一种基于泰森多边形的事故多发点鉴别方法及其应用
1.本发明属于道路安全评价技术领域,涉及一种基于泰森多边形的事故多发点鉴别方法及其应用。
背景技术:
2.事故多发点的鉴别是道路安全评价及有针对性地对交通安全措施进行改善的重大前提,常用的事故多发点鉴别方法有事故数法、核密度分析、聚类分析和基于路网单元空间自关的分析方法。
3.事故数法旨在确定一个临界值作为判断事故多发的指标,即将单位时间内相同大小的统计单元内发生的事故数量作为评价指标;核密度分析结果较为粗糙,受极大值的影响大,且确定其搜索半径和像元大小的主观性很大,适用于初步判断事故分布情况;聚类分析同样受极大值影响较大,极值会严重影响评价分级结果,且在原理上存在缺陷,忽视了相对独立但事故多发的地点,不符合事故多发点的概念;基于路网单元空间自相关的方法使用的是集计模型,先划分路网单元,将事故点的属性赋值给路网单元,再对路网单元进行聚类分析,在划分路网单元时,确定路网单元长度的主观性大,划分方式将对评价结果产生很大的影响,适用于少量事故发生的情况,且该方法需要详细的城市路网数据,难以应用于实际。上述事故多发点鉴别分析过程中,核密度和聚类分析无法排除极值的影响;核密度和基于路网单元空间自相关的方法主观性过强,通用性差。
4.事故多发点定义的核心理念是找出一定的统计时间段内事故发生数或特征与其他正常地点相比明显突出的位置(点、路段或区域),其鉴别方法可分成基于点模式的非集计模型和基于空间统计单元的集计模型。上述方法中在空间统计单元划分时,主观性强,划分方法对鉴别结果有显著影响,且通用性差,且统计单元内部情况无法进行鉴别;非集计模型中,聚类分析方法受极值影响大,且鉴别结果为空间点,实际应用差。
5.因此,需要一种相对客观且可复制性强的统计单元划分方法来鉴别事故多发点。
技术实现要素:
6.本发明的目的在于提供一种基于泰森多边形的事故多发点鉴别方法,克服现有技术中的鉴别事故多发点时主观性强、受极值影响大、评价结果实际应用上存在缺陷等问题。
7.为实现上述目的,本发明提供如下技术方案:
8.一种基于泰森多边形的事故多发点鉴别方法,包括以下步骤:
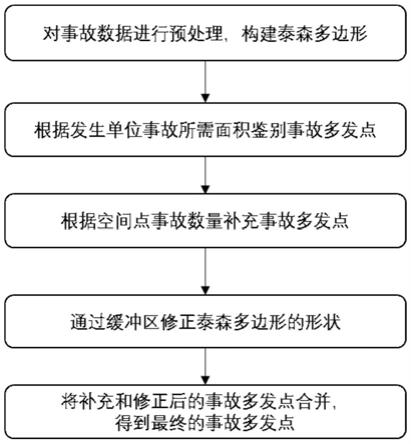
9.对事故数据进行预处理,构建泰森多边形;
10.根据发生单位事故所需面积鉴别事故多发点;
11.根据空间点事故数量补充事故多发点;
12.通过缓冲区修正泰森多边形的形状;
13.将补充和修正后的事故多发点合并,得到最终的事故多发点。
14.本发明的基于泰森多边形的事故多发点鉴别方法,从事故的空间分布出发,用泰
森多边形划分事故统计单元,用发单位事故所需面积作为评价指标,用事故点第一个近邻点距离均值作为临界值来初步鉴别事故多发点,根据空间点事故数量补充事故多发点,用半径为事故点第三个近邻点均值的缓冲区来修正多边形形状,最终将补充的事故多发点和修正后的事故多发点合并作为最终事故多发点,克服了现有技术方案划分事故空间统计单元主观性强、通用性差的缺陷,克服了非集计模型中聚类分析方法受极值影响大、空间点作为鉴别结果实际应用差的缺陷,极具应用前景。
15.作为优选的技术方案:
16.如上所述的一种基于泰森多边形的事故多发点鉴别方法,所述鉴别事故多发点的评价指标w的公式为:
17.w=s0/x;
18.其中,s0为某一泰森多边形的面积;x为所述某一泰森多边形内事故数量。
19.如上所述的一种基于泰森多边形的事故多发点鉴别方法,所述根据发生单位事故所需面积鉴别事故多发点具体是以w小于的泰森多边形作为初始事故多发点,其中为与上述泰森多边形对应的该事故数据第一个近邻点距离均值。
20.如上所述的一种基于泰森多边形的事故多发点鉴别方法,所述缓冲区为以初始事故多发点为圆心,以该事故数据第三个近邻点距离均值为半径的区域。
21.如上所述的一种基于泰森多边形的事故多发点鉴别方法,所述通过缓冲区修正泰森多边形的形状的具体操作如下:
22.判断是否存在重合缓冲区,若存在,则将重合缓冲区合并作为事故多发点,并将其剔除于以下三种修正情况;
