一种获取水氮策略的人工智能方法、系统和电子设备与流程
本发明涉及农业
技术领域:
,尤其涉及一种获取水氮策略的人工智能方法、系统和电子设备。
背景技术:
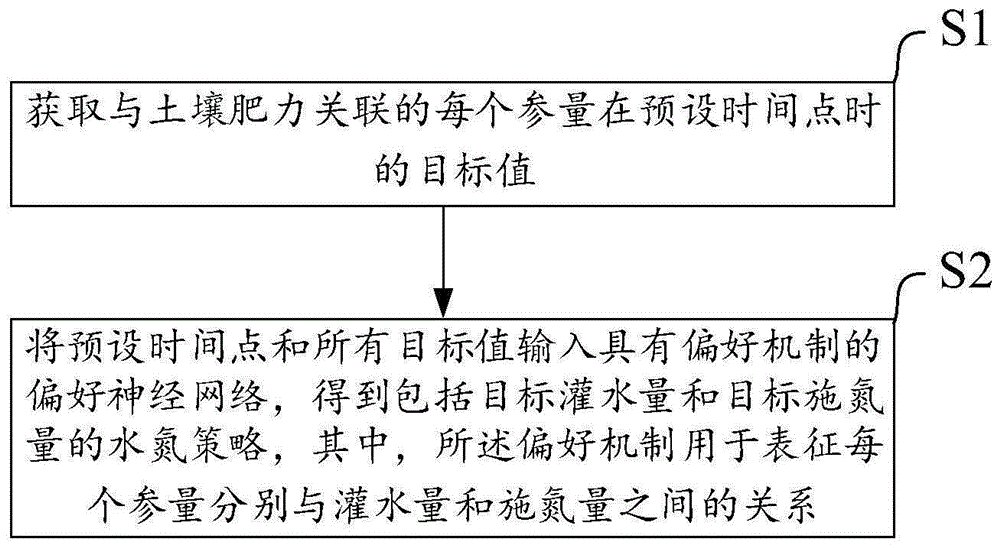
:以提升作物根区土壤肥力为目标,准确提出秸秆深埋下优化水氮策略对提升河套灌区土地生产力、缓解面源污染及促进精准农业发展意义重大。但目前研究方法中,无论采取田间试验、物理模型还是人工智能手段,大多只能先通过有限的水氮处理揭示出对其土壤、植株指标的影响趋势,然后得出优化水氮规律,导致得到的水氮策略普遍不够精准。技术实现要素:本发明所要解决的技术问题是针对现有技术的不足,提供了一种获取水氮策略的人工智能方法、系统和电子设备。本发明的一种获取水氮策略的人工智能方法的技术方案如下:获取与土壤肥力关联的每个参量在预设时间点时的目标值;将预设时间点和所有目标值输入具有偏好机制的偏好神经网络,得到包括目标灌水量和目标施氮量的水氮策略,其中,所述偏好机制用于根据每个参量分别与灌水量和施氮量之间的客观关系对神经网络可学参数进行有侧重的训练。本发明的一种获取水氮策略的有益效果如下:首次提出用于表征每个参量分别与灌水量和施氮量之间的关系的偏好机制,由此得到的具有偏好机制的偏好神经网络可自然地将神经网络结构与数据在自然界中的先验规律相融合,在大幅提高模型即偏好神经网络的收敛性的同时,还能有效提升预测精度,得到最优的水氮策略。本发明的一种获取水氮策略的人工智能系统的技术方案如下:包括第一获取模块和第二获取模块;所述第一获取模块用于获取与土壤肥力关联的每个参量在预设时间点时的目标值;所述第二获取模块用于将预设时间点和所有目标值输入具有偏好机制的偏好神经网络,得到包括目标灌水量和目标施氮量的水氮策略,其中,所述偏好机制用于表征每个参量分别与灌水量和施氮量之间的关系。本发明的一种获取水氮策略的人工智能系统的有益效果如下:首次提出用于表征每个参量分别与灌水量和施氮量之间的关系的偏好机制,由此得到的具有偏好机制的偏好神经网络可自然地将神经网络结构与数据在自然界中的先验规律相融合,在大幅提高模型即偏好神经网络的收敛性的同时,还能有效提升预测精度,得到最优的水氮策略。本发明的一种电子设备的技术方案如下:包括存储器、处理器及存储在所述存储器上并在所述处理器上运行的程序,所述处理器执行所述程序时实现如上述任一项所述的一种获取水氮策略的人工智能方法的步骤。附图说明图1为本发明实施例的一种获取水氮策略的人工智能方法的流程示意图;图2为偏好神经网络的结构示意图;图3为sigmoid函数的示意图;图4为sigmoid函数的导数的示意图;图5为relu函数的示意图;图6为relu函数的导数的示意图;图7为偏好矩阵的形式嵌入神经网络的结构示意图;图8为预测土壤有机质含量的结果;图9为预测土壤总氮含量的结果;图10为预测土壤含盐量的结果;图11为预测ph值的结果;图12为ec值与含盐量线性关系图;图13为播种后第17天时即苗期的土壤有机质总量的曲面;图14为播种后第59天时即拔节期的土壤有机质总量的曲面;图15为播种后第87天时即灌浆期的土壤有机质总量的曲面;图16为播种后17天时即苗期的土壤总氮含量的曲面;图17为播种后第59天时即拔节期的土壤总氮含量的曲面;图18为播种后第87天时即灌浆期的土壤总氮含量的曲面;图19为播种后17天时即苗期的土壤含盐量的曲面;图20为播种后第59天时即拔节期的土壤含盐量的曲面;图21为播种后第87天时即灌浆期的土壤含盐量的曲面;图22为播种后17天时即苗期的ph值的曲面;图23为播种后第59天时即拔节期的ph值的曲面;图24为播种后第87天时即灌浆期的ph值的曲面;图25为最优水氮策略的目标灌水量的上下限;图26为最优水氮策略的目标施氮量的上下限;图27为本发明实施例的一种获取水氮策略的人工智能系统的结构示意图。具体实施方式如图1所示,本发明实施例的一种获取水氮策略的人工智能方法,包括如下步骤:s1、获取与土壤肥力关联的每个参量在预设时间点时的目标值;s2、将预设时间点和所有目标值输入具有偏好机制的偏好神经网络,得到包括目标灌水量和目标施氮量的水氮策略,其中,所述偏好机制用于表征每个参量分别与灌水量和施氮量之间的关系。首次提出用于表征每个参量分别与灌水量和施氮量之间的关系的偏好机制,由此得到的具有偏好机制的偏好神经网络可自然地将神经网络结构与数据在自然界中的先验规律相融合,在大幅提高模型即偏好神经网络的收敛性的同时,还能有效提升预测精度,得到最优的水氮策略。其中,与土壤肥力关联的多个参量包括:土壤有机质含量(soilorganicmattercontent)、土壤总氮含量(soiltotalnitrogencontent)、土壤含盐量(soilsaltcontent)、ph值等。较优地,在上述技术方案中,还包括:s020、搭建神经网络;s021、获取每个参量分别与灌水量和施氮量之间的偏好值并进行归一化,得到偏好矩阵,把偏好矩阵引入到神经网络,并结合adam算法,训练得到具有偏好机制的偏好神经网络。较优地,在上述技术方案中,所述搭建神经网络还包括:s0201、将relu函数作为神经网络的激活函数,以relu函数作为神经网络的激活函数,解决了神经网络的梯度消失问题。较优地,在上述技术方案中,所述搭建神经网络还包括:s0202、将dropout算法引入神经网络;s0203、将批标准化引入神经网络。将dropout算法和批标准化引入神经网络,有效降低了出错风险和运算成本,提高运算效率。通过下面一个实施例对本申请的一种获取水氮策略的人工智能方法进行详细说明:s10、选取试验田,具体地:本试验于2017年4月至10月在内蒙古河套灌区中游临河区双河镇农业综合节水示范区开展,试验区隶属永济灌域(北纬40°42',东经107°24'),属中温带半干旱大陆性气候,多年平均降水量138mm,多年平均蒸发量2332mm,降雨大多集中在夏秋季,春冬地表返盐较为严重,2017年玉米生育期降雨量分别为75.3mm。试验区0-40cm土壤属于粉砂壤土,平均容重为1.42-1.53g·cm-3,中度盐碱地,土壤物理性质见下表1:表1s11、试验设计。具体地:以内蒙古河套灌区主要种植作物玉米为供试材料,采用当地常规品种(西蒙168)开展田间试验。试验在中度盐渍化土壤下(ec值介于0.7~1.24ms/cm)进行,在40cm土层深处埋设玉米秸秆层,厚度5cm,随后平整土地,农药选取莠去津除草剂,施量按当地常规。除秋浇及春灌外,在玉米全生育期内灌黄河水3次,灌溉方式为畦灌,设3个灌水水平,灌水定额即灌水量分别为60mm、90mm、120mm;施用肥料采用尿素(46%n)和磷酸二铵(18%n,46%p2o5),设4个施氮量的水平,分别为135kg/hm2、180kg/hm2、225kg/hm2、280kg/hm2。