一种内容标注方法和相关装置与流程
本申请涉及数据处理领域,特别是涉及一种内容标注方法和相关装置。
背景技术:
对互联网中产生的内容进行标注可以实现对内容的有效识别、分类,通过对内容标注的标签,后续可以作为标注集使用在大量的内容应用场景中,例如基于内容的标签向用户有针对性的内容推荐场景。
对未标注的内容进行标注的效率和准确度直接影响了对内容的后续使用,相关技术中主要采用人工标注或基于规则标注两种方式。
人工标注的标签虽然准确率尚可,但是非常依赖经验且效率低下,基于规则标注的方式难以适用于日新月异的各类内容,准确率无法保证。
技术实现要素:
为了解决上述技术问题,本申请提供了一种内容标注方法和相关装置,用于提高对未标注的内容进行标注的效率和准确度
本申请实施例公开了如下技术方案:
一方面,本申请提供一种内容标注方法,所述方法包括:
获取待处理内容集合,所述待处理内容集合中的内容具有通过弱监督训练的模型所标注的待定标签;
根据所述待定标签的标签置信度,从所述待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,和标签置信度不满足所述第一阈值的第二目标内容;
将所述第一目标内容作为训练样本训练得到分类模型;
通过所述分类模型对第二目标内容进行标注,得到所述第二目标内容的候选标签;
根据所述第二目标内容的待定标签和候选标签,确定所述第二目标内容的实际标签。
另一方面,本申请提供一种内容标注装置,所述装置包括:获取单元、训练单元、标注单元和确定单元;
所述获取单元,用于获取待处理内容集合,所述待处理内容集合中的内容具有通过弱监督训练的模型所标注的待定标签;
所述获取单元,还用于根据所述待定标签的标签置信度,从所述待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,和标签置信度不满足所述第一阈值的第二目标内容;
所述训练单元,用于将所述第一目标内容作为训练样本训练得到分类模型;
所述标注单元,用于通过所述分类模型对第二目标内容进行标注,得到所述第二目标内容的候选标签;
所述确定单元,用于根据所述第二目标内容的待定标签和候选标签,确定所述第二目标内容的实际标签。
另一方面,本申请提供一种计算机设备,所述设备包括处理器以及存储器:
所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
所述处理器用于根据所述程序代码中的指令执行上述方面所述的方法。
另一方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行上述方面所述的方法。
另一方面,本申请实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面所述的方法。
由上述技术方案可以看出,虽然通过弱监督训练的模型可以快速对内容标注标签,但是准确性难以保证,会直接影响内容的后续使用。为此,针对基于上述方式打标得到的待处理内容集合,根据内容的待定标签的标签置信度将待处理内容集合中的内容分为满足第一阈值的第一目标内容,和不满足第一阈值的第二目标内容,由于第一目标内容的待定标签的准确性高于第二目标内容,将第一目标内容作为训练样本训练得到的分类模型的可信度较高,通过该分类模型可以对第二目标内容进行标注,得到第二目标内容的候选标签,由于分类模型所具备的可信度较高,故可以将候选标签和待定标签均作为判断第二目标内容的实际标签的依据,以此确定第二目标内容的实际标签。由此,确定出的第二目标内容的实际标签更为准确,而且分类模型是根据待处理内容集合中标签置信度较高的第一目标内容进行训练的,可以适应不断变化的待处理内容集合中的内容,提高了对待处理内容集合中的内容进行标注的准确性。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种内容标注方法的应用场景示意图;
图2为本申请实施例提供的一种内容标注方法的流程图;
图3为本申请实施例提供的一种snorkel框架的示意图;
图4为本申请实施例提供的一种通过弱监督训练的模型标注标签的示意图;
图5为本申请实施例提供的一种内容标注方法的应用场景示意图;
图6为本申请实施例提供的一种内容标注装置的结构示意图;
图7为本申请实施例提供的服务器的结构示意图;
图8为本申请实施例提供的终端设备的结构示意图。
具体实施方式
下面结合附图,对本申请的实施例进行描述。
相关技术中,对未标注的内容进行标注主要采用人工标注与基于规则标注两种方式,其中,采用人工标注的方式会使人力与时间成本较高,不适用于业务迭代周期快的应用场景。采用基于规则标注的方式对未标注的内容的准确率较低,使用准确率低的标注的内容构建模型效果较差,而且也不适用于业务迭代周期快的应用场景。
基于此,本申请提供一种内容标注方法和相关装置,用于提高对未标注的内容进行标注的效率和准确度。
本申请实施例提供的内容推荐方法是基于人工智能实现的,人工智能(artificialintelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
在本申请实施例中,主要涉及的人工智能技术包括上述机器学习/深度学习等方向。
本申请提供的内容标注方法可以应用于具有数据处理能力的内容标注设备,如终端设备、服务器。其中,终端设备具体可以为智能手机、台式计算机、笔记本电脑、平板电脑、智能音箱、智能手表等,但并不局限于此;服务器可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云计算服务的云服务器。终端设备以及服务器可以通过有线或无线通信方式进行直接或间接地连接,本申请在此不做限制。
该内容标注设备可以具备机器学习能力。机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络等技术。
