铝/铜板带材生产全流程大数据存储方法
本发明涉及大数据和数据存储技术领域,尤其涉及一种铝/铜板带材生产全流程大数据存储方法。
背景技术:
近年来,信息技术迅猛发展,随着大数据技术的发展,需要处理分析的数据集的大小已经远远超过了单台计算机的存储能力,因此需要将数据集进行分区并存储到若干台独立的计算机中。分布式存储技术在整个大数据生态中,扮演着承上启下的重要作用。铝/铜板带材厂积累了大量的生产数据,但是铝/铜板带材大数据具有多源异构、质量遗传、数据不精确、时空关系复杂、实时性要求高的特点,这些特点为大数据的存储与处理带来了巨大困难。随着数据量的增大,单纯的关系型数据库无法满足生产中的需求,对以后的数据处理与分析带来了不便。因此利用分布式的大数据存储技术,对铝/铜板带材生产全流程数据进行高效、安全存储有着重大和深远的意义。
技术实现要素:
针对上述问题,本发明的目的在于提供一种铝/铜板带材生产全流程大数据存储方法,可有效存储生产全流程的结构化数据、半结构化数据以及非结构化数据,提供一整套数据存储及管理系统,实现对各类型数据的高效存取,并确保数据的安全。
本发明采用的技术方案如下:
本发明所提出的铝/铜板带材生产全流程大数据存储方法,包括以下步骤:
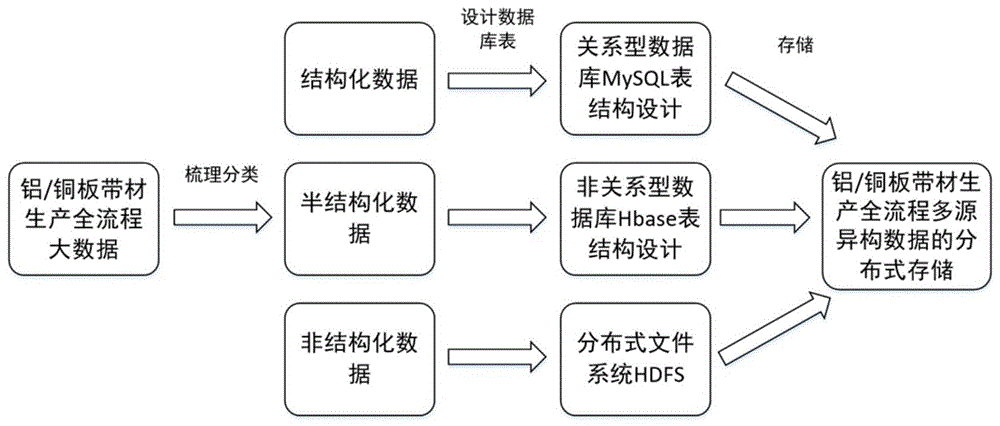
s1:针对铝/铜板带材生产全流程数据进行梳理分类,整理出不同结构和不同类型的数据;
s2:根据s1梳理的不同类型的数据,设计不同的存储方式和适用于铝/铜板带材生产全流程多源异构数据的数据库表结构,快速存取不同结构的数据;
s3:根据s2设计出的存储方式和数据库表结构,构建集群存储,实现针对铝/铜板带材生产全流程多源异构数据特点的分布式存储功能。
进一步的,所述步骤s1的具体过程如下:
(1.1)根据铝/铜板带材生产全流程工业大数据平台的数据结构,将铝/铜板带材生产全流程数据分为结构化数据、半结构化数据和非结构化数据;
(1.2)根据铝/铜板带材生产全流程的数据类型,将数据分为设备运行数据、工艺过程数据、管理信息数据、自然环境数据、质量检测数据、用于数据查询和索引的检索性数据、字段翻译数据、和加工过程中产生的各类文件数据;
(1.3)将铝/铜板带材工艺过程中的用于数据查询和索引的检索性数据以及字段翻译数据归为结构化数据;将铝/铜板带材生产过程中产生的设备运行数据、工艺过程数据、管理信息数据、自然环境数据和质量检测数据归为半结构化数据;将铝/铜板带材生产加工过程中产生的各类文件数据归为非结构化数据。
进一步的,所述步骤s2的具体过程如下:
(2.1)针对铝/铜板带材的结构化数据,将铝/铜板带材生产全流程中的生产设备、报文号、产品id、时间等索引字段和字段翻译数据存储在mysql中,且表结构选择符合第一范式的二维表形式,其中索引表存储的字段名为对应相应的索引字段,字段翻译表的字段分别为英文字段和中文字段;
(2.2)针对铝/铜板带材的半结构化数据,将设备运行数据、工艺过程数据、管理信息数据、自然环境数据和半成品/成品质量检测数据部署在非关系型数据库hbase中,存储的表结构为面向主键和列族索引的,其中将hbase的rowkey设置为设备+报文号+产品id+时间,将列族设置为对应的工艺过程,列的列名为对应的字段名;
(2.3)针对铝/铜板带材的非结构化数据,将铝/铜板带材生产全流程中产生的所有文件类型数据按照数据的基础信息,包括时间、产生此数据的设备、数据的文件名,存储在hdfs上;文件存储系统中的存储路径为设备+时间+文件名。
进一步的,所述步骤s3的具体过程如下:
(3.1)根据步骤s2设计出的存储方法和数据库表,按照以下步骤构建hadoop集群:安装java;安装hadoop;进行ssh配置;对hadoop进行配置;格式化hdfs文件系统;启动守护进程;创建用户目录;安装配置hbase;
(3.2)根据步骤s2设计的存储方法和数据库表,分别针对铝/铜板带材的不同数据,使用客户端api建立数据库表,其中表结构的设计和步骤s2相同;在hdfs中,将文件分成块来进行存储,一个文件可以包含许多个块,每个块存储在不同的datanode中;当一个客户端请求读取一个文件时,先在namenode中获取文件的元数据信息,然后从对应的数据节点上并行地读取数据块,文件最终以数据块的形式存储;hbase表根据行键的值水平分割成区域region;一个区域包含表中所有行键位于区域的起始键值和结束键值之间的行;集群中负责管理区域的结点负责数据的读写;