23.判断多边形是否为细长条状且不完全被缓冲区覆盖,若是,则统计该缓冲区内事故数量,若其事故数量大于按事故数量从大到小排序的前2%值中的最小值,则剔除多边形,保留该缓冲区作为事故多发点;
24.判断缓冲区面积是否大于多边形,且缓冲区能大范围覆盖多边形,若是,则剔除缓冲区,保留多边形作为事故多发点;
25.判断是否满足以上情况,若均不满足,则保留缓冲区和多边形相交部分作为事故多发点。
26.具体地,本发明的一种基于泰森多边形的事故多发点鉴别方法,包括以下步骤:
27.步骤1、对事故数据进行预处理;
28.步骤1.1、计算原始事故数据1个和3个近邻点距离均值,记为
29.步骤1.2、将原始事故点数据中的重合点合并,转化为加权点数据,权重为该点的事故数量x;
30.步骤1.3、对加权点数据建立泰森多边形,并将该加权点的事故数量赋值给该点所在的泰森多边形,将泰森多边形集合记为s,计算每个泰森多边形的面积s0;
31.步骤1.4、计算评价指标w,其计算方法为:
32.w=s0/x
33.步骤2、对泰森多边形集合s进行筛选,将w小于的泰森多边形记为s1,作为初始
事故多发点;
34.步骤3、根据每个空间点事故数量x对初始事故多发点集合s1进行补充;
35.步骤3.1、对事故数量x从大到小排列,选取其前2%值的点;
36.步骤3.2、判别步骤3.1中筛选出的点是否在s1内,如果不在则进入步骤3.3;
37.步骤3.3、计算泰森多边形集合s1中多边形的平均面积对步骤3.2所筛选的点建立缓冲半径为的缓冲区(记为缓冲区i),缓冲区集合记为h1;
38.步骤4、根据第3个近邻点距离对多边形集合s1进行形状修正;
39.步骤4.1、对s1中的点建立缓冲半径为的缓冲区(记为缓冲区ii,即对应以初始事故多发点为圆心,以该事故数据第三个近邻点距离均值为半径的区域),缓冲区集合记为h2;
40.步骤4.2、若h2中存在部分缓冲区重叠,则将有重叠部分的缓冲区融合,其集合记为s2;
41.步骤4.3、在h2中剔除s2,并将剩余部分相交,将相交区域集合记为j,计算j中每个面要素的面积s
j
;
42.步骤4.4、若s
j
/s0<0.8且s0/s
h
<0.5,则统计缓冲区内事故的总数量,若其值小于步骤3.1中x值前2%的最小值,则将该点所在的多边形剔除出事故多发点,反之则保留缓冲区作为事故多发点;
43.步骤4.5、若s
j
/s0≥0.8且s
h
/s0≥1.6,保留泰森多边形作为事故多发点;
44.步骤4.6、若不满足步骤4.4和步骤4.5这2种情况,则保留相交部分作为事故多发点;
45.步骤4.7、将步骤4.4、步骤4.5、步骤4.6三部分修正后的结果融合作为事故多发点,记为s3;
46.步骤5、将集合h1、s2、s3合并,即为事故多发点。
47.本发明还提供了一种电子设备,包括一个或多个处理器、一个或多个存储器、一个或多个程序及获取事故数据的输出设备;
48.所述一个或多个程序被存储在所述存储器中,当所述一个或多个程序被所述处理器执行时,使得所述电子设备执行如上所述的基于泰森多边形的事故多发点鉴别方法。
49.有益效果:
50.(1)本发明的基于泰森多边形的事故多发点鉴别方法,从历史事故的空间位置分布出发,利用泰森多边形划分事故单元,用多少面积会发生一起事故作为评价指标鉴别事故多发点,用第一个近邻点距离均值作为临界值确定的依据,同时通过重合点事故数量百分比和第3个近邻点距离均值构成的缓冲区()来修正评价结果,充分反应了事故点的空间分布特征,有效地去除了极值的影响,避免了鉴别过程中主观性过强导致的通用性差、误差大的问题;
51.(2)本发明的基于泰森多边形的事故多发点鉴别方法,克服了聚类分析方法受极值影响大的问题,同时弥补了聚类分析原理上无法鉴别相对独立的事故多发点的缺陷。在统计单元划分方面,本发明克服了其他方法的路网单元划分方式主观性强、通用性差的缺
陷,且本发明不需要城市路网数据,适用于事故数量较大的情况,通用性和客观性强;