在本申请实施例提供的内容标注方法中,采用的人工智能模型主要涉及对机器学习的应用,通过机器学习提高待定标签的准确性。
本申请实施例提供的内容标注设备还具备云计算能力,利用云计算能力对待处理内容集合中的内容进行大数据处理,确定待处理内容集合中的内容的实际标签。
其中,大数据(bigdata)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。随着云时代的来临,大数据也吸引了越来越多的关注,大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。适用于大数据的技术,包括大规模并行处理数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。
本申请实施例提供的内容标注方法,对待处理内容集合中的内容进行标注,其中,待处理内容集合中的内容、标注了实际标签的内容等数据均可保存于区块链上。
为了便于理解本申请的技术方案,下面结合实际应用场景,以服务器作为内容标注设备对本申请实施例提供的内容标注方法进行介绍。
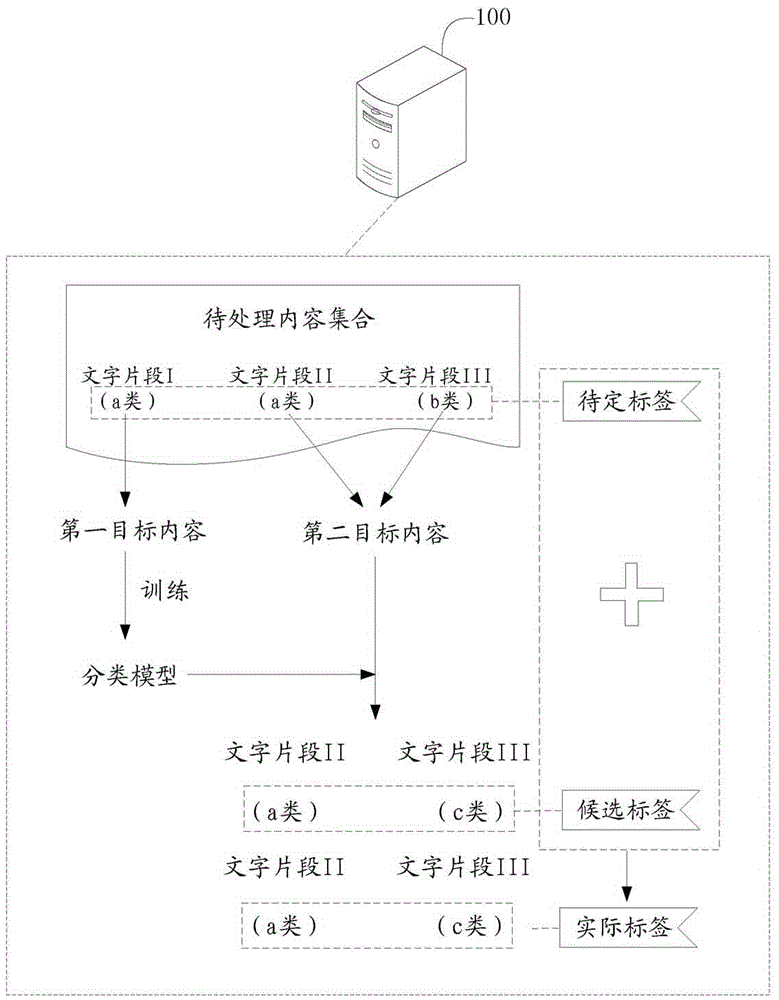
参见图1,图1为本申请实施例提供的一种内容标注方法的应用场景示意图。在图1所示的应用场景中,包括服务器100,用于确定待处理内容集合中的内容的实际标签。
在图1所示的应用场景中,服务器100获取待处理内容集合包括三个文字片段及其分别对应的待定标签,分别为文字片段i、对应的待定标签为a类,文字片段ii、对应的待定标签为a类,以及文字片段iii、对应的待定标签为b类。其中,三个文字片段分别对应的待定标签均是通过弱监督训练的模型进行标注的。
虽然通过弱监督训练的模型可以对待处理内容集合中的内容进行快速的标注,但是通过该种标注方式获得的标签准确性较低,会直接影响内容的后续使用。为此,服务器100根据待定标签的标签置信度,将待处理内容集合中的内容分为满足第一阈值的第一目标内容,和不满足第一阈值的第二目标内容。在图1所示的应用场景中,第一目标内容包括文字片段i,第二目标内容包括文字片段ii和文字片段iii。
由于第一目标内容的待定标签的准确性高于第二目标内容,故将第一目标内容作为训练样本训练得到分类模型,该分类模型的可信度较高,可以通过该分类模型对准确性较低的第二目标内容再次进行标注,得到第二目标内容的候选标签。在图1所示的应用场景中,文字片段ii的候选标签为a类,文字片段iii的候选标签为c类。
由于分类模型所具备的可信度较高,根据分类模型获得的候选标签的准确性具有参考价值,故可以将候选标签和待定标签均作为判断第二目标内容的实际标签的依据,获得第二目标内容的实际标签。例如,在图1所示的应用场景中,文字片段ii的待定标签与候选标签相同,则文字片段ii的实际标签可以为a类;文字片段iii的待定标签与候选标签不同,但是文字片段iii的候选标签的标签置信度较高,则文字片段iii的实际标签可以为c类。
由此,以第二目标内容的待定标签和候选标签为依据,确定出的第二目标内容的实际标签更为准确,而且分类模型是根据待处理内容集合中标签置信度较高的第一目标内容进行训练的,该分类模型可以适应不断变化的待处理内容集合中的内容,提高了对待处理内容集合中的内容进行标注的准确性。
下面结合附图,以服务器作为内容标注设备,对本申请实施例提供的一种内容标注方法进行介绍。
参见图2,图2为本申请实施例提供的一种内容标注方法的流程图。如图2所示,该内容标注方法包括以下步骤:
s201:获取待处理内容集合。
待处理内容集合中包括至少一个内容,内容为创作者展现给用户的信息或者经验,可以为新闻、视频、文章等。待处理集合中的每一个内容均具有待定标签,若内容为新闻,该新闻对应的待定标签可以为娱乐新闻、科技新闻、数码新闻等。该待定标签是通过弱监督训练的模型所标注的,即该弱监督训练的模型是通过弱监督学习的方式训练获得的。
弱监督学习是机器学习领域中的一个分支,与传统的监督学习相比,其使用有限的、含有噪声的或者标注不准确的数据来进行模型参数的训练。弱监督学习旨在研究通过较弱的监督信号来构建预测模型,通俗来讲就是通过在少量的标注样本上学习建模,达到大量样本上同样的效果。弱监督学习可以分为不确切监督(inexactsupervision)、不准确监督(inaccuratesupervision)与不完全监督(incompletesupervision)三类,当遇到不准确监督和不完全监督的问题,其对应的标签不准确或数量较少,均会影响内容的后续使用。其中,不确切监督指的是标签不确切,粗粒度标签只到大类,没有到具体的小类。不准确监督指的是人工标注的时候存在结果矛盾的标签,使得标签不准确,有噪声。不完全监督指的是标签少,标签不全等。
本申请实施例不具体限定通过弱监督训练的模型,例如,该模型可以为snorkel框架(一种弱监督系统),snorkel框架能解决不准确监督与不完全监督这两类问题。其中,snorkel框架是一种快速产出训练数据的弱监督系统,利用标签函数,可以快速产生,管理,建模训练数据。同时,snorkel框架是一套专门基于弱监督创建训练数据的框架,它能基于内部模型、本体、规则知识图谱等各种形式的知识为机器学习模型创建大规模的数据。与传统手工标注不同,snorkel框架创造出为数据打标的标注函数,程序化地完成数据标记工作。研究人员主要探索了这些标注函数是如何捕获工程师的经验,如何基于现有资源启发式的进行弱监督学习的。
后续会基于snorkel框架对待处理内容集合中的内容标注待定标签进行说明,参见s2011-s2013,在此不再赘述。
为了使得内容在后续可以进行原子能力建设,待处理内容集合中的内容所需的待定标签,可以用于标识待处理内容集合中内容在最小划分粒度下的内容类别。
其中,原子能力建设主要是为了细化与深入理解优质内容,同时拆分细粒度的优质原子特征能力,以便于推荐更好地使用内容理解侧细粒度的原子能力特征。
