一种基于结构特征增强和类中心匹配的跨域图像分类方法
本发明涉及图像分类的
技术领域:
,更具体地,涉及一种基于结构特征增强和类中心匹配的跨域图像分类方法。
背景技术:
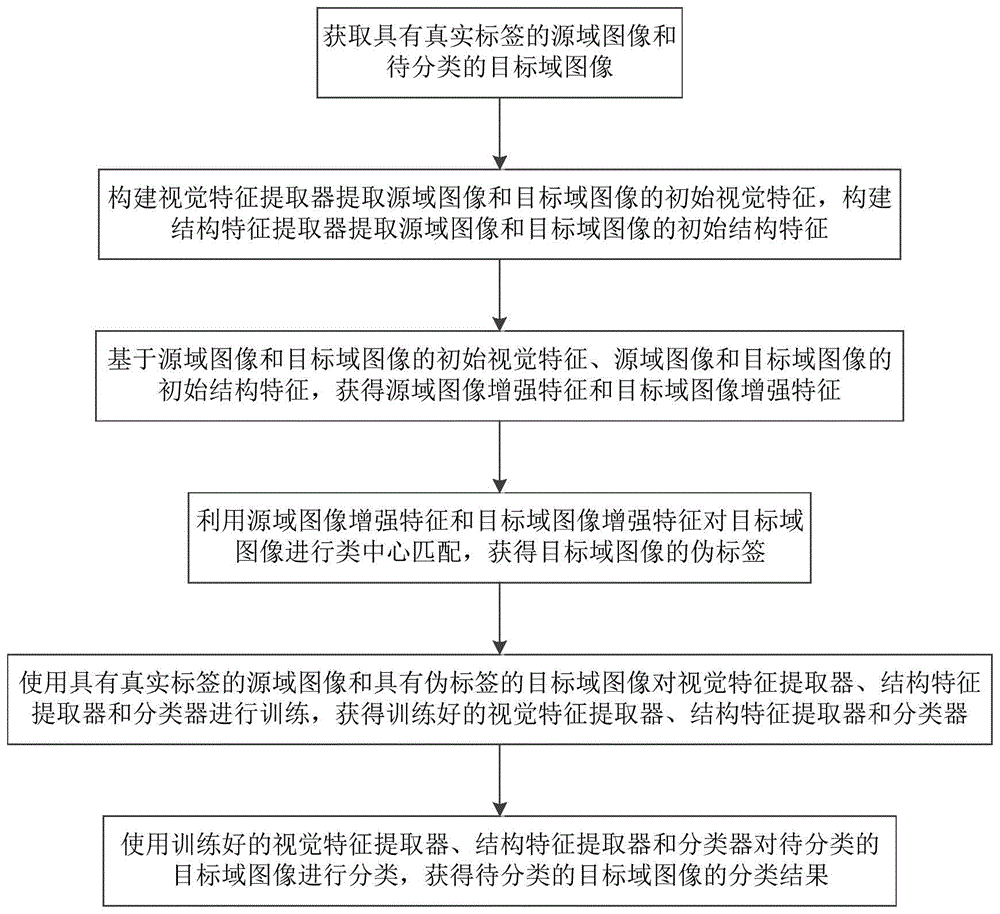
:目前,国内外已经有人开始对跨域图像分类方法进行了研究和探索,目前用于跨域图像分类方法的特征一般是视觉特征,而忽略了结构特征,从而因为结构差异使得分类器在目标域图像上分类效果不好。同时,目前方法大多直接赋予目标域图像伪标签,然后用这些带伪标签的目标域图像对网络进行训练。但是,这种直接赋予伪标签的方式无法保证伪标签的准确率,使得错误的伪标签给分类器引入错误信息,造成分类器在目标域图像上分类效果不好。2020年6月2日公开的中国专利cn111222471a种提供了一种基于自监督域感知网络的零样本训练及相关分类方法,通过自监督学习的方式充分挖掘源域和目标域之间的关系,减少因目标域数据挖掘不充分而导致的域偏差;该方法通过以agent作为桥梁连接所有类别建立联合的嵌入空间,学习域感知的视觉特征,虽然具备一定的知识迁移和泛化能力,但是分类时仅考虑图像的视觉特征,忽略了图像的结构特征,赋予目标域伪标签的准确率降低,最终导致分类精度低。技术实现要素:本发明为克服上述现有技术对跨域图像分类时考虑的特征单一,导致分类精度低的缺陷,提供一种基于结构特征增强和类中心匹配的跨域图像分类方法,对跨域图像分类时综合考虑图像的视觉特征和结构特征,使用类中心匹配方法为待分类的目标域图像赋予伪标签,提高了对跨域图像的分类精度。为解决上述技术问题,本发明的技术方案如下:本发明提供一种基于结构特征增强和类中心匹配的跨域图像分类方法,所述方法包括以下步骤:s1:获取具有真实标签的源域图像和待分类的目标域图像;s2:构建视觉特征提取器,提取源域图像和目标域图像的初始视觉特征,构建结构特征提取器,提取源域图像和目标域图像的初始结构特征;s3:基于源域图像和目标域图像的初始视觉特征、源域图像和目标域图像的初始结构特征,获得源域图像增强特征和目标域图像增强特征;s4:利用源域图像增强特征和目标域图像增强特征对目标域图像进行类中心匹配,获得目标域图像的伪标签;s5:使用具有真实标签的源域图像和具有伪标签的目标域图像对视觉特征提取器、结构特征提取器和分类器进行训练,获得训练好的视觉特征提取器、结构特征提取器和分类器;s6:使用训练好的视觉特征提取器、结构特征提取器和分类器对待分类的目标域图像进行分类,得到待分类的目标域图像的分类结果。优选地,获取源域图像和目标域图像的初始视觉特征的具体方法为:以深度卷积神经网络alexnet为基础网络构建视觉特征提取器;将源域图像集合和目标域图像集合中的所有图像输入视觉特征提取器,获得源域图像的初始视觉特征集合和目标域图像的初始视觉特征集合其中,ns表示源域图像的数量,表示第ns张源域图像,表示第nt张目标域图像,nt表示目标域图像的数量;xsv表示源域图像的初始视觉特征集合,表示第ns张源域图像的初始视觉特征;xtv表示目标域图像的初始视觉特征集合,表示第nt张目标域图像的初始视觉特征。优选地,获取源域图像和目标域图像的初始结构特征的具体方法为:以深度卷积神经网络alexnet为基础网络构建结构特征提取器,所述结构特征提取器包括结构分数提取器和图卷积神经网络;将源域图像集合和目标域图像集合中的所有图像输入结构分数提取器,获得源域图像结构分数集合xsc和目标域图像结构分数集合xtc;将源域图像结构分数集合xsc和目标域图像结构分数集合xtc输入图卷积神经网络,获得源域图像的初始结构特征集合和目标域图像的初始结构特征集合其中,xsd表示源域图像的初始结构特征集合,表示第ns张源域图像的初始结构特征;xtd表示目标域图像的初始结构特征集合,表示第nt张目标域图像的初始结构特征。