以及数据集和识别任务调整上具有较大意义。
3.模型的分类性能评估的方法一般可以通过计算准确率、召回率、绘制混淆矩阵等指标来实现,由于这些指标没有考虑类别占比情况给模型分类性能带来的影响,模型倾向性结论需要挖掘工程师通过对多个指标进行综合分析才能得到,要求的门槛更高,有可能引发反复模型训练、模型预测、模型评估,过程更复杂效率低。然而,好的倾向性评估指标的确立需要花费较大的工作量,不易实现。综上所述,可以通过简单改变测试集类别比例的方式对训练模型进行测试,对比使用不同比例样本得到的对应的测试精度或者错误率是评估模型对不同类别识别敏感程度的一个较实用的方法,若模型的分类精度随着某种类别比例的增加而发生较大变化,则说明模型更倾向于去识别使测试精度提高的那个类别,若分类精度不随着类比占比变化而发生的较大的影响,则说明模型在训练过程中获得了充分的训练,不具有明显倾向性。然而,如何在不需要重新制定评估指标的情况下在资源有限的测试集上根据训练集比例去合理调整自身比例去做分类倾向性测试也是一个难点。
技术实现要素:
4.为了解决上述技术问题,本发明提供一种基于分层技术的分类模型倾向性检验方法及系统。
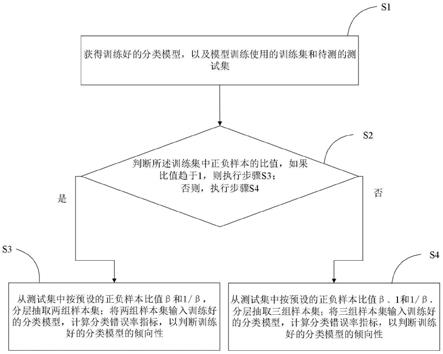
5.本发明技术解决方案为:一种基于分层技术的分类模型倾向性检验方法,包括:
6.步骤s1:获得训练好的分类模型,以及模型训练使用的训练集和待测的测试集;
7.步骤s2:判断所述训练集中正负样本的比值,如果所述比值趋于1,则执行步骤s3:否则,执行步骤s4;
8.步骤s3:从所述测试集中按预设的正负样本比值β和1/β,分层抽取两组样本集;将两组所述样本集输入所述训练好的分类模型,计算分类错误率指标,以判断所述训练好的分类模型的倾向性;
9.步骤s4:从所述测试集中按预设的正负样本比值β、1和1/β,分层抽取三组样本集;将三组所述样本集输入所述训练好的分类模型,计算分类错误率指标,以判断所述训练好
的分类模型的倾向性。
10.本发明与现有技术相比,具有以下优点:
11.1、本发明提供的方法在调整测试集类别占比时,结合了分层技术,根据实际需求有效调整了类别占比。本方法为了有效验证模型对不同类别样本数据识别的倾向性,调整了测试集中各类样本所占的比例,其中采用了分层采样技术,按照采样比多次采样,保证数据分布不变的情况下,有效重组了不同类别占比的测试资源。
12.2、本发明提供的方法制定了多采样比策略的模型倾向性验证方法,为了验证模型对不同类别数据识别的敏感程度差异,直接从测试样本类别比例入手检验,通过制定倾向性评估策略,对比分析了所得到的测试错误率,从而有效对模型分类倾向性进行了鉴定,使得验证结果可靠。
13.3、本发明设计了仅需使用一个分类错误率指标,即可对分类模型倾向性进行验证的简易方法。本发明通过分析在不同类别比例的测试集上得到的错误率,对比错误率之间的差距大小,摒弃了倾向性指标复杂的制定过程,简单高效地实现了对模型倾向性的评估。
附图说明
14.图1为本发明实施例中一种基于分层技术的分类模型倾向性检验方法的流程图;
15.图2为本发明实施例中一种基于分层技术的分类模型倾向性检验方法中步骤s3:从测试集中按预设的正负样本比值β和1/β,分层抽取两组样本集;将两组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性的流程图;
16.图3为本发明实施例中一种基于分层技术的分类模型倾向性检验方法中步骤s4:从测试集中按预设的正负样本比值β、1和1/β,分层抽取三组样本集;将三组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性的流程图;
17.图4为本发明实施例中一种基于分层技术的分类模型倾向性检验系统的结构框图。
具体实施方式
18.本发明提供了一种基于分层技术的分类模型倾向性检验方法,基于分层技术,在测试集上运用不同的采样策略,根据原始样本中的比例情况,通过设置不相同的采样比例,以最直接的方式在测试集上对模型倾向性进行检验,同时摒弃了制定倾向性评估指标的繁琐过程,使用现有的分类性能指标对模型倾向性做出合理的评估。
19.为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
20.实施例一
21.如图1所示,本发明实施例提供的一种基于分层技术的分类模型倾向性检验方法,包括下述步骤:
22.步骤s1:获得训练好的分类模型,以及模型训练使用的训练集和待测的测试集;
23.步骤s2:判断训练集中正负样本的比值,如果比值趋于1,则执行步骤s3:否则,执行步骤s4;
24.步骤s3:从测试集中按预设的正负样本比值β和1/β,分层抽取两组样本集;将两组
样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性;
25.步骤s4:从测试集中按预设的正负样本比值β、1和1/β,分层抽取三组样本集;将三组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性。
