一种基于产流系数的分布式水文模型空间率定方法与流程
1.本发明涉及水文模拟预报技术领域,尤其涉及一种基于产流系数的分布式水文模型空间率定方法。
背景技术:
2.分布式水文模型可以描述现实流域特征的空间变异性,是探究流域水循环机理、开展业务水文预报的主要工具之一。目前,由于人类尚未完全掌握所有现实流域中的产汇流机理,分布式水文模型多将复杂的水文过程进行概化,形成一些物理参数,这些参数大多和下垫面、地形、土壤特征有关,空间变异性较强,其取值需要通过率定确定。目前,通用的分布式水文模型参数率定方法主要有两大类,即基于实测径流的参数优选和基于相似流域的参数移植。基于实测径流的参数优选是指通过不断迭代调整模型参数,使得流域出口站点的实测径流与模拟径流尽可能吻合。然而,这种方法往往将站点以上流域的各参数设为同一值,无法反映参数的空间变异性,致使参数物理意义被削弱,难以完全精准刻画流域水文过程,且这一问题随着流域尺度的增大而进一步放大。基于相似流域的参数移植主要针对缺径流资料流域开展,即基于机器学习、多元回归等统计方法查找相似流域,将相似流域的参数值移植到缺资料的目标流域中。然而,该方法所得参数的不确定性较大,且仍然无法反映参数的空间变异性,对缺资料地区分布式水文模拟的参考价值有限。
3.在业务预报或水循环模拟中,采用上述两种方法进行参数率定可能导致预报或模拟结果呈现不稳定性,即部分洪水或径流过程模拟效果较好,另一部分洪水或径流过程模拟效果不佳。因此,实际工作中多需要依据前期预报情况动态调整模型参数,从参数层面极大地增加了模型的不确定性和工作量,限制了分布式水文模型在水文模拟和业务预报中的准确性,尤其限制了模型在大尺度及缺资料流域中的应用。
技术实现要素:
4.本发明的目的在于提供一种基于产流系数的分布式水文模型空间率定方法,从而解决现有技术中存在的前述问题。
5.为了实现上述目的,本发明采用的技术方案如下:
6.一种基于产流系数的分布式水文模型空间率定方法,包括如下步骤,
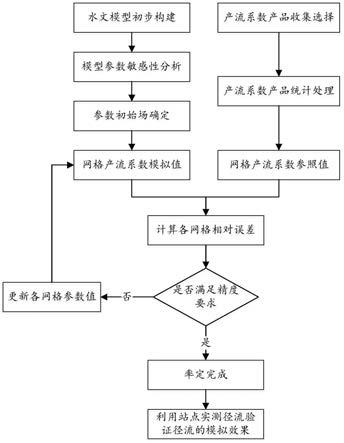
7.s1、初步构建目标流域的分布式水文模型;
8.s2、选择适用于目标流域的产流系数数据产品或数据产品集合;
9.s3、对产流系数产品进行处理,获取分布式水文模型每个网格的产流系数参照值;
10.s4、筛选并初始化分布式水文模型的敏感性参数,构建分布式水文模型的初始参数场;
11.s5、基于所构建的分布式水文模型参数场,利用分布式水文模型开展水文模拟,获取分布式水文模型每个网格的产流系数模拟值;
12.s6、计算分布式水文模型每个网格的产流系数模拟值与分布式水文模型每个网格
的产流系数参照值之间的相对误差;并结合相对误差对分布式水文模型的每个网格的参数在一定范围内进行扰动,形成新的分布式水文模型参数场;
13.s7、重复步骤s5
‑
s6,直到分布式水文模型每个网格的产流系数的模拟效果都达到预定精度,终止率定;利用站点实测径流验证径流的模拟效果。
14.优选的,步骤s1具体为,收集目标流域的基础数据和气象驱动数据,并将数据插值到同一空间分辨率,初步建立目标流域的分布式水文模型;目标流域的基础数据包括目标流域的dem数据、土壤数据和土地利用数据。
15.优选的,步骤s2具体为,收集现有产流系数网格化公开数据,根据数据精度、时空分辨率和覆盖范围选择并下载适用于目标流域的产流系数数据或数据集合。
16.优选的,步骤s3具体为,提取目标流域内的产流系数数据,并利用插值算法将产流系数数据插值到分布式水文模型的网格时空分辨率中,获取分布式水文模型每个网格的产流系数参照值。
17.优选的,当多个产流系数数据满足要求时,采用等权重平均法计算多个产流系数数据在分布式水文模型每个网格上的平均产流系数值,并将该平均产流系数值作为分布式水文模型每个网格的产流系数参照值。
18.优选的,步骤s4具体为,基于文献调研或参数敏感性分析,筛选得到分布式水文模型的敏感性参数,在敏感性参数的取值范围内随机选择初始值赋值给分布式水文模型的所有网格的相应参数,生成分布式水文模型的初始参数场。
19.优选的,步骤s5具体为,基于分布式水文模型每个网格的参数值,利用分布式水文模型开展多年长时段的水文模拟,计算每个网格降水量和产流量的多年平均值,并基于平均值计算获取分布式水文模型每个网格的产流系数模拟值。