粒度就是同一维度下,数据统计的粗细程度,细化程度越高,粒度级就越小;相反,细化程度越低,粒度级就越大。最小划分粒度为待处理内容集合中内容对应的标签体系中,将内容标签细化至最小的内容类别对应的标签。例如,资讯类应用中的资讯内容可以划分为不同的频道,如视频频道、娱乐频道、新闻频道等,新闻频道还可以继续划分至娱乐新闻、科技新闻、数码新闻等不同内容类别,则将资讯内容划分至新闻频道标签不是基于最小划分粒度划分的,将其划分至娱乐新闻标签等标签才是基于最小划分粒度划分的。通过将待处理内容集合中内容的标签细化至最小划分粒度可以获得多样性的标签,从而使得优质原子特征能力。
s202:根据待定标签的标签置信度,从待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,和标签置信度不满足第一阈值的第二目标内容。
虽然通过弱监督训练的模型可以对待处理内容集合中的内容进行快速的标注,但是通过该种标注方式获得的标签准确性较低,会直接影响内容的后续使用。
为了不影响内容的后续使用,可以提高待定标签的准确性。基于待定标签的标签置信度,将待处理内容集合中的内容分为两类:标签置信度满足第一阈值的第一目标内容和标签置信度不满足第一阈值的第二目标内容。本申请实施例不具体限定第一阈值的数值和满足条件,例如,将待处理内容集合中标签置信度大于90%的内容作为第一目标内容,将标签置信度小于或等于90%的内容作为第二目标内容。
相比于第二目标内容的待定标签,第一目标内容的待定标签的标签置信度更高,第一目标内容的待定标签的可信度更高。由此,基于第一目标内容作为训练样本训练得到的分类模型的准确率较高,降低了对内容后续使用的影响。
其中,待定标签的标签置信度标识待定标签的可信程度,在通过弱监督训练的模型获得待定标签的同时,会获得该待定标签的标签置信度。例如,将未标注待定标签的新闻文本输入至弱监督训练的模型中,该模型识别该新闻文本为娱乐新闻的概率为70%、为科技新闻的概率为20%、为数码新闻的概率为10%,故此该模型会输出该新闻文本的待定标签为娱乐新闻,对应的标签置信度为70%。
s203:将第一目标内容作为训练样本训练得到分类模型。
第一目标内容较为准确,即高准确种子样本,将其作为训练样本,输入至分类模型中,经过训练获得分类模型。本申请实施例不具体限定训练的方式,例如,将第一目标内容文本输入至初始分类模型中,初始分类模型会输出第一目标内容文本对应的标签结果,根据第一目标内容的标签结果和待定标签的差异,对初始分类模型进行参数调整,从而获得分类模型。
本申请实施例不具体限定分类模型,例如,分类模型可以为fasttext分类模型(一个词向量计算和文本分类工具)、卷积神经网络(convolutionalneuralnetwork,cnn)等。
需要说明的是,第一目标内容是待处理内容集合的一部分,将第一目标内容作为训练样本训练得到分类模型,适用于对待处理内容集合中的内容进行标注。针对于业务迭代周期快的应用场景,相比于采用基于规则标注的方式,将第一目标内容作为训练样本训练得到的分类模型,更能适应不断变化的待处理内容集合中的内容,提高了对待处理内容集合中的内容进行标注的准确性。
s204:通过分类模型对第二目标内容进行标注,得到第二目标内容的候选标签。
相比于使用可信度较低的第二目标内容作为训练样本,或者混合第二目标内容和第一目标内容作为训练样本,仅基于第一目标内容作为训练样本训练得到的分类模型的可信度更高。从而基于该分类模型对标签置信度较低的第二目标内容再次进行标注,得到第二目标内容的候选标签。
其中,候选标签与待定标签是针对第二目标内容同一个分类需求的标签。例如,当第二目标内容为新闻文本时,针对新闻类型进行分类的时候,待定标签与候选标签可以为娱乐新闻、科技新闻、数码新闻等。
由此,候选标签可以作为评判待定标签是否准确的依据,例如,若候选标签与待定标签相同,则待定标签的可信度较高,若候选标签与待定标签不相同,则待定标签的可信度较低等。
s205:根据第二目标内容的待定标签和候选标签,确定第二目标内容的实际标签。
候选标签与待定标签均是针对第二目标内容同一分类需求确定的标签,在候选标签作为评判待定标签是否准确的依据的同时,待定标签也可以作为评判候选标签是否准确的依据,由此,待定标签与候选标签相互印证,二者可以作为确定第二目标内容的实际标签的依据,共同确定第二目标内容的实际标签,从而提高第二目标内容的实际标签的准确性。相比于相关技术中仅根据待定标签确定第二目标内容的实际标签,根据待定标签和候选标签共同确定出的第二目标内容的实际标签更为准确。
由上述技术方案可以看出,虽然通过弱监督训练的模型可以快速对内容标注标签,但是准确性难以保证,会直接影响内容的后续使用。为此,针对基于上述方式打标得到的待处理内容集合,根据内容的待定标签的标签置信度将待处理内容集合中的内容分为满足第一阈值的第一目标内容,和不满足第一阈值的第二目标内容,由于第一目标内容的待定标签的准确性高于第二目标内容,将第一目标内容作为训练样本训练得到的分类模型的可信度较高,通过该分类模型可以对第二目标内容进行标注,得到第二目标内容的候选标签,由于分类模型所具备的可信度较高,故可以将候选标签和待定标签均作为判断第二目标内容的实际标签的依据,以此确定第二目标内容的实际标签。由此,确定出的第二目标内容的实际标签更为准确,而且分类模型是根据待处理内容集合中标签置信度较高的第一目标内容进行训练的,可以适应不断变化的待处理内容集合中的内容,提高了对待处理内容集合中的内容进行标注的准确性。
本申请实施例不具体限定根据候选标签和待定标签共同确定第二目标内容的实际标签的方式,下面以三种方式为例进行说明。
方式一:
确定第二目标内容的待定标签和候选标签的一致性,即确定第二目标内容的待定标签和候选标签是否一致,响应于确定第二目标内容的待定标签和候选标签一致,即若一致,则说明第二目标内容的待定标签和候选标签可信程度较高,可以将第二目标内容的候选标签作为第二目标内容的实际标签。由于第二目标内容的待定标签和候选标签相同,故此还可以将第二目标内容的待定标签作为第二目标内容的实际标签。