26.首先,在步骤s1获取一个已经训练好的分类模型,并得到该模型训练时候使用的训练集,以及将要用于验证分类模型的测试集。
27.其次,在步骤s2中,计算在训练上述分类模型时候,使用的训练集中正负样本的比例。如果正负样本比值趋于1,则执行下述步骤s3:否则,执行下述步骤s4。
28.举例来说,一个已经训练好的分类模型使用的训练集中正负样本分别为100和95,则根据步骤s2得知,二者比值接近1,即正负样本数量趋于均衡时,则执行下述步骤s3。
29.如图2所示,在一个实施例中,上述步骤s3:从测试集中按预设的正负样本比值β和1/β,分层抽取两组样本集;将两组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性;具体包括:
30.步骤s31:利用公式(1),计算初次分层抽样比例,
31.α=n/n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
32.其中,n为预设的从测试集初次抽取样本的数量,n为测试集样本总数;
33.假设测试集样本总数为400个,正负样本分别为200个,即n
+
=200,n
‑
=200。假设初次抽取的样本数为100个,则根据公式(1)得出α=0.25。
34.步骤s32:利用公式(2),对初次抽取样本中的正负样本分层采样;
[0035][0036]
其中,为需要抽取类别为i的样本数;n
i
为测试集中i类别的样本数,i∈{+,
‑
},为向下取整符号;
[0037]
在此步骤中,计算初次抽取的正负样本数,根据公式(2)得到
[0038]
步骤s33:当样本集中正负样本比值为β;利用公式(3),计算单份样本增量;当样本集中正负样本比值为1/β,利用公式(4),计算单份样本增量;
[0039][0040][0041]
其中,i∈{+,
‑
},为单份样本增量;
[0042]
设定要采集的两组样本集中,正负样本比值分别为2和1/2,即β=2,计算单份样本增量;
[0043]
当正负样本比值为2时,根据公式(3)计算得到
[0044]
当正负样本比值为1/2时,根据公式(4)计算得到
[0045]
步骤s34:当样本集中正负样本比值为β,计算最终正负样本数量如下述公式(5)所示;当样本集中正负样本比值为1/β,计算最终正负样本数量如下述公式(6)所示;
[0046][0047][0048]
其中,分别表示最终抽取的正负样本数量;
[0049]
当正负样本比值为2时,根据公式(5)计算得到最终正负样本数量分别为:
[0050]
当正负样本比值为1/2时,根据公式(6)计算得到最终正负样本数量分别为
[0051]
步骤s35:将两组样本集分别输入到训练好的分类模型,分别得到其对应的分类错误率指标e
β
和e
1/β
,利用公式(7)计算其倾向性;
[0052][0053]
若r>θ,则训练好的分类模型更倾向于对负类的识别;
[0054]
若r<θ,则训练好的分类模型更倾向于对正类的识别;
[0055]
若r接近0,则训练好的分类模型训练充分,不存在明显的识别倾向性;
[0056]
其中,θ(>0)为预设的阈值。
[0057]
本发明实施例采用mlp模型为例,对病人二次发病预测:通过病人的体重胆固醇以及压力控制情况等数据预测出病人是否具有二次发病,从而根据发病概率去降低关键因素的影响,为稳定健康生活作保障。
[0058]
当训练集中正负样本分别为135和140时,用该训练集对mlp模型进行训练。该模型训练完毕,需要对该模型进行倾向性检验。此时,由于训练集中正负样本数量均衡,则执行上述步骤s3,从测试集中经过分层抽取正负样本,分别为:n
+
=106,n
‑
=114,设置β=6,按上述步骤分别取两组样本集,并计算mlp模型的分类错误率指标e
β
和e
1/β
,本发明实施例设置θ=0.5,其结果如下表1所示:
[0059]
表1测试样本充分时,计算分类模型倾向性
[0060]
模型e
1/β
e
β
r倾向性mlp0.1760.1850.05无
[0061]
该结果表明,r接近0,说明mlp模型训练充分,不存在明显的识别倾向性。
[0062]
当从测试集中减少取得的正负样本,经过分层抽取后正负样本,分别为:n
+
=74,n
‑
=63,同样设置β=6时,按上述步骤分别取两组样本集,并计算mlp模型的分类错误率指标e
β
和e
1/β
,同样设置θ=0.5,其结果如下表2所示:
[0063]
表2测试样本不充分时,计算分类模型倾向性
[0064]
模型e
1/β
e
β
r倾向性mlp0.1570.3721.3偏负类
[0065]
该结果表明,r>θ,说明ml p模型更倾向于对负类的识别。
[0066]
当一个已经训练好的分类模型使用的训练集中正负样本分别为600和100,则根据步骤s2得知,正负样本比值远远大于1,即正负样本数量不均衡时,则执行下述步骤s4。
[0067]