52.(3)本发明的基于泰森多边形的事故多发点鉴别方法,通过历史事故数据鉴别事故多发点,针对事故空间分布构建科学合理、有效便捷、适应性强且能够分析事故成因的城市道路事故多发点鉴别方案,极具应用前景。
附图说明
53.图1为本发明的基于泰森多边形的事故多发点鉴别方法的总体流程示意图;
54.图2为本发明实例中泰森多边形修正部分中缓冲区重叠示意图;
55.图3为本发明实例中泰森多边形修正部分中细长条多边形示意图;
56.图4为本发明实例中泰森多边形修正部分中多边形被缓冲区大范围覆盖示意图;
57.图5为本发明实例中初步鉴别出的多边形事故多发区域;
58.图6为本发明实例中最终的事故多发区域鉴别结果;
59.图7为本发明实例中用本发明方法所鉴别出事故多发点与聚类分析中热点分析鉴别结果对比图。
具体实施方式
60.下面结合附图,对本发明的具体实施方式做进一步阐述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
61.实施例1
62.一种基于泰森多边形的道路事故多发点鉴别方法,如图1所示,包括以下步骤:
63.步骤一、对原始事故数据进行预处理,首先计算第1个和第3个近邻点距离的均值,其次对事故点进行去重,并统计每个空间点上的事故数量,构成加权点,然后对加权点建立泰森多边形,将加权点和泰森多边形建立空间连接,将加权点的权重(事故数量或其他事故属性)赋值给多边形,计算每个泰森多边形的面积,并计算评价指标w,即多少面积会发生一起事故;
64.步骤二、根据第1个近邻点距离均值来初步评价多边形是否为事故多发,第1个近邻点距离均值为每个事故点离最近的事故点的平均距离(重合点的第1个近邻点距离为0),假设点均匀分布,以点为形心构建长为的正方形来完整划分空间,此正方形的面积即为临界值,w小于该值的多边形集合为初步事故多发点s1;
65.步骤三、补充相对独立的事故多发点。存在部分点,此类点的权重(事故数量)值本身很大,即该地点发生了大量交通事故,但是周围没有其他事故点,从而导致构成的泰森多边形面积过大,进而使w值过大,因此需要对此类点建立缓冲区来补充事故多发点。选取事故数量按从大到小排序在前2%且不再集合s1中的空间点,构建缓冲半径为的缓冲区(使补充的缓冲区大小和集合s1大小相近)作为事故多发点,记为h1,其中为泰森多边形集合s1中多边形的平均面积;
66.步骤四、对泰森多边形集合s1进行修正。由于泰森多边形将相邻事故点构成三角网,用三角网的中垂线来划分空间,因此多边形距点较近的几条边为事故的事故多发的方
向,距点较远的几条边为事故发生较少的方向,所以需要对多边形进行修正。对多边形内的点建立缓冲半径为第3个近邻点距离均值的缓冲区,缓冲区集合记为h2。若缓冲区h2存在相交部分,即泰森多边形相邻或十分相近的情况,如图2所示,将存在相交部分的缓冲区融合作为事故多发点,记为s2。
67.在h2中剔除s2,剩余缓冲区生成后与多边形集合相交,相交区域记为j,缓冲区面积为定值s
h
,多边形面积为s0,相交区域j的面积为s
j
,并对以下几种情况进行修正:
68.(1)s
j
/s0<0.8且s0/s
h
<0.5,即多边形为细长条状且不完全被缓冲区覆盖,如图3所示,因为该事故点周围存在过近的相邻点,从而导致多边形面积过小的情况,此时统计缓冲区内事故的总数量,若其值小于步骤三中补充事故空间点的最小事故数量,则将该点所在的多边形剔除出事故多发点,反之则保留缓冲区作为事故多发点。
69.(2)s
j
/s0≥0.8且s
h
/s0≥1.6,即相交部分能覆盖大部分多边形,且缓冲区面积大于多边形面积,意味着缓冲区能覆盖大部分多边形,如图4所示,保留泰森多边形作为事故多发点。
70.(3)不满足以上2种情况,则保留相交部分作为事故多发点。
71.以上3种修正后的形状记为s3。
72.步骤五、合并步骤三中的h1、步骤四中的s2、s3,对其重合部分进行融合得到最终的事故多发点s。若s的边中同时存在圆弧和直线,则直线部分为事故多发的倾向,若只存在直线,则距离事故点较近的边为事故多发倾向。
73.以下结合实例对本发明做进一步描述。