试验中50%的氮肥及全部的磷、钾肥在播种前作为基施施入,剩余氮肥分别在二水、三水前按每次25%等量追施;试验共设13个处理,3次重复,共39个小区,每小区面积为8×9=72m2,四周用埋深1.2m的聚乙烯塑料膜隔开,顶部留30cm,防止各小区肥水互窜,田间管理与当地农户管理一致。玉米于4月下旬铺地膜、播种,9月中、下旬收获。玉米膜宽1.1m,一膜2行,株距约45cm,行距35cm,玉米种植密度为6万株/hm2。具体设计见下表2:编号处理灌水定额(mm)施氮量(kg/hm2)1w1n1601352w1n2601803w1n3602254w1n4602805w2n1901356w2n2901807w2n3902258w2n4902809w3n112013510w3n212018011w3n312022512w3n412028013当地135325表2s13、观察和测量,具体地:通过四项指标综合评价土壤肥力,四项指标包括:土壤有机质含量、土壤总氮含量、土壤含盐量、ph值,即四项参量。取样及测定方法如下:s130、试验开始前,在每处理小区用土钻取0-20cm、20cm-40cm、40cm-60cm、60cm-80cm、80cm-100cm共5层土样,深度为100cm,每层三个重复。取土后测定土壤容重,并进行土壤颗粒粒径分析;s131、在作物全生育期内,每20cm为一个层次,共取5层,深度为100cm。用土钻在取样区采用三点法,分别采集0-20cm、20cm-40cm、40cm-60cm、60cm-80cm、80cm-40cm土层土样,在4℃冷藏保存,测定土壤有机质含量、土壤总氮含量、土壤含盐量、ph值,具体地:利用kdn-aa双管定氮仪测定土壤总氮含量,利用mwd-2型号微波通用消解装置测定土壤有机质含量,利用tu1810pc型紫外可见光分光光度计测定土壤含盐量,利用tu18950双光束紫外可见光分光光度计测定ph值。s14、定义偏好值,具体地:以往农田水利学中,通常利用皮尔逊相关系数r(x,y)法表示两个变量间的相关性,公式为:其中,r(x,y)表示皮尔逊相关系数,最早由统计学家卡尔·皮尔逊设计(pearson,e.s.etal,1955),是用于研究变量x、y之间线性相关程度的量,var[x]为x的方差,var[y]为y的方差;其中,cov(x,y)为x与y的协方差,表示的是两个变量的总体的误差,公式为:假设两组数据x和y都包含n个元素,e表示x、y的期望值,可见,如变量x、y变化趋势一致(如同时大于自身期望值)则cov(x,y)为正值,反之为负值,如x、y分布无相关性,则(xi-e(xi))(yi-e(yi))有正有负,导致cov(x,y)最终趋近于0。如x、y存在显著相关性,则绝对值很大,从而cov(x,y)趋于1;如所有样本相关系数呈对称分布,则r的显著性可用t检验来进行。x、y间相关性的显著性常用p表示,p<0.05表示x与y显著相关,p<0.01表示x与y极显著相关;p需在特定样本容量下根据t值查表获取,t值公式为:其中n为样本的数量且n为正整数,r是皮尔逊相关系数,由于存在两个变量x、y,故自由度为n-2。为提高冗杂的全连接的神经网络的收敛性,偏好值作为用来计算农田水利中不同指标间依存程度的统计量,是上述相关性和显著性的集中体现。偏好值是在皮尔逊相关系数的基础上,结合显著性将变量之间的内在正负相关性进一步放大或缩小,使其在表征关联性的同时,更加显著的表达出指标间相互作用程度,从而更全面有效的体现水氮处理等试验控制因素与土壤、作物等指标间的内在关系,偏好值(preferencevalues)计算公式为:其中,pvij为变量xi和yj间的偏好值,xi代表第i个与试验处理有关的变量即参量,如本申请中的灌水水平即灌水量、施氮水平即施氮量,yj代表第j个在不同处理下由试验监测获取的指标变量,具体为:土壤有机质含量、土壤总氮含量、土壤含盐量、ph值,以及土壤取样时间点、深度,e为常数且e取0.001,用于防止公式分母为0。s15、偏好值的归一化,具体地:为使各指标间的偏好值处于同一数量级,以变得更加稳定和方便计算,将偏好值进行归一化处理,公式为:其中,取绝对值,而pvnormal的正负由相关性r的正负决定。s16、搭建神经网络,具体地:s160、定义神经网络的输入端和输出端,具体地:1)定义神经网络的输入端为矩阵其中,n为样本容量,如n=420;d为每个输入向量的维数,如d=6,其中{xi}i=1,…,n∈x代表用于衡量土壤肥力的土壤有机质含量的目标值、土壤总氮含量的目标值、土壤含盐量的目标值、ph值的目标值的四项指标即参量及施氮灌水时间(用播种后天数表示)即预设时间点的向量化集合;2)定义神经网络的输出端为代表灌水量和施氮量的矩阵神经网络的目标是通过给定的输入端矩阵x学习到固定的映射即得到偏好神经网络,θ为通过pnn训练能够得到良好优化的可学参数,而预测值y'则会无限向实测值y逼近。s161、得到神经网络的结构,具体地:本申请首次提出的偏好神经网络(pnn)是一种典型的深度学习(deeplearning,dl)模型。pnn可以被看作是描述土壤有机质含量、土壤总氮含量、土壤含盐量、ph值分别与灌水量、施氮量之间完全依赖关系的近似自然函数。具体来讲,神经网络通过构造映射y=f(x,θ)并学习参数θ使该函数达到最优化,以得到偏好神经网络,神经网络的结构如图2所示,图2也为偏好神经网络的结构;图2中的relu即relu函数,preferencematrix即偏好矩阵,batchnormlayer即进行批标准化的层;神经网络的结构中,层间信息流仿射变换的良好定义是神经网络模型训练的关键。一般而言,每层的可学参数θ包含权重参数w和偏好参数b。神经网络中第l层隐含表示hl定义为:其中,wl和bl分别表示可学到的l层权重和偏好变量,hl-1是上一层的隐含表示,当l=1时,h0=x,使用分层更新规则,给定的输入数据流通过具有中间操作的各个隐层,最后到达输出端。得到神经网络的结构包括:1)将relu函数作为神经网络的激活函数,具体地:激活函数将非线性机制引入神经网络,使它们能够在输入的分布范围内任意逼近形式复杂的自然函数,没有激活函数的多层结构由于其线性特性而等同于单层模型。然而,目前的许多研究都未能采用正确的激活函数,多数现有研究都只在浅层模型中引入sigmoid函数导致其模型性能欠优(cybenko,1989)。