一种基于UCL知识空间的实体消歧方法及装置
本发明涉及一种基于ucl知识空间的实体消歧方法及装置,属于互联网中知识图谱构建技术领域。
背景技术:
随着互联网的飞速发展,网络新闻数量激增,新闻中所包含的知识信息也越发庞杂,急需合适的载体对于新闻信息进行有效存储与管理。知识图谱能够通过构造“实体-关系-实体”三元组以及“实体-属性(值)”键值对将实体关联在一起形成图数据库。由国家标准《统一内容标签格式规范》(gb/t35304-2017)所定义的统一内容标签ucl(uniformcontentlabel),能够提供丰富的语义信息,其内容格式包含了何人、何物、何地、何事以及何因等与新闻事件高度契合的要素内容。通过填充ucl的描述属性集合能够对于庞杂无序的网页新闻内容进行有效组织。基于上述前提,ucl知识空间(uclknowledgespace,uclks)应运而生,ucl知识空间以维基百科、百度百科等基础知识库为基础,以网络新闻内容对于实体知识进行补充。将新闻文本中的实体与ucl知识空间中已存在的实体相关联的过程即为实体消歧,或称为实体链接。实体消歧是后续的知识空间更新以及实现基于知识空间的应用的必要前提。
在过去的几十年里,学者们对于实体消歧进行了大量研究,主要包括基于规则的方法、传统统计方法以及深度学习的方法。在文本上下文内容丰富的情况下,最先进的算法已经取得了非常好的消歧效果。然而,这些方法在短文本以及口语化文本上的性能却急剧下降。这些短文本所缺失的上下文内容对于消歧工作来说是十分必要的。近年来,很多学者努力通过探索更加丰富的上下文信息来改进实体消歧的效果。这些方法主要关注更好地利用现有文本,但是信息缺失的问题仍然没有得到解决。如果不能通过添加外部信息扩充源文本,很难在本质上改善消歧结果。
技术实现要素:
为解决上述问题,本发明提出了一种基于ucl知识空间的实体消歧方法及装置,通过对于待消歧实体以及候选实体分别进行知识扩充来提升模型效果。对于待消歧实体,给实体一个概念向量表示将其形式化为概念子图;对于候选实体,给实体一个实体向量表示将其形式化为ucl知识空间中的事实知识。最后,采用基于自注意力匹配的深度结构化语义模型获得实体消歧的结果。本能够有效地解决短文本中实体上下文信息不足导致的消歧精度不高的问题,改善实体消歧的效果。
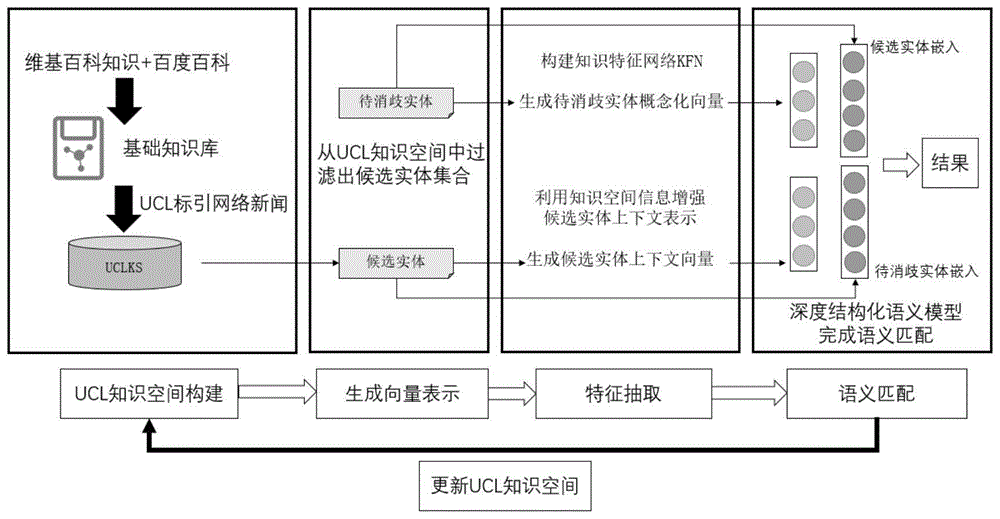
为了达到上述目的,本发明提供一种基于ucl知识空间的实体消歧方法,首先通过获取维基百科、百度百科知识构建基础知识库,将新闻信息进行ucl标引并存储在知识库中,作为ucl知识空间的内容补充,从而完成ucl知识空间的构建;利用开放域三元组抽取方法抽取出文本中的待消歧实体,从ucl知识空间获取实体消歧的候选实体集;然后对待消歧实体进行特征抽取,利用实体的上下文信息所对应的概念知识,增强待消歧实体的嵌入表示;接着利用ucl知识空间中已有的事实知识对于候选实体进行嵌入增强;最后利用一个基于自注意力匹配网络的深度结构化语义模型获得匹配结果。
具体的,本发明提供如下技术方案:
一种基于ucl知识空间的实体消歧方法,包括如下步骤:
(1)ucl知识空间构建:利用信息抽取相关技术从开放的离线数据库中获取实体、实体基础属性以及实体间关联,构建基础知识库;获取网络新闻,利用ucl标引网络新闻,计算出实体与新闻的关联,作为知识库的补充,完成ucl知识空间的构建;
(2)向量表示生成:从ucl知识空间中获取待消歧实体相关的候选实体集合,利用词向量表示方法生成候选实体和待消歧实体的嵌入表示,作为步骤(4)中语义匹配模块的输入;
(3)特征抽取:不仅考虑文本本身的内容信息,还通过引入外部知识对于文本进行补充;第一阶段抽取待消歧实体及其上下文的概念特征,第二阶段抽取候选实体上下文的特征;