优选地,所述s3中,获得源域图像增强特征和目标域图像增强特征的具体方法为:对源域图像的初始视觉特征和初始结构特征进行拼接操作,获得源域图像增强特征集合xsf=[xsv,xsd];对目标域图像的初始视觉特征和初始结构特征进行拼接操作,获得目标域图像增强特征集合xtf=[xtv,xtd]。优选地,所述s4中,获得目标域图像的伪标签的具体方法为:s4.1:利用目标域图像增强特集合xtf计算所有目标域图像对应的类别k,计算公式为:其中,表示目标域图像集合xt中的第i项目标域图像,表示目标域上第k个类别的中心点,,argmin(*)为*取最小值时求变量取值的函数,k表示常数;表示目标域图像集合xt中在第k个点的所有图像,表示目标域图像增强特征集合xtf中的第i项增强特征;s4.2:利用目标域图像增强特集合xsf计算所有源域图像对应的类别k′,计算公式为:其中,表示源域图像集合xs中的第i项目标域图像,表示源域上第k′个类别的中心点,argmin(*)为*取最小值时求变量取值的函数,k表示常数;表示目标域图像集合xs中在第k′个点的所有图像,表示源域图像增强特征集合xsf中的第i项增强特征;s4.3:相互相匹配源域图像和目标域图像的类别的中心点,计算目标域图像的伪标签:其中,表示目标域图像的分类概率,e表示自然常数;s4.4:选取目标域图像的分类概率数值最大时对应的类别作为目标域图像的伪标签。优选地,所述s5中,所述获得训练好的视觉特征提取器、结构特征提取器和分类器的具体方法为:s5.1:初始化视觉特征提取器和结构特征提取器的网络参数;s5.2:建立总损失函数,设置训练参数;s5.3:输入所有具有真实标签的源域图像和具有伪标签的目标域图像;s5.4:采用随机梯度下降算法对视觉特征提取器、结构特征提取器和分类器进行迭代训练;直到总损失函数的取值最小时,训练结束,获得训练好的视觉特征提取器、结构特征提取器和分类器。优选地,所述s5.1中,使用正态分布对视觉特征提取器和结构特征提取器的网络参数进行初始化。优选地,所述s5.2中,建立总损失函数的具体方法为:s5.2.1:构建源域图像的分类损失函数lc:其中,j为交叉熵损失函数,ps表示源域图像的分类概率,ys表示源域图像的真实标签;s5.2.2:构建目标域图像的分类损失函数lt:其中,表示目标域图像的伪标签,表示目标域图像的辅助标签;s5.2.3:构建结构损失函数lsa:其中,表示源域图像结构损失函数,表示从源域图像结构分数集合xsc中随机选出的分数集合,表示从源域图像结构分数集合xsc中随机选出的与类别一致的分数集合,表示从源域图像结构分数集合xsc中随机选出的与类别不一致的分数集合,表示第一margin系数;表示目标域图像结构损失函数,表示从目标域图像结构分数集合xtc中随机选出的分数集合,表示从目标域图像结构分数集合xtc中随机选出的与类别一致的分数集合,表示从目标域图像结构分数集合xtc中随机选出的与类别不一致的分数集合,表示第二margin系数;表示源域图像-目标域图像结构损坏函数,表示从目标域图像结构分数集合xtc中随机选出的与类别一致的分数集合,表示从目标域图像结构分数集合xtc中随机选出的与类别不一致的分数集合,表示第三margin系数;表示从源域图像结构分数集合xsc中随机选出的与类别一致的分数集合,表示从源域图像结构分数集合xsc中随机选出的与类别不一致的分数集合,表示第四margin系数;s5.2.4:构建总损失函数l:l=lc+lt+lsa其中,lc为源域图像的分类损失函数,lt为目标域图像的分类损失函数,lsa为结构损失函数。