响应于确定第二目标内容的待定标签和候选标签不一致,即若不一致,说明第二目标内容的待定标签的可信程度较低,不能直接将第二目标内容的待定标签作为第二目标内容的实际标签。本申请实施例不具体限定该种情况下第二目标内容的实际标签的确定方式,例如,由于第二目标内容的候选标签是根据可信程度较高的分类模型获得的,故可以将第二目标内容的候选标签直接作为第二目标内容的实际标签。又如,还可以根据后续方式三确定第二目标内容的实际标签,在此不再赘述。
方式二:
确定第二目标内容的候选标签的标签置信度,响应于确定第二目标内容的候选标签的标签置信度满足第二阈值,即若确定第二目标内容的候选标签的标签置信度满足第二阈值,则说明通过分类模型获得的第二目标内容的候选标签的可信程度较高,可以将其作为确定第二目标内容的实际标签的依据,通过前述方式一的方式确定第二目标内容的实际标签。
响应于确定第二目标内容的候选标签的标签置信度不满足第二阈值,即若确定第二目标内容的候选标签的标签置信度不满足第二阈值,则说明通过分类模型获得的第二目标内容的候选标签的可信程度较低,不能将其作为确定第二目标内容的实际标签的依据,可以将其删除,不用做内容的后续使用,又或者,可以通过人工标注的方式对第二目标内容进行标注。
通过确定第二目标内容的候选标签的标签置信度是否满足第二阈值,从而仅选择标签置信度满足第二阈值的候选标签对应的第二目标内容,使得作为确定第二目标内容的实际标签的依据更为可信,从而提高第二目标内容的实际标签的准确性。
本申请实施例不具体限定第二阈值的数值,例如,可以将第二阈值设置为0.9,还可以设置为85%。
方式三:
在经过多次迭代训练后,分类模型的准确度将趋于可信,故根据分类模型获得的候选标签也趋于可信。即在确定第二目标内容的待定标签和候选标签的一致性之后,响应于确定第二目标内容的待定标签和候选标签不一致,即若第二目标内容的候选标签与待定标签不一致时,确定第二目标内容的候选标签的标签置信度,若响应于确定第二目标内容的候选标签的标签置信度满足第三阈值,说明第二目标内容的候选标签可信度较高,可以将第二目标内容的候选标签直接作为第二目标内容的实际标签。
需要说明的是,第三阈值可以与第一阈值或者与第二阈值相等,也可以不相等,本申请实施例不具体限定第三阈值的数值。
为了进一步提高实际标签的准确性,还可以通过多次迭代训练分类模型,提高分类模型的准确性。本申请实施例不具体限定迭代训练分类模型的方式,下面以两种方式为例进行说明。
第一种方式:
将通过s205确定了实际标签的第二目标内容作为训练样本对分类模型进行迭代训练;通过迭代训练后的分类模型对未确定实际标签的第二目标内容重新标注候选标签,并执行s205。
以待处理内容集合中包括100个内容为例,其中,80个内容为第二目标内容,20个内容为第一目标内容。通过20个第一目标内容作为训练样本训练得到分类模型,通过该分类模型确定了第二目标内容中50个内容确定了实际标签,30个内容未确定实际标签。将该50个确定了实际标签的第二目标内容作为训练样本对分类模型进行训练,获得迭代训练后的分类模型,通过迭代训练后的分类模型对30个未确定实际标签的第二目标内容重新标注候选标签,执行s205。
本申请实施例不具体限定迭代训练的次数,例如,直至将第二目标内容全确定实际标签为止。又如,设置固定的迭代训练次数,直至达到迭代训练次数为止,结束迭代训练。
第二种方式:
在每一次获取的待处理内容集合后,从每一次获取的待处理内容集合的内容中,获取标签置信度满足第一阈值的内容,作为该待处理内容集合中的第一目标内容,并根据每一次获取的第一目标内容作为训练样本迭代训练分类模型。
迭代训练的方式为:针对第1次获取的待处理内容集合,根据s203的方式获得分类模型后,第2次获取待处理内容集合,从第2次获取的待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,并作为训练样本,再次训练根据第1次训练获得的分类模型,获得训练完成后的分类模型。同理,第n次获取待处理内容集合后,从第n次获取的待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,并作为训练样本,继续训练根据第n-1次训练获得的分类模型,获得训练完成后的分类模型。由此,在经过多次迭代训练后,分类模型将趋于可信,提高了分类模型的准确率。
需要说明的是,n次迭代训练获取的待处理内容集合均为来自相同的数据垂直领域。例如,若第1次待处理内容集合中的内容为新闻文本,则直至第n次待处理内容集合中的内容均为新闻文本。
在确定第二目标内容的实际标签之后,可以将确定了实际标签的第二目标内容和第一目标内容作为训练数据集,该训练数据集中内容对应的标签相比于相关技术中通过弱监督训练的模型所标注的待定标签更为准确,根据该训练数据集训练内容类型标识模型,训练好的内容类型标识模型更为准确,由此,可以基于该训练好的内容类型标识模型确定待识别内容的内容类型更为准确,降低由于训练数据集中标签不准确带来的后续确定内容类型也不准确的影响。
其中,待识别内容与待处理内容集合中的内容来自相同的数据垂直领域,由此,根据训练好的内容类型标识模型获得确定待识别内容的内容类型会更为准确。这里所述的垂直领域是指属于同一大类的内容范围,同属于一个垂直领域的内容具有相同的内容特点。例如针对新闻领域的内容,基于垂直领域的划分,可以划分出美食、健康、生活、汽车、科技、情感等多个垂直领域。由于待识别内容与待处理内容集合中的内容处于同一垂直领域,在标签标注上具有一定的共性,基于待处理内容集合训练出的内容类型识别模型更适用于对待识别内容的标签识别。
