提供大规模机器学习推理应用的多裸片点积引擎的制作方法
提供大规模机器学习推理应用的多裸片点积引擎
背景技术:
1.深度学习是一种基于更广泛的人工智能和机器学习(ml)概念的方法。深度学习可被描述为在学习信息和识别用于决策的模式时模仿生物系统,例如人脑的运作。深度学习通常涉及人工神经网络(ann),其中神经网络能够从标记的数据进行监督学习,或者从非结构化或未标记的数据进行非监督学习。在深度学习的示例中,计算机模型可以学习直接从图像,文本或声音中执行分类任务。随着ai领域技术的进步,深度学习模型(例如使用大量数据和包含多层的神经网络架构进行训练的深度学习模型)可以达到最高(state-of-the-art)精度,有时甚至超过了人类水平性能。由于性能的增长,深度学习可以具有各种实际应用,包括函数逼近,分类,数据处理,图像处理,机器人技术,自动车辆和计算机数控。
附图说明
2.根据一个或多个各种实施例,参考以下附图详细描述本公开。提供这些附图仅出于说明的目的,并且附图仅描绘了典型或示例性实施例。
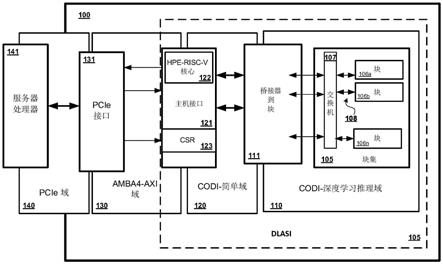
3.图1描绘了根据一些实施例的包括将多个推理计算单元连接到主存储器的深度学习加速器系统接口(dlasi)的深度学习加速器系统的示例。
4.图2示出了根据一些实施例的用于包括提供大规模机器学习推理应用的多裸片点积引擎(dpe)的多芯片接口系统的示例架构。
5.图3示出了根据一些实施例的可以在图2的多芯片接口系统中实施的dpe专用集成电路(asic)的示例架构。
6.图4a描绘了根据一些实施例的利用图2的多芯片接口系统的对象识别应用的示例。
7.图4b示出了根据一些实施例的块级(tile-level)流水线方案的示例,其允许图2的多芯片接口系统协调用于图像,推理和结果输出的存储器访问。
8.图5描绘了根据一些实施例的图2的多芯片接口系统的基于现场可编程门阵列(fpga)的仿真设置的示例。
9.图6示出了根据一些实施例的可以包括图2所示的多芯片接口系统的示例计算机系统。
10.这些附图不是穷举性的,并且不将本公开限制于所公开的精确形式。
具体实施方式
11.本文所述的各种实施例涉及提供大规模机器学习推理应用的多裸片(multi-die)点积引擎。目前用于实施深度学习硬件加速器的点积引擎(dpe)技术和基于忆阻器的可编程超高效加速器(puma)深度神经网络(dnn)推理架构是高度节能的。但是,这些技术利用了裸片上权值(on-die weight)存储方法,这对于这些架构至关重要。所述裸片上权值存储方法可能会限制dnn的大小,尤其是在单个硅器件上实施硬件的情况下。为了解决该缺点,所公开的多裸片点积引擎被明确地设计为利用针对dpe的多芯片架构。由于多裸片架构,多个
硅器件可以被实施以进行推理,从而使得大规模ml应用和复杂dnn的高能效推理成为可能。随着技术的不断进步,dnn的大小和复杂性也可能会增加,以适应成长型市场中的广泛应用,例如自动驾驶,自然语言处理,网络安全或任何数量的其他应用。
12.如将在本文中描述的,所公开的多裸片点积引擎是能够以高精度执行对象识别的多设备dnn推理系统的一部分。此外,根据所述实施例,所述系统可以包括符合可扩展iov的增强型系统接口,因此超融合服务器可以根据需要部署扩展卡。而且,在所公开的示例系统中使用的框被设计用于集成在专用集成电路(asic)中。
13.如上所述,dpe技术可用于实施深度学习加速器系统。例如,本文描述了包括深度学习加速器系统接口(dlasi)的深度学习加速器系统。所述dlasi被设计为在核心(core)(例如,用于推理)和服务器之间提供高带宽,低延时的接口,否则核心和服务器可能不具有通信兼容性(相对于存储器)。设计由数千个小核心组成的加速器可能会具有一些挑战,例如:所述许多核心之间的协调,尽管与dnn推理相关的问题大小截然不同但仍要保持加速器的高效率,以及完成这些基于dnn的计算任务而不消耗太多的功率或裸片面积。一般来说,协调数千个的神经网络推理核心可能会使单个主机接口控制器承受压力,从而使该控制器可能成为性能瓶颈。