优选地,所述s5.2中,训练参数包括学习率和每次训练迭代的图像数量。优选地,所述s6中,获得待分类的目标域图像的分类结果的具体方法是:将待分类的目标域图像输入训练好的视觉特征提取器和结构特征提取器,获得目标域图像的准确视觉特征和准确结构特征;将准确视觉特征和准确结构特征输入训练好的分类器进行计算,获得待分类的目标域图像的准确标签作为分类结果。与现有技术相比,本发明技术方案的有益效果是:本发明通过构建视觉特征提取器提取源域图像和目标域图像的初始视觉特征,构建结构特征提取器提取源域图像和目标域图像的初始结构特征,获得源域图像增强特征和目标域图像增强特征,并利用源域图像增强特征和目标域图像增强特征对目标域图像进行类中心匹配,获得目标域图像的伪标签;本方法综合考虑了图像的视觉特征和结构特征,充分挖掘了图像的视觉信息和结构信息,降低了图像结构分布差异,提高了伪标签的正确率;与现有方法使用分类器直接赋予目标域图像伪标签相比,利用类中心匹配方法可以避免个别图像缺少辨别性的问题,进一步提高了伪标签的正确率,促进域内知识正迁移;使用具有真实标签的源域图像和具有伪标签的目标域图像对视觉特征提取器、结构特征提取器和分类器进行训练,利用训练好的视觉特征提取器、结构特征提取器和分类器对待分类的目标域图像进行分类,获得待分类的目标域图像的分类结果。本发明综合考虑图像的视觉特征和结构特征,使用类中心匹配方法为待分类的目标域图像赋予伪标签,提高了对跨域图像的分类精度。附图说明图1为实施例所述的基于结构特征增强和类中心匹配的跨域图像分类方法的流程图。图2实施例所述的基于结构特征增强和类中心匹配的跨域图像分类方法的分类结果示意图。具体实施方式附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。下面集合附图和实施例对本发明的技术方案做进一步的说明。实施例本实施例提供一种基于结构特征增强和类中心匹配的跨域图像分类方法,如图1所示,所述方法包括以下步骤:s1:获取具有真实标签的源域图像和待分类的目标域图像;s2:构建视觉特征提取器,提取源域图像和目标域图像的初始视觉特征,构建结构特征提取器,提取源域图像和目标域图像的初始结构特征;以深度卷积神经网络alexnet为基础网络构建视觉特征提取器,包括8层:conv1、conv2、conv3、conv4、conv5、fc6、fc7和fc8,其中fc8层神经元的个数为256;将源域图像集合阳目标域图像集合中的所有图像输入视觉特征提取器,经视觉特征提取器层层处理,以fc8的输出作为源域图像和目标域图像的视觉特征,获得源域图像的初始视觉特征集合和目标域图像的初始视觉特征集合其中,ns表示源域图像的数量,表示第ns张源域图像,表示第nt张目标域图像,nt表示目标域图像的数量;xsv表示源域图像的初始视觉特征集合,表示第ns张源域图像的初始视觉特征;xtv表示目标域图像的初始视觉特征集合,表示第nt张目标域图像的初始视觉特征;以深度卷积神经网络alexnet为基础网络构建结构特征提取器,所述结构特征提取器包括结构分数提取器和图卷积神经网络;所述结构分数提取器包括8层:conv1、conv2、conv3、conv4、conv5、fc6、fc7、fc8,其中fc8层神经元的个数为1000;所述图卷积神经网络包括图卷积层和映射层;将源域图像集合和目标域图像集合中的所有图像输入结构分数提取器,经结构分数提取器层层处理,以fc8的输出作为源域图像和目标域图像的结构分数,获得源域图像结构分数集合xsc