针对多核数据独立任务的启发式调度算法
本发明属于操作系统设计技术领域,具体涉及一种针对多核数据独立任务的启发式调度算法。
背景技术:
处理器的技术发展从频率的提升转向核心数目的提升是一个大的趋势。而随着分布式计算和云计算的发展,多核已经广泛地应用到了多用户操作系统的服务器集群上。许多用户在同一时刻共享着一台服务器,它们所提交的任务通常也是数据相互之间独立的。但是,传统的针对多核的任务调度算法通常认为任务之间是相互依赖的。
比如,颜色敏感的任务划分算法用来分配处理器之间共享的颜色。动态颜色敏感调度器在运行时检测缓存一致性来减少缓存一致性协议所引发的争抢现象。在减少缓存争抢之后,应用的执行时间得以最小化。尽管这些算法都在任务相互依赖时取得了不错的表现,但是因为他们太关注数据依赖而忽视了任务和处理器核心的特性,所以他们在数据独立的场景下性能较差。这里有两个经典的数据独立算法,先来先服务算法(fcfs)和min-min算法。在fcfs中,先来的任务会优先分给空闲的主机,而在min-min中,它会优先分配执行时间最少的任务给主机以达到任务之间相互竞争时间最少的目的。因此,这类算法考虑到了数据独立条件下任务和核心的特性从而提升了运行效率,负载均衡。
既然任务之间的相互依赖不在考虑的范围内,那么多核任务调度问题即为非确定性多项式竞争问题(np-c),对于此类问题,基因算法,粒子群算法等启发式算法非常适合。正因如此,我们提出了一个启发式算法(hitsm),它非常适合在数据独立的任务下进行多核心的任务调度。hitsm算法通过迭代的办法找到调度方案使得运行效率和负载均衡有了很大的提高。
技术实现要素:
本发明以数据独立性为前提结合启发式算法设计了一套新的调度算法,使得在数据相互独立的情况下,运行效率和负载均衡有了很大的提高。
本发明提供的技术方案如下:
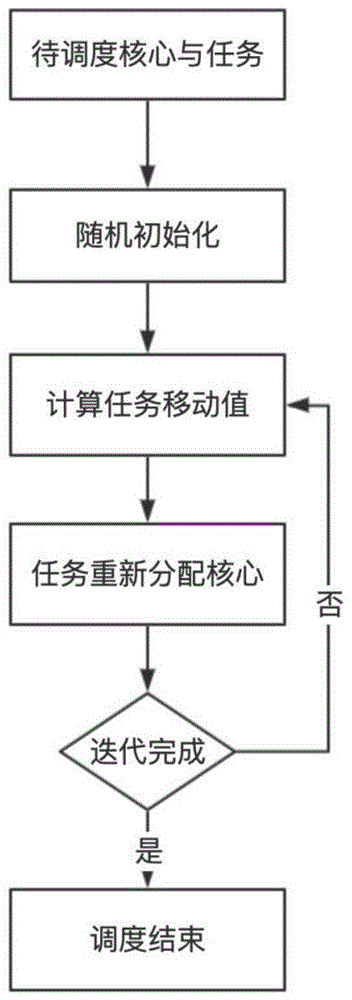
一种针对多核数据独立任务的启发式调度算法,具体步骤如下:
步骤1、获得服务器主机cpu核心(聚集地)列表cl和用户所提交的任务(点)列表tl;
步骤2、待全部的任务提交完毕后,将所有任务随机分配给主机核心;
步骤3、首先设置迭代次数的最大值,然后开始迭代过程,每次迭代需判断迭代次数是否达到迭代次数的最大值,若达到,则停止迭代,任务完成。否则,跳转到步骤4继续执行。
步骤4、判断任务列表中的所有任务是否移动,若是,则转到步骤3;否则,起始点切换到第一个未移动的点并跳转到步骤5;
步骤5、计算tl中移动到其他核心的有效值
其中,
之后,对每一个有效值进行过滤;如果有效值大于或等于1,则不变,否则有0.1%的概率保持不变以防止陷入局部最优解,如果有效值不能保持不变,则置为0;
步骤6、步骤5所获得的有效值
偏置从0开始依次加上有效值除以其总和的结果,而轮转的间隔为每次相加后所得的新值与加之前的值所组成;生成0到1之间的一个随机数,其落到哪个间隔,则会移动到此处。然后跳转到步骤4。
本发明中,核心为cpu核,核心列表为所在服务器的所有cpu核所组成的列表。所述任务为用户提交给服务器所待完成的任务。
本发明中,随机初始化的过程是为每一个任务随机化选择一个核心。
本发明中,所述算法的迭代次数最大值为经验值,需按情况调整。
本发明中,所述任务的移动是指任务从一个核心转移到另一个核心上。
本发明提供的针对多核数据独立任务的启发式调度算法,充分利用了当前多用户操作系统所广泛存在的数据相互独立性,使得执行效率、负载均衡有了很大的提高。
附图说明
图1本发明的算法流程框架。
具体实施方式
本发明中,提出针对多核数据独立任务的启发式调度算法,整个算法的流程如图1所示,该算法的工作过程如下。
1、使用主机操作系统所提供的api设计脚本以获得服务器主机cpu核心信息,并设置id区别不同核心并用链表将核心进行管理起来形成核心列表cl。同样地,用户所提交的任务也通过设置id号并用链表将任务管理起来形成列表tl。
2、开始时,等待任务提交,当任务提交完毕后,发送信号给算法开始调度过程并停止任务的提交。之后,对于每一个任务,使用随机数来随机选择核心。