20.优选的,步骤s6具体为,将分布式水文模型每个网格的产流系数模拟值与步骤s3中获取的分布式水文模型每个网格的产流系数参照值进行比较,获取两者之间的相对误差;结合相对误差以及敏感性参数的物理意义,对分布式水文模型每个网格的参数在一定范围内进行扰动,形成新的分布式水文模型参数场。
21.本发明的有益效果是:1、本发明方法在一定程度上克服了现有分布式水文模型率定方法无法准确反映物理参数空间变异性和无法在缺少实测径流资料的情况下精准刻画流域水文过程的问题,能够为大尺度及缺资料流域的水文预报和模拟提供准确的参数信息,为分布式水文模型的相关应用提供支撑。2、本发明方法可以在无实测径流资料的情况下开展模型参数率定,可以为缺资料地区的水文模拟提供关键参数信息和参考价值。3、本发明方法可与基于实测径流的参数率定方法叠加使用。在完成产流系数率定后,可利用实测径流从产汇流整体角度进一步率定参数,修正参数率定结果,从空间和站点两个方面提升分布式水文模型模拟效果,为准确的水文预报和模拟提供支撑。4、本发明方法从网格尺度上实现各参数的率定,可以从空间上反映参数的空间分布,加强参数的物理意义,更准确的描述流域水文过程,为准确的水文预报和模拟提供支撑。
附图说明
22.图1是本发明实施例中率定方法的原理流程图;
23.图2是本发明实施例中长江上游dcor率定结果;
24.图3是本发明实施例中长江上游ecor率定结果;
25.图4是基于本发明参数率定方法的寸滩站月径流模拟效果示意图。
具体实施方式
26.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
27.实施例一
28.如图1所示,本实施例中,提供了一种基于产流系数的分布式水文模型空间率定方法,包括如下步骤,
29.s1、初步构建目标流域的分布式水文模型;
30.s2、选择适用于目标流域的产流系数数据产品或数据产品集合;
31.s3、对产流系数产品进行处理,获取分布式水文模型每个网格的产流系数参照值;
32.s4、筛选并初始化分布式水文模型的敏感性参数,构建分布式水文模型的初始参数场;
33.s5、基于所构建的分布式水文模型参数场,利用分布式水文模型开展水文模拟,获取分布式水文模型每个网格的产流系数模拟值;
34.s6、计算分布式水文模型每个网格的产流系数模拟值与分布式水文模型每个网格的产流系数参照值之间的相对误差;并结合相对误差对分布式水文模型的每个网格的参数在一定范围内进行扰动,形成新的分布式水文模型参数场;
35.s7、重复步骤s5
‑
s6,直到分布式水文模型每个网格的产流系数的模拟效果都达到预定精度,终止率定;利用站点实测径流验证径流的模拟效果。
36.本实施例中,本发明提供的率定方法主要包括七个步骤,下面分别针对七个步骤做出详细的解释。
37.一、目标流域分布式水文模型的初步构建
38.该部分内容对应步骤s1,步骤s1具体为,收集目标流域的基础数据和气象驱动数据,并将数据插值到同一空间分辨率,初步建立目标流域的分布式水文模型;目标流域的基础数据包括目标流域的dem数据、土壤数据、土地利用数据等;目标流域的气象驱动数据包括目标流域的降水量数据、气温数据、湿度数据、风速数据、气压数据等;气象驱动数据具体包括的哪些数据需要根据实际情况进行确定;如湿度数据、风速数据、气压数据等,对于某些分布式水文模型并非必需的,因此,应当根据所实际使用的分布式水文模型对降水量数据、气温数据、湿度数据、风速数据、气压数据进行组合选择。
39.二、产流系数数据的收集及选择
40.该部分内容对应步骤s2,步骤s2具体为,收集现有产流系数网格化公开数据,根据数据精度、时空分辨率和覆盖范围等特征,选择并下载适用于目标流域的产流系数数据或数据集合。
41.三、产流系数数据的处理
42.该部分内容对应步骤s3,步骤s3具体为,提取目标流域内的产流系数数据,并利用插值算法将产流系数数据插值到分布式水文模型的网格时空分辨率中,获取分布式水文模
型每个网格的产流系数参照值。
43.本实施例中,当多个产流系数数据满足要求时,采用等权重平均法计算多个产流系数数据在分布式水文模型每个网格上的平均产流系数值,并将该平均产流系数值作为分布式水文模型每个网格的产流系数参照值。
44.四、分布式水文模型敏感性参数筛选及初始化
45.该部分内容对应步骤s4,步骤s4具体为,基于文献调研或参数敏感性分析,筛选得到分布式水文模型的敏感性参数,在敏感性参数的取值范围内随机选择初始值赋值给分布式水文模型的所有网格的相应参数,生成分布式水文模型的初始参数场。