和目标域图像结构分数集合xtc;将源域图像结构分数集合xsc和目标域图像结构分数集合xtc输入图卷积神经网络,获得源域图像的初始结构特征集合阳目标域图像的初始结构特征集合其中,xsd表示源域图像的初始结构特征集合,表示第ns张源域图像的初始结构特征;xtd表示目标域图像的初始结构特征集合,表示第nt张目标域图像的初始结构特征;图卷积层的图卷积公式为:hii=∑jgij其中,g表示结构分数构建的数据结构图,xc表示结构分数集合,表示结构分数集合的转置;gij表示结构分数构建的数据结构图g中第i行第j列的值,,h为对角矩阵,hii表示对角矩阵h的对角线;u表示图卷积后的g;映射层的映射公式为:xd=uxvw其中,xd为初始结构特征集合,xv为初始视觉特征集合,w为映射矩阵;当输入图卷积层的是源域图像结构分数集合xsc时,将xsc代入图卷积公式中的xc,将源域图像的初始视觉特征集合xsv代入映射公式中的xv,获得的xd即为源域图像的初始结构特征集合xsd;当输入图卷积层的是目标域图像结构分数集合xtc时,将xtc代入图卷积公式中的xc,将目标域图像的初始视觉特征集合xtv代入映射公式中的xv,获得的xd即为目标域图像的初始结构特征集合xtd;s3:基于源域图像和目标域图像的初始视觉特征、源域图像和目标域图像的初始结构特征,获得源域图像增强特征和目标域图像增强特征;对源域图像的初始视觉特征和初始结构特征进行拼接操作,获得源域图像增强特征集合xsf=[xsv,xsd];对目标域图像的初始视觉特征和初始结构特征进行拼接操作,获得目标域图像增强特征集合xtf=[xtv,xtd];s4:利用源域图像增强特征和目标域图像增强特征对目标域图像进行类中心匹配,获得目标域图像的伪标签,具体方法为:s4.1:利用目标域图像增强特集合xtf计算所有目标域图像对应的类别k,计算公式为:其中,表示目标域图像集合xt中的第i项目标域图像,表示目标域上第k个类别的中心点,,argmin(*)为*取最小值时求变量取值的函数,k表示常数;表示目标域图像集合xt中在第k个点的所有图像,表示目标域图像增强特征集合xtf中的第i项增强特征;s4.2:利用目标域图像增强特集合xsf计算所有源域图像对应的类别k′,计算公式为:其中,表示源域图像集合xs中的第i项目标域图像,表示源域上第k′个类别的中心点,argmin(*)为*取最小值时求变量取值的函数,k表示常数;表示目标域图像集合xs中在第k′个点的所有图像,表示源域图像增强特征集合xsf中的第i项增强特征;s4.3:相互相匹配源域图像和目标域图像的类别的中心点,计算目标域图像的伪标签:其中,表示目标域图像的分类概率,e表示自然常数;s4.4:选取目标域图像的分类概率数值最大时对应的类别作为目标域图像的伪标签。s5:使用具有真实标签的源域图像和具有伪标签的目标域图像对视觉特征提取器、结构特征提取器和分类器进行训练,获得训练好的视觉特征提取器、结构特征提取器和分类器,具体步骤为:s5.1:初始化视觉特征提取器和结构特征提取器的网络参数:视觉特征提取器采用imagenet下的预训练权重,fc8层的参数用正态分布进行初始化;结构特征提取器中的的结构分数提取器采用imagenet下的预训练权重,fc8层的参数用正态分布进行初始化;结构特征提取器中的的图卷积神经网络参数用正态分布进行初始化s5.2:建立总损失函数,设置学习率和每次训练迭代的图像数量;本实施例中学习率设置为0.01,每次训练迭代的图像数量设置为256;s5.2.1:构建源域图像的分类损失函数lc:其中,j为交叉熵损失函数,ps表示源域图像的分类概率,ys表示源域图像的真实标签;s5