在此部分,我们将详细阐述sigmoid函数在制定水肥优化策略中不合适的原因,并将relu函数引入到所提出的神经网络中,具体地:①sigmoid激活函数又称logistic函数,其数学表达式为:图3和图4表明其压缩变换的数值范围在0和1之间,这使得模型在饱和状态时梯度易趋近于0(那些隐藏值接近0或1的神经元梯度值为0)。显然,饱和神经元的权值参数无法更新,与此同时,与这些饱和神经元连接的神经元传播缓慢,这种现象被称为梯度消失。此外,另一个不利于sigmoid函数在深度学习结构中应用的原因是,sigmoid中的exp(·)运算如被应用于模型的每一层,将使sigmoid函数在计算复杂度上变得繁重。②relu函数可以有效处理上述问题,图5和图6表现出relu函数的“半调整”特点,其数学表达式为:relu(x)=max(0,x),那么:当x<0时,relu激活使输出为0,否则x保持原始值,这样简洁的操作将使整个神经网络的传播和收敛更加有效。由于relu将神经元从边界限制中解放出来,至少有一定数量的神经元从正区域进行反向传播,避免了梯度消失的问题。在本文中,我们在每一个隐层之后应用relu来进行非线性变换。该操作可以表示为:其中,是批标准化的隐藏表示,将在下面详细说明。2)将批标准化引入神经网络,具体地:虽然深度神经网络得益于深度架构中获得的优秀泛化能力而变得十分有效,但其通过所有神经网络层中的可学习参数转换输入数据的机制,导致训练过于复杂。在此情况下,这些参数的细微变化将随着网络的深入而被无限放大。各层输入分布不断变化,而后续各层又不得不一直服从更新后的分布,此情况大大削弱了训练过程的稳定性和模型本身的稳定性。考虑到具有六层结构的偏好神经网络pnn同样会遇到与上述问题,所以利用批标准化(batchnormalization)来改善训练的迭代过程和增强模型稳定性(ioffeandszegedy,2015)。批标准化(batchnormalization)操作共分四步:①设置迷你批b,得到迷你批b中所有元素的均值为:其中,m为每个迷你批(mini-batch)中的样本数;②获取批均值μb对应的方差具体通过得到批均值μb对应的方差③标准化操作可用批采样的均值和方差表示为:其中,l是为防止σ等于0而设置的非常小但不为0的数。④通过两个可学习的参数对标准化的隐藏层表达进行缩放和移位:γ表示用来提高神经网络的表达能力的规模参数,β表示用来提高神经网络的表达能力的位移参数,γ和β均可通过模型训练得到。批标准化变换总体演示如下:令:最小批量lth隐层表示;l:层数;m:每个迷你批(mini-batch)中的样本数;γ:规模参数,可通过学习获得;β:位移参数,可通过学习获得;输出:1.forl=1,2,3,······,ldo;2.更新迷你批均值:3.更新迷你批方差:4.标准化迷你批的隐含表达:5.对标准化后的隐含表示进行平移和缩放:6.endfor3)将dropout算法引入神经网络,具体地:有限的训练数据集通常会导致复杂的深度结构在训练过程中不得不强制适应所输入数据的特性,这种现象通常被称为过拟合(overfitting)或协同适应(co-adaptation)。dropout算法是一种通过在每次训练迭代中,将非输出神经元从非线性模型中随机悬置,从而以低计算成本(计算复杂度为o(n))有效解决上述问题的方案,dropout算法具体以dropout模块的形式引入。具体而言,dropout算法通过对一个二进制掩码进行采样,以将网络中输入层和隐藏层生成的隐含表示相乘。输出值乘以0的神经元在当前的训练迭代中被暂时悬置。对于每一层掩码的采样都是不相关的,掩码中值为1的概率是整个网络的一个预定义超参数。dropout算法在数学上可以用分层方法表示:其中,为元素点乘操作,dl为第l层的dropout掩码,p′是训练前预先定义的dropout超参数。4)引入偏好结构,具体地:现有基于bp神经网络的模型构建策略大多仅凭借较为简单的结构直接获取输入和输出端的映射关系,而从本质上忽略了农业水土工程相关因素间的自然运行规律,导致神经网络性能大打折扣。为最大程度的同时发挥农业水土领域的先验知识优势和人工神经网络出色的学习优势,本文提出的偏好神经网络(pnn)顺势利用农业水土工程因素间的内在相关性进行模型性能优化。具体而言,本申请首次提出偏好值的概念,并用以此为基础计算出的偏好矩阵明确表达了输入端各指标与水氮配施策略间的内在依存关系。pnn通过使偏好矩阵与输入和输出间的可学习权值进行哈达玛积(hadamardproduct),将偏好矩阵融合到神经网络结构中。在这种情况下,神经网络由于受到偏好矩阵的强约束指导而学习基于农业水土工程先验知识的映射。参考在分层仿射变换中的公式:pnn的偏好约束的数学表达式为:hl(hl-1;wl,b1)=htl-1wl⊙p+bl,其中,p为通过公式和表8计算得到的偏好矩阵。⊙是矩阵对应元素间的哈达玛积。对于传统的全连接神经网络内的节点,均要与下一层的所有节点相连接,进而在误差的逆向传播阶段进行每一层权重值和偏置值的迭代更新。虽然,全连接神经网络被证明可以很好的建立变量间的未知关系,但其过于冗杂的结构却势必会拖慢模型的运行速度。此外,相关性极低的变量与关系十分密切的变量,由于二者所对应的节点在全连接网络中拥有相等的连接数,导致模型受到干扰,最终影响收敛。偏好神经网络pnn的偏好结构即偏好机制可以很好的解决上述问题,其建立源于一个大胆的构想,即通过改变模型输入端变量对应节点的连接权重矩阵,可以对神经网络的学习过程进行人为干预和引导,进而强调某些变量间关系和弱化其他关系。具体为,通过实测数据反映出的自变量与因变量间相关性,初步评价每一自变量对因变量的影响强弱,并将这种强弱关系通过偏好矩阵的形式嵌入神经网络中,最终大幅优化神经网络收敛速度,如图7所示;且图7中,不同输入节点与隐含层的连接线数目代表该点对应变量根据自身偏好性获得的连接强度,利用权重矩阵和偏好值矩阵进行哈达玛积将使得每个输入端节点与隐藏层的连接关系根据自然规律具有偏好性,与输出端关系较强的输入端变量(例如土壤含盐量)将获得更大的连接强度,且图中网络的深度只是为了说明偏好连接结构,并不是实验中使用的pnn的深度。s17、训练,具体地:①逆向训练方案(reversetrainingscheme),具体地:以往利用bp神经网络(bpneuralnetwork)解决农田水利的水氮优化问题的研究多为建立从处理到指标的正向训练(forwardtrainingscheme)参数模型。这些基于正向训练方案(forwardtrainingscheme)得到的神经网络模型受限于输入输出端分别为实施策略和目标参数,不得不在模型建立之后通过比较大量的水肥策略提出较优处理,而无法直接根据所需参数的目标值制定最优策略从而实现端对端的高效决策输出,未能充分利用到人工智能中深度学习框架的优势。