一种基于深度监督的图像语义分割方法
本发明涉及深度学习、图像语义分割领域,具体涉及一种基于深度监督的图像语义分割方法。
背景技术:
随着深度学习的快速发展,给图像分割领域注入了新的血液,各种基于深度学习的图像分割框架相继出现,并取得了重大的突破,越来越多的研究者们把目光放到深度学习的图像分割方法上,卷积神经网络具有优异的特征学习能力,学习到的特征对数据有更本质的刻画。基于深度学习的图像分割方法中端到端的全卷积网络(fcn)是真正有代表性的一个工作,最先提出来的全卷积网络是逐渐下采样生成特征图的过程,而后扩展出了编码器-解码器结构的全卷积结构的u型网络u-net,编码器进行逐步下采样提取特征,解码器进行逐步上采样和特征叠加融合最后恢复图像相同的尺寸大小,并在编码器解码器之间加入了跳转连接。这样的网络结构在面对较少样本时具有独特的优势,真正实现了从像素到像素的一步走,基于编码器解码器的方法还有如segnet、deeplabv3+等,本发明正是采用了这种网络结构并在编码器提取特征时加载了预训练模型权重帮助模型快速收敛。
在地球上石油和天然气大量聚集的地方,往往在其地表下面会形成一定规模的盐沉积层,通过精准的定位盐沉积层的位置,便可找到石油和天然气的位置所在,由专业设备获取得到的盐体图像后通过人工标注盐体,然而人为标注的结果具有很大的主观性和高度可变的渲染性,判断错误还会存在一定的安全隐患。将对盐体标注的过程划分为语义分割的范畴,现有的一些盐体图像标注的方法常基于纹理属性和盐丘边缘检测,比如pitas和kotropoulos在该领域的第一篇论文中提出了一种基于纹理分析的地震图像语义分割方法,周等人和aqrawi等人分别将2d滤波器和倾角导向三维sobel滤波器与地震数据进行卷积,获得了包含独特边界的梯度图。这一类的方法还是存在准确性差等很多的不足,而基于深度学习的方法,近年来很多研究者进行尝试将深度学习用于盐层识别并取得了显著性的效果,比如di等人提出了一种反卷积神经网络(dcnn),它能够同时理解和标记整个地震剖面中的所有特征,从而可以实现实时地震图像解释。zeng等人提出了一种利用u-net分割网络结合resnet分类网络的方法,实现了对盐体图像高精度的划分。shi等人将盐体识别问题看作三维图像分割,采用基于编码器-解码器的u-net架构来构建一个用于3d盐体分割的网络。本发明提出的基于深度监督的图像语义分割方法取得了较好的精度,并优于很多现有的一些分割模型。
技术实现要素:
本发明要解决的技术问题是:提供了一种基于深度监督的图像语义分割方法,以解决盐体图像不定型、数据样本少,分割难度大的问题,实验证明本发明提出的方法能有效改善盐体图像的分割精度,并且本发明不仅仅局限于盐体图像,还可以相对容易的扩展用于其它场景的语义分割范畴。
本发明采用的技术方案如下:一种基于深度监督的图像语义分割方法,包括了如下的步骤:
步骤1、获取数据集:通过采集装置获取图像,对其人工标注,构建训练样本集和测试样本集;
步骤2、数据预处理:针对盐体图像,为了使得图像更加符合格式要求和使样本多样性,将大尺寸盐体图像划分为多个小尺寸的patch图像(如果是其它数据集,则根据实际图像尺寸大小可省略这一步),采用了图像增强的手段,包含训练集的增强和测试集的增强;
为了使得图像更加符合格式要求和使样本多样性,将大尺寸盐体图像划分为多个小尺寸的patch图像,具体为128×128像素大小的patch,这是为了减少每次输入的数据量少便于模型的训练,然后采用了图像增强的手段,包含训练集的增强和测试集的增强,具体为对训练集连同标签图像进行随机水平翻转、几何变换和光照变化三个层次的增强,在进行测试时对测试时只做水平翻转操作;