(3.3)对于不同的数据类型,利用现有的api,编写java程序将铝/铜板带材全流程数据直接导入服务器集群当中。
本发明与现有技术相比具有以下有益效果:
本发明解决了铝/铜板带材数据量大、数据复杂难以存储以及存储效率低的问题,实现对铝/铜板带材各类型数据的高效存取,便于后对铝/铜板带材数据的使用分析。并且hbase运行在hdfs上,hdfs的多副本存储可以让它在出现故障时自动恢复,使其具有高可靠性。
附图说明
图1为本发明的整体流程示意图;
图2为数据梳理的分类示意图;
图3为不同数据的存储方式示意图;
图4为分布式存储铝/铜板带材数据的步骤示意图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
本发明所提出的一种铝/铜板带材生产全流程大数据存储方法,如图1所示,具体实施步骤如下:
s1:针对铝/铜板带材生产全流程数据进行梳理分类;由于铝/铜板带材生产全流程数据的来源不同,结构不同,因此通过将不同的数据类型划分为结构化数据、半结构化数据、非结构化数据,为后面存储提供基础;如图2所示,具体包括以下步骤:
(1.1)针对铝/铜板带材生产全流程工业大数据平台的数据特点,将铝/铜板带材生产全流程数据按照数据的结构分为结构化数据、半结构化数据、非结构化数据;结构化数据主要是从erp、mes、二级系统等相关数据库采集到的数据;半结构化数据主要是在铝/铜板带材生产过程中传感器采集到的数据;非结构化数据主要是部分质量检测数据和部分设备运行数据,传输各类型的文件,包括图片、视频、文档等;
(1.2)根据铝/铜板带材生产全流程的数据类型,将数据分为设备运行数据、工艺过程数据、管理信息数据、自然环境数据、质量检测数据、用于数据查询和索引的检索性数据、字段翻译数据、和加工过程中产生的各类文件数据;
(1.3)将铝/铜板带材工艺过程中的用于数据查询和索引的检索性数据分为结构化数据;其中数据查询的索引用来查询分布式存储的半结构化数据和非结构化数据;将铝/铜板带材生产过程中产生的设备运行数据、工艺过程数据、管理信息数据、自然环境数据和质量检测数据分为半结构化数据;其中生成的索引存储在结构化数据库表中;将铝/铜板带材生产加工过程中产生的各类文件数据分为非结构化数据,例如,表面检测图像、组织晶相图像、加工过程视频等。
s2:设计适用于铝/铜板带材生产全流程多源异构数据的数据库表结构,根据s1中梳理的不同结构的数据,设计不同的数据库和数据表,如图3所示。其中针对铝/铜板带材的结构化数据,设计mysql数据库表进行存储,针对铝/铜板带材的半结构化数据,设计hbase数据库表进行存储,针对铝/铜板带材的非结构化数据,使用分布式文件系统hdfs进行存储;从而实现能够快速存取不同结构的数据的功能;具体包括以下步骤:
(2.1)将铝/铜板带材生产全流程中的生产设备、报文号、产品id、时间等索引字段和字段翻译数据存储在mysql中,且表结构选择符合第一范式的二维表形式,其中索引表存储的字段名为对应相应的索引字段,字段翻译表的字段分别为英文字段和中文字段;
根据铝/铜板带材生产全流程工艺进行分表存储;铝/铜板带材生产过程的工艺步骤将生产相关结构化数据分为熔铸、热轧、冷轧、热处理四个表,同时,每个表的所有列名拼接起来应形成半结构化数据表中行键;对于铝/铜板带材半结构化数据和非结构化数据的导入过程中生成对应的索引表,如表1所示:
表1结构化数据表
针对铝/铜板带材冷轧连退过程字段进行翻译,根据工艺不同分为两个表,每个表分两列分别存储英文字段名称和中文字段,如表2所示:
表2字段翻译数据表
根据设备进行分表存储;铝/铜板带材生产过程中不同设备形成不同的表用来存储其报文信息,用于查询功能进行设备选取时返回对应的报文信息,如表3所示:
表3报文信息数据表
(2.2)针对铝/铜板带材生产全流程数据的特点,将设备运行数据、工艺过程数据、管理信息数据、自然环境数据和半成品/成品质量检测数据部署在非关系型数据库hbase中;存储的表结构应是面向主键和列族索引的;其中,主键结构应采用“设备号+报文号+产品id+时间”的结构,列族应是具体的生产工艺编号,列族下的字段应为具体工艺下生产的工艺参数或变量字段。如表4所示:
表4实时数据表
(2.3)针对铝/铜板带材生产全流程加工过程中产生的各类文件数据等非结构化数据特点,按照铝/铜板带材数据的基础信息(时间、产生此数据的设备、数据的具体类型),规划数据在分布式文件存储系统中的存储路径,存储在hdfs上;铝/铜板带材生产非结构化数据的存储路径为“设备+时间+文件名”,对应在关系型数据库中的索引表包含:产生文件的设备(工艺)、文件产生时间、文件的类型、文件路径以及文件名称;铝/铜板带材全流程生产非结构化数据在分布式文件存储系统中的存储名称为:产生数据的设备(工艺)-文件产生时间-产生文件的设备号-其他文件属性。
s3:根据铝/铜板带材数据的特征,实现针对铝/铜板带材生产全流程多源异构数据的分布式存储功能;分布式存储采用非关系型数据库hbase和分布式文件系统hdfs,相比于传统的关系型数据库存储数据的方式,更适合于对大量的铝/铜板带材的历史数据加以利用和管理;具体步骤如图4所示:
(3.1)根据设计出的存储方法和数据库表,构建hadoop集群。按照以下步骤构建hadoop集群:安装java;安装hadoop;进行ssh配置:
ssh安装好后,需要允许来自集群内机器的hdfs用户和yarn用户能够无需密码登录,创建一个公钥/私钥对,存放在nfs之中,让整个集群共享,让整个集群共享该密钥对。测试是否可以从主机器ssh到工作器;对hadoop进行配置:设置hadoop系统的java安装的位置,在hadoop-env.sh文件中设置java_home项。设置hadoop-env.sh文件中设置hadoop-heapsize的堆内存大小为5000mb。修改xml文件,将一台主机指定为namenode;格式化hdfs文件系统:创建存储目录和初始化版本的namenode持久数据结构,格式化进程将创建一个空的文件系统。使用%hdfsname–format快速操作;启动守护进程:以hdfs用户身份运行%start-dfs.sh启动hdfs守护进程。使用%start-yarn.sh启动yarn守护进程;创建用户目录:给目录设置用户访问许可并且给用户目录设置了5tb的容量限制;安装配置hbase。
(3.2)根据设计的存储方法数据库表,分别针对铝/铜板带材的不同的数据,使用客户端api建立数据库表,其中表结构的设计和s2相同。在hdfs中,将文件分成块来进行存储,一个文件包含许多个块,每个块存储在不同的datanode中;当一个客户端请求读取一个文件时,先在namenode中获取文件的元数据信息,然后从对应的数据节点上并行地读取数据块,文件最终以数据块的形式存储。hbase表根据行键的值水平分割成区域region;一个区域包含表中所有行键位于区域的起始键值和结束键值之间的行;集群中负责管理区域的结点负责数据的读写;
针对s2中的结构化数据表,进入mysql客户端,使用建表sql语句进行建表,表结构和字段名参照步骤(2.1)。
针对s2中的半结构化数据表,进入hbaseshell,使用create命令对设备运行数据、工艺过程数据、管理信息数据、自然环境数据和质量检测数据建立5张hbase表,其中将列族设置为对应的工艺名,列名为对应的字段名。
(3.3)对于不同的数据类型,利用现有的api,编写java程序将铝/铜板带材全流程数据直接导入服务器集群当中。
针对铝/铜板带材生产结构化数据,直接使用java的jdbc连接数据库,根据上述设置的mysql数据库表,将铝/铜板带材结构化数据导入到mysql数据库中。
针对铝/铜板带材生产半结构化数据,官方代码包里含有原生访问客户端,由java语言实现,导入官方提供的hadoop和hbase的jar包,根据已经建立的hbase数据库表以及存储逻辑,利用api将铝/铜板带材半结构化数据导入到hbase数据库中。
针对铝/铜板带材生产非结构化数据,使用官方提供的api,利用java程序存储到hdfs上。导入官方提供的hadoop的jar包,按照步骤(2.3)所述的文件存储路径,编写java代码将铝/铜板带材生产非结构化数据存储到hdfs上。
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!