14.此外,不同神经网络的大小可以有很大的不同。一些神经网络可能只具有几千个权值,而其他神经网络,例如用于自然语言处理或图像识别的神经网络,可能具有超过1亿个权值。对于每个应用都使用大型加速器似乎是可行的暴力解决方案。另一方面,如果将大型加速器分配在小型神经网络上工作,则该加速器可能不能得到充分利用。此外,现代服务器托管(host)许多操作系统(os),并且仅能容纳几个扩展卡。例如,服务器每个处理器插座(socket)可能具有多个pcie卡插槽(slot)。将大型神经网络映射到单个裸片上提出了许多挑战,因为可能没有足够的裸片上存储来容纳每个权值。因此,本文描述了包括用于提供大规模机器学习推理应用的多裸片点积引擎(dpe)的多芯片接口解决方案。作为另一个示例,pcie交换机可以在pcie形状因数卡上使用,其中多个裸片与其交互以映射大型模型。因此,即使只有有限数量的pcie通道,仍可以通过利用多个dpe裸片将大型模型映射到单个pcie卡上。
15.通常,商品服务器(例如,基于xeon的),个人计算机(pc)和嵌入式系统(例如raspberry pi)运行标准化的操作系统,并包含复杂的通用cpu和可缓存存储系统。但是,深度学习处理器可以用更简单的指令集和存储器架构来实现高性能。此外,核心的架构被优化用于处理较小的数字,例如在操作中处理8位数字(而不是32位或64位)以进行神经网络推理。深度学习加速器的硬件设计可以包括大量处理器,例如使用数千个深度学习处理器。而且,随着所述数千个的使用,这些深度学习处理器通常可能不需要高精度。因此,处理小数字对于其多核心设计可能是最佳的,例如以减轻瓶颈。相反,商品服务器可以非常高效地运行以处理更大的数字,例如处理64位。由于这些(和其他)功能差异,在深度学习处理期间,所述加速器核心与服务器之间可能会出现一些不一致的情况。如上所述,所公开的dlasi被设计用于解决这样的问题。所述dlasi实现了多裸片解决方案,该解决方案有效地连接了不同类型的处理(在所述加速器核心和主机服务器上执行的处理),以连接加速系统中的实体,从而提高了兼容性并增强了系统的整体性能。
16.根据一些实施例,所述dlasi包括结构协议(fabric protocol),基于处理器的主
机接口以及桥接器,该桥接器可以连接服务器存储器系统(将存储器视为64字节(b)缓存行(cache line)的阵列)到大量dnn推论计算单元,即将存储器视为16位字(word)的阵列的核心(块(tile))。所述结构协议可以是两个虚拟通道(vc)协议,这使得构造简单而有效的交换机成为可能。所述结构协议可以支持大数据包,而大数据包又可以支持高效率。另外,通过简单的排序规则,所述结构协议可以扩展到多个芯片。甚至在某些情况下,所述结构协议可以在另一个协议(例如以太网)之上分层,以用于服务器到服务器的通信。此外,在一些示例中,所述主机接口可以在“映像”级别(或输入数据序列级别)与服务器连接,并且可以以“填鸭式”的方式从较大级别将较小的工作段流水线传送到所述多个核心。这通过应用同步方案来实现,在此称为重叠间隔流水线(overlapping interval pipelining)。重叠间隔流水线通常可以描述为发送指令和屏障指令(barrier instruction)的连接。这种流水线方法使每个所述推理计算单元(例如块)能够使用少量的裸片上存储器(例如7nm asic,1个卡,2个裸片,128个块)构建,并以最小化块空闲的方式同步块之间的工作(从而优化处理速度)。
17.图1是包括dlasi 105的深度学习加速器100的示例框图。所述深度学习加速器100可以作为硬件实施,例如作为现场可编程门阵列(fpga)或其他形式的集成电路(ic)芯片(例如专用集成电路-asic)。作为fpga,所述加速器100可以包括数字数学单元(而不是基于忆阻器的模拟计算电路)。所述深度学习加速器100可以具有允许在同一硅片上运行各种深度学习应用的架构。如图1所示,所述dlasi(由虚线框表示)可以是几个部件的概念上的集合,包括:dli结构协议链路108;主机接口121;桥接器111;和交换机107。所述深度学习加速器100具有被划分为四个域的架构,包括:codi-深度学习推理域110;codi-简单域120;amba4-axi域130;和外围部件互连快速(pcie)域140。此外,图1用于说明所述dlasi 105可以作为裸片上互连实施,从而允许所公开的接口是完全集成的芯片内解决方案(相对于所述加速器芯片)。