步骤3、构建基于编码器-解码器的u型网络,在编码器部分使用加载了预训练权重的模型作为骨干网络提取特征,解码器部分应用了多个能有效改善模型分割精度的必要模块,过程中使用反卷积的方式逐步上采样;
在编码器部分使用加载了预训练权重的模型作为骨干网络提取特征,具体为resnest-269,包括一个卷积层(convolution)、一个批归一化层(bn)、一个激活层(relu)和四个残差网络单元层,这四个残差网络单元层分别包含3,30,48,8个残差块,对应包含了6,60,96,16个3×3的卷积,四个残差单元中包含最大池化层来进行下采样操作。解码器部分应用了多个能有效改善模型分割精度的必要模块,具体为目标语义池化模板ocnet-block,空间通道注意力机制模块scse-block,这儿实现的scse-block略有不同,过程中使用反卷积的方式逐步上采样;
步骤4、为了更好的监督模型训练,采用中继监督的方法,设置包含分类和分割在内的多任务损失路径,其中全部图片分割分支为主要,其它两个分支为辅助;
其中全部图片分割分支为主要损失函数路径lmain,设定的权重较大,其它两个分支lclass和lnon_empty为辅助,设定的权重较小,分别为α=0.05,β=0.1;
步骤5、对含有盐体(目标)的分割分支构建多尺度特征进行融合,同时兼顾到深度特征的语义信息和浅层特征的细节信息帮助有效改善分割精度;具体采用的方法称为超列(hyper-column),这种方法的思想与金字塔的思想不谋而合,都是建立了多尺度特征进行融合以达到更高的分割精度;
步骤6、总损失为三个分支损失的加权求和,对总损失函数进行优化:分类分支采用数值稳定二分类交叉熵(bceloss)损失函数,分割分支采用lovasz-softmax损失函数,用adamw优化器对网络进行学习优化;
总损失为三个分支损失的加权求和ltotal=lmain+αlclass+βlnon_empty,对总损失函数进行优化:分类分支采用数值稳定二分类交叉熵(bceloss)损失函数,分割分支采用lovasz-softmax损失函数,用adamw优化器对网络进行学习优化;
步骤7、训练模型直到收敛后得到模型权重,加载模型权重对图像进行分割。
进一步地,步骤1针对盐体图像数据获取过程为通过声波发射装置和声波接收装置,根据声波在不同密度层传播速度的不同,记录地下不同岩层区域的结构从而获得盐体图像,而对于其他场景,直接通过图像采集装置获得图像。
进一步地,步骤2数据预处理中将大尺寸的盐体图像划分为128×128小尺寸的patch图像,便于模型的训练,图像增强方法中对训练集进行了三个层次的增强,每次连同标签mask图像一起增强,包含随机水平翻转(randomhorizontalflip),几何变化(geometrictransform),光照变化(brightnesstransform),对测试集只进行随机水平翻转。
进一步地,步骤3中编码器部分使用加载了预训练模型权重的resnest-269作为骨干网络提取特征,该部分包括一个卷积层(convolution)、一个批归一化层(bn)、一个激活层(relu)和四个残差网络单元层,这四个残差网络单元层分别包含3,30,48,8个残差块,对应包含了6,60,96,16个3×3的卷积;编码器部分为了有效提高模型的分割精度,在解码器的前四层中加了一些必要的模块,包含聚集目标语义信息的目标语义池化模块ocnet-block,能有效帮助特征图信息提取的空间和通道注意力机制模块scse-block,并采用反卷积操作进行逐步上采样恢复输入时图像的尺寸大小,总共5个卷积层(convolution)、5个批归一化层(bn)、5个leaky_relu层,4个ocnet-block、4个scse-block和4个反卷积层。