例如,若待处理内容集合中的内容均为新闻文本,训练好的内容类型识别模型可以对新闻文本进行分类,若待识别内容为新闻文本,则获得分类结果较为准确,由于内容类型识别模型更适用于对新闻文本进行分类,若待识别内容为视频片段,则获得分类结果不准确甚至是无法得到分类结果。
本申请实施例不具体限定内容类型识别模型,例如,内容类型识别模型可以为应用在长文本场景下的神经网络(thelong-documenttransformer,longformer)模型等。
其中,transformer(一种神经网络)模型成功的部分原因在于,自注意力(self-attention)机制使网络能够从整个序列中捕获上下文信息。可是自注意力机制虽然很有效,但它所需的内存和算力会随着输入序列长度呈平方增长,这使得当前硬件在处理长序列内容的情况下不可行,或者说非常昂贵、代价很大。相关技术中,将长序列内容的上下文缩短或者划分成为较小的序列内容,以限制这些序列内容的长度在512以内。虽然可以分段处理长序列内容,但数据的预处理也是相当麻烦的,同时这种划分可能导致长序列内容中重要的信息丢失。
基于此,可以基于将确定了实际标签的第二目标内容和第一目标内容作为训练数据集,训练longformer模型,通过训练好的longformer模型实现对长序列内容的分类。
其中,longformer模型中注意力(attention)包括窗口化的局部上下文的局部自注意力和由终端任务激活的全局自注意力。针对长序列内容,局部自注意力用来建立局部的上下文内容表示,全局自注意力用来建立完整的序列内容表示。longformer模型采用局部自注意力和全局自注意力结合的方式(或简称为稀疏注意力),即使用“注意模式(attentionpattern)”来稀疏完整的自注意力矩阵,同时为其进行了cuda(computeunifieddevicearchitecture,一种通用并行计算架构)优化,从而使得模型最大能够容纳长度上万的长序列内容,同时还能实现更好的结果,也即使用稀疏自注意力拓展模型长序列内容的容纳量。
作为一种可能的实现方式,若通过内容类型识别模型确定待识别内容的内容类型为目标类型,在向用户推荐内容时,增加目标类型对应的内容的推荐权重,实现将对用户感兴趣的内容或对用户有用的内容等优先推荐给用户,以便业务侧可以取得良好的业务效果。
例如,在对图文内容进行图文实用性原子能力判定的场景中,待识别内容为图文内容,目标类型为实用性原子能力,实用性原子能力为对用户日常生活产生帮助的展示实用性内容对应的类型。针对内容处理链路中所有图文内容,通过longformer模型确定其类型是否为实用性原子能力,将获得的结果出库并分发给端侧,若图文内容的类型为实用性原子能力,则在给用户推荐内容时,适当增加该内容的推荐权重,以便将对用户日常生活产生帮助的知识实用性内容优先推荐给用户,给用户带来良好的阅读体验。
下面结合图3和图4对基于snorkel框架对待处理内容集合中的内容标注待定标签进行说明。
snorkel框架是一种快速产出训练数据的弱监督系统,利用标签函数(labelfunction),可以快速产生,管理,建模训练数据。标注函数为使用规则、外部数据、其他分类模型(如内容垂类模型)等信息对内容打上不完全准确的标签,然后通过小样本准确标注计算标签函数对真实标签的后验概率,最后通过标签之间的冲突学习标签函数对真实标签的概率生成模型,生成标签。
其中,小样本为相对于全部样本内容数据量较小的样本内容,大样本为相对于全部样本内容数据量较大的样本内容。
参见图3,图3为本申请实施例提供的一种snorkel框架的示意图。使用snorkel框架快速构建内容类型识别模型所需的训练数据集的整体流程,参见s2011-s2013。
s2011:设置标签函数。
通过标签函数引入业务经验等弱标签信息、策略规则、弱分类器、业务经验等。其中,标签函数可以分为四类,如下:
(1)基于规则。
大体可分为业务经验、启发式规则、关键词,正则模版等类型。
(2)弱监督模型。
来自其他领域训练的模型结果,如用户意图分类领域中使用情感分析模型的结果,或者不同数据集训练的模型。
(3)外部知识库。
例如利用知识图谱管理样本中的实体。
(4)标签函数组合。
原则上标签函数越多,越独立,效果越好。
需要说明的是,标签函数不一定都是有效的,效果不好的标签函数可能对效果产生负面的影响,需要筛选增删。通常的方式是在设置标签函数时对各标签函数做效果验证,确认有效后添加。
由此,通过标签函数对未标注的内容打上不完全准确的标签。
s2012:构建生成模型。
使用一个生成模型在没有任何带标签数据的条件下学习标注函数的准确性,例如,通过小样本准确标注计算标签函数对真实标签的后验概率。并相应地对它们的输出进行加权,通过标签之间的冲突学习标签函数对真实标签的概率构建生成模型,该生成模型甚至可以自动学习它们的相关结构。
其中,生成模型可以为概率图模型、矩阵分解等,还可以采用简单的投票方式。生成模型和内容类型识别模型(一种判别模型)本质区别为前者学习的是联合分布,后者为条件概率。生成模型是一个概率模型,模拟出联合分布之后,再用贝叶斯(bayes)规则得到目标内容基于先验概率的条件概率。生成模型使用的是概率图模型中知识图谱(factorgraph),概率图模型公式推导如下:
s2013:训练内容类型识别模型。
生成模型输出一组概率训练标签之后,使用这些标签来训练内容类型识别模型,如深度神经网络,该内容类型识别模型将泛化到标签函数表示的内容之外,提升覆盖率。
此外,还可以通过人工进行校验,进一步提升标签的准确率,从而提高内容分类模型分类的准确性。
基于此,可以通过snorkel框架对未标注的内容进行标注。参见图4,图4为本申请实施例提供的一种通过弱监督训练的模型标注标签的示意图。