46.五、分布式水文模型网格产流系数模拟
47.该部分内容对应步骤s5,步骤s5具体为,基于分布式水文模型每个网格的参数值,利用分布式水文模型开展多年长时段的水文模拟,计算每个网格降水量和产流量的多年平均值,并基于平均值计算获取分布式水文模型每个网格的产流系数模拟值。
48.可以采用以下公式计算得到各网格产流系数模拟值:
49.rc
s
(i,j)=p(i,j)/(sr(i,j)+gr(i,j))
50.式中,(i,j)代表网格坐标,rc
s
为分布式水文模型各网格的产流系数模拟值,p为各网格多年平均降水量,sr为各网格多年平均地表产流量,gr为各网格多年平均地下地表产流量。
51.六、基于产流系数模拟相对误差的参数迭代
52.该部分内容对应步骤s6,步骤s6具体为,将分布式水文模型每个网格的产流系数模拟值与步骤s3中获取的分布式水文模型每个网格的产流系数参照值进行比较,获取两者之间的相对误差;结合相对误差以及敏感性参数的物理意义,对分布式水文模型每个网格的参数在一定范围内进行扰动,形成新的分布式水文模型参数场。
53.可以采用以下公式计算得到相对误差
54.err(i,j)=(rc
s
(i,j)
‑
rc
r
(i,j))/rc
r
(i,j)
55.式中,(i,j)代表网格坐标,err为相对误差,rc
s
分布式水文模型各网格产流系数模拟值,rc
r
为分布式水文模型各网格产流系数参照值。
56.七、参数率定终止和模拟效果验证
57.该部分对应步骤s7,s7具体为重复步骤s5
‑
s6,直到分布式水文模型每个网格的产流系数的模拟效果都达到预定精度,终止率定;利用站点实测径流验证径流的模拟效果。
58.可以设定分布式水文模型各网格的产流系数模拟值与分布式水文模型各网格产流系数参照值之间的相对误差在
±
10%以下;当分布式水文模型某网格的产流系数模拟值与分布式水文模型相应网格产流系数参照值的相对误差处于在
±
10%范围内时,则终止该网格参数的率定;否则重复步骤s5
‑
s6,直到分布式水文模型所有网格的产流系数模拟值与分布式水文模型相应网格产流系数参照值的相对误差都处于
±
10%范围内时,完成参数率定过程。并可采用站点实测径流验证径流的模拟效果。
59.本实施例中,相比传统集总式及半分布式水文模型,基于物理机制的分布式水文模型可以有效描述现实流域特征的空间变异性,在结构和机理上应当优于集总式及半分布式水文模型。然而,在实际预报及模拟工作中,分布式水文模型的模拟效果并不一定好于集总式及半分布式水文模型。造成这种矛盾的原因多种多样,其潜在的原因之一是传统的模
型参数率定方法与分布式水文模型的分布式结构往往不匹配,即现有的模型参数率定方法无法从空间上确定各物理参数的取值。
60.产流系数是一个地区一段时间产流量和降水量的比值,是流域产流过程的直接反映。在降水量一定的情况下,通过精准模拟产流系数,可以提升产流过程的模拟效果,从而提升流域径流的预报和模拟效果。
61.实施例二
62.本实施例中,结合具体实例详细说明本发明提供的率定方法的具体实施过程。
63.一、长江流域分布式水文模型的初步构建
64.首先从长江流域气象站点及雨量站点获得长江流域1961
‑
2000年的降水量数据,由ncep再分析资料获得气温、风速、湿度、气压数据。利用strm 90m数据集得到长江上游数字高程模型(dem),利用modis数据集获得长江上游土地利用数据,利用hwsd世界土壤数据库获取长江上游土壤数据。利用二次线性插值方法将上述数据插值到10km网格上,构建10km网格的长江上游流域的分布式水文模型clhms。长江上游clhms模型共17824个网格。
65.二、长江流域产流系数数据的收集及选择
66.初步收集美国ncep/ncar的fnl再分析资料产流系数数据(分辨率1
°×1°
,覆盖全球)、全球陆面同化系统gldas的产流系数输出数据(分辨率0.25
°×
0.25
°
,覆盖全球),以及基于第二次水资源评价的中国产流系数公开数据集(https://doi.org/10.5281/zenodo.1403296)提供的产流系数数据。经文献调研和对比分析发现,前两者主要为耦合数据同化的模型模拟结果,不能完全反映长江上游流域真实产流情况,且分辨率较粗,难以适应长江上游流域精细化水文预报及模拟。另一方面,基于第二次水资源评价的中国产流系数公开数据集(分辨率0.1
