使用神经网络对原始侧信道数据进行端到端攻击的方法
本发明涉及的是一种信息安全领域的技术,具体是一种使用神经网络对原始侧信道数据进行端到端攻击的方法,即直接对掩码防护下未对齐的高维原始侧信道数据进行侧信道攻击。
背景技术:
侧信道分析主要是基于物理特征的分析技术,包括功耗分析,电磁分析,错误分析,时间分析等等,其中功耗分析是指通过分析密码运算过程中呈现的电流/电压变化得出功耗的变化,进而将功耗与密钥信息联系起来,最终获取密钥信息。其进一步包括简单功耗分析(spa)和差分功耗分析(dpa):spa是指根据功耗曲线上所呈现的特殊特征来推测密钥信息,dpa利用的是操作数的变化所引起的微小的功耗变化,需要通过对大量功耗曲线进行统计分析才能得出密钥信息。电磁分析与功耗分析类似,只是获取曲线的方式有别。错误分析是利用错误结果进行分析得出密钥信息的分析技术。时间分析是指有的算法运行时间会因密钥的不同而不同,因而可以通过运行时间来推测密钥。
现有的随机掩码防护方法(masking)采用随机数掩盖运算过程中的真实数据,以此阻止攻击者找到中间值和侧信道信息的直接相关关系。此时随机掩码和中间值依然会在侧信道信息中泄露,但由于掩码的随机性,攻击者无法直接定位它们的位置,致使攻击代价大幅提高。由于所述掩码的存在,在实际分析中进行直接的特征点选择是不可行的,而结合不同位置功耗点的高阶攻击会因为原始曲线过长而消耗大量存储资源(随掩码阶数增长呈指数增长),也不可行。
技术实现要素:
本发明针对现有技术存在的上述不足,提出一种使用神经网络对原始侧信道数据进行端到端攻击的方法,使用神经网络技术直接对掩码防护下未对齐高维原始侧信道信息进行攻击,能够自动地在原始侧信道曲线上(无需预先时序对齐或降维)发现并组合掩码和中间值泄露,并利用组合后的信息直接进行侧信道攻击,有效解决掩码防护下进行侧信道攻击困难的问题。
本发明是通过以下技术方案实现的:
本发明涉及一种使用神经网络对原始侧信道数据进行端到端攻击的方法,包括:
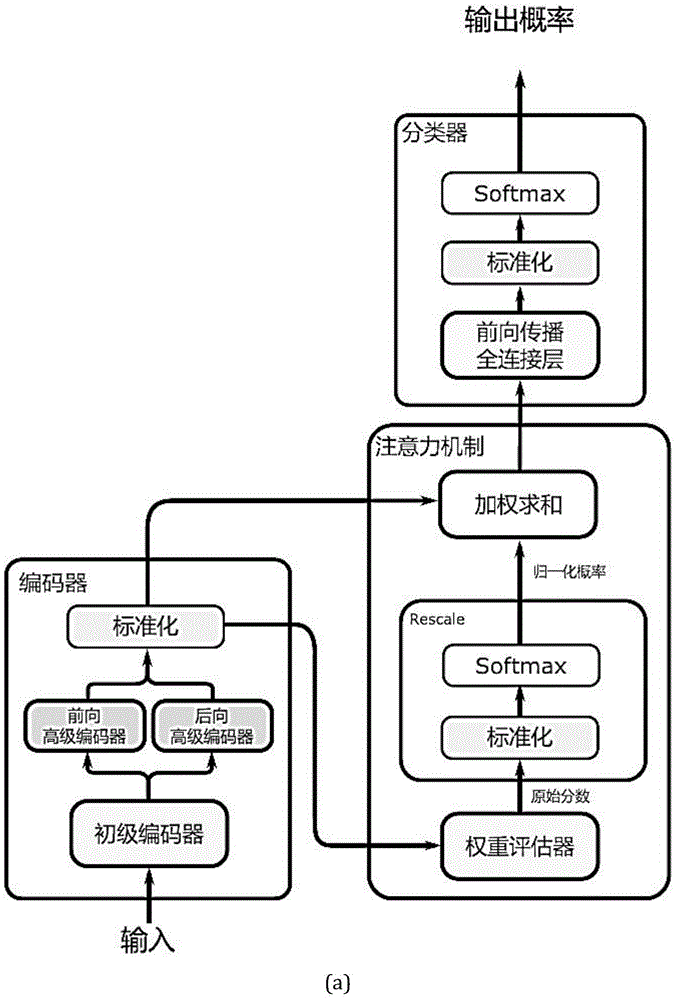
步骤1,构建包括初级编码器、高级编码器、至少一个注意力机制单元以及分类器的神经网络用于后续的训练和攻击步骤。
所述的初级编码器包括:局部连接网络和卷积网络,其中:局部连接网络由一层局部连接层和整形(reshape)层组成,卷积网络包括至少一层卷积层和最大池化层。
所述的高级编码器包括:两个分别与初级编码器的输出端相连的长短期记忆(lstm)网络结构,该两个lstm网络结构分别按照时间顺序从前到后和从后到前遍历数据。
所述的两个lstm网络结构按照数据通道维度结合或按照时间维度结合,其中:按照数据通道维度结合时,中间特征向量的通道数量翻倍,时间步数量不变且两个lstm网络结构共享一个批标准化(batchnormalization)操作;按照时间维度结合时,中间特征向量的通道数量不变,时间步翻倍且两个lstm网络结构分别具有独立的批标准化操作。
所述的至少一个注意力机制单元是指:当两个lstm网络结构按照数据通道维度结合时,一个注意力机制单元的输入端与两个lstm网络结构结合后的输出端相连;当两个lstm网络结构按照时间维度结合时,两个相互独立的注意力机制单元的输入端分别与两个lstm网络结构(fwattention和bwattention)的输出端相连,两个方向不同的注意力机制单元相互配合,从不同方向确定侧信道信息的主要泄露区间,帮助上层lstm缩小实际训练中的学习序列长度。