(4)语义匹配:利用步骤(3)中生成的待消歧实体的概念化嵌入、候选实体的上下文嵌入以及步骤(2)中生成的候选实体与待消歧实体本身的词向量嵌入共四个向量表示作为输入,采用基于深度结构化语义匹配模型dssm的自注意力匹配网络,获得匹配度。根据匹配结果的排序得到最终消歧结果,完成文本中实体与ucl知识空间中实体的实体链接,进而更新ucl知识空间内容。
作为优选,所述步骤(1)构建基础知识库时,选择中文维基百科离线数据库作为基础库,从维基百科的词条页面获取实体及属性、关联信息;针对于维基百科数据的不全面问题,利用百度百科数据作为实体的补充,进而完善知识库内容。
作为优选,所述步骤(1)中完成ucl知识空间的构建时利用爬虫技术爬取主流中文新闻门户站点的新闻,对于获取的新闻信息进行清理、语义解析,将新闻中的实体标引为ucl实体,将ucl实体融入基础实体库,在ucl之间以及实体与ucl之间构建起联系,从而完成初始ucl知识空间的构建。
作为优选,所述步骤(2)中针对于候选实体的获取,首先完成链接候选过滤,选择使用实体指称项词典的方式从知识库中获取实体可能链接的目标对象;给定一个待消歧对象m和一个候选实体e,通过平均化文本中的词或者字符的隐藏表示生成待消歧实体的词向量表示
作为优选,所述步骤(3)中第一阶段对于待消歧实体的特征提取过程基于三个模块实现,具体包括知识特征网络模块、子图构建模块以及概念化模块。
作为优选,所述步骤(3)中知识特征网络构建依靠于待消歧实体所在句子中的词、待消歧实体本身以及候选概念之间的对应关系;其中词与待消歧实体通过词汇分析和实体识别的方式获得,候选概念通过知识空间匹配获得;知识特征网络描述三种关系,分别为概念-实体关系、概念-概念关系以及词-概念关系;通过获取上述三种关系,从而构建出概念化子图;通过重启随机游走算法计算获得最合适的概念,将待消歧实体对应的概念转化为概念化嵌入
作为优选,所述步骤(3)中第二阶段对于候选实体的特征提取过程包括如下过程:首先,根据ucl知识空间中对于实体的描述生成一个正样本,对描述文本进行分词;对于正样本中的词频进行统计,利用分层随机采样产生负样本;利用实体共现数据集和知识空间中的s-p-o三元组数据生成训练样本,从而学习候选实体与增强的实体表示之间的关系,s-p-o三元组来自于知识空间中存储的ucl节点,ucl标引的新闻事件天然带有三元组信息;随后通过cbow模型生成实体及其上下文信息的向量表示,然后通过skip-gram模型更新实体的嵌入表示,增强实体间的联系,训练得到候选实体的嵌入表示
作为优选,所述步骤(4)中实体的语义匹配过程采用基于自注意力匹配网络的深度结构化语义模型;将步骤(2)以及步骤(3)获得的待消歧实体与候选实体的四个向量表示:待消歧实体词向量
本发明还提供了一种基于ucl知识空间的实体消歧装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的基于ucl知识空间的实体消歧方法。
作为优选,计算机程序包括ucl知识空间构建模块、生成向量表示模块、特征抽取模块、语义匹配模块;ucl知识空间构建模块用于通过获取维基百科、百度百科知识构建基础知识库,将新闻信息进行ucl标引并存储在知识库中,作为ucl知识空间的内容补充,从而完成ucl知识空间的构建;生成向量表示模块用于抽取出文本中的待消歧实体,从ucl知识空间获取实体消歧的候选实体集;特征抽取模块用于对待消歧实体进行特征抽取,利用实体的上下文信息所对应的概念知识,增强待消歧实体的嵌入表示;接着利用ucl知识空间中已有的事实知识对于候选实体进行嵌入增强;语义匹配模块用于利用一个基于自注意力匹配网络的深度结构化语义模型获得匹配结果。
与现有技术相比,本发明具有如下优点和有益效果:
(1)本发明利用ucl内容格式与新闻要素相契合的特征对于新闻文本进行标引,融合基础知识库构建了ucl知识空间。相较于传统的百科知识库,通过ucl丰富的语义信息增加了知识库中实体的语义关联。