农田水肥策略与目标参数间存在的客观因果关系被许多田间试验研究所验证,这种关系所对应的映射并不会由于因与果顺序的调转而改变。模型研究的本质是通过对自然界客观存在的因果关系的揭示与学习,从而进行实际生产策略的优化。而传统映射关系下训练的神经网络无法直接提出最优策略,只能提出某一策略对应的目标参数。本申请首次提出的逆向训练方案(reversetrainingscheme)是一种将因果关系的逆向映射关系应用于模型训练过程进而通过目标参数直接制定最优策略的神经网络训练方案,其在决策研究中避免了正向训练过程导致的结构性低效和所提出策略代表性不足的问题,进而获得更高效的决策性能。②目标函数(objectivefunction),具体地:农田水利领域得到广泛应用的均方根误差(rmse)和标准差(mse)往往由于过于灵敏的检测出数据异常值而易对模型性能产生负面影响。为提高模型的鲁棒性,我们利用huber损失(也称平滑l1损失)作为计算梯度和本文更新模型的目标函数。huber损失从本质上上平衡了rmse的过敏感性和平均绝对误差(mae)的弱敏感性,其采用的分段定义为:其中,k代表一个执行决策操作的平衡器,其存在可在损失值大于k时放大损失值,而小于k的缩小损失值。③优化,具体地:不同于以往研究中由于采用随机梯度下降法(sgd)造成的大斜率反复迭代不收敛和所有神经网络参数只能采用统一学习率问题,偏好神经网络(pnn)通过采用adam操作即adam算法可使其在训练阶段稳定且平滑的达到收敛状态。动量项vt和指数加权移动平均项s作为adam最核心的两部分(也被成为“漏平均项”),通常都取0进行初始化。其中,adam算法如下:令:b=*x1,…,xm}分别对应的y(i);m:迷你批(mini-batch)中的样本数;t:迭代次数;v:动量项;s:平均遗漏项;βv:v的非负超参数;βs:s的非负超参数;ε:稳定常数;初始化:v=0,s=01.fort=0,1,2,......,tdo2.梯度生成:3.t=t+1;4.动量项计算:vt=βvvt-1+(1-βv)gt;5.计算泄露平均项:6.动量项的偏差校正:7.泄漏平均项的偏差校正:8.重新缩放渐变:9.更新参数:10.结束;训练得到偏好神经网络的过程如如下表5所示:令:bx={x1,...,xm}:训练数据集中的迷你批(mini-batch);l:层数;m:迷你批(mini-batch)中的样本数;1.foriterator=1,2,3,······,tdo:2.通过相应的yi对训练数据集中包含m个例子的微批(bx)进行抽样,3.forl=1,2,3,......,ldo:4.利用逐层仿射变换:5.6.非线性激活变换的应用7.信号丢弃模块(dropout模块)的应用8.批标准化的应用9.endfor10.得出的损失函数梯度更新偏好神经网络(pnn)11.endfor12.根据预期出的灌水施肥水平返回y'值。s18、模型验证,具体地:模型性能通常用rootmeansquarederror均方根误差(rmse)、meansquarederror均方误差(mse)和平均绝对误差meanabsoluteerror(mae)为标准进行评价。其中,其中,n表示数据对个数,yi、分别表示预测值和实测值,表示实测值的平均值,mse的取值范围是[0,+∞),mse越接近0表示模型的精确度越高。rmse作为mse的开平方,可以在数量级上更加直观的比较出模型精度的高低,其取值范围和精确度评价标准与mse一致。mae取值范围为[0,+∞),mae=0表示模拟值与实测值完全吻合。对于完美适应全部样本的预测模型,应表现为rmse=0、mse=0、mae=0。本申请利用2017年田间实测数据训练和验证偏好神经网络pnn,将生育期内三次灌水和施肥后测定的土壤0-100cm内土壤有机质含量、土壤含盐量、ph值以及土壤总氮含量作为模型输入端,预测灌水量和施氮量,所得到的模拟值与实际设置的灌水施肥水平即实际的灌水量和施氮量比较,最终验证模型性能。模型训练集与测试集采用随机抽样法按4:1建立,并通过adam操作使模型通过多次迭代后稳定且平滑的趋于收敛。本申请采用与偏好神经网络pnn相同的数据集对linearsvr、polysvr、rbfsvr、lr、lor、传统bp神经网络进行训练,通过对比模型间的rmse、mse、mae验证各模型性能,结果如下表3所示:表3根据表6可知:1)本申请的偏好神经网络pnn预测灌水量时的rmse、mse、mae分别为0.012、0.009、0.011,较linearsvr、polysvr、rbfsvr、lr、lor、传统bp神经网络分别高出88.78%-99.18%、89.57%-99.28%、88.81%-99.25%。可见,本申请的偏好神经网络pnn对灌水量的预测精度显著优于其他模型。2)本申请的偏好神经网络pnn预测预测施氮量时,pnn的rmse、mse、mae分别为0.008、0.007、0.007,相对于linearsvr、polysvr、rbfsvr、lr、lor、传统bp神经网络分别高出87.47%-98.76%、92.82%-99.11%、86.99%-96.78%,可见,本申请的偏好神经网络pnn对施氮量的预测精度亦显著优于其他模型。综上,本申请的偏好神经网络pnn基于特定土壤的土壤有机质含量、土壤总氮含量、土壤含盐量、ph值等多维肥力目标预测水氮策略方面具有显著优越性。pnn能够直接通过输入特定肥力目标得出水氮策略,这得益于本申请的偏好神经网络pnn具有的逆向结构。更有利的是,本申请的偏好神经网络pnn的逆向和正向结构可根据实际需求灵活转换,本申请进一步展示了正向pnn模型对不同水氮条件下土壤有机质含量、土壤总氮含量、土壤含盐量、ph值在0-40cm土壤平均值的模拟情况。正向pnn模型分别模拟玉米播种后的17天、59天、87天不同灌水量和施氮量下土壤各指标变化情况,灌水量和施氮量与大田试验设置一致。各指标预测值与实测值拟合关系如图8-图11所示;根据图8-图11所示的结果表明:土壤有机质含量、土壤总氮含量、土壤含盐量、ph值的模拟值与实测值间吻合良好,拟合直线斜率均趋近于1,四指标回归分析的决定系数r2分别为0.8162、0.6401、0.5916和0.4763(p<0.05)。其中,正向pnn对于有机质的预测最为准确,而对于ph值的预测精度较其他指标略逊,产生此种差异可能与四指标在土壤中的稳定性有关。综上,对正向pnn和逆向pnn的双重验证,证明了本申请的偏好神经网络pnn在多目标水肥策略优化方面的优越性和先进性。s19、基于多维肥力目标的优化水氮策略制定,具体地:1)土壤肥力标准:土壤肥力指所有决定作物生产能力的土壤因素(havlinetal.,2005)。