°×
0.1
°
,覆盖全中国地区)由第二次水资源评价结果生成,采用了全国13600个雨量站和3100个水文站的实测数据,可以反映长江上游流域产流过程的实际空间分布情况,因此选择该数据集作为本实施例产流系数的唯一数据源。
67.三、长江流域产流系数数据的处理
68.利用arcgis的裁剪模块提取长江上游流域范围内的产流系数栅格数据。利用二次线性插值方法将上述产流系数栅格数据插值到步骤一中所构建的分布式水文模型网格格点,得到分布式水文模型每个网格的产流系数参照值。
69.四、长江流域分布式水文模型敏感性参数筛选及初始化
70.采用分布式水文模型clhms。根据文献,clhms具有三个敏感性参数:河道糙率rough、潜热交换系数ecor和直接产流系数dcor,其中rough主要与汇流过程相关,不直接参与产流过程的计算,且在月尺度对径流的影响较小。因此,仅选择参数ecor和dcor作为率定参数,其中ecor的一般取值范围在0.5
‑
6.0之间,dcor的一般取值范围在30
‑
500之间。将长江上游17824个网格的ecor赋值为1.0,dcor赋值为150,形成分布式水文模型参数初始场。
71.五、长江流域分布式水文模型网格产流系数模拟
72.设置运行时段为1961
‑
2000年,利用clhms模拟各网格1961
‑
2000年的降水量和产流量,并在多年尺度上进行平均,得到各网格降水量和产流量的多年平均值。采用以下公式计算得到各网格产流系数模拟值:
73.rc
s
(i,j)=p(i,j)/(sr(i,j)+gr(i,j))
74.式中,(i,j)代表网格坐标,rc
s
为分布式水文模型各网格的产流系数模拟值,p为
各网格多年平均降水量,sr为各网格多年平均地表产流量,gr为各网格多年平均地下地表产流量。
75.六、基于产流系数模拟相对误差的参数迭代
76.设定各网格产流系数模拟值与参照值的相对误差应在
±
10%以下,利用如下公式反复迭代各网格的ecor和dcor的参数值:
77.dcor(i,j)=dcor(i,j)+100*err(i,j)
78.ecor(i,j)=ecor(i,j)*(1+0.2*err(i,j))
79.式中,(i,j)代表网格坐标,err为网格(i,j)产流系数相对误差。
80.七、参数率定终止和模拟效果验证
81.当分布式水文模型某网格的产流系数模拟值与分布式水文模型相应网格的产流系数参照值之间的相对误差在
±
10%范围内时,则停止该网格参数的率定,否则重复步骤
⑤
和
⑥
,直到分布式水文模型所有网格的产流系数模拟值与分布式水文模型相应网格的产流系数参照值之间的相对误差均在
±
10%范围内时,完成参数率定过程。所得参数dcor和ecor的长江上游空间分布如图2和图3所示。
82.选择2001
‑
2010年为一研究时段,将参数初始场模拟得到的寸滩站月径流过程、本发明参数率定值模拟得到的寸滩站月径流过程与寸滩站实测月径流过程进行对比。结果表明,由率定参数模拟得到的寸滩径流的纳什效率系数(nse)为0.90,由初始参数模拟得到的寸滩径流的纳什效率系数(nse)为0.77,如图4所示,模拟效果得到显著提升。
83.通过采用本发明公开的上述技术方案,得到了如下有益的效果:
84.本发明提供了一种基于产流系数的分布式水文模型空间率定方法,本发明方法在一定程度上克服了现有分布式水文模型率定方法无法准确反映物理参数空间变异性和无法在缺少实测径流资料的情况下精准刻画流域水文过程的问题,能够为大尺度及缺资料流域的水文预报和模拟提供准确的参数信息,为分布式水文模型的相关应用提供支撑。本发明方法可以在无实测径流资料的情况下开展模型参数率定,可以为缺资料地区的水文模拟提供关键参数信息和参考价值。本发明方法可与基于实测径流的参数率定方法叠加使用。在完成产流系数率定后,可利用实测径流从产汇流整体角度进一步率定参数,修正参数率定结果,从空间和站点两个方面提升分布式水文模型模拟效果,为准确的水文预报和模拟提供支撑。本发明方法从网格尺度上实现各参数的率定,可以从空间上反映参数的空间分布,加强参数的物理意义,更准确的描述流域水文过程,为准确的水文预报和模拟提供支撑。
85.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1