18.pcie域140被示出为包括服务器处理器141之间的通信连接。所述pcie域140可以包括所述pcie接口131,作为将所述dli推理芯片连接到例如服务器处理器的主机处理器的高速接口。例如,服务器的主板可以具有用于接收附加卡(add-on card)的多个pcie插槽。所述服务器处理器141可以在与块106a-106n通信的商品服务器中实施,以用于执行深度学习操作,例如,图像识别。所述服务器处理器141可以实施为机架式服务器或刀片服务器,诸如xeon服务器,proliant服务器等。如上所述,通过支持多卡配置,所述加速器100可以支持更大的dnn。对于少量的fpga或asic(例如,四个fpga),有可能使用pcie:点对点(peer to peer)机制。在某些情况下,pcie链路可能无法传递足够的带宽,因而可以使用专用的fpga至fpga(或asic至asic)链路。
19.在所示的示例中,所述codi-深度学习推理域110包括块集(the sea of tiles)105,多个块106a-106n,交换机107和桥接器111。如所看到的,块集10由多个可彼此通信连接的块106a-106n组成。每个块106a-106n被配置为dnn推理计算单元,其能够执行与深度学习有关的任务,诸如计算,推理处理等。因此,所述块集105可以被认为是芯片上(on-chip)块网络106a-106n,在本文中也被称为dli结构。所述codi-dli域110包括codi互连,其用于将块彼此连接以及将块连接至主机接口控制器121。
20.每个单独的块106a-106n可以进一步包括多个核心(未示出)。例如,单个块106a可
以包括16个核心。此外,每个核心可以包括矩阵向量乘法单元(mvmu)。这些mvmu可以使用用于存储器内模拟计算的基于电阻式存储器(例如忆阻器)的交叉开关(cross-bar)来实施,或使用包括用于存储神经网络权值的静态随机存取存储器(sram)和用于计算的数字乘法器/加法器(相对于忆阻器)的数字电路来实施。在一个实施例中,所述核心可以实施全套指令,并采用四个256
×
256mvmu。块中的核心连接到块存储器。因此,例如,可以从驻留在块106a中的任何核心访问用于块106a的块存储器。所述块集105中的块106a-106n可以通过将数据报数据包发送到其他块来彼此通信。所述块存储器具有用于管理流控制的独特功能-块存储器中的每个元件具有计数字段,该计数字段通过读取递减并通过写入设置。而且,块106a-106n中的每个可以具有用于与所述其他块以及所述交换机107进行通信的裸片上结构接口(未示出)。所述交换机107可以提供块到块的通信。
21.因此,存在裸片上互连,其允许推理芯片与所述pcie域140连接。所述codi-深度学习推理域110是将许多计算单元彼此连接的独特结构。
22.所述深度学习推理(dli)结构协议链路108被配置为根据所述dli结构协议提供通信连接。所述dli结构协议可以使用低级别约定,例如codi提出的约定。所述dli结构协议可以是2虚拟通道(vc)协议,其使得能够构造简单而有效的交换机。所述交换机107可以是16端口交换机,其用作设计的基础。所述dli结构协议可以通过以确保结构停止(fabric stalling)少发生的方式设计更高级别的协议来实施为2-vc协议。所述dli结构协议支持大的标识符(id)空间,例如16位,进而支持可由主机接口121控制的多个芯片。此外,所述dli结构协议可以使用简单的排序规则,从而允许该协议被扩展到多个芯片。
23.所述dlasi 105还包括桥接器111。作为一般描述,所述桥接器111可以是从一个物理接口获取数据包并将其透明地路由到另一物理接口的接口,以促进它们之间的连接。所述桥接器111被示为在所述codi-简单域120中的主机接口121与在所述codi-深度学习推理域110中的交换机107之间的接口,桥接了域以用于通信。桥接器111最终可以将服务器存储器(将存储器视为64b缓存行的阵列)连接到所述dli结构,即块106a-106n(将存储器视为16位字的阵列)。在实施例中,所述桥接器111具有硬件功能,用于将输入数据分发到所述块106a-106n,收集输出和性能监视数据,以及从处理一个图像(或输入数据序列)切换到处理下一图像。