3、首先设置迭代次数的最大值,之后开始迭代过程,每次迭代需判断迭代次数是否达到迭代次数的最大值,若达到,则停止迭代,任务完成。否则,跳转到步骤4继续执行。
4、任务列表中每个任务设置移动标志位,每次迭代完成后使用此遍历整个任务列表来判断任务列表中的所有任务是否移动,若是,则转到步骤3。否则,跳转到步骤5。
5、计算tl中移动到其他核心的有效值
之后,对每一个有效值进行过滤。如果有效值大于或等于1,则不变,否则其只有0.1%的概率保持不变以防止获得局部最优解,如果有效值不能保持不变,则置为0。
6、步骤5所获得的有效值
、算法具体实例。首先,使用python构建多核仿真环境并在此实现本算法。具体配置为cpu:inteli7-4790,memory:16g。并进行了1000次重复测试。在测试中,十个核心的运算力相对于标准核心分别为(2,0.8,0.4,0.8,1.1,0.9,1.2,0.8,0.4,1.6)。并且在标准核心上,100个任务的竞争时间从0.1s到100s随机选择。此外,本算法还提出负载均衡因子(lbf)来衡量负载均衡性能。具体公式为
其中,nc表示核的数目,
参考文献
[1]fengyanandludmilacherkasova,“dyscale:amapreducejobschedulerforheterogeneousmulticoreprocessors”,ieeetransactionsoncloudcomputing,p.317-330(2017).
[2]giovanigracioliandantônioaugustofröhlich,“two-phasecolour-awaremulticorereal-timescheduler”,ietcomputers&digitaltechniques,p.133-139(2017).
[3]julianazamithandthiagosilva,“ontheevaluationofcontention-awarelistschedulersonmulticorecluster”,internationalsymposiumoncomputerarchitectureandhighperformancecomputingworkshop(sbac-padw),p.61-67(2015).
[4]sudhakarsahandvinayg.vaidya,“dependencyawareaheadoftimestaticschedulerformulticore”,ieeeinternationalconferenceoncomputerandinformationscience(icis),p.337-342(2014).
[5]teenamathewandk.chandrasekaran,“studyandanalysisofvarioustaskschedulingalgorithmsinthecloudcomputingenvironment”,internationalconferenceonadvancesincomputing,communicationsandinformatics,p.658-664,(2014).
[6]h.a.makasarwalaandp.hazari,“usinggeneticalgorithmforloadbalancingincloudcomputing”,electronics,computersandartificialintelligence,p.49-54,(2016).
[7]shubhamandrishabhgupta,“aneffectivemulti-objectiveworkflowschedulingincloudcomputing:apsobasedapproach”,internationalconferenceoncontemporarycomputing,(2016)。
- 还没有人留言评论。精彩留言会获得点赞!