.2.2:构建目标域图像的分类损失函数lt:其中,表示目标域图像的伪标签,表示目标域图像的辅助标签;s5.2.3:构建结构损失函数lsa:其中,表示源域图像结构损失函数,表示从源域图像结构分数集合xsc中随机选出的分数集合,表示从源域图像结构分数集合xsc中随机选出的与类别一致的分数集合,表示从源域图像结构分数集合xsc中随机选出的与类别不一致的分数集合,表示第一margin系数;表示目标域图像结构损失函数,表示从目标域图像结构分数集合xtc中随机选出的分数集合,表示从目标域图像结构分数集合xtc中随机选出的与类别一致的分数集合,表示从目标域图像结构分数集合xtc中随机选出的与类别不一致的分数集合,表示第二margin系数;表示源域图像-目标域图像结构损坏函数,表示从目标域图像结构分数集合xtc中随机选出的与类别一致的分数集合,表示从目标域图像结构分数集合xtc中随机选出的与类别不一致的分数集合,表示第三margin系数;表示从源域图像结构分数集合xsc中随机选出的与类别一致的分数集合,表示从源域图像结构分数集合xsc中随机选出的与类别不一致的分数集合,表示第四margin系数;本实施例中4个margin系数的数值为1。s5.2.4:构建总损失函数l:l=lc+lt+lsa其中,lc为源域图像的分类损失函数,lt为目标域图像的分类损失函数,lsa为结构损失函数。s5.3:输入所有具有真实标签的源域图像和具有伪标签的目标域图像;s5.4:采用随机梯度下降算法对视觉特征提取器、结构特征提取器和分类器进行迭代训练;直到总损失函数的取值最小时,训练结束,获得训练好的视觉特征提取器、结构特征提取器和分类器。s6:使用训练好的视觉特征提取器、结构特征提取器和分类器对待分类的目标域图像进行分类,得到待分类的目标域图像的分类结果,具体的方法为:将待分类的目标域图像输入训练好的视觉特征提取器和结构特征提取器,获得目标域图像的准确视觉特征和准确结构特征;将准确视觉特征和准确结构特征输入训练好的分类器进行计算,获得待分类的目标域图像的准确标签作为分类结果。在具体实施过程中,选用office-31数据集,数据集中包含31个类别、共有4110张图片。该数据集主要包含3个域:amazon(a)、webcam(w)和dslr(d)。基于所述域,可以构建6个分类任务:a→w,w→a,w→d,d→w,d→a,a→d。例如,a→w是指以a为源域,以w为目标域的迁移任务。分类效果如图2所示。本实施例提供的方法记为ours,与传统的分类方法revgrad、rtn、jan、cat、mstn、gcan和dirt-t相比,本实施例提供的方法的分类精度如下表所示:methoda→wd→ww→da→dd→aw→aavgrevgrad73.096.499.272.353.451.274.3rtn73.396.899.671.050.551.073.7jan74.996.699.571.858.355.076.0cat77.497.499.974.763.460.878.9mstn80.596.999.974.562.560.079.1gcan82.797.199.876.464.962.680.6dirt-t73.196.899.071.362.951.375.7ours84.898.899.980.564.964.282.1从表中可以看出,本实施例提供的方法与传统的相比,对跨域图形进行分类时,6个分类任务的分类精度均高于传统方法的分类精度,平均分类精度也高于传统方法的平均分类精度。显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1