24.所述主机接口121提供输入数据并将输出数据传输到所述主机服务器存储器。为了实现简单的流控制,所述主机接口可以声明下一个间隔(interval)何时发生,并在块的puma核心都已经达到停止指令(halt instruction)时得到通知。当所述主机接口声明下一个间隔的开始时,每个块将其中间数据发送到下一个块集,以执行下一个间隔的计算。
25.在一个示例中,当pcie卡启动时,训练所述pcie域140中的链路。例如,所述pcie域140中的链路可以完成训练,时钟开始计时并且所述块从复位中被取出。然后,可以初始化所述卡中的块。然后,当将dnn加载到所述卡上时,可以加载矩阵权值,核心指令和/或块指令。
26.现在参照图2,描绘了包括多个dpe裸片250a-250l的多芯片接口系统200的示例架构。作为背景,ml已成为现代生活中不可或缺的一部分,使各种复杂的决策过程自动化。由于ml算法的数据密集型和矩阵向量乘法(mvm)-运算繁重的性质,常规cmos硬件可能在规模上提供有限的性能。因此,采用电阻式存储器技术(例如忆阻器)来并行执行计算(通过存储
忆阻器的权值)是一种可行的选择。但是,随着ml算法复杂性的提高,模型的计算强度和大小也在不断增长。神经网络模型的大小根据用例和所需的最低精度而有很大差异。例如,具有少于700万个突触权值参数(synaptic weight parameters)的小型深度可分离模型(例如mobile net-ssd)足以用于高级驾驶员辅助系统(adas)的中等精度行人和车辆对象检测。具有超过5000万个权值的更大模型(例如yolo v3或r-fcn w/resnet-101)可用于更高精度的对象检测,以实现完全自主的移动性,医学图像分析等。具有2-4亿权值的甚大模型可以用于自然语言机器翻译。
27.尽管从理论上讲,有可能在单个硅裸片上构建在忆阻器交叉开关中容纳4亿个权值的加速器asic(即8位/16位权值分辨率下为3.2/6.4gbit),但裸片尺寸将与当今一些最大的芯片(例如nvidia v100 gpu@815mm2)相抗衡,其产量低,成本高,占地面积大,并且仅支持裸片上最大模型的单个副本,限制了数据和模型的并行性,从而导致性能欠佳。
28.为了克服这些前述挑战,所公开的多芯片接口系统200扩展了所述dpe架构,以支持神经网络模型横跨多个硅dpe裸片250a-250l(在本文中也称为dpe asic)。所述系统200使得模块化架构能够以小得多的芯片尺寸适应于广泛的市场,其可以以低成本支持大量的权值(例如,使用支持多达约1亿个权值的未来的asic)。换句话说,可以调整设计中使用的芯片数量,以最适合特定的基于dnn的应用的复杂性,约束条件和性能要求。例如,单个芯片可用于嵌入式市场(adas等),pcie半宽/半高形状因数加速器板上的两个芯片(50-75w)可用于高性能边缘系统(包括el-1000/el-4000服务器或工作站),以及标准大小的pcie卡或专用加速器托盘上的四个或更多芯片可用于数据中心应用。
29.所述多芯片接口系统200具有可支持更大模型的可扩展架构。此外,所述系统200可以在支持大量dpe裸片250a-250l的同时提供低功率和成本有效的方法。在所示的示例中,所述系统200示为包括至少十二个dpe asic 250a-250l。而且,所述系统200利用交换机扩展,即pcie交换机260,以支持多个dpe asic 250a-250l之间的通信链路。如图2所示,多个dpe asic可以链接到单个dpe asic,该单个dpe asic又依次链接到所述pcie交换机260。例如,dpe asic 250d,dpe 250h和dpe asic 250l链接到所述pcie交换机260。dpe asic 250d具有多个与其链接的芯片,即dpe asic 250a,250b和250c。dpe 250h链接到dpe asic 205e,250f和250g。另外,dpe 250l链接到dpe asic205i,250j和250k。因此,dpe asic 250a-250l中的每个通信链接到面向所述pcie交换机260的所述服务器处理器241。各个dpe asic 250a-250l,所述pcie交换机260,和所述服务器处理器241之间的裸片外连接(用箭头表示)可以被实施作为结构链路。在一个实施例中,所述链路是pcie gen3链路。
