一种以深度学习加速的迭代式光声图像重建方法
1.本发明涉及一种迭代式光声图像重建方法。
背景技术:
2.光声成像是一种新兴的成像方式,其结合了光学和超声两种成像模态的优点。在保持超声成像的高穿透深度的优点的同时还具备比超声成像更高的空间分辨率和对比度。
3.光声计算机断层扫描(pact)系统具备快速大区域的成像性能。现在的研究表明其有许多预临床和临床方面的应用,如早期的肿瘤检测和小动物的全身成像。在不适定条件下(如有限视角、稀疏视角等)的图像重建可能存在较多问题。迭代式重建的方法可在优化条件下实现高质量重建,但其成像时间较久,需要较大的计算资源。
技术实现要素:
4.本发明要解决的技术问题是:现有的迭代式光声图像重建方法成像时间较久,需要较大的计算资源。
5.为了解决上述技术问题,本发明的技术方案是提供了一种以深度学习加速的迭代式光声图像重建方法,光声图像重构的目标是从所接收到的信号y恢复初始压力x,通过最小化最小二乘法误差来求解,求解时利用通过优化方法进行迭代,迭代时加入r(x)正则项,使得优化目标变为:式中,是数据一致项,r(x)是正则项,λ是超参数,a是前向模型;
6.设正则项r(x)可微分梯度下降,则第k+1次迭代表示为设正则项r(x)可微分梯度下降,则第k+1次迭代表示为式中,表示梯度增量,则表示正则项第k次迭代的梯度增量,α表示迭代步长,a
*
为前向模型a的一个伴随线性模型,x
k
表示第k次迭代的结果,其特征在于,所述迭代式光声图像重建方法包括以下步骤:
7.通过神经网络对迭代过程学习正则项的梯度增量在每次迭代中让重建图像快速收敛;对于需要手动调整的迭代步长α,通过设置可学习的参数ω使其自主学习最佳参数。
8.优选地,所述神经网络采用卷积神经网络cnn模型替代,若正则项r(x)未确定,则第k+1次迭代表示为x
k+1
=x
k
‑
ω(a
*
(ax
k
‑
y))+cnn(x
k
),式中,cnn(x
k
)表示神经网络模型的输出;
9.若正则项r(x)已确定,则第k+1次迭代表示为若正则项r(x)已确定,则第k+1次迭代表示为使用卷积神经网络cnn模型仅仅学习每次迭代的步长与数据一致项的梯度与正则项r(x)的梯度的比例,以非线性的形式迭代,表示为式中,表示神经网络模型的输出。
10.优选地,对于所述神经网络的训练,使用均方根mse误差并以最终高质量图像为标签进行优化:l
rec
=mse(x
‑
x
k+1
),l
rec
表示损失函数,x表示标签图像,x
k+1
是第k+1次迭代的结
果。
11.本发明提出了一种用深度学习网络加速迭代收敛与自动调整参数的方法,通过训练的网络可以使得仅在5次以下的迭代结果胜于传统的10次以上的迭代效果。
附图说明
12.图1为网络模型参与的正则梯度迭代流程;
13.图2为用于学习正则梯度的卷积神经网络;
14.图3为用于非线性迭代的深度学习模型;
15.图4为学习正则增量的仿真结果展示:(a)、(b)为不同样品的时间反演(tr)重建结果;(c)、(d)为不同样品的全变分的20次迭代结果;(e)、(f)为不同样品的网络参与迭代的5次结果;(g),(h)为标签图像;
16.图5为学习迭代比例的仿真结果展示:(a)、(b)为不同样品的时间反演(tr)重建结果;(c)、(d)为不同样品的全变分的20次迭代结果;(e)、(f)为不同样品的网络参与迭代的3次结果;(g)、(h)为标签图像。
具体实施方式
17.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
18.在光声成像中,脉冲激光触发的光声信号的时空函数满足下式:
[0019][0020]
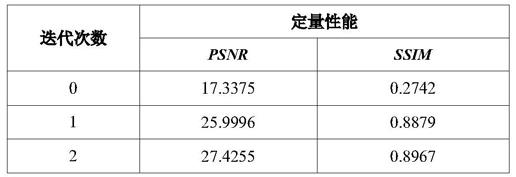
式(1)中,表示哈密顿算子,v
s
表示声波的传播速度,r表示空间位置,p(r,t)表示光声压力场的时空函数,p0(r)表示初始的压力分布,δ(t)表示脉冲函数。定义一个x矩阵等于初始压力分布p0(r),将x通过一个传感器转换成所接收到的时域光声信号,同时受到采样条件和环境因素影响,所接收到的信号y满足:
[0021]
y=a(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0022]
式(2)中,a(
·
)表示前向模型。光声图像重构的目标就是从y恢复初始压力x。由于a(
·
)受限于多个条件(物理性质和采样角度等),通常无法直接求逆。因此通过y求出精确的x是一个不适定问题。通常可以通过最小化最小二乘法误差来求解:
[0023][0024]
通常求解式(3)的方法是通过优化方法,如梯度下降,进行迭代。对于典型的第k+1次的迭代可以被表达为:
[0025]
x
k+1
=x
k
‑
aa
*
(ax
k
‑
y)
ꢀꢀꢀ
(4)
[0026]
式(4)中,x
k
表示第k次迭代的结果,α表示迭代步长,a
*
为前向模型a的一个伴随线性模型。
[0027]
为降低上述迭代过程的不适定性,常常加入一个正则项,使得优化目标变为:
[0028]
[0029]
式(5)中,r(x)是正则项,λ是超参数。
[0030]
同样的,若正则项可微分梯度下降,可以对式(5)所示的目标函数进行迭代。可以对第k+1次的迭代写为以下形式:
