基于格网索引和球树的倾斜模型和激光点云融合方法与流程
本发明涉及工程测量点云数据处理技术领域,具体涉及一种基于格网索引和球树的倾斜模型和激光点云融合方法。
背景技术:
倾斜摄影测量及三维激光扫描技术是三维空间快速获取信息的重要手段,被广泛应用在地理信息系统、国家基础建设规划等众多领域。通过该技术采集得到的倾斜模型数据和三维激光点云数据是三维地理信息空间重要的数据来源,同时,对倾斜模型和激光点云进行融合,同时对数据的三维坐标与纹理信息进行提取、综合,是后期数据处理及应用的关键步骤,也是当前的研究热点之一。
目前,国内外学者针对空间数据的组织进行了大量的研究工作,其中,广泛应用的组织策略主要有格网索引、四叉树索引、八叉树索引、kd树索引、r树及其变种树索引等。海量点云的空间形态千差万别,数据量巨大,单纯使用一种索引模型往往难以进行高效管理,为了充分发挥不同索引的优势,多数学者将重心放在了两种及以上索引的混合索引模型的研究。
kdtree的优势是可以递增更新,新的观测点可以不断地加入进来。找到新观测点应该在的区域,如果它是空的,就把它添加进去,否则,沿着最长的边分割这个区域来保持接近正方形的性质。这样会破坏树的平衡性,同时让区域不利于找最近邻点,我们可以当树的深度到达一定值时重建这棵树。
然而,kdtree也有问题。矩形并不是用到这里最好的方式。偏斜的数据集会造成我们想要保持树的平衡与保持区域的正方形特性的冲突。另外,矩形甚至是正方形并不是用在这里最完美的几何形状。
为了解决沿着笛卡尔坐标进行划分的低效率,球树(ball-tree)在kdtree的二叉树树形结构上进行了改进,其在一系列嵌套的超球体上分割数据。也就是说:使用超球面而不是超矩形划分区域。虽然ball-tree在多维数据上表现的很高效,但是,在构建数据结构的花费上要大过于kdtree,极大地影响算法效率。
技术实现要素:
本发明的目的是提供一种基于格网索引和球树的倾斜模型和激光点云融合方法,解决使用kdtree组织大数据量点云时存在的问题,包括:第一,由于点云具有多维属性数据,使用kdtree进行查询操作效率较低;第二,由于点云数据量较大,直接构建ball-tree结构将导致树的深度过大,极大地降低了ball-tree的查询效率。
本发明所采用的技术方案为:
基于格网索引和球树的倾斜模型和激光点云融合方法,其特征在于:
所述方法为:
针对整个测区先建立格网索引,然后在每个格网内建立ball-tree结构,各个ball-tree为各自独立的索引结构;
使用ball-tree快速搜索到最邻近的带坐标的倾斜模型节点,并将纹理信息赋值给该点,实现融合。
所述格网索引的建立过程为:
获取倾斜模型数据的二维包围盒,遍历点云数据,使用每个包围盒对点云数据进行裁剪,获取落在该包围盒内的激光点,使模型数据和点云块一一对应。
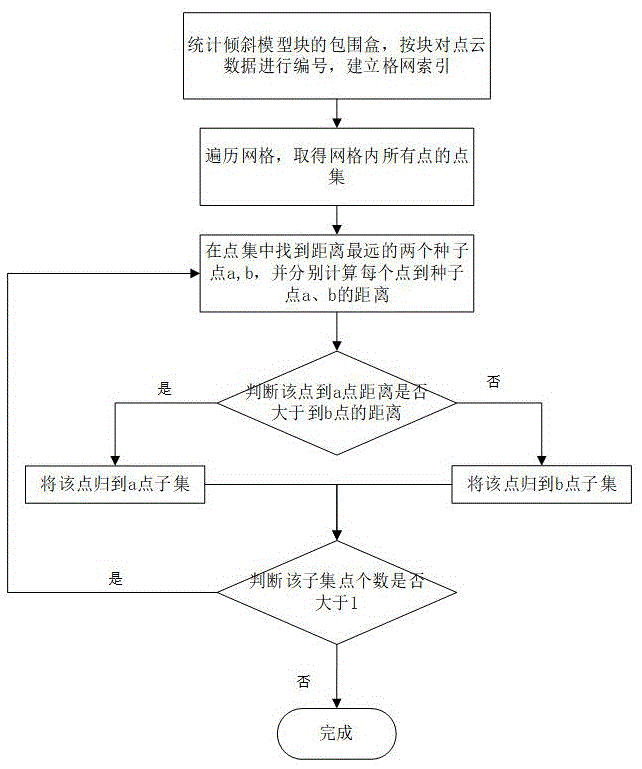
所述ball-tree结构的建立过程为:
(1)遍历每个格网,在其中找到距离最远的两个激光点a和b,以它们为种子点;
(2)遍历其余所有点,对每个激光点s,分别计算其与a和b的距离,离a近就归到a的子簇,对b同理;
(3)分别针对a和b的点簇,计算出覆盖该点簇的最小圆,求得圆心和半径;
(4)以步骤(3)得到的两个圆分别重复步骤(1)至(3),直到只剩一个点,将其作为叶子节点存储下来,至此ball-tree构建完成。
所述使用ball-tree快速搜索的过程为:
遍历模型点坐标,在ball-tree先自上而下找到包含查询点的叶子结点(c,r),从此结点中找到离它最近的父节点,这个距离就是最近邻的距离的上界,检查它的兄弟结点中是否包含比这个上界更小的父节点,如果有,则其为要搜索的目标点。
本发明具有以下优点:
1、本发明构建ball-tree提升了点云索引效率,由于点云数据具有x,y,z,强度,回波等多维属性数据,而且,点云数据具有随机性,其密度分布跟实际地形地物息息相关,不均匀的点云分布将极大地影响kdtree的平衡性,导致其构建和查询效率较低。因此,本发明使用ball-tree代替了传统的kdtree结构,使用球面而不是矩形去划分区域,提高了点云数据查询效率。