30.或者,所述多个dpe asic 250a-250l之间的直接链路(未示出)可被实施以作为简单且快速的方法。然而,由于在使用直接链路时相对于更大连接性的成本的规模效率低下,使用所述pcie交换机260可能是被期望的。
31.此外,为了支持到多芯片互连系统中的其他dpe asic的裸片外互连,所述dpe asic250l可以包括多个pcie根端口接口252a-252c。pcie根端口接口(例如252a)可以用作所述dpe asic 2501与另一个具有到dpe asic 250l的直接互连(或结构链路)的dpe asic之间的接口。在一些实施例中,每个pcie根端口接口252a-252c对应于将所述dpe asic 250l连接到相应dpe asic的链路。在图2的示例中,pcie根端口接口252a与结构链路连接以创建从dpe asic 250l到dpe asic 250i的芯片到芯片互连。pcie根端口接口252b与不同的
结构链路连接,从而创建从dpe asic 250l到dpe asic 250j的芯片到芯片互连。pcie根端口接口252c与另一结构链路连接,从而创建从dpe asic 250l到dpe asic 250k的芯片到芯片互连。
32.所述dpe asic 250l还包括裸片上amba-axi交换机207。所述amba-axi交换机207可以提供所述dpe asic 250l和直接链接到其上的其他dpe asic之间的芯片到芯片通信。与所述基于dlasi的系统(如图1所示)相比,所述amba-axi交换机207以类似于由其裸片上交换机支持的块到块通信的方式支持芯片到芯片通信。
33.转向图3,所述dpe asic 250l还可以包括目标pcie接口231。所述目标pcie接口231可以是用于将所述pde asic 250l连接至主机处理器(例如,服务器处理器(如图2所示))的高速接口。所述dpe asic 2501可以由主机接口221控制。此外,所述主机接口221可以包括用于处理能力的核心222。在所示的示例中,核心222被实施为risc-v核心。
34.返回参考所述基于dlasi的系统(如图1所示),所述系统是一种分层设计,其实现了专门为深度学习推理加速器核心设计的多块通信协议以及节约面积的裸片上互连。但是,这种基于dlasi的系统依赖于块到块的边带导线(sideband wires)来指示块何时准备好接收新数据。具有容错结构的现代vlsi设计不能支持跨多个芯片的边带信号。因此,所述深度学习推理结构扩展为具有两个虚拟通道,一个通道用于高优先级同步数据包,另一个通道用于数据通信数据包。
35.在图3中,突出显示了来自所述多芯片系统200(图2所示)的单个dpe asic 250l,以便示出所述asic架构的内部部件。特别地,由于所述系统的多芯片设计,所述dpe asic 205l包括多芯片支撑块251,其在先前所述的基于dlasi的系统中未使用。所述多芯片支撑块251被配置为桥接裸片外互连到裸片上互连的需求。与许多低带宽的裸片上链路相比,所述dpe asic的裸片外互连(即pcie链路)的带宽更少且更高。为了充分利用所述裸片外链路,所述多芯片支撑块251被配置为对裸片到裸片数据包执行缓冲。为了使流控制变得简单并与大多数商品结构兼容,所述多芯片接口系统中的流控制是基于信用的。因此,所述系统可以有效地使用其芯片到芯片互连,而不会引入过于复杂的数据包仲裁。此外,所述结构协议和指令集架构支持多达4096个块。在一个实施方式中,多芯片块可支持多达64个块,从而允许扩展(scaling)以适应全系列流行的dnn尺寸。
