一种融合节点偏好的异构图歌单多标签推荐方法
本发明属于音乐推荐系统领域,具体涉及一种融合节点偏好的异构图歌单多标签推荐方法。
背景技术:
近年来,网易云音乐推出的歌单功能,使云音乐打破了传统专辑歌手歌单分类组织的方式。以歌单为核心的播放模式,可以以社交化的分享和个性化的推荐来解决用户发现寻找音乐的需求。其中,歌单标签对于改善在线音乐用户的听歌体验,鼓励用户制作个性化歌单方面具有重要作用。在大数据迅速发展的背景下,我们可以从大量带有专家标签的歌单中隐含地推断出歌单中歌曲的特征,使歌单标签推荐成为可能。协同过滤算法在音乐推荐领域的应用非常普遍,其算法一般分为数据收集、相似度计算和给出推荐结果三步。然而,在大数据时代下,由于歌单数据的高维稀疏性以及过分关注交互关系的原因,传统的协同过滤算法在进行歌单标签推荐时存在容易推荐热门标签,推荐用时久等问题,使得这种方法很难在实践中得以应用。
技术实现要素:
为克服现有技术中的问题,本发明目的在于提供一种融合节点偏好的异构图歌单多标签推荐方法。
为实现上述目的,本发明采用如下的技术方案实现:
一种融合节点偏好的异构图歌单多标签推荐方法,包括以下步骤:
步骤1:通过歌单训练集的异构数据构建歌单异构图;
步骤2:通过歌单异构图采用基于歌曲元路径以及基于歌手元路径,对每个歌单进行融合节点偏好的邻居采样,得到包含歌曲邻居特征的歌单信息和包含歌手邻居特征的歌单信息;
步骤3:包含歌曲邻居特征的歌单信息和包含歌手邻居特征的歌单信息使用word2vec技术进行歌单连续特征表示;
步骤4:采用谱聚类算法对歌单的连续特征表示进行聚类分析,得到歌单聚类结果;
步骤5:根据歌单聚类结果,计算出每类中各导航类标签的权重值,再使用局部敏感哈希技术,完成对目标歌单的标签推荐。
进一步的,步骤1的具体过程为:
步骤1.1:根据如下公式连接歌单节点
步骤1.2:根据如下公式连接歌单节点
步骤1.3:根据如下公式连接歌单节点
进一步的,步骤1.1中,歌曲-歌单边
其中,
其中,
步骤1.3中,用户-歌单边
其中,
进一步的,步骤2具体过程如下:
步骤2.1:若歌单节点
步骤2.2:若歌单节点
步骤2.3:通过备选歌曲邻居
步骤2.4:根据歌单节点偏好
步骤2.5:采用歌单邻居集
步骤2.6:通过下式整合歌单节点
步骤2.7:重复步骤2.1-2.6将所有歌单节点
进一步的,步骤2.3中,歌单节点偏好
其中,
进一步的,步骤2.6中,歌曲列表
进一步的,步骤3的具体过程如下:
步骤3.1:初始化歌单歌曲特征word2vec语言模型modelm和歌单歌手特征word2vec语言模型models,模型modelm和模型models的输出向量长度和模型迭代次数都为模型的输入参数值;
步骤3.2:将包含歌曲邻居特征的歌单信息作为句子输入到模型modelm,将包含歌手邻居特征的歌单信息作为句子输入到模型models中;
步骤3.3:对歌曲特征word2vec语言模型modelm和歌单歌手特征word2vec语言模型models进行训练后,输出歌单节点集合的歌曲特征向量化表示集合vecm和歌单节点的歌手特征向量化表示集合vecs,如下公式所示:
其中,
步骤3.4:歌单节点
进一步的,步骤4的具体过程如下:
步骤4.1:根据聚类的类别数n_cluster初始化聚类模型modelcluster;
步骤4.2:将经过连续特征表示的歌单训练集数据
步骤4.3:根据歌单的训练集标签
其中,
步骤4.4:将歌单测试集特征集
进一步的,步骤5的具体过程如下:
步骤5.1:根据歌单训练集
步骤5.2:对分组歌单集进行lsh/minhash哈希分桶计算,得到语种类哈希桶byz、主题类哈希桶bzt、场景类哈希桶bcj、风格类哈希桶bfg以及情感类哈希桶bqg,其中根据歌单歌曲集和歌单歌手集使得语种类哈希桶byz、主题类哈希桶bzt、场景类哈希桶bcj、风格类哈希桶bfg以及情感类哈希桶bqg分别生成两种数据哈希桶,如公式如下所示:
其中,
步骤5.3:从测试集
步骤5.4:将目标歌单的歌曲集
步骤5.5:根据与目标歌单相似的歌单集simij以及权重值wij更新每个标签的推荐指标
其中,权重值wij为
步骤5.6:最后将待推荐标签集rtag中各标签按照推荐指标
本发明和现有技术相比较,具有如下有益效果:针对传统协同过滤算法具有推荐效率低下、推荐准确率不高且未能考虑到歌单之间关联性等问题,提出了融合节点偏好的异构图歌单多标签推荐方法,其歌单标签推荐过程主要分为四步:首先,使用歌单的异构数据创建歌单异构图,运用基于节点偏好异构图的元路径歌单特征采样方法提取歌单的邻居信息,获取包含歌曲邻居特征的歌单信息和包含歌手邻居特征的歌单信息。其次,采用word2vec技术中将歌单特征进行连续特征表示。接着使用谱聚类算法计算歌单特征表示的聚类类别,通过歌单被聚类的类别计算出每类中各导航类标签的权重值。最后,将包含歌单邻居的歌单集特征与歌单集的类别群体特征结合使用局部敏感哈希技术,完成最终的歌单多标签推荐任务,使得此推荐方法的准确性得到提升。本发明具有结构简单,推荐高效的特点。相比于传统的协同过滤方法,本发明的歌单标签推荐的准确率高、推荐速度快。
附图说明
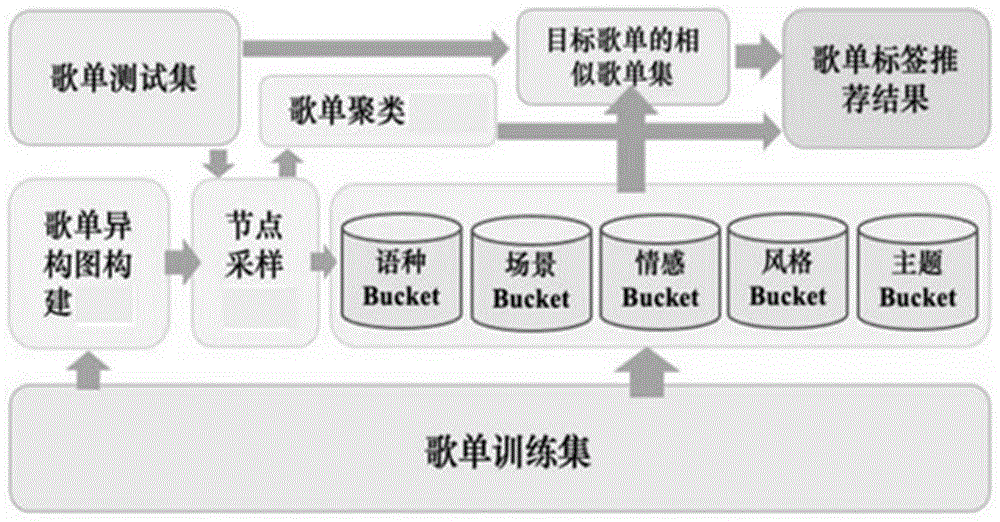
图1为推荐模型架构图。
图2为歌单异构图示例。
图3为歌单节点的歌曲邻居特征采样方法示意图。
图4为歌单节点特征向量化表示示意图。
图5为歌单节点聚类分析方法示意图。
图6为歌单聚类中各类别的导航类占比。
图7为训练集歌单-歌曲集的哈希分桶图。
图8为基于歌单聚类结果的多标签推荐方法示意图。
图9为传统方法(trad)和本发明(grac)的执行用时及推荐准确性结果。
图10为本发明(grac)在不同优化方式的两种数据集规模消融实验结果。
具体实施方式
下面结合附图对本发明做详细描述。
本发明的一种融合节点偏好的歌单异构图多标签推荐方法,使用抓取到的十万规模网易云音乐歌单数据,将其按照1:9的比例分为测试集歌单异构数据ltest和训练集歌单异构数据ltrain。
首先,使用网易云音乐中歌单的训练集歌单异构数据ltrain创建歌单异构图gl,运用基于节点偏好异构图的元路径歌单特征采样方法提取歌单的邻居信息,获取歌单的歌曲异构特征信息
其次,采用word2vec技术中的skip-gram算法将歌单特征进行连续特征表示
接着使用谱聚类算法计算歌单特征表示的聚类类别,通过训练集歌单被聚类的类别