74.本实例数据为江苏省盐城市2019年报警事故数据,数据来源于交管部门,事故发生地点是具体地址,因此需要通过地理编码得到其经纬度坐标。经数据清洗和地理编码后导入arcgis得到39825条有效事故数据,其事故分布在4345个空间点上,其初步特征为事故主要集中在市区位置,部分空间点重复发生了多起的交通事故,且极少部分空间点的事故数量存在明显极大值,影响聚类分析的精度。
75.步骤1、根据上述所得的arcgis中39825条有效事故点数据,计算其第1个近邻点和第3个近邻点的均值其值近似为20、50米。将事故点转化为加权点后得到4345个加权点,权重为每个点的事故数量,生成4345个泰森多边形,将加权点与泰森多边形进行一对一的空间连接,使得权重赋值到泰森多边形属性内,并计算每个多边形的面积s0,计算评价指标w;
76.步骤2、计算得评价指标w的临界值为400平方米,小于该值的泰森多边形记为s1,s1内共有115个面要素,部分结果如图5所示;
77.步骤3、补充相对独立的事故多发点。选取事故数量按从大到小排序在前2%的空间点,即权重(事故数量)大于等于68的点,共计88个,其中,有56个点在多边形集合s1,32个在s1外。集合s1的平均面积近似为14818平方米,则缓冲半径近似为68米,对32个在集合s1外建立缓冲半径为68米的缓冲区,记为h1;
78.步骤4、对泰森多边形进行修正。对集合s1内的点建立缓冲半径为的缓冲区,记为h2,为50米。利用相交工具对缓冲区h2进行相交,得到相交区域,将相交区域与缓冲区
进行空间连接,相交区域作为连接要素、缓冲区作为为目标要素,得到存在相交部分的缓冲区(多个面要素),再用编辑器进行合并,得到最终的相交缓冲区(单一要素),记为s2。利用交集取反工具将s2作为输入要素、h2作为更新要素,使s2在h2中剔除,剔除后得到93个缓冲区。将这93个缓冲区与多边形s1相交,相交区域记为j,缓冲区的面积为定值s
h
,s
h
为7850平方米,多边形面积为s0,相交区域j的面积为s
j
,并对以下几种情况进行修正(因具体操作步骤十分繁琐,以下不详细描述):
79.(1)s
j
/s0<0.8且s0/s
h
<0.5,即多边形为细长条状且不完全被缓冲区覆盖,计算筛选得到8个结果。统计这8个结果所对应事故点的缓冲区h2内的事故总数量,其事故总数量为10、13、13、21、21、29、33、50,均未超过步骤3中的临界值68,不作为事故多发区域,将这8个结果对应的事故点所在多边形剔除。
80.(2)s
j
/s0≥0.8且s
h
/s0≥1.6,即相交部分能覆盖大部分多边形,且缓冲区面积大于多边形面积,意味着缓冲区能覆盖大部分多边形,计算筛选得到19个结果,将这19个结果对应的事故点所在的泰森多边形作为事故多发区域。
81.(3)对不满足以上2个条件的事故点,保留相交部分作为事故多发区域。
82.将以上3种修正结果合并得到事故多发区域s3。
83.步骤5、合并步骤3中的h1、步骤4中的s2、s3,得到最终的事故多发区域,部分结果如图6所示,图7为本实例用本发明方法所鉴别出的事故多发点与聚类分析中热点分析结果对比示意图。
84.由图7可以看出,应用发明方法所鉴别出的事故多发点与实际情况匹配度较高,其能够准确地完成事故多发点的鉴别。
85.实施例2
86.一种电子设备,包括一个或多个处理器、一个或多个存储器、一个或多个程序及获取事故数据的输出设备;
87.一个或多个程序被存储在存储器中,当一个或多个程序被处理器执行时,使得电子设备执行如实施例1所述的基于泰森多边形的事故多发点鉴别方法。
88.上述的对实例的描述时为了便于该技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对这些实例做出各种修改,并把在此说明的一般原理应用到其他实例中而不必经过创造性的劳动。因此,本发明不限于上述实例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1