36.所述多芯片扩展不会使更高级别的软件框架复杂化。举例来说,当dpe编译器将模型映射到所述dpe asic 250l上的互连块集205时,不管硬件拓扑如何,其可以使用逻辑标识。这允许从高级框架提供的模型定义到dpe硬件的无缝映射。一旦所述dpe编译器生成具有逻辑块的装配模型,dpe调度器软件就会提供对物理块的转换(translations),所述物理块例如为互连块集205,其由芯片-标识,团(clump)-标识和块-标识的组合来标识。最终,dpe加载器可以在其将模型加载到硬件时,根据提供的即时转换来转换汇编代码。
37.现在参考图4a,示出了由计算机系统480执行并利用多芯片接口系统455(也在图2中示出)的对象识别应用的示例。所述对象识别应用450可以接收初始图像452(在图4a中示为“预处理图像x”),诸如以视频格式(例如1mb)流到主机计算机的图像帧。因此,如本文所指,图像452是指预处理(例如,在对象识别分析之前)。然后,所述图像452被发送以由所述多芯片接口系统455使用dnn推理技术进行分析。该示例特别涉及基于“you only look once(yolo)-tiny”的实施方式,其是可用于视频对象识别应用的一种dnn。根据该示例,
yolo-tiny可以映射到所述多芯片接口系统455上。例如,所述多芯片接口系统455可以在硬件中实施为多个fpga芯片,这些芯片能够使用yolo-tiny框架作为实时对象检测系统对视频流执行对象识别。
38.主机上的os接口453可以发送请求以分析工作队列454中的数据。接下来,门铃(doorbell)459可以作为所述请求的指示被发送,并被传送到所述多芯片接口系统455的主机接口。如本文所用,所述术语“门铃”是指接口通信协议中的一种常见的信号。所述门铃459是用于通知主机控制器输入数据可在主机系统工作队列454中进行处理的信号。当与图像分析有关的工作由所述os接口453放入工作队列454中并且门铃459响时,所述主机接口可以从队列454中获取图像数据。此外,当从所述多芯片接口系统455获得分析结果时,生成的对象可被放置在完成队列456中,然后转移到服务器主存储器中。所述主机接口可以读取请求,然后使用桥接器和块(以及其中运行的指令)“填鸭式灌输”图像,所述块分析图像数据以进行对象识别。根据实施例,所述dli结构协议是允许最终完成向块的这种“填鸭式”工作的机制。也就是说,之前描述的结构协议和其他多芯片系统部件将协议域链接到硬件域。
39.所述对象识别应用450的结果可以是与识别对象相关联的边界框和概率。图4a描绘了可能由于运行所述对象识别应用450而产生的后处理图像460(在图4a中显示为“后处理图像x”)。因此,图像452表示在由所述对象识别应用处理之前的图像,并且图像460表示随后由所述对象识别应用处理的图像,包括各种识别对象。在所述图像460内的对象周围存在三个边界框,这些边界框已被识别为“人”的视觉表示(visual representations),每个具有显示为“63%”,“61%”和“50%”的关联概率。在图像160中还存在以“50%”概率识别为“键盘”并且以“51%”概率识别为“tv监视器”的对象。
40.图4b示出了块级流水线的示例,其允许同时处理不同的图像。详细地,图4b示出了协调图像,推断和结果的dma(直接存储器访问)传输的多芯片接口系统。作为背景,在计算上,典型的dnn算法主要由矩阵矢量乘法和矢量运算的组合组成。dnn层使用非线性计算来打破输入对称性并获得线性可分离性。核心是可编程的并且可以执行指令以实施dnn,其中每个dnn层在执行低级计算的指令方面在根本上都是可表达的。这样,dnn的多层通常被映射到所述多芯片系统的多个芯片的多个块,以便执行计算。另外,在图4b的示例中,用于图像处理的dnn的层也被映射到所述多芯片接口系统的块474a-474e。在该示例中,所述系统包括多个芯片,即芯片0,芯片1和芯片2,并且多个块可以在相应芯片上实施。例如,芯片0包括块0 474a和块1 474b;芯片1包括块0 474c和块1 474d;芯片2包括块0 474e。应当理解的是,在图4b所示的芯片之间的块的分区并非旨在限制,而是用作示例。该分区可以基于特定的实施方式而变化,例如取决于神经网络模型的大小。