所述的注意力机制单元包括单个神经元和softmax激活函数,其中:单个神经元按照相同标准给所有时间步的重要性打分,softmax激活函数将分数映射成概率,该概率可以进一步控制不同时间步之间的权重,以权重形式作用于注意力单元的输入,并给出加权求和的结果向量,从而帮助高级编码器中的lstm在大量的时间步中筛选重要时间步,并通过不同权重控制训练过程中的梯度方向,起到了软性的时间步截断作用。
所述的分类器为使用softmax作为激活函数的全连接层。
步骤2,使用任意原始侧信道数据对步骤1搭建的神经网络进行训练,并从中随机不超过其中50%的数据作为验证集,训练过程中使用交叉熵作为损失函数,当验证数据集上的损失函数数值开始上升时,停止训练。
所述的原始侧信道数据是指:未经过特征点选择和对齐处理的侧信道数据。
步骤3,使用训练后的神经网络在攻击数据集上开展攻击,即将攻击数据集输入网络,网络将返回每条侧信道信息曲线的分类概率,根据多条侧信道信息分类的概率值,利用最大似然估计,求得一组侧信道信息背后密码算法运行时的密钥值。
所述的攻击数据集是指:在训练过程中未使用的,用于实际攻击密码算法的数据集,在机器学习的分类问题背景下通常被称为测试集,用于测试匹配率,在侧信道背景下,因为测试集的分类概率可直接用于侧信道攻击,也被称为攻击数据集。
所述的步骤3具体包括:
步骤3.1,使用神经网络中的初级编码器对原始侧信道数据进行细粒度特征提取,同时实现对原始侧信道数据的维度压缩。
优选地,当原始侧信道信息未对齐或无法对齐,通过替换不同结构的初级编码器,对未对齐的原始侧信道数据进行细粒度特征提取。
所述的局部连接网络使用局部权重对局部侧信道信息进行点乘处理,卷积网络使用共享权重对全局侧信道信息进行点乘处理,所述两种网络都可提取到细粒度(一个或几个时钟周期提取一个特征向量)的侧信道特征。
步骤3.2,使用神经网络中的高级编码器,对步骤3.1得到的细粒度特征进行组合,从而达到结合掩码和被掩中间值泄露信息的目的,以实现最终的端到端攻击。
所述的高级编码器中lstm的数据流控制门可根据训练数据的不同对自身的权重向量进行自动化学习,并依不同门控逻辑中的不同权重值对数据流和内部存储单元进行输入、输出、记忆和遗忘操作。
步骤3.3,使用注意力机制单元计算高级编码器输出的组合后的特征之间的权重并求和,对最终得到的特征向量使用分类器进行分类,得到该条侧信道信息属于不同中间值类别的概率。
步骤3.4,使用一层全连接层和softmax为加权求和后的特征向量分类。
技术效果
与现有技术相比,本发明直接使用原始侧信道信息建模,可实施切实可行的端到端攻击,可以省略对有掩码防护的实现进行侧信道攻击时的特征点选择过程。
附图说明
图1为实施例中两种网络构型的抽象结构实例;
图2为本发明初级编码器中局部连接层示意图;
图3为本发明初级编码器中卷积层示意图;
图4为使用神经网络对原始侧信道数据进行端到端攻击的方法示意图;
图5-图7为实施例效果示意图。
具体实施方式
本实施例针对开源数据集ascad进行分析,ascad数据集中单个时钟周期长度约为52个时间点,本实施例涉及一种用于对原始侧信道数据进行端到端攻击的神经网络,包括:初级编码器、高级编码器、注意力机制单元以及分类器。
所述初级编码器中的局部连接网络,该局部连接网络包括:局部连接层和整形(reshape)层。