作物生长受土壤盐渍化(chavesmmetal,2009)、土壤ph值(rengasamyandpichu,2016)、土壤有机质含量(jianghetal,2018)和总氮(harperla,1987)含量影响剧烈。具体地:①氮素是植物除碳外需求量最大的营养物质,它作为蛋白质、核酸、叶绿素、辅酶、植物激素和次生代谢物的组成部分,在植物代谢中起着核心作用(hawkesfordmetal.,2012)。其缺乏将导致植物生长速度缓慢、植株瘦弱、茎秆细长,叶片小且老叶过早地脱落。缺氮还会使叶绿体分解并抑制其形成,缺氮造成的缺绿症均匀地分布在整个叶片上,缺氮严重可致使叶片坏死。土壤总氮指土壤中各种形态氮素含量之和,包括有机态氮和无机态氮。作为可直观反映土壤中氮素丰缺的指标,土壤总氮可有效评价土壤肥力。②土壤有机质可以释放和固定土壤养分,增加农田生产潜力、土壤持水能力以及土壤氮素对植株生成的有效性,还可改善土壤结构(johnstonae,2007)。因此,土壤有机质被广泛用于田间土壤肥力的评价中。③ph值是氢离子浓度的量度,更准确地说,是氢离子活性的量度。为了维持正常的代谢功能,植物根真皮细胞质的ph值必须维持在7.0至7.5之间。细胞质中h+的浓度高于或低于细胞壁和外部h+的浓度,植株生长均会受到抑制(marschnerh,1991)。碱性土壤上的植物群落与酸性土壤上的明显不同是由于h+和oh-离子浓度对植物新陈代谢的干扰。因此,ph值是评价土壤肥力最有价值的指标之一。④土壤盐渍化是决定作物生产能力的重要因素,含盐量作为表征土壤盐渍化程度的重要指标被广泛应用于土壤肥力的评价体系中。土壤盐分中na+和cl-离子会对植株造成渗透胁迫,且易引起养分失衡最终影响植物的生长发育(sairamrkandtyagiaetal.,2004)。因此,本研究将以土壤有机质含量、土壤总氮含量、土壤含盐量、ph值四指标综合表征不同水氮策略对土壤肥力的影响规律,即通过与土壤肥力关联的四个参量即土壤有机质含量、土壤总氮含量、土壤含盐量、ph值表征不同水氮策略对土壤肥力的影响规律。本申请依据内蒙古河套灌区“3414”测土配方施肥试验成果(见表7)及内蒙古自治区地方标准《db15/t1086—2016耕地地力分等定级技术规范》对土壤有机质含量、土壤总氮含量、土壤含盐量、ph值四项指标进行分等定级。测土配方施肥“3414”试验结果中土壤肥力分级对应的土壤有机质含量、土壤总氮含量及土壤含盐量如表4和表5所示:等级急缺缺中高有机质(g·kg-1)10以下10-2020以上总氮(g·kg-1)<0.410.41-0.870.87-1.60>1.60表4等级非盐化土轻盐化土中盐化土重盐化土盐土浓度(g·kg-1)<22-44-66-10>10表5ph值在《db15/t1086—2016耕地地力分等定级技术规范》对土壤地力的评价体系中按其对土地生产力评价的隶属度分为4个等级,具体如表6所示:等级1234ph值>8.5<6.57.5-8.56.5-7.5表6本申请采用数理统计分析试验区内105个土样实测的含盐量与土壤浸提液电导率ec1:5的数理统计关系,利用spss软件分析,建立土壤电导率(ec)与土壤含盐量线性关系,如图12所示,得到统计公式(r2=0.988):si=2.591ec1:5+0.4682,其中,si为第i层土含盐量(g·kg-1),即盐分质量分数;ec1∶5为土水比为1:5的土壤浸提液电导率(ms/cm)。在此基础上,通过田间试验监测的不同水氮模式下土壤电导率值(ec),得到各土层的土壤含盐量。田间试验开始前,将本研究相关的土壤肥力评价指标进行初始样测定,各土层养分含量如表7所示:深度有机质(g·kg-1)总氮(g·kg-1)全盐量(g·kg-1)ph0-2019.521.041.088.2020-4013.950.860.908.1540-6013.170.681.098.1060-809.720.591.258.1580-10010.570.551.378.04表7可见,试验区各土层初始有机质含量除60cm-80cm表现为缺乏外,其余土层处于中等水平,初始土壤总氮所有土层均处于中等水平。试验区初始盐渍化水平较低,属于非盐渍土,ph值等级为3级。灌水施肥对以上四种肥力指标影响显著,采用优化水氮模式的目的在于:在提升土壤养分含量的同时将施肥和灌水对土壤的负面效应维持在较低水平。即:使土壤有机质和土壤总氮含量达到20g·kg-1和1.6g·kg-1以上,土壤含盐量降低在2g·kg-1以下,同时ph值保持在6.5-7.5之间。2)肥力指标变化下水肥策略模拟:pnn作为具有六维输入向量的深度神经网络,其最终输出的水氮策略综合考虑了灌水和施肥时间即预设时间点、土壤有机质含量、土壤总氮含量、土壤含盐量、ph值等因素,如此多维度的耦合变化机制已超出图像能够展示的能力范围。为便于体现科学规律,特在模型模拟训练过程中将输入模型中6维变量的其中五维设为定值,然后揭示单一肥力指标变化即参量变化所引起的相应水氮策略的变化情况。具体地:灌溉施肥时间定为播种后第17天、59天和87天,与田间试验一致,也就是说,将预设时间点定为播种后第17天、59天和87天;土壤深度取玉米根系层0-40cm均值;限定土壤有机质含量、土壤总氮含量、土壤含盐量和ph值的其中三个为定值即确定目标值,研究剩下的一个参量在不同水平时,模型得出的相应水肥策略。其中,土壤有机质含量的目标值为20g·kg-1、土壤总氮含量的目标值为1.6g·kg-1、土壤含盐量的目标值为2g·kg-1,ph值的目标值为7.5。具体地:①将土壤总氮含量的目标值设置为1.6g·kg-1、将土壤含盐量的目标值设置为2g·kg-1、将ph值的目标值7.5,模拟土壤有机质含量的目标值在5-30g·kg-1范围内对应的水氮策略变化,如图13-图15所示,随着土壤有机质含量的目标值的增加,得到的水氮策略的目标灌水量和目标施氮量总体呈现增加趋势,但这一趋势在全氮达到28g·kg-1时基本停止。这是由于灌溉有助于有机碳积累,降低分解速率,施氮则能够降低有机质流失。土壤有机质含量在20g·kg-1以上时,玉米生育期即分别在苗期、拔节期和灌浆期的三次目标灌水量应分别介于84.36-120.03mm、87.94-110.94mm和90.16-114.67mm,施目标氮量应分别介于95.11-131.57kg·hm-2、86.70-99.27kg·hm-2和71.73-110.13kg·hm-2。施氮量随生育期推进呈下降趋势,这可能由于生育初期土壤中的秸秆分解需较多水分和氮素补充,而生育后期由于秸秆大半已腐化,土壤有机质已相对较高,施肥对该指标的影响逐渐变小。