首先,将m个内容作为输入,在snorkel框架中处理成候选(candidate)形式,作为基本的处理单元。例如,若针对文本分类问题,每个输入的文本作为一个candidate。然后,通过预先设置的标签函数,输出为三种1,-1,0,对应于正,负,无法判断,或者输出1-n,对应于n类标签。此时获得的标签是含噪标签,由于标签函数可能是存在矛盾的,也可能是不完备的,故获得的标签之间可能是存在冲突的。接下来将含噪标签输入至一个生成模型,得到修正标签,最后用修正标签训练一个内容类型识别模型。
接下来,以图文实用性原子能力判定场景为例对本申请实施例提供的内容标注方法进行说明。其中,图文实用性原子能力建设主要是挖掘一些细粒度的优质原子特征,例如,对图文内容建设了实用性、正能量、专业性等原子能力,对视频内容建设了趣味性等原子能力。
参见图5,图5为本申请实施例提供的一种内容标注方法的应用场景示意图。
s1:原子能力启动需要大量数据,而业务场景中带标签的图文数据(如以图片和文字构成的新闻文本)很少,为了增加带标签的图文数据,可以将其输入至snorkel框架中。
s2:使用snorkel框架对图文数据标注待定标签。
整体流程如下:通过观察图文数据样本或使用外部模型结果等设置标签函数,然后对小样本进行准确标注,对已标注小样本进行标注函数的后验概率计算,接下来对未标注的大样本进行标注并学习标签函数对真实标签的生成模型,最后对大样本进行标注。通过评测,重点数据垂直领域(如健康,科技,美食,汽车,情感,生活等)被标注待定标签的准确率可达80%。
s3:获得待处理内容集合。
s4:根据待定标签的标签置信度,从待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,和标签置信度不满足第一阈值的第二目标内容。
s5:将第一目标内容作为训练样本训练得到fasttext分类模型。
s6:通过fasttext分类模型对第二目标内容进行标注,得到第二目标内容的候选标签。
s7:获得由第二目标内容的待定标签和候选标签构成的标签数据库。
s8:若第二目标内容的第二类标签的标签置信度高于第二阈值,则通过前述方式一确定第二目标内容的实际标签,直接加入到训练数据集中。
s9:若第二目标内容的第二类标签的标签置信度小于或等于第二阈值,则将其重新标注后加入到训练数据集中。
重新标注的方式可以为人工标注的方式,由此,以自训练的方式结合少量人工筛选构建内容类型识别模型,对重点垂类分类的准确率达到90%,召回率达到95%。
s10:根据训练数据集训练longformer模型。
需要说明的是,训练数据集中还包括第一目标内容的第一类标签。通过训练好的longformer模型确定待识别内容的内容类型,若通过longformer模型确定待识别内容的内容类型为实用性原子能力,在向用户推荐内容时,增加实用性原子能力对应的内容的推荐权重。
由此,通过longformer模型识别出来的图文实用性内容进行推荐加权实验,实现了将用户日常生活产生帮助的知识实用性与实操类内容优先推荐给用户,在浏览器侧整体大盘点击访问量(pageview,pv)提升0.45%,大盘点击提升0.17%,图文点击提升0.5%;同时日均活跃用户数量(dailyactiveuser,dau)次日留存提升0.064%,互动指标数据中分享独立访客(uniquevisitor,uv)提升0.337%,点赞pv提升3.090%,评论uv提升0.325%。
针对上述实施例提供的内容标注方法,本申请实施例还提供了一种内容标注装置。
参见图6,图6为本申请实施例提供的一种内容标注装置的结构示意图。如图6所示,该内容标注装置600包括:获取单元601、训练单元602、标注单元603和确定单元604;
所述获取单元601,用于获取待处理内容集合,所述待处理内容集合中的内容具有通过弱监督训练的模型所标注的待定标签;
所述获取单元601,还用于根据所述待定标签的标签置信度,从所述待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,和标签置信度不满足所述第一阈值的第二目标内容;
所述训练单元602,用于将所述第一目标内容作为训练样本训练得到分类模型;
所述标注单元603,用于通过所述分类模型对第二目标内容进行标注,得到所述第二目标内容的候选标签;
所述确定单元604,用于根据所述第二目标内容的待定标签和候选标签,确定所述第二目标内容的实际标签。
作为一种可能的实现方式,所述确定单元604,用于:
确定所述第二目标内容的待定标签和候选标签的一致性响应于确定所述第二目标内容的待定标签和候选标签一致,将所述第二目标内容的候选标签作为所述第二目标内容的实际标签。
作为一种可能的实现方式,所述确定单元604,用于:
确定所述第二目标内容的候选标签的标签置信度响应于确定所述第二目标内容的候选标签的标签置信度满足第二阈值,执行所述确定所述第二目标内容的待定标签和候选标签的一致性的操作。
作为一种可能的实现方式,在所述确定所述第二目标内容的待定标签和候选标签的一致性之后,所述确定单元604,用于:
响应于确定所述第二目标内容的待定标签和候选标签不一致,确定所述第二目标内容的候选标签的标签置信度;
响应于确定所述第二目标内容的候选标签的标签置信度满足第三阈值,将所述第二目标内容的候选标签作为所述第二目标内容的实际标签。
作为一种可能的实现方式,所述训练单元602,还用于:
将确定了实际标签的所述第二目标内容作为训练样本对所述分类模型进行迭代训练;
通过迭代训练后的所述分类模型对未确定实际标签的所述第二目标内容重新标注候选标签,并执行所述根据所述第二目标内容的待定标签和候选标签,确定所述第二目标内容的实际标签的操作。
作为一种可能的实现方式,所述训练单元602,还用于:
针对第n次获取的待处理内容集合,从所述第n次获取的待处理内容集合的内容中获取标签置信度满足所述第一阈值的第一目标内容,并作为训练样本迭代训练所述分类模型。
作为一种可能的实现方式,所述内容标注装置600,还用于:
将所述第一目标内容和确定了实际标签的所述第二目标内容确定为训练数据集;
根据所述训练数据集训练内容类型识别模型;
