基于增强的可分离卷积网络的图像去压缩效应方法
1.本发明涉及图像去压缩效应技术,具体涉及一种基于增强的可分离卷积网络的图像去压缩效应方法,属于数字图像处理领域。
背景技术:
2.有损图像压缩算法能够有效地节约传输带宽和存储空间,已被广泛地应用于各种移动设备和系统。然而,有损压缩将不可避免地造成图像质量的下降。例如,jpeg编码标准通常对非重叠的8
×
8图像块的离散余弦变换系数进行粗量化,由此引入了各种压缩效应。这些压缩效应不仅降低了视觉体验,而且给后续诸如目标检测、语义分割、超分辨率重建等计算机视觉任务增加了很大的难度。
3.为了去除图像的压缩效应,提高其质量,研究人员已经提出了大量的方法。这些方法主要包括基于增强的方法、基于重建的方法、基于学习的方法。其中,基于深度学习的方法由于其优越的性能得到了越来越多的关注和研究。然而,大多数现有的基于深度学习的方法的模型参数量和计算量都比较大,这使得它们难以被部署在移动设备和系统上。为此,本发明构建了一种增强的可分离卷积网络,取得良好的图像去压缩效应效果的同时大大减少了模型的参数量和计算量。
技术实现要素:
4.本发明进一步发展了深度可分离卷积(depth-wise separable convolution,dwsconv)的优点,设计了一种增强的可分离卷积(enhanced separable convolution,esconv),由此构建了一种轻量的深度卷积神经网络用于高效的图像去压缩效应。
5.本发明提出的基于增强的可分离卷积网络的图像去压缩效应方法主要包括以下操作步骤:
6.(1)以增强的可分离卷积为主要的构建单元,搭建用于去除图像压缩效应的卷积神经网络;
7.(2)利用步骤一的卷积神经网络,分别训练不同质量因子下的图像去压缩效应模型;
8.(3)将压缩图像输入训练好的图像去压缩效应模型,输出去压缩效应后的图像。
附图说明
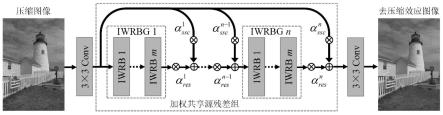
9.图1是本发明基于增强的可分离卷积网络的图像去压缩效应方法的原理框图。
10.图2为增强的加权残差模块框图。
11.图3为增强的可分离卷积框图。
12.图4是本发明与另外五种方法对压缩图像“bikes”去压缩效应结果的对比图(质量因子为10):其中,(a)为原始图像,(b)为jpeg压缩图像,(c)(d)(e)(f)(g)(h)分别为方法1、方法2、方法3、方法4、方法5及本发明的去压缩效应结果。
具体实施方式
13.下面结合附图对本发明作进一步说明:
14.图1中,基于增强的可分离卷积网络的图像去压缩效应方法具体可以分为以下几个步骤:
15.(1)以增强的可分离卷积为主要的构建单元,搭建用于去除图像压缩效应的卷积神经网络;
16.(2)利用步骤一的卷积神经网络,分别训练不同质量因子下的图像去压缩效应模型;
17.(3)将压缩图像输入训练好的图像去压缩效应模型,输出去压缩效应后的图像。
18.具体地,在步骤(1)中,搭建的增强的可分离卷积网络模型主要包括三大部分:低层次特征提取、高层次特征提取、图像重建。低层次特征提取和图像重建都由一个卷积核大小为3
×
3的卷积层3
×
3conv来实现,而高层次特征提取由加权共享源残差组来实现。
19.加权共享源残差组由n个带有加权共享源跳连接(weighted share-source skip connection,wssc)的增强的加权残差模块组(improved weighted residual block group,iwrbg)构成,可以用公式表示为:
[0020][0021]
其中,f
ll
、f
hl
分别表示第n个增强的加权残差模块组的输入、卷积层3
×
3conv提取的低层次特征、加权共享源残差组提取的高层次特征,表示第n个增强的加权残差模块组的操作,分别表示第n个增强的加权残差模块组及其共享源跳连接的加权系数。每个增强的加权残差模块组包含m个增强的加权残差模块(improved weighted residual blocks,iwrb)。图2展示了每一个增强的加权残差模块的结构,可以用公式表示为:
[0022][0023]
其中,分别表示增强的加权残差模块的输入和输出,β
res
、β
ssc
分别表示增强的加权残差模块的残差分支和跳连接分支的加权系数,h
esc
(
·
)表示增强的可分离卷积的操作。
[0024]
图3展示了增强的可分离卷积的结构,包括分组多尺度对偶深度卷积(grouped multi-scale dual depth-wise convolution,gmddconv)和宽激活对偶逐点卷积(wide-activated dual point-wise convolution,wdpconv)两部分。分组多尺度对偶深度卷积能够让我们使用具有很多分支和大卷积核的网络结构来提取丰富的多尺度信息而只增加少量的参数量和计算量,而宽激活对偶逐点卷积能够增强通道间的信息交融,使更多的特征信息通过激活函数relu,同时保持高度的非线性。具体而言,分组多尺度对偶深度卷积首先将通道数为c的输入张量沿通道维度划分为g组,这一过程可以用公式表示为:
[0025][0026]
其中,hg(
·
)表示分组操作,表示第g组特征张量。接着,分组的特征张量被送到相应的对偶深度卷积(dual depth-wise convolution,ddconv)以提取多尺度特征。最后,对多尺度特征沿着通道维度进行级联,就得到了分组多尺度对偶深度卷积的输出这
images[c].ieee conference on computer vision and pattern recognition workshops,2018:711-720.”。
[0041]
方法5:sun等人提出的方法,参考文献“sun m,he x,xiong s,et al.reduction of jpeg compression artifacts based on dct coefficients prediction[j].neurocomputing,2020,384:335-345.”。
[0042]
对比实验的内容如下:
[0043]
实验1,先用pil(python image library)模块的save函数对数据集classic5的5张测试图像分别进行质量因子(quality factor,qf)为10、20、30、40的jpeg压缩,再用方法1到方法5以及本发明分别对压缩图像进行去压缩效应处理。表一给出了对比方法及本发明在数据集classic5上评价指标的平均值。其中,方法3的作者没有提供qf为30和40时的训练模型,所以表一只给出了该方法qf为10和20时的测试结果。客观评价指标采用psnr(peak signal to noise ratio)、ssim(structure similarity index)和psnr-b。这三个指标的数值越高说明得到的去压缩效应图像的质量越好。
[0044]
表一
[0045][0046]
实验2,先用pil(python image library)模块的save函数对数据集live1的29张测试图像分别进行质量因子(quality factor,qf)为10、20、30、40的jpeg压缩,再用方法1到方法5以及本发明分别对压缩图像进行去压缩效应处理。表二给出了对比方法及本发明在测试图库live1上获得的平均psnr、ssim和psnr-b值。此外,为了进行主观视觉比较,图4给出了测试图库live1中图像“bikes”在qf为10时的去压缩效应结果。原始图像、jpeg压缩图像、方法1、方法2、方法3、方法4、方法5及本发明的去压缩效应结果分别如图4(a)、图4(b)、图4(c)、图4(d)、图4(e)、图4(f)、图4(g)及图4(h)所示。
[0047]
表二
[0048][0049]
实验3,用pytorch第三方库thop中的profile函数计算方法1到方法5以及本发明的模型参数量params和乘加操作数mult-adds以比较它们的模型复杂度。在计算乘加操作数mult-adds时,假定输入的压缩图像的分辨率为1280
×
720。表三给出了计算结果。
[0050]
表三
[0051]
评价指标方法1方法2方法3方法4方法5本发明params(k)10666767713433002277mult-adds(g)98.2614.82665.0309.6686.5255.9
[0052]
从表一和表二可以看出,相比较于其他5种图像去压缩效应方法,除了在数据集classic5质量因子qf为40的情况下,本发明的平均psnr-b值略低于方法5,在其他情况下,本发明均取得了最高的平均psnr、ssim和psnr-b值。从图4可以看出,jpeg图像存在着严重的分块、振铃、模糊等压缩效应,经过方法1、方法2、方法3、方法4和方法5的处理,jpeg图像存在的压缩效应虽然得到了有效的抑制,但是仍然存在一定的模糊,部分丢失的细节信息没有得到较好的恢复。相比之下,本发明在有效地去除jpeg图像压缩效应的同时能够恢复出更加清晰的纹理结构,获得更加接近原图的视觉效果。从表三可以看出,相比较于方法2、方法3、方法4和方法5,本发明具有较低的模型复杂度。
[0053]
综上所述,相比于其他5种方法,本发明的图像去压缩效应方法在主客观评价上都有较大的优势,且本发明的模型复杂度较低。因此,本发明是一种高效的图像去压缩效应方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1