(2)本发明利用ucl知识空间中的知识信息对于候选实体的相关实体进行了补充,增强了候选实体的上下文表示。在完成实体消歧工作后,对于ucl知识空间产生正向反馈,更新了ucl知识空间中实体的相关信息。随着实体消歧任务量级的增加,实体消歧的效果也会随之提升。
(3)本发明引入了待消歧实体的知识特征网络,为待消歧实体增加了概念化属性,通过细粒度的概念化表示解决了短文本中实体链接上下文信息不足的问题。本发明既能够解决短文本中实体相关信息较少的问题,还能提高实体消歧的准确度。
附图说明
图1为本发明实施例的方法流程图。
图2为本发明实施例涉及的ucl知识空间节点示例图。
图3为本发明实施例涉及的实体消歧任务示例图。
图4为本发明实施例涉及的基于ucl知识空间的实体消歧整体架构图。
图5为本发明实施例涉及的待消歧实体概念化特征抽取模块结构图。
图6为本发明实施例涉及的候选实体上下文嵌入向量生成结构图。
具体实施方式
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
如图1所示,本发明实施例公开的一种基于ucl知识空间的实体消歧方法,具体实施步骤如下:
步骤1,ucl知识空间的构建。利用信息抽取相关技术从开放的离线数据库中获取实体、实体基础属性以及实体间关联,构建基础知识库;获取网络新闻,利用ucl标引网络新闻,作为知识库的补充,完成ucl知识空间的构建。本步骤为本发明的前提工作,具体步骤如下:
子步骤1-1,基础知识库构建。利用中文维基百科的离线数据库作为源数据建立基础数据库,爬取维基百科的分类页面与内容页面,从维基百科的词条页面获取实体及属性、关联等信息。分类页面的链接可以链接至具体的实体内容页面以及下一级子分类页面,内容页面即为内容详情页,包含结构化数据、相关实体链接。然后爬取百度百科的实体和关系数据,百度百科词条界面展示了同一实体的多个不同义项,通过抽取这部分内容,可以作为后续实体消歧工作的候选实体来源。利用实体融合、实体对齐等相关技术完成维基百科与百度百科知识的融合,构成基础知识库。
子步骤1-2,利用爬虫工具爬取主流中文新闻门户站点的新闻,对爬取的新闻信息进行清洗、语义解析,通过自然语言处理工具获得新闻的标题、作者、时间、摘要等要素信息以及新闻正文中的实体与关系信息。然后通过ucl标引工具对新闻内容进行标引,将新闻中的实体标引为ucl实体,得到ucl节点。
子步骤1-3,计算各个实体在新闻中出现的频率,如公式1所示。count(ei)表示实体出现的次数,分母即为所有实体的出现次数。在完成词频计算之后,过滤掉词频较低的实体,以便于简化后续的计算。
子步骤1-4,对于实体出现的位置进行区分,针对于实体出现的不同区域,分值也应当有所差异,位置权重设为location(ei)。如公式2所示,p为新闻段落数目,p为当前实体ei所处段落数,当新闻总段落数不超过两段时,location(ei)为固定值;当新闻总段落超过两段时,处于首末段落的实体分值相同,其他段落分值统一为首末端分值的四分之一。
子步骤1-5,利用textrank算法提取出中心句集合,集合记为sents={s1,s2,...,sn},集合中si代表中心句,它由实体组成。当实体出现在不同的中心句中的次数越多,代表实体相对权重越高。如公式3所示,n为中心句的数量,i(ei∈st)为指示函数,表示实体ei是否存在于当前的中心句st中。
子步骤1-6,计算完上述三个部分的权重参数值,结合之后提出ucl中实体语义权重计算公式如公式4所示:
ew(ei)=avg(location(ei))×(η·freq(ei)+(1-η)·center(ei))公式4
其中η为调节参数,范围为0~1。avg(location(ei))表示实体的平均位置权重,因为同一个实体可能多次出现在文章中的不同位置,需要将实体在每个位置出现的频率设为权值,综合计算实体位置权重的加权平均数。在计算完所有实体的ew(ei)之后,通过归一化就得到了每个实体的ucl语义权重。