2、本发明生成格网索引,并行构建ball-tree,提升了运行效率。本发明先对整个测区建立格网索引,然后在每个格网内建立ball-tree结构,大幅减少ball-tree的深度。此外,由于各个ball-tree为各自独立的索引结构,因此,每个ball-tree的生成和查询都可并行运行,效率得到大幅提升。
附图说明
图1为本发明流程图。
具体实施方式
下面结合具体实施方式对本发明进行详细的说明。
本发明涉及一种基于格网索引和球树的倾斜模型和激光点云融合方法,以提高大范围倾斜模型和激光点云数据进行融合时的效率。所述方法为:
针对整个测区先建立格网索引,然后在每个格网内建立ball-tree结构,各个ball-tree为各自独立的索引结构;
使用ball-tree快速搜索到最邻近的模型点(带坐标的倾斜模型节点),并将纹理信息赋值给该点,实现融合。
所述格网索引的建立过程为:
获取倾斜模型数据的二维包围盒,遍历点云数据,使用每个包围盒对点云数据进行裁剪,获取落在该包围盒内的激光点,使模型数据和点云块一一对应。
所述ball-tree结构的建立过程为:
(1)遍历每个格网,在其中找到距离最远的两个激光点a和b,以它们为种子点;
(2)遍历其余所有点,对每个激光点s,分别计算其与a和b的距离,离a近就归到a的子簇,对b同理;
(3)分别针对a和b的点簇,计算出覆盖该点簇的最小圆,求得圆心和半径;
(4)以步骤(3)得到的两个圆分别重复步骤(1)至(3),直到只剩一个点,将其作为叶子节点存储下来,至此ball-tree构建完成。
所述使用ball-tree快速搜索的过程为:
遍历模型点坐标,在ball-tree先自上而下找到包含查询点的叶子结点(c,r),从此结点中找到离它最近的父节点,这个距离就是最近邻的距离的上界,检查它的兄弟结点中是否包含比这个上界更小的父节点,如果有,则其为要搜索的目标点。
本发明的方法对ball-tree进行改进,先利用格网索引对倾斜模型和激光点云进行划分,再分块构建出ball-tree,提高倾斜模型和激光点云融合的效率,同时,为融合的并行运算提供了强有力的支持。具体优势包括:
1.引进ball-tree代替传统的kdtree提升点云索引效率。
传统的kdtree的二叉树树形结构,沿着笛卡尔坐标进行划分,搜索效率较低。相应的,balltree将在一系列嵌套的超球体上分割数据,其使用超球面而不是超矩形划分区域。虽然在构建数据结构的花费上大过于kdtree,但是在较高维数据上表现的很高效。
由于点云数据具有x,y,z,强度,回波等多维属性数据,kdtree查询效率较低,本发明使用ball-tree代替了传统的kdtree结构,提高了点云数据查询效率。
2.构建格网索引,对数据进行组织划分。
由于测区范围较大,点云点个数达数百亿,直接构建ball-tree结构将导致树的深度过大,极大地降低了ball-tree的查询效率。因此,本发明对整个测区先建立格网索引,然后在每个格网内建立ball-tree结构,大幅减少ball-tree的深度,此外,由于各个ball-tree为各自独立的索引结构,因此,每个ball-tree的生成和查询都可并行运行,效率得到大幅提升。
参见附图,本发明所述的基于格网索引和球树的倾斜模型和激光点云融合方法,涉及点云数据的组织与查询,具体按如下步骤进行操作:
1.首先获取每块倾斜模型数据的二维坐标包围盒,并遍历点云数据,使用每个包围盒对点云数据进行裁剪,获取落在该包围盒内的激光点,并将其编号,使模型数据和点云块一一对应。
2.遍历每个格网,在其中找到距离最远的两个激光点a和b,以它们为种子点。
3.遍历其余所有点,对每个激光点s,分别计算其与a和b的距离,离a近就归到a的子簇,对b同理。
4.分别针对a和b的点簇,计算出覆盖该点簇的最小圆,求得圆心和半径。
5.以第四步得到的两个圆分别重复2-4步,直到只剩一个点,将其作为叶子节点存储下来,至此ball-tree构建完成。
6.遍历模型点坐标,在ball-tree先自上而下找到包含查询点的叶子结点(c,r),从此结点中找到离它最近的父节点。这个距离就是最近邻的距离的上界。检查它的兄弟结点中是否包含比这个上界更小的父节点。如果有,则其为要搜索的目标点,进行属性融合即可。
本发明的内容不限于实施例所列举,本领域普通技术人员通过阅读本发明说明书而对本发明技术方案采取的任何等效的变换,均为本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!