41.如所看到的,在服务器存储器级别471处,图像0 472a,图像1 472b和图像2 472c作为输入以流水线方式被发送以被多个块474a-474e(在相应芯片上)接收。换句话说,图像数据可能不会同时被发送。而是,如本文所公开的流水线方案可以错开图像数据段(如所示的图像0 472a,图像1 472b和图像2 472c)的传输和处理。在被所述块474a-474e接收之前,所述图像472a-472c在所述主机接口级别473处被接收。所述主机接口级别473首先将图像0 472a传输到所述块474a-474e。在该示例中,由所述块474a-474e执行的推理工作如下所示:芯片0 474a中的块0和芯片0 474b中的块1用于针对图像0 472a映射dnn层计算的第一层;芯片1 474c中的块0和芯片1 474d中的块1用于针对图像0 472a映射dnn层计算的中间层;
以及芯片2 474e中的块0用于针对图像0 472a映射dnn层计算的最后一层。然后,随着流水线的推进,在完成最后一层的计算之后,针对图像0 475a的对象检测可以被输出到所述主机接口级别473。在流水线的下一间隔,针对图像0 475a的对象检测可以被转移到所述服务器存储器471。此外,根据流水线方案,当针对图像0 475a的对象检测正被发送到所述服务器存储器475a时,针对图像1 475b的对象检测可以被转移到所述主机接口级别473。
42.在卷积神经网络(cnn)的早期阶段比在cnn推理的后期阶段可以执行更多次的迭代。因此,在一些实施例中,附加资源(块或核心)可以被分配给这些更多的迭代阶段。总体而言,图像识别性能可以由流水线推进速度来确定,并且在某些示例中,流水线推进速度可以由花费最长时间来完成其工作的块来设置。在每个流水线间隔开始之前,所述dnn接口都会设置输入数据并捕获输出数据。
43.现在参照图5,描绘了基于fpga的多芯片仿真设置500的示例,其仿真所述多芯片接口系统(图2所示)的硬件。fpga仿真器平台能够在dpe fpga软件开发框架上运行大量常用的神经网络模型。此外,神经网络跨越被认为是迈向未来可组合性和虚拟化的第一步,其跨加速器池对许多单/多租户推理工作负载进行软件定义分区,而无需担心特定的物理硬件关联。如图5所述,为了复制多芯片的设置500,可以利用xilinx alveo现成的fpga卡。同样,可以在所述设置500中使用扩展的pcie接口,其通过利用pcie点对点能力而被用于主机通信以用于芯片-芯片通信。为了使接口能够独立于系统级别约束条件(例如,缺少pcie通道)进行扩展,启用了两个fpga卡之间的芯片到芯片(c2c)连接,其将所述多芯片仿真设置400扩展到多台机器,并且使得能够映射较大模型。
44.图6描绘了示例计算机系统600的框图,其中可以实施如本文所述的多芯片接口系统(图2所示)。所述计算机系统600包括总线602或用于传送信息的其他通信机制,以及与总线602耦接的用于处理信息的一个或多个硬件处理器604。硬件处理器604例如可以是一个或多个通用微处理器。
45.所述计算机系统600还包括主存储器606,例如随机存取存储器(ram),高速缓存和/或其他动态存储装置,所述主存储器耦接到总线602,用于存储要由处理器604执行的信息和指令。主存储器606还可以用于存储在执行将由处理器604执行的指令期间的临时变量或其它中间信息。这些指令当被存储在处理器604可访问的存储介质中时,使计算机系统600成为被定制为执行指令中指定的操作的专用机器。
46.所述计算机系统600进一步包括耦接到总线602用于存储处理器604的静态信息和指令的诸如只读存储器(rom)或其它静态存储装置的存储装置610。如磁盘、光盘或usb拇指驱动器(闪存驱动器)等存储装置610被提供并耦接到总线602,用于存储信息和指令。
47.所述计算机系统500可以经由总线602耦接到显示器612,例如液晶显示器(lcd)(或触摸屏),以用于向计算机用户显示信息。输入设备614(包括字母数字键和其他键)被耦接到总线602,以用于将信息和命令选择传输到处理器604。用户输入设备的另一个类型是光标控制装置616,例如鼠标,轨迹球或光标方向键,用于将方向信息和命令选择传输到处理器604并且用于在显示器612上控制光标移动。在一些实施例中,可以通过在没有光标的情况下接收触摸屏上的触摸来实施与光标控制装置相同的方向信息和命令选择。