进一步地,步骤4中采用中继监督的方法,在编码器之后设置一个分割损失路径预测是否包含盐体或其它的目标以加速模型收敛,包括:1个全局池化层、一个dropout层和一个线性变换层;在解码器之后设置了包含盐体或其它的目标的图像的分割分支和全部图像的分割分支,以全部图像的分割分支为主,其它两个分支为辅的多任务监督训练;含有盐体的分割分支包含1个3×3卷积层,1个批归一化层(bn),1个relu激活层和1个1×1的卷积层,输出含有盐体区域的特征图,全部图像的分割分支包含1个3×3卷积层,1个批归一化层(bn),1个relu激活层和1个1×1的卷积层,输出全部图像的特征图。
进一步地,步骤5中构建经过解码器之后的多个不同尺度的特征分割损失,进行特征融合,这种方式称之为超列(hyper-column)。
进一步地,步骤6中总损失的设置,假设分类分支的损失为lclass,权重比例为α=0.05,包含盐体(目标)的图像的分割损失为lnon_empty,权重比例为β=0.1,全部图像的分割损失为lmain,模型的总损失为ltotal=lmain+αlclass+βlnon_empty,使用adamw优化器优化总损失函数对网络训练得到一个精度最佳的模型。
本发明原理在于:盐体图像的数据特征不同于自然图像,盐体图像具有形状不定、不具有形状先验知识和纹理更加突出等特征,这些都给盐体图像的分割造成了一定的挑战,针对此种问题,本发明设计了u-net形状结构的深度监督语义分割模型,为提高模型分割的结果,加入了一些不可或缺的组件,实验结果证明,这些组件的加入能有效改善盐体图像的分割性能。
网络的整体呈现一个u形的结构,编码器和解码器分别位于中心位置的左侧和右侧,两者之间通过跳跃连接融合具有相同尺度的特征映射,编码器是一个逐步下采样的过程,也就是一个收缩路经,遵循普通的cnn卷积操作,在这个过程中,图像的特征被提取,这儿骨干网络backbone采用resnest-269,与之相对应,解码器是一个逐步“上采样”的操作,称之为扩张路径,在解码器部分实现了场景解析,通过目标语义池化模块ocnet-block聚集目标语义信息,ocnet可以理解为是一种自注意力机制的语义聚集策略,可以使得同一物体的像素信息更加汇聚,再引入注意力机制的scse-block模块增强语义细粒度特征,该模块由通道注意力模块和空间注意力模块组成,同时关注到通道和空间上的有用信息,要注意的是,这儿实现的scse-block略有不同,采用senet中的se通道注意力实现方法代替了scse中原本的通道注意力部分,再和sse空间注意力模块组合得到空间通道注意力机制模块scse-block。最后采用中继监督的方法设置了分类和分割在内的多路径损失函数充分训练模型,使得模型加速收敛,最后得到性能较好的模型。
综上所述,相比于现有的一些方法,本发明的有益效果是:
1)相比于其它一些模型,本发明提出的模型能有效区分是否包含目标的图像,能有效改善了分割结果的准确性,在编码器采用相同的骨干网络的情况下,该模型比其它现有的一些分割模型平均高1%map个精度。
2)编码器使用resnest-269作为骨干网络的模型精度能加速模型的收敛并很好的适应于图像语义分割,解码器加入的模块对最终的分割精度非常有必要,最终模型的精度能达到87.32%map,能改善针对数据分辨率有限且数据量不足的情况。