子步骤1-7,利用ucl中的实体与基础知识库中实体建立起联系,将ucl节点加入到知识库中,完成ucl知识空间的构建。图2展示了ucl知识空间中ucl节点与实体节点的关系,其中方形节点表示标引新闻内容的ucl,圆形节点表示基础实体。ucl节点与实体节点的连线上的数值表示实体在ucl标引的新闻中所占语义权重,实体之间的连线表示实体间的关系。以图3中“《天龙八部》应该是金庸算最畅销的一部作品”中“天龙八部”这一实体的消歧过程为例,在完成知识空间构建之后,“天龙八部”在知识空间中有18个义项。
步骤2,向量表示生成。从ucl知识空间中获取待消歧实体相关的候选实体集合,利用词向量表示方法生成候选实体和待消歧实体的嵌入表示,作为步骤(4)中语义匹配模块的输入。具体步骤如下:
子步骤2-1,针对于待消歧实体m,使用实体指称项词典的方式从知识库中获取实体可能链接的目标对象,指称词典通过自定义的方法对于实体存在的别名进行约束,保留一词多义的词语对应的所有目标实体。
子步骤2-2,给定一个待消歧对象m和子步骤2-1获得的一个候选实体e,通过平均化待消歧实体所在的文本中的词或者字符的隐藏表示,生成待消歧实体的词向量表示
步骤3,特征抽取,不仅考虑文本本身的内容信息,还通过引入外部知识对于文本进行补充。利用待消歧实体在ucl知识空间中可能对应的概念以及候选实体在ucl知识空间中的相关上下文信息作为文本的外部补充,进而丰富实体的向量表示。
本步骤主要分为两个阶段,第一阶段对于待消歧实体进行特征抽取,将待消歧实体用概念来进行标记,实体的概念作为待消歧实体的附加特征。利用文本实体和对应概念构建一个知识特征网络kfn(knowledgefeaturenetwork),基于kfn生成一个具有实体与概念节点的子图,利用重启随机游走算法获得适当的待消歧实体概念。将该概念化表示为向量形式作为待消歧实体的补充特征;
第二阶段对于候选实体进行特征抽取,利用ucl知识空间已有的知识同时学习实体上下文文本以及实体之间的关系,使用带有sigmoid函数层的cbow模型来生成候选实体的向量表示。
具体的实施步骤如下:
子步骤3-1,待消歧实体的特征提取。如图4所示,本阶段采用三个模块实现,分别是知识特征网络kfn(knowledgefeaturenetwork)模块、子图构建模块以及概念化模块。以图3中“《天龙八部》应该算是金庸最畅销的一部作品”作为给定的文本对象,首先利用文本和事实知识构建一个知识特征网络。其中包括文本中的待消歧实体,即“天龙八部”、文本中的其他词语,即“金庸”、“畅销”、“作品”以及候选概念三种类型的内容知识。
子步骤3-2,知识特征网络构建依靠于待消歧实体所在句子中的词、待消歧实体本身以及候选概念之间的对应关系。其中词与待消歧实体通过词汇分析和实体识别的方式获得,候选概念通过知识空间匹配获得。kfn描述三种概念关系,分别为概念-实体关系、概念-概念关系和词-概念关系。具体的获取步骤如下:
(1)概念-实体关系由概念c到实体e的生成概率来表示,p(c|e)概率本发明采用基于维基百科实体页面的页面点击率统计而来的,如公式5所示,npv(e)为实体e的统计次数,e′为属于概念c的任一实体:
(2)概念-概念关系由两个概念之间的转移概率来表示,例如ci和cj,概率p(ci|cj)是基于两个概念下实体的共现频率来计算的,如公式6所示:
其中,如公式7所示,共现概率n(ej,ei),基于百度百科的锚链接统计计算,w是统计百度百科中实体对共现频率的窗口大小,本发明中设置为25。
n(ej,ei)=freqw(ej,ei)公式7
(3)词-概念关系由词w和相关概念c间的标注概率来表示。该概率基于词频率和词-概念共现频率来计算,如公式8所示,其中n(w)为词w出现的频率统计:
子步骤3-3,在知识特征网络上本发明使用重启随机游走算法(randomwalkwithrestart,rwr),以得到适当的待消歧实体的概念。首先,通过下述公式9、10初始化节点和边的权重,其中l表示知识特征网络的边,n表示知识特征网络的节点,t表示知识特征网络中实体个数,t表示实体节点,c表示概念节点。
随后,通过下列公式11、12对于节点和边进行迭代更新:
nk=(1-α)e′×nk-1+αn0公式11
ek←(1-β)nk+βek公式12
其中α、β是在发展集上调整的超参数。最终,通过归一化边缘权重,得到权重最高的概念类型,如公式13所示:
如图5所示,通过计算可以得到概念化子图结构,图中包含了各个实体、词与概念之间的关系与转化概率,将最终转化概率最高的概念作为概念化嵌入的对象,生成向量
子步骤3-4,对于候选实体上下文进行特征抽取。如图6所示,本发明提出一种新的特征学习方法,同时学习候选实体上下文以及知识空间中包含的实体关系,然后通过带有激活函数sigmoid的cbow模型来生成候选实体对应的上下文向量表示。具体步骤如下:
(1)首先根据ucl知识空间中对于实体的相关描述生成一个正样本,描述包括与候选实体相关的文本或实体。然后对于实体描述文本进行分词,统计正样本的词频,利用分层随机采样产生负样本。
(2)上述步骤中,为了增强候选实体与相关实体之间的关系,使用实体的共现数据和ucl知识空间中的s-p-o三元组数据来生成训练样本。s-p-o三元组来自于ucl知识空间与候选实体相关的ucl所标引的新闻文本,新闻事件包含的三元组信息会存储在知识空间中。利用子步骤1-6中计算得到实体语义权重,也可以作为候选实体上下文的补充信息。
(3)得到与候选实体相关的实体序列作为训练样本,利用cbow模型生成每个实体的嵌入表示。最终使用skip-gram模型更新实体的上下文嵌入表示,继而获得候选实体上下文的向量
步骤4,语义匹配。如图4所示,通过子步骤2-2、子步骤3-3以及子步骤3-4训练获得的待消歧实体词向量
子步骤4-1,输入的词向量序列首先通过一个lstm层,捕捉到原始句子的关键信息,分别输出一个语义向量。随后利用两层自注意力机制将待消歧实体相关的向量表示以及候选实体相关的向量表示分别聚合为一个单独的高维词向量。接着,利用全连接层将高维语义向量映射到一个连续的语义空间学习文本低纬的向量表示,进而建模向量之间的语义相似度。通过多层全连接网络(fullyconnectedlayers,fc)作为生成低纬语义向量的模型,利用余弦相似度来计算相似度损失,即实体之间的关联得分。
子步骤4-2,对于候选实体集合中的所有实体依次重复上述步骤,根据关联得分排序获得最高得分实体,即与待消歧实体最匹配的候选实体,完成实体消歧工作。最后,根据实体消歧结果完成待消歧实体与知识空间中对应实体的链接。
基于相同的发明构思,本发明还提供了一种基于ucl知识空间的实体消歧装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的基于ucl知识空间的实体消歧方法。基于ucl知识空间的的实体消歧装置包括ucl知识空间构建模块、生成向量表示模块、特征抽取模块、语义匹配模块,ucl知识空间构建模块用于通过获取维基百科、百度百科知识构建基础知识库,将新闻信息进行ucl标引并存储在知识库中,作为ucl知识空间的内容补充,从而完成ucl知识空间的构建,具体实现步骤1内容;生成向量表示模块用于抽取出文本中的待消歧实体,从ucl知识空间获取实体消歧的候选实体集,具体实现步骤2内容;特征抽取模块用于对待消歧实体进行特征抽取,利用实体的上下文信息所对应的概念知识,增强待消歧实体的嵌入表示;接着利用ucl知识空间中已有的事实知识对于候选实体进行嵌入增强,具体实现步骤3内容;语义匹配模块用于利用一个基于自注意力匹配网络的深度结构化语义模型获得匹配结果,具体实现步骤4内容。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!