②将土壤有机质含量的目标值设置为20g·kg-1,将土壤含盐量的目标值设置为2g·kg-1、将ph值的目标值设置为7.5,模拟土壤总氮含量的目标值在0.5-2g·kg-1范围内对应的水氮策略的变化,如图16-图18所示,在pnn给出的施氮量和灌水量的范围内,生育期内土壤总氮含量随施氮量和灌水量的增加总体呈增加趋势。不同的是,土壤总氮含量在17d的上限值为1.74g·kg-1左右,继续增加施氮量和灌水量,对其提升作用不再明显,而第59d、第87d时增加施氮量和灌水量,则能将土壤总氮含量增加到2.00g·kg-1左右。这可能由于第17d时作物处在苗期,0-40cm土壤中作物根系层发育不够完全,土壤孔隙率较低,持氮能力较玉米拔节期和乳熟期较差。土壤总氮在1.6g·kg-1以上时,三次目标灌水量应分别介于89.30-97.30mm、86.31-90.76mm、90.78-93.24mm,目标施氮量分别介于93.65-98.89mm、81.38-93.74mm、76.13-79.12kg·hm-2。随生育期推进,灌水量上下限值先减小后增大,施氮量上下限值均逐渐减小。③将土壤有机质含量的目标值设置为20g·kg-1,将土壤总氮含量的目标值设置为1.6g·kg-1,将ph值的目标值设置为7.5,模拟土壤含盐量的目标值在1.0-3.0g·kg-1范围内对应的水氮策略的变化,如图19至图21所示,土壤含盐量变化体现了明显的水氮交互效应。当施氮量处于低水平时,土壤含盐量随灌水量的增加变化不显著或呈现降低趋势,如图20所示,而当施氮量高时,土壤含盐量随灌水量增加而略有升高。这可能由于低施氮量下灌水易将氮肥淋溶至0-40cm之下,作物根层由于过量施肥而增加的盐分含量较小。高施肥水平下较多肥料易积累于表层,造成积盐。土壤含盐量在2g·kg-1以下时,三次目标灌水量应分别介于85.18mm-92.27mm、87.06mm-94.93mm和78.40mm-94.61mm,三次目标施氮量应分别介于86.42-103.68、80.78-86.96和69.71-83.10kg·hm-2。可见,随生育期推进,灌水量上限值均先增大后减小,下限值先增大后略微降低,施氮量上下限值均逐渐减小。④将土壤有机质含量的目标值设置为20g·kg-1,将土壤总氮含量的目标值设置为1.6g·kg-1,将土壤含盐量的目标值设置为2g·kg-1,模拟土壤的ph值的目标值在6.5-8.5g·kg-1范围内对应的水氮策略变化。如图22-图24所示,全生育期0-40cm土壤的ph值的目标值对应的水氮策略。土壤的ph值受水氮交互作用影响显著,17d左右时,土壤发ph值在施氮量较小时,受灌水水平影响较小,而在施氮量较大则呈现先减小后增加趋势,可见高氮低水将使生育初期土壤的ph值显著增加。59d和87d的土壤ph值随灌水量和施氮量的增加,总体呈增长趋势。ph值在59d时增速先慢后快,最终趋于稳定,而在87d先快速增长,后趋于稳定,达到峰值后又略微下降。当土壤的ph值维持在6.5-7.5时,三次目标灌水量应分别介于77.94-90.68、76.41-88.61和81.65-91.71mm,目标施氮量应分别介于89.88-99.32、73.37-86.70、70.50-78.38kg·hm-2。随生育期推进,灌水量上下限值均先降后增。施氮量上下限随生育期推进逐渐下降。3)优化水氮策略制定,具体地:本申请通过水氮交互曲面分别得出了土壤有机质含量、土壤总氮含量、土壤含盐量和ph值达到高肥力标准时的水氮优化范围,将四指标的水氮优化范围取交集,即可得到最优水氮策略。具体地:①如图25所示,在播种后第17天的目标灌水量的范围为:89.30-90.68mm;在播种后第59天的目标灌水量的范围为:87.91mm-88.61mm;在播种后第87天的目标灌水量的范围为:90.78mm-91.70mm;②如图26所示,在播种后第17天的目标施氮量的范围为:95.11-98.89kg·hm-2;在播种后第59天的目标施氮量的范围为:86.69-86.70kg·hm-2;在播种后第87天的目标施氮量的范围为:76.12-78.38kg·hm-2;那么,可将土壤有机质含量保持在20g·kg-1、土壤总氮含量保持在1.2g·kg-1以上、将土壤含盐量在2g·kg-1以下,将ph值介于6.5-7.5,属于高土壤肥力下土壤ph范围。可见,最优的目标灌水量波动小于2mm,最优的目标施氮量波动小于3kg·hm-2,制定的最优水氮策略已较为精确。优化灌水量随生育期推进而基本保持稳定,施氮量则持续减小,这与生产中基肥施用较多而追肥较少的实际情况相吻合。秸秆深埋还田作为盐渍化防控和地力提升的关键手段,近年来倍受关注。一方面,有研究学者对秸秆层本身特性进行了深入研究:zhaoy(2016)等人对于秸秆埋深与土壤水盐分布关系的研究发现,40cm是河套灌区秸秆埋设的最优深度。zhangh(2020)等人对不同秸秆层厚度下盐渍土水盐交换通量变化的研究表明,秸秆埋设深度为5cm时,土壤能获得较好的渗透性,并抑制盐分回流。可见,多数针对秸秆深埋的研究主要针对土壤水盐展开,但秸秆深埋对土壤环境的影响在现实中却是多维的。另一方面,秸秆深埋下水氮交互作用也愈发受到重视。rasoolg(2020)通过设置秸秆-灌水量-施氮量交叉试验,并结合topsis排序分析,揭示了秸秆深埋下水氮耦合对番茄品质和土壤盐分的影响趋势。研究揭示了秸秆深埋、水氮灌施对土壤多个指标的影响趋势,但由于大田工作量限制,该研究灌水和施氮均只设置了两水平,最终未能得出较为准确的水氮优化策略。本研究吸收前人对秸秆埋设深度和厚度的优化成果,在40cm土层处埋设5cm厚度秸秆,开展了三灌水水平、四施肥水平大田交叉试验,并通过pnn模型构建了多维土壤肥力指标与灌水施氮策略的复杂映射关系,最终得出水氮施灌水平的精确范围,弥补了当前在多维目标下精确制定水氮策略的研究空白。2)本申请开发了具有偏好机制的逆向神经网络,即偏好神经网络,并以此为基础建立土壤有机质含量、土壤总氮含量、土壤含盐量、ph值四指标即四个参量与三次灌水量、施氮量的复杂映射关系。拟合结果表明,偏好神经网络pnn的预测性能显著优于linearsvr、polysvr、rbfsvr、lr、lor、传统bp神经网络。本申请的偏好神经网络pnn的出色性能取决于其特殊的网络构造形式。首先,dropout模块可以通过随机悬置非线性模型中的非输出神经元显著降低pnn过拟合风险和运算成本。而batchnormalization使pnn不会对网络中可学参数的细微变化过分敏感,增强模型在训练过程中的稳定性。此外,pnn模型采用的激活函数relu具有“半调整”特点,可有效降低梯度消失风险。