通过训练好的所述内容类型识别模型确定待识别内容的内容类型,所述待识别内容与所述待处理内容集合中的内容来自相同的数据垂直领域。
作为一种可能的实现方式,所述内容标注装置600,还用于:
若通过所述内容类型识别模型确定所述待识别内容的内容类型为目标类型,在向用户推荐内容时,增加所述目标类型对应的内容的推荐权重。
作为一种可能的实现方式,所述待定标签用于标识所述待处理内容集合中内容在最小划分粒度下的内容类别。
本申请实施例提供的内容标注装置,虽然通过弱监督训练的模型可以快速对内容标注标签,但是准确性难以保证,会直接影响内容的后续使用。为此,针对基于上述方式打标得到的待处理内容集合,根据内容的待定标签的标签置信度将待处理内容集合中的内容分为满足第一阈值的第一目标内容,和不满足第一阈值的第二目标内容,由于第一目标内容的待定标签的准确性高于第二目标内容,将第一目标内容作为训练样本训练得到的分类模型的可信度较高,通过该分类模型可以对第二目标内容进行标注,得到第二目标内容的候选标签,由于分类模型所具备的可信度较高,故可以将候选标签和待定标签均作为判断第二目标内容的实际标签的依据,以此确定第二目标内容的实际标签。由此,确定出的第二目标内容的实际标签更为准确,而且分类模型是根据待处理内容集合中标签置信度较高的第一目标内容进行训练的,可以适应不断变化的待处理内容集合中的内容,提高了对待处理内容集合中的内容进行标注的准确性。
前述所述的内容标注设备可以为一种计算机设备,该计算机设备可以为服务器,还可以为终端设备,下面将从硬件实体化的角度对本申请实施例提供的计算机设备进行介绍。其中,图7所示为服务器的结构示意图,图8所示为终端设备的结构示意图。
参见图7,图7是本申请实施例提供的一种服务器结构示意图,该服务器1400可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(centralprocessingunits,cpu)1422(例如,一个或一个以上处理器)和存储器1432,一个或一个以上存储应用程序1442或数据1444的存储介质1430(例如一个或一个以上海量存储设备)。其中,存储器1432和存储介质1430可以是短暂存储或持久存储。存储在存储介质1430的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器1422可以设置为与存储介质1430通信,在服务器1400上执行存储介质1430中的一系列指令操作。
服务器1400还可以包括一个或一个以上电源1426,一个或一个以上有线或无线网络接口1450,一个或一个以上输入输出接口1458,和/或,一个或一个以上操作系统1441,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等等。
上述实施例中由服务器所执行的步骤可以基于该图7所示的服务器结构。
其中,cpu1422用于执行如下步骤:
获取待处理内容集合,所述待处理内容集合中的内容具有通过弱监督训练的模型所标注的待定标签;
根据所述待定标签的标签置信度,从所述待处理内容集合的内容中获取标签置信度满足第一阈值的第一目标内容,和标签置信度不满足所述第一阈值的第二目标内容;
将所述第一目标内容作为训练样本训练得到分类模型;
通过所述分类模型对第二目标内容进行标注,得到所述第二目标内容的候选标签;
根据所述第二目标内容的待定标签和候选标签,确定所述第二目标内容的实际标签。
可选的,cpu1422还可以执行本申请实施例中内容标注方法任一具体实现方式的方法步骤。
参见图8,图8为本申请实施例提供的一种终端设备的结构示意图。图8示出的是与本申请实施例提供的终端设备相关的智能手机的部分结构的框图,该智能手机包括:射频(radiofrequency,简称rf)电路1510、存储器1520、输入单元1530、显示单元1540、传感器1550、音频电路1560、无线保真(wirelessfidelity,简称wifi)模块1570、处理器1580、以及电源1590等部件。本领域技术人员可以理解,图8中示出的智能手机结构并不构成对智能手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图8对智能手机的各个构成部件进行具体的介绍:
rf电路1510可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器1580处理;另外,将设计上行的数据发送给基站。通常,rf电路1510包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器(lownoiseamplifier,简称lna)、双工器等。此外,rf电路1510还可以通过无线通信与网络和其他设备通信。上述无线通信可以使用任一通信标准或协议,包括但不限于全球移动通讯系统(globalsystemofmobilecommunication,简称gsm)、通用分组无线服务(generalpacketradioservice,简称gprs)、码分多址(codedivisionmultipleaccess,简称cdma)、宽带码分多址(widebandcodedivisionmultipleaccess,简称wcdma)、长期演进(longtermevolution,简称lte)、电子邮件、短消息服务(shortmessagingservice,简称sms)等。
存储器1520可用于存储软件程序以及模块,处理器1580通过运行存储在存储器1520的软件程序以及模块,从而实现智能手机的各种功能应用以及数据处理。存储器1520可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据智能手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器1520可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