3)解码器之后对多尺度featuremap计算loss,引入超列(hyper-column)融合多尺度特征进行细化,使得分割性能得到较好的提升,简单的采用超列(hyper-column)的策略,就使得模型带来了近乎0.2%的精度提升。
附图说明
为了更加清晰明了的说明本发明的具体细节,对本发明中涉及到的一些附图做简单的介绍,以下附图仅仅示出了本发明的某些实施例以便于细节理解,并不以任何方式限制本发明的范围。
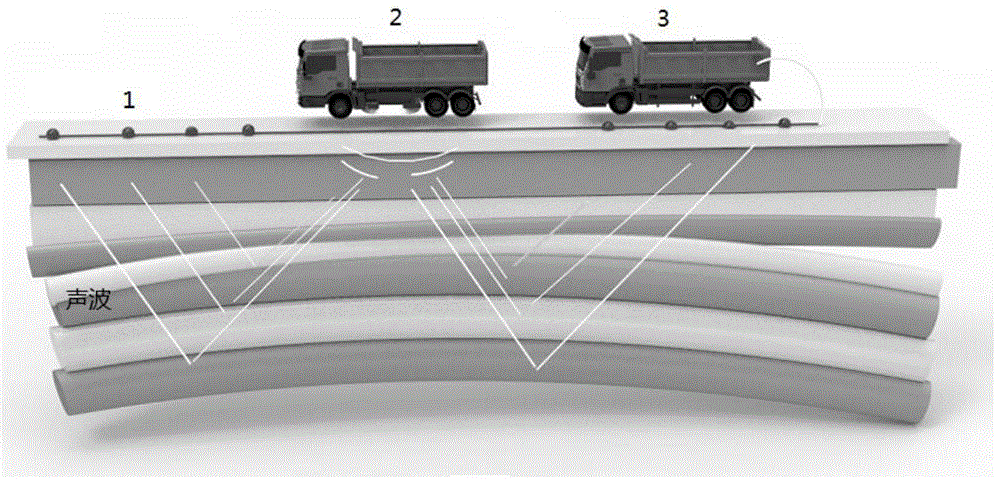
图1为本发明中针对盐体图像数据采集的过程示意图;
图2为本发明的模型结构图;
图3为本发明的解码器单元说明示意图;
图4为本发明提出的方法与其他现有的方法分割结果对比示意图。
图中附图标记含义为:1为地震检波器,2为声波发射装置,3为声波接收装置。
具体实施方式
以下结合附图说明本发明的具体实施例做详细说明。但以下的实施例仅限于解释本发明,本发明的保护范围应包括权利要求书限定的全部内容;而且通过以下实施例对本领域的技术人员即可以实现本发明权利要求书的全部内容。
图1为本发明中针对盐体图像数据采集的过程示意图:由声波发射装置发射声波,声波接收装置接收声波,根据声波在不同介质间传播速度不同,记录下地底岩层结构从而获得盐体图像;
图2为本发明的模型结构图:该方法是包含编码器和解码器在内的一个u型神经网络网络架构,以resnest作为编码器的backbone,通过一个中心处理,然后解码器部分包含目标语义池化模块ocnet和注意力机制模块scse和反卷积操作等,输出包含了分类和有盐体的分割或为空的分割三个分支,三个分支的损失加权协同优化训练模型;
如图2所示,本发明的整体网络框架结构图,主要包含了编码器和解码器在内一个呈现u型结构的网络,设置了分类和分割在内的三个分支损失路径监督模型训练,主要如下的几个步骤:
步骤1、获取数据集:通过特殊的获取装置采集到盐体图像,采集数据过程如图1所示,声波发射装置发射声波,由声波接收装置接收声波,根据声波在不同密度的介质中传播速度的不同记录下岩层结构获取盐体图像数据,对其人工标注,构建训练样本和测试样本集。本发明使用的数据是由tgs在kaggle平台开放的数据集(https://www.kaggle.com/c/tgs-salt-indentif-ication-challenge);
步骤2、数据预处理:为了使得图像更加符合格式要求和使样本多样性,将大尺寸盐体图像划分为多个小尺寸的patch图像,采用了图像增强的手段,包含训练集的增强和测试集的增强;
步骤3、构建基于编码器-解码器的u型网络,在编码器部分使用加载了预训练权重的模型作为骨干网络提取特征,解码器部分应用了多个能有效改善模型分割精度的必要模块,包括目标语义池化模块ocnet-block和注意力机制模块scse-block,过程中使用反卷积的方式逐步上采样,具体的解码器单元说明见图3;图3为本发明的解码器单元说明示意图:先通过一个卷积操作后进行批归一化激活,再通过目标语义池化模块ocnet-block和注意力机制模块scse-block之后进行上采样,这里实现的scse-block略微有所不同,具体如图3所示,将se通道注意力机制模块替换了原来的通道注意力机制模块,se注意力机制模块和sse空间注意力模块组合的方式更能有效提升模型的精度。
步骤4、为了更好的监督模型训练,采用中继监督的方法,设置包含分类和分割在内的多任务损失路径,其中全部图片分割分支为主要,其它两个分支为辅助,编码器顶层的特征图通过全局平均池化操作后,然后输出一个分类结果,这个分类分支使用交叉熵损失(bceloss)lclass辅助监督,并设置权重比例α=0.05合并到总的损失中,以促进网络区分不含盐层的图片,产生更好的分割结果,主干分支上的分割损失为lmain;