最关键的是,pnn具备独一无二的“偏好机制”,可在训练过程中主动学习并通过神经元之间的偏好连接持久化数据之中的先验规律,大幅提高模型收敛性,显著降低模型训练中的错误率和计算成本。pnn相较于其他人工智能模型,除预测精度较优,逆向训练结构也使其能够通过“端对端”方式,直接基于多维肥力目标值得出最优的水氮策略,大幅增强模型应用性和推广性。更重要的是,pnn的逆向和正向结构间可根据实际需求灵活转换,本文进一步展示了正向pnn模型对不同水氮条件下土壤有机质、总氮、含盐量和ph值的模拟过程,并得到了良好的拟合性。对正向和逆向pnn的双重验证,证明了pnn模型在构建水氮策略与土壤肥力间复杂映射关系中的优越性和先进性。pnn正逆向灵活转换的特点,赋予其多重实用功能。具体地:①如果正向pnn能够用来准确量化灌水和施肥等人为因素影响下土壤盐分、有机质等环境因素的变化情况,以准确评估某一生产策略的可行性,那么逆向pnn就能够基于土壤盐分、有机质等环境目标制定精确的人为操作方案,进而指导实际生产。②pnn模型结构现已成型,其经过不同类指标数据集的训练,能够制定出不同领域的优化方案。因此,pnn在功能上不仅限于水氮优化策略的制定,也可制定其他可量化的实施方案,其目标也不局限于维持较高的土壤肥力,更可以是提升作物品质、产量等。③值得一提的是,除土壤有机质含量、土壤总氮含量、土壤含盐量、ph值外,本申请的偏好神经网络pnn的输入向量中还包涵了对灌水、施肥时间以及土层深度的考虑,因此,pnn不仅能基于0-40cm土壤肥力目标制定水氮优化策略,还能够针对不同施灌时间下,不同空间的盐分、ph值、有机质含量和总氮含量进行更为灵活的水氮策略制定。pnn对时间和空间因素的准确把控使其作为核心决策工具应用于精准农业中成为可能。本申请通过2017年秸秆深埋下水氮交叉试验获取的玉米各生育期有机质含量、土壤总氮含量、土壤含盐量、ph值田间实测数据,构建出的逆向的偏好神经网络pnn对水氮施灌策略的模拟性能显著优于linearsvr、polysvr、rbfsvr、lor、lr和传统bp神经网络,而正向pnn对不同水氮策略下土壤有机质、总氮、含盐量和ph值变化的模拟亦具有较高精度。偏好神经网络pnn基于多维肥力目标得出的最优水氮策略为:播种后第17天的目标施氮量的范围为:95.11-98.89kg·hm-2;在播种后第59天的目标施氮量的范围为:86.69-86.70kg·hm-2;在播种后第87天的目标施氮量的范围为:76.12-78.38kg·hm-2;那么,可将土壤有机质含量保持在20g·kg-1、土壤总氮含量保持在1.2g·kg-1以上、将土壤含盐量在2g·kg-1以下,将ph值介于6.5-7.5,,综上所述,本申请的偏好神经网络pnn在基于特定肥力目标制定优化水氮策略方面性能良好。中国农业发展十分依赖化肥投入(wangqbetal.,1996),过量灌水和施氮不仅使作物肥料利用效率偏低,还会造成土壤酸化(miaoyxetal.,2011)、土壤氮素淋失(lujetal.,2019)、有机质含量下降(sunhetal,2018)及次生盐碱化(machadormaandserralheirorp,2017),最终导致土壤肥力低下。研究表明,施氮量每增加10%,氮损失量增加1%(zhangshetal,2020)。秸秆深埋能够缓解氮素流失(yanghetal,2016)和土壤盐碱化(yongganzhaoetal,2016),同时增加土壤碳储量(lufei,2015)。因此,精确制定秸秆深埋条件下优化水氮策略对提高土壤肥力、减少面源污染和盐碱化防治意义重大,但目前在秸秆深埋条件下以土壤肥力为目标综合制定水氮策略的研究较少。水氮优化一直是农田水利领域的研究热点。在过去的二十年里,水氮灌施策略大多只能从有限的田间处理中比较得出(yinf,2007;wangyetal,2019;ningdetal,2019;zhangmmetal,2018)。为降低田间试验成本和提高水氮策略精度,hydrus(karandishfetal,2018;hua,2019)和swap(wuyetal,2017;sonneveldmpwetal,2003)等物理模型应运而生。此类模型可在特定边界条件下模拟不同水氮配施方案对土壤溶质和植株生长的影响,通过增加模拟次数加密水氮设置水平从而提高水氮策略的精度。然而,无论通过田间试验还是物理模型,所提出的优化水氮策略大多基于“处理-指标-处理”的正向研究理念,即先确定水氮措施对土壤指标的影响趋势,而后再利用这种趋势反推较优的水氮措施。此种理念下制定出的水氮策略精度十分依赖田间布置或输入模型的水氮变量的范围和密度,很多研究只是在有限的水氮处理中进行了择优筛选,而那些未被涵盖进试验设计或模型输入范围的水氮组合,其有效性无法得到充分验证。因此,处理-指标-处理思路由于其高昂的试验成本、较低的精度和代表性而不再适于水氮策略的制定。一种能够根据确定目标直接提出水氮优化策略的创新研究思路亟待提出。近年来,人工智能(ai)模型已被成功用于对产量(suyxetal,2017,senthilnathjetal,2016)、土壤水氮(shekoftehhetal,2013)等农田指标的预测中。有研究通过作物图像训练的svm模型成功预测柑橘和咖啡的果实数(ramospjetal,2017;senguptasetal,2014);通过卫星传感器收集的高分辨率数据预测小麦产量(pantazixeetal,2016);通过近红外光谱数据训练svm模型预测土壤总氮、有机碳和水分含量(morellosaetal,2016),或利用多层感知器(mlp)较准确的预测作物et0(sanikhanihetal.,2019)和油菜产量(niedbalag,2019)。除在时间尺度进行预测外,yuhongdong(2019)利用小波-bp神经网络,预测出每种施肥处理下的玉米产量,建立了施肥与产量间的映射关系。guj(2017)等则利用bp神经网络预测了不同灌水量下的作物产量。人工智能与大田试验的结合,为水氮策略的制定提供了新思路,但以上模型多用于产量等指标的预测,很少能够制定出精确的水氮策略。此外,bp神经网络结构简单,无法有效解决由试验数据量有限引发的过拟合问题,而模型泛化能力不足也成为层数较少的神经网络的一大弊端。为此,本文创新性的开发出偏好神经网络(pnn),其逆向训练机制使模型根据由土壤有机质含量、土壤总氮含量、土壤含盐量、ph值直接制定出每次的最优水氮灌施策略,真正实现“端对端”预测机制;pnn的dropout模块使模型能利用有限的田间数据进行随机、多次训练,突破数据量限制,大幅降低过拟合风险;2隐层的网络结构则可极大提升pnn对偏好结构的契合性。