输入单元1530可用于接收输入的数字或字符信息,以及产生与智能手机的用户设置以及功能控制有关的键信号输入。具体地,输入单元1530可包括触控面板1531以及其他输入设备1532。触控面板1531,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板1531上或在触控面板1531附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板1531可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器1580,并能接收处理器1580发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板1531。除了触控面板1531,输入单元1530还可以包括其他输入设备1532。具体地,其他输入设备1532可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
显示单元1540可用于显示由用户输入的信息或提供给用户的信息以及智能手机的各种菜单。显示单元1540可包括显示面板1541,可选的,可以采用液晶显示器(liquidcrystaldisplay,简称lcd)、有机发光二极管(organiclight-emittingdiode,简称oled)等形式来配置显示面板1541。进一步的,触控面板1531可覆盖显示面板1541,当触控面板1531检测到在其上或附近的触摸操作后,传送给处理器1580以确定触摸事件的类型,随后处理器1580根据触摸事件的类型在显示面板1541上提供相应的视觉输出。虽然在图8中,触控面板1531与显示面板1541是作为两个独立的部件来实现智能手机的输入和输入功能,但是在某些实施例中,可以将触控面板1531与显示面板1541集成而实现智能手机的输入和输出功能。
智能手机还可包括至少一种传感器1550,比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示面板1541的亮度,接近传感器可在智能手机移动到耳边时,关闭显示面板1541和/或背光。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别智能手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于智能手机还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
音频电路1560、扬声器1561,传声器1562可提供用户与智能手机之间的音频接口。音频电路1560可将接收到的音频数据转换后的电信号,传输到扬声器1561,由扬声器1561转换为声音信号输出;另一方面,传声器1562将收集的声音信号转换为电信号,由音频电路1560接收后转换为音频数据,再将音频数据输出处理器1580处理后,经rf电路1510以发送给比如另一智能手机,或者将音频数据输出至存储器1520以便进一步处理。
wifi属于短距离无线传输技术,智能手机通过wifi模块1570可以帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图8示出了wifi模块1570,但是可以理解的是,其并不属于智能手机的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。
处理器1580是智能手机的控制中心,利用各种接口和线路连接整个智能手机的各个部分,通过运行或执行存储在存储器1520内的软件程序和/或模块,以及调用存储在存储器1520内的数据,执行智能手机的各种功能和处理数据,从而对智能手机进行整体监控。可选的,处理器1580可包括一个或多个处理单元;优选的,处理器1580可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器1580中。
智能手机还包括给各个部件供电的电源1590(比如电池),优选的,电源可以通过电源管理系统与处理器1580逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。
尽管未示出,智能手机还可以包括摄像头、蓝牙模块等,在此不再赘述。
在本申请实施例中,该智能手机所包括的存储器1520可以存储程序代码,并将所述程序代码传输给所述处理器。
该智能手机所包括的处理器1580可以根据所述程序代码中的指令执行上述实施例提供的内容标注方法。
本申请实施例还提供一种计算机可读存储介质,用于存储计算机程序,该计算机程序用于执行上述实施例提供的内容标注方法。
本申请实施例还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面的各种可选实现方式中提供的内容标注方法。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质可以是下述介质中的至少一种:只读存储器(英文:read-onlymemory,缩写:rom)、ram、磁碟或者光盘等各种可以存储程序代码的介质。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备及系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的设备及系统实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上所述,仅为本申请的一种具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!