步骤5、对含有盐体的分割分支构建多尺度特征进行融合,同时兼顾到深度特征的语义信息和浅层特征的细节信息帮助有效改善分割精度,具体为五个特征层级上的损失求和,假设损失为lnon_empty,权重比例β=0.1,其计算公式如下,其中i表示解码器的层级:
步骤6、总损失为三个分支损失的加权求和,对总损失函数进行优化:分类分支采用数值稳定二分类交叉熵(bceloss)损失函数,其表达式如下:
l(y,x)=-y·log(sigmoid(x))-(1-y)·log(1-sigmoid(x))
其中sigmoid函数定义如下:
对于图像分割分支采用lovasz-softmax损失函数,其结合子模集合函(submodularsetfunction)数做了一定的优化。当对于某一个像素属于c类别的lovasz-softmax损失函数loss(f(c))损失计算公式如下:
这里的
这里:
其中,c表示具体的某一个类别,y*,
其中,loss(f)为所有类别lovasz-softmax损失的平均值,fi(c)为第i个输出评分函数的值,mi(c)表示对某个预测像素i的hingeloss,
ltotal=lmain+αlclass+βlnon_empty
最后使用adamw优化器对网络进行学习优化;
步骤7、训练模型直到收敛后得到模型权重,加载模型权重对盐体图像进行分割。
为了验证本发明的有效性,将本发明的方法与state-of-the-art方法进行了比较,详细结果见表ⅰ,在对比的算法中,除了denseaspp采用densenet-121作为骨干网络,其它的方法都以resnet-101作为骨干网络以便于标准化实验对比,过程中都加载了在imagenet上预训练得到的权重。
表i与多种模型分割精度比较结果
由表ⅰ可以看出,本发明提出的模型具有绝对性的优势,比由fpn获得的次高精度85.14%map高了2.18%map,比由denseaspp获得的最低精度82.59%map超出了4.73%map,为了更加公平的相比较,这儿也展示了以resnest-101作为backbone的模型结果,可以看到,本发明提出的模型依旧具有一定的优势,得到的精度也都高于其它所有模型的结果,这也是针对数据集的特殊性精心设计网络模型的结果,其他方法相互之间差异性不是很大,说明直接使用现有的分割网络并不适用于盐体图像。
图4为本发明提出的方法与其他现有的方法分割结果对比:模型分割结果可视化图,样本选自tgs数据集,第一、第二行分别代表了输入图像和对应的真实mask图,接下来的几行分别表示了pspnet、linknet、fpn和本文提出的模型的分割结果。(白色代表盐层区域,黑色代表非盐区域(nonsalt))。最后对比较结果做可视化如图4所示,对pspnet、linknet、fpn、和分别以senet-154和resnest-269作为backbone的模型做可视化对比分析,其中resnest-269_our是本发明提出的方法的分割结果。图4中给出的5个样本示例说明了盐体图像分割的一些简单和困难的情况,比较之下,本发明能有效分割盐体图像的细节部分,具有较好的分割性能,能在盐体图像标注过程实现自动化和很大程度上减少人工作业。由于其巧妙地设计,可相对容易地扩展用于很多其它地图像语义分割场景。
本发明未详细阐述的部分属于本领域公知技术,以上所述仅为本发明的较佳的实例,并不用以限制本发明,本领域技术人员均能根据具体应用场景做出适当调整和有效性改进。
- 还没有人留言评论。精彩留言会获得点赞!