传统bp神经网络作为线性全连接模型,所有神经元具有相同的连接数,导致输入向量各维度的变化在信号传播时被同等对待。不得不说,这样的信号传播过程与田间实际变量间的互相影响机制存在较大差距。例如在本研究中,模型输入的土壤总氮、有机质(som)、全盐量、ph四项指标,对灌水和施氮变化的敏感性具有显著差异,如将对水氮施用具有强敏感性的指标与具有弱敏感性的指标同等对待的进行全连接,则模型在信号传播中无法准确识别这两个指标与水氮策略的强弱关系,最终可能导致模型运算成本和出错风险双增。为此,本研究首次提出了偏好值概念用以更好的表征农田水利中不同指标之间依存程度,偏好值是变量间相关性和显著性的集中体现。基于实测数据中各变量间偏好性,本文为pnn独创了神经元连接偏好模块,其能够根据实测数据集处理水平与指标间相关性强弱,令偏好矩阵与权重矩阵进行哈达玛积以先行控制神经元间的连接强度,在大幅优化模型收敛性的同时有效提升预测精度。本文通过2017年在不同水氮措施下采集的土壤有机质含量、土壤总氮含量、土壤含盐量、ph值四项土壤肥力数据即参量训练的pnn模型,构建各指标与水氮配施策略间的复杂映射关系,并通过对正向和逆向pnn的验证,最终证明了基于pnn提出水肥策略的可靠性。进而提出可维持作物根层土壤高肥力的优化水氮策略。本申请的主要贡献如下:1.基于多维目标制定水氮优化策略构建了偏好神经网络(pnn);2.创新性提出适于水氮优化方案的人工神经网络逆向训练方案;3.提出秸秆深埋下基于农田土壤肥力的优化水氮配施策略;4.本文所提出的模型及其训练策略的有效性已被田间试验验证。本申请基于2017年田间实测数据,首次开发出具有逆向训练机制和偏好结构的2隐层深度学习模型--偏好神经网络(preferenceneuralnetwork,pnn)。pnn特有的逆向训练机制使其能够直接基于玉米根区0-40cm土壤肥力多维目标(有机质、总氮、含盐量、ph值)输出生育期内灌水、施氮策略,2隐层结构则能够很好的契合pnn的偏好机制。本文首次提出的偏好值及其计算方式集中体现了变量间的相关性和显著性,以此为基础建立的“偏好机制”可自然地将神经网络结构与数据在自然界中的先验规律相融合,在大幅提高模型收敛性的同时有效提升预测精度。此外,pnn创新性的采用dropout和batchnormalization模块有效降低了出错风险和运算成本,并采用relu函数解决了深度神经网络的梯度消失问题。pnn预测水氮策略的均方误差为0.007-0.009,平均绝对误差为0.007-0.011,均方根误差为0.008-0.012,显著优于同等条件下训练的linearsvr、polysvr、rbfsvr、lor、lr和传统bp神经网络。经pnn模拟得出,播种后17d、59d、87d分别灌水89.30-90.68mm、87.91-88.61mm和90.78-91.70mm,施氮95.11-98.89kg·hm-2、86.69-86.70kg·hm-2、76.12-78.38kg·hm-2可同时将生育期0-40cm土壤有机质、总氮含量分别维持在20g·kg-1、1.6g·kg-1以上,含盐量维持在2g·kg-1以下,ph值介于6.5-7.5之间,满足高土壤肥力指标要求,pnn可实际应用于最优水氮策略的制定。在上述各实施例中,虽然对步骤进行了编号s1、s2等,但只是本申请给出的具体实施例,本领域的技术人员可根据实际情况调整s1、s2等的执行顺序,此也在本发明的保护范围内,可以理解,在一些实施例中,可以包含如上述各实施方式中的部分或全部。如图27所示,本发明实施例的一种获取水氮策略的人工智能系统200,包括第一获取模块210和第二获取模块220;所述第一获取模块210用于获取与土壤肥力关联的每个参量在预设时间点时的目标值;所述第二获取模块220用于将预设时间点和所有目标值输入具有偏好机制的偏好神经网络,得到包括目标灌水量和目标施氮量的水氮策略,其中,所述偏好机制用于表征每个参量分别与灌水量和施氮量之间的关系。首次提出用于表征每个参量分别与灌水量和施氮量之间的关系的偏好机制,由此得到的具有偏好机制的偏好神经网络可自然地将神经网络结构与数据在自然界中的先验规律相融合,在大幅提高模型即偏好神经网络的收敛性的同时,还能有效提升预测精度,得到最优的水氮策略。较优地,在上述技术方案中,还包括搭建模块和训练模块;所述搭建模块用于搭建神经网络;所述训练模块用于:获取每个参量分别与灌水量和施氮量之间的偏好值并进行归一化,得到偏好矩阵,把偏好矩阵引入到神经网络,并结合adam算法,训练得到具有偏好机制的偏好神经网络。较优地,在上述技术方案中,所述搭建模块还用于将relu函数作为神经网络的激活函数,以relu函数作为神经网络的激活函数,解决了神经网络的梯度消失问题。较优地,在上述技术方案中,所述搭建模块还用于:将dropout算法引入神经网络,并将批标准化引入神经网络,将dropout算法和批标准化引入神经网络,有效降低了出错风险和运算成本,提高运算效率。上述关于本发明的一种获取水氮策略的人工智能系统200中的各参数和各个单元模块实现相应功能的步骤,可参考上文中关于一种获取水氮策略的人工智能方法的实施例中的各参数和步骤,在此不做赘述。本发明实施例的一种电子设备,包括存储器、处理器及存储在所述存储器上并在所述处理器上运行的程序,所述处理器执行所述程序时实现上述任一实施的一种获取水氮策略的人工智能方法的步骤。其中,电子设备可以选用电脑、手机等,相对应地,其程序为电脑软件或手机app等,且上述关于本发明的一种电子设备中的各参数和步骤,可参考上文中一种获取水氮策略的人工智能方法的实施例中的各参数和步骤,在此不做赘述。所属
技术领域:
的技术人员知道,本发明可以实现为系统、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:可以是完全的硬件、也可以是完全的软件(包括固件、驻留软件、微代码等),还可以是硬件和软件结合的形式,本文一般称为“电路”、“模块”或“系统”。此外,在一些实施例中,本发明还可以实现为在一个或多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质中包含计算机可读的程序代码。可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是一一但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram),只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1