[0031][0032]
式(6)中,表示梯度增量,则表示正则项第k次迭代的梯度增量。
[0033]
选择合适的正则项有助于重建完整的图像。在光声成像中,全变分(tv)的正则项常常被使用。在迭代中,存在两个需要手动调整的参数:α和λ。本发明提出一种使用深度学习加速迭代的步骤,通过神经网络对迭代过程学习正则项的梯度增量,这部分在每次迭代中让重建图像快速收敛。对于原来需要手动调整的参数,也通过设置可学习的参数使其自主学习最佳参数。该方法允许将传统正则项一起加入迭代过程,或对于已有正则的优化目标,本发明也演示仅仅用神经网络去自动学习参数与部分增量的方案。演示结果表明本发明可以大大减少迭代次数与提高迭代效果,在少于普通迭代次数的情况下得到了更高的质量。
[0034]
在式(6)的迭代中,若将第三项正则项的梯度项用卷积神经网络(cnn)模型替代,可以得到如下式子:
[0035]
x
k+1
=x
k
‑
ω(a
*
(ax
k
‑
y))+cnn(x
k
)
ꢀꢀꢀ
(7)
[0036]
式(7)中,ω是一个超参数,用以调整梯度步长,cnn(x
k
)表示神经网络模型的输出。
[0037]
在这个基础上,将α替换成可学习的参数即可同时免除繁杂的手动调整过程,达到最优的学习速率。其迭代过程可以表示为图1所示,相比于一般用于图像处理的神经网络,用在本发明中的神经网络模型可以相对较小。本实施例的网络如图2所示,网络的结构中,每条黑线表示2个3
×
3的卷积。网络延迟信号是在延迟叠加重构过程中的一个中间状态的信号。而对于网络的训练,可以使用均方根(mse)误差并以最终高质量图像为标签进行优化:
[0038]
l
rec
=mse(x
gt
‑
x
k+1
)
ꢀꢀꢀꢀꢀꢀ
(8)
[0039]
式(8)中,l
rec
表示损失函数,x
gt
表示真实的压力分布图像,x
k+1
是第k+1次迭代的结果。这样即可通过神经网络实现迭代过程的正则化,后续演示结果将对比其与传统迭代正则的效果。
[0040]
针对已确定的正则项,上述方案可进一步演化,以全变分正则tv为例,可将迭代过程描述为:
[0041][0042]
可以使用卷积神经网络仅仅学习每次迭代的步长与两项的比例,以非线性的形式迭代式(9),即可表示为如下式子:
[0043][0044]
可以使用一个简单模型优化迭代,如图3所示。该方法的训练过程可以使用标签图像对输出的x
k+1
做约束,即:
[0045]
l
rec
=mse(x
‑
x
k+1
)
ꢀꢀꢀ
(11)
[0046]
式(8)及式(10)所示的两个损失函数表达式一致,其针对的是一次迭代的最终结果进行约束,但迭代中cnn所承担的作用略有不同。
[0047]
为验证本发明的效果,首先通过仿真生成大量分割的血管原始光声信号与初始压力分布。所设置的实验由环型的传感器环绕包围,数量为120个传感器,环绕半径为19mm,声速为1500m/s,所有图片的尺寸为256x256的大小,传感器的中心频率被设置为2.5mhz,整个数据集由4000个训练集和400个测试集组成。所有的实验程序都在深度学习开源框架pytorch上实现,直接对重建图像进行比较,并比较定量指标的高低判断效果。
[0048]
实验平台配置为两张intel xeon e5
‑
2690(2.6ghz)cpu和四张nvidia gtx1080tigpu。cnn参与正则梯度学习的实验结果如图4所示,与非迭代的tr方法比较,迭代重建的效果非常接近标签图像,tv的结果还存在些模糊的细节,可进一步对比结构相似度(ssim)与峰值信噪比(psnr)来定量比较这几个方法的效果,如表1所示的结果是ssim的定量结果,表2则表示psnr的定量结果,可以发现本发明方法的定量性能优越。
[0049]
ssimtrtvours10.29240.93840.984120.22330.92880.9787
[0050]
表1.图4中各个图像的ssim值
[0051]
psnrtrtvours120.902834.715736.41422
‑
11.389633.374134.7074
[0052]
表2.图4中各个图像的psnr值
[0053]
对于整个测试集,随着迭代次数增加,定量性能变化如表3所示。从表中可以发现每次迭代的提升都很大,这促使该方法可以加速传统迭代重建的收敛速度。
[0054][0055][0056]
表3.测试集性能随迭代次数变化
[0057]
针对tv的正则项,若不使用cnn作为正则梯度,其结果如图5所示。在仅仅迭代3次的结果就可看出其性能超越传统线性迭代的tv正则效果。可以进一步比较定量指标的效果,表4和表5分别列出图5中各个图像的ssim和psnr值。在相似度上,3次迭代的效果已经超过tv的传统迭代方式。
[0058]
ssimtrtvours10.24870.91110.954520.26290.95230.9636
[0059]
表4.图5中各个图像的ssim值
[0060]
psnr(db)trtvours117.655832.101332.307219.965735.505837.1162
[0061]
表5.图5中各个图像的psnr值
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1