48.所述计算系统600可以包括用于实施gui的用户界面模块,该gui可以作为由计算设备执行的可执行软件代码存储在大容量存储装置中。该模块和其他模块例如可以包括:
部件(component)(例如软件部件,面向对象的软件部件,类部件和任务部件),进程,功能,属性,程序,子例程,程序代码段,驱动程序,固件,微代码,电路,数据,数据库,数据结构,表,数组和变量。
49.通常,如本文所使用的词语“部件”,“引擎”,“系统”,“数据库”,“数据存储”等可以指硬件或固件中体现的逻辑或指用诸如java,c或c++等编程语言编写的可能具有入口和出口点的软件指令的集合。软件部件可以被编译并被链接到可执行程序中,被安装在动态链接库中,或者可以用诸如basic,perl或python之类的解释性编程语言编写。应当理解,软件部件可以从其他部件或从其自身调用,和/或可以响应于检测到的事件或中断而被调用。被配置为在计算设备上执行的软件部件可以在计算机可读介质(例如光盘,数字视频光盘,闪存驱动器,磁盘或任何其他有形介质)上提供,或以数字下载的形式提供(并且可以最初以压缩或可安装的格式存储,执行之前需要安装,解压缩或解密)。这样的软件代码可以部分地或全部地存储在执行计算设备的存储装置上,以供计算设备执行。软件指令可以嵌入在诸如eprom的固件中。还应当理解,硬件部件可以包括连接的逻辑单元,例如门和触发器,和/或可以包括可编程单元,例如可编程门阵列或处理器。
50.所述计算机系统600可以使用定制的硬连线逻辑,一个或多个asic或fpga,固件和/或程序逻辑来实现本文所述的技术,其结合所述计算机系统使计算机系统600或将其编程为专用机器。根据一个实施例,本文所述的技术由计算机系统600响应于处理器604执行包含在主存储器606中的一个或多个指令的一个或多个序列来执行。这些指令可以从诸如存储装置610的另一存储介质读取到主存储器606中。执行包含在主存储器606中的指令序列使处理器604执行本文所述的处理步骤。在替代实施例中,硬连线电路可以用来代替软件指令或与软件指令结合使用。
51.如本文所使用的,可利用任何形式的硬件,软件或其组合来实现电路。例如,一个或多个处理器,控制器,asic,pla,pal,cpld,fpga,逻辑部件,软件例程或其他机制可被实施来构成电路。在一个实施方式中,本文描述的各种电路可以实现为分立电路,或者所描述的功能和特征可以在一个或多个电路之间部分或全部共享。即使可以将各种特征或功能元素单独描述或要求保护为单独的电路,这些特征和功能也可以在一个或多个通用电路之间共享,并且此类描述将不需要或暗示需要单独的电路来实现此类特征或功能。在使用软件全部或部分地实现电路的情况下,该软件可以实现为与能够执行相对于此所描述的功能的计算或处理系统(例如计算机系统500)一起操作。
52.如本文所使用的,术语“或”可以用包括性或排他性的意义来解释。而且,对资源,操作或结构的单数形式的描述不应理解为排除复数。除非另外明确说明或在所使用的上下文中以其他方式理解,否则条件性语言(例如“能够”,“能”,“可能”或“可以”等)通常旨在传达某些实施例包括某些特征,元件和/或步骤,而其他实施例不包括某些特征,元件和/或步骤。
53.除非另有明确说明,否则本文档中使用的术语和短语及其变体应解释为开放式的,而不是限制性的。诸如“常规的”,“传统的”,“正常的”,“标准的”,“已知的”等形容词和类似含义的术语不应解释为将所描述的项目限制到给定时间段或在给定时间内可用的项目,但是应该理解为包括现在或将来任何时候可用或已知的常规的,传统的,正常的或标准的技术。在某些情况下,诸如“一个或多个”,“至少”,“但不限于”或其他类似的短语的广义
词汇和短语的存在不应理解为是指在可能不存在这种广义短语的情况下,意指或要求使用更狭义的情况。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1