所述的局部连接层中的过滤器(filter)大小是原始曲线中一个时钟周期长度的整数倍,通常取一到两个时钟周期,步进(stride)可以整除过滤器的长度,通常取过滤器的长度的一半。
所述的整形层的整形参数为:(-1,int(f/s)),其中:f为过滤器长度,s为步长,int为取整。
所述初级编码器中的卷积网络,该卷积网络包括:若干卷积层和池化层,其中:第一层卷积层的卷积核长度为应用曲线集的时钟周期长度步进为1,其他卷积层卷积核长度皆为3,步进皆为1;池化层中池化长度皆为2,步进皆为2,使用最大池化。
所述的卷积层在每次池化层后通道数量翻倍。
所述的高级编码器采用的长短期记忆结构(lstm),分别从正向和反向遍历所有的初级编码器输出,并依据侧信道信息复杂程度不同,使用不同的组合方式进行结合(按时间维度或按数据通道维度),lstm中的单元数为128或256,激活函数为tanh,循环激活函数为sigmoid。
所述两个方向不同的lstm网络结构,其各自拥有独立的注意力机制,使得注意力机制有方向性,两个方向不同的注意力机制可以相互配合确定侧信道信息泄露的主要区间,帮助上层lstm缩小实际训练中的学习序列长度。
所述的注意力机制单元直接作用于高级编码器的输出之上,使用单神经元的网络结构,按照统一标准评判每一个时间步数据的重要程度,该单神经元的网络结构的输出将输入softmax激活函数,最终得到求和为1的一组概率值,并使用该组概率值,将高级编码器所有时间步的输出进行加权求和,具体为:a′=batchnorm(vth),a=softmax(a′),r=hat,其中:h为高级编码器输出,v为单神经元中的可训练权重向量,a′为加权分数,a为注意力概率向量,r为加权求和后的特征向量。
本发明中的注意力机制额外加入了批标准化(batchnormalization)操作,该操作会在统一标准的加权分数a′之上,再对每个不同的时间步引入缩放和偏置自由度,当时间步数量较多时,可以有效加速注意力机制自身的收敛速度。
经过具体实际实验,在ubuntu20.04,python3.6,keras2.2.4,tensorflow1.13.1的环境设置下,以keras库中的默认随机初始化网络参数构建网络,使用批大小为8,学习率为0.0001,优化函数为adam开始训练,以公开数据集ascad为攻击目标,能够得到以下实验数据。
如图5所示,本发明构建的神经网络,在攻击对齐后的ascad数据集时,可实现7条攻击曲线恢复正确的密钥(猜测熵将至0)。
如图6所示,本发明构建的神经网络,在攻击未对齐的ascad数据集时(进行了额外的随机平移作为数据增强,数据增强移动区间长度为80个时间点),可实现20条攻击曲线恢复正确的密钥(猜测熵将至0)。
如图7所示,为本发明的攻击结果和现有zbhv20技术(gabrielzaid,lilianbossuet,amauryhabrard,andalexandrevenelli.methodologyforefficientcnnarchitecturesinprofilingattacks.iacrtrans.cryptogr.hardw.embed.syst.,2020(1):1–36,2020.)的比较,相比之下现有技术需要选取700个特征点,本发明方法直接攻击原始曲线共10万点。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!