如图3所示,在一个实施例中,上述步骤s4:从测试集中按预设的正负样本比值β、1和1/β,分层抽取三组样本集;将三组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性,具体包括:
[0068]
步骤s41:同步骤s31,计算初次分层抽样比例;
[0069]
假设测试集样本总数为400个,正负样本分别为300和100个,即n
+
=300,n
‑
=100。假设初次抽取的样本数为100个,则根据公式(1)得出α=0.25。
[0070]
步骤s42:同步骤s32,对初次抽取样本中的正负样本分层采样;
[0071]
在此步骤中,计算初次抽取的正负样本数,根据公式(2)得到
[0072]
设定要采集的三组样本集中,正负样本比值分别为6、1和1/6,即β=6,分别计算三组样本集中正负样本数量。
[0073]
步骤s43:当样本集中正负样本比值为1,利用公式(8),计算单份样本增量;利用公式(9),计算最终的正负样本数量;
[0074][0075][0076]
其中,k为样本集中的正负样本比值;
[0077]
在此步骤中β=1,k=300/100=3,因此,利用公式(8)得到利用公式(9)因此,得到最终的正负样本数量分别为:
[0078]
步骤s44:当样本集中正负样本比值为β,利用公式(10),计算单份正样本增量,计算最终的正负样本数量如公式(11)所示;
[0079][0080][0081]
在此步骤中β=6,k=3,利用公式(10),得到利用公式(11),得到因此,得到最终的正负样本数量分别为:
[0082]
步骤s45:当样本集中正负样本比值为1/β;利用公式(10),计算单份正样本增量,最终的正负样本数量如公式(11)所示;
[0083]
在此步骤中1/β=1/6,k=3,利用公式(10)得到
利用公式(11),得到因此,得到最终的正负样本数量分别为:
[0084]
步骤s46:将三组样本集分别输入到训练好的分类模型,分别得到其对应的分类错误率指标e1、e
1/β
、e
β
;
[0085]
若e
β
>e1>e
1/β
,则训练好的分类模型更倾向于对负类的识别;
[0086]
若e
β
<e1<e
1/β
,则训练好的分类模型更倾向于对正类的识别;
[0087]
若则训练好的分类模型训练充分,不存在明显的识别倾向性。
[0088]
当训练集中正负样本分别为180和50时,用该训练集对mlp模型进行训练。该模型训练完毕,需要对该模型进行倾向性检验。此时,由于训练集中正负样本数量不均衡,则执行上述步骤s4,从测试集中经过分层抽取正负样本数分别为:n
+
=104,n
‑
=30,设置β=6,按上述步骤分别抽取三组样本集,并计算mlp模型的分类错误率指标e
β
、e1和e
1/β
,其结果如下表3所示:
[0089]
表3训练样本不均衡时,计算分类模型倾向性
[0090][0091][0092]
该结果表明,计算得到的分类错误率指标e1、e
1/β
、e
β
,根据评估规则,说明mlp更倾向于对正类的识别。
[0093]
本发明提供的方法在调整测试集类别占比时,结合了分层技术,根据实际需求有效调整了类别占比。本方法为了有效验证模型对不同类别样本数据识别的倾向性,调整了测试集中各类样本所占的比例,其中采用了分层采样技术,按照采样比多次采样,保证数据分布不变的情况下,有效重组了不同类别占比的测试资源。
[0094]
本发明提供的方法制定了多采样比策略的模型倾向性验证方法,为了验证模型对不同类别数据识别的敏感程度差异,直接从测试样本类别比例入手检验,通过制定倾向性评估策略,对比分析了所得到的测试错误率,从而有效对模型分类倾向性进行了鉴定,使得验证结果可靠。
[0095]
本发明设计了仅需使用一个分类错误率指标,即可对分类模型倾向性进行验证的简易方法。本发明通过分析在不同类别比例的测试集上得到的错误率,对比错误率之间的差距大小,摒弃了倾向性指标复杂的制定过程,简单高效地实现了对模型倾向性的评估。
[0096]
实施例二
[0097]
如图4所示,本发明实施例提供了一种基于分层技术的分类模型倾向性检验系统,包括下述模块:
[0098]
获取模型及数据模块51,用于获得已训练的分类模型,以及模型训练使用的训练集和待测的测试集;
[0099]
判断模块52,用于判断训练集中正负样本的比值,如果比值趋于1,则执行采集两组样本及检验模块;否则,执行采集三组样本及检验模块;
[0100]
采集两组样本及检验模块53,用于从测试集中按预设的正负样本比值β和1/β,分层抽取两组样本集;将两组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性;
[0101]
采集三组样本及检验模块54,用于从测试集中按预设的正负样本比值β、1和1/β,分层抽取三组样本集;将三组样本集输入训练好的分类模型,计算分类错误率指标,以判断训练好的分类模型的倾向性。
[0102]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1