最后,将包含歌单邻居的歌单集特征与歌单集的类别群体特征结合使用局部敏感哈希技术完成最终的歌单多标签推荐任务。
具体包括以下步骤:
步骤1:通过歌单训练集的异构数据构建歌单异构图gl具体过程为:
网易云歌单数据集中包含n各歌单的集合l={l1,l2,…,ln}。集合中的每个歌单都包含3种类型的特征信息
此歌单异构图为无向图,表示为gl={v,e},其中,异构图中由四种类型节点,表示为v={vl,vm,vs,vu},而每种类型节点中都由若干个该类型节点集组成,分别为:歌单节点
步骤1.1:给定歌单节点
步骤1.2:给定歌单节点
步骤1.3:给定歌单节点
步骤2:通过歌单异构图gl采用基于歌曲元路径rm以及基于歌手元路径rs,对每个歌单进行融合节点偏好的邻居采样,得到包含歌曲邻居特征的歌单信息和包含歌手邻居特征的歌单信息;
具体过程如下:
步骤2.1:给定歌单节点
步骤2.2:若歌单节点
步骤2.3:通过备选歌曲邻居
其中,
步骤2.4:根据歌单节点偏好
步骤2.5:通过歌单邻居集
步骤2.6:最终通过下式整合歌单节点
步骤2.7:通过如上步骤2.1-2.6将所有歌单节点
步骤3:对包含邻居特征的歌单信息使用word2vec技术进行歌单连续特征表示;具体过程如下:
步骤3.1:初始化歌单歌曲特征word2vec语言模型modelm和歌单歌手特征word2vec语言模型models,这两个模型modelm和模型models的输出向量长度和模型迭代次数都为模型的输入参数值;
步骤3.2:将包含歌曲邻居特征的歌单信息作为句子输入到模型modelm,将包含歌手邻居特征的歌单信息作为句子输入到模型models中;
步骤3.3:对歌曲特征word2vec语言模型modelm和歌单歌手特征word2vec语言模型models进行训练后,输出歌单节点集合的歌曲特征向量化表示集合vecm和歌单节点的歌手特征向量化表示集合vecs,如下公式所示:
其中
步骤3.4:歌单节点
其中,
步骤4:使用谱聚类算法对歌单的连续特征表示进行聚类分析,得到歌单聚类结果;具体过程如下:
步骤4.1:根据聚类的类别数n_cluster初始化聚类模型modelcluster;
步骤4.2:将经过连续特征表示的歌单训练集数据
步骤4.3:根据歌单的训练集标签
其中,
步骤4.4:将歌单测试集特征集
步骤4.5:输出测试集歌单类别
步骤5:根据歌单聚类结果,计算出每类中各导航类标签的权重值,再使用局部敏感哈希技术,完成对目标歌单的标签推荐。具体过程为:
步骤5.1:根据歌单训练集
步骤5.2:对分组歌单集进行lsh/minhash哈希分桶计算,得到语种类哈希桶byz、主题类哈希桶bzt、场景类哈希桶bcj、风格类哈希桶bfg以及情感类哈希桶bqg,其中根据歌单歌曲集和歌单歌手集使得语种类哈希桶byz、主题类哈希桶bzt、场景类哈希桶bcj、风格类哈希桶bfg以及情感类哈希桶bqg分别生成两种数据哈希桶,如公式如下所示:
步骤5.3:从测试集
步骤5.4:将目标歌单的歌曲集
步骤5.5:根据与目标歌单相似的歌单集simij以及权重值wij更新每个标签的推荐指标
其中,权重值wij为
步骤5.6:最后将待推荐标签集rtag中各标签按照推荐指标
其中,n为参数,可以根据实际需要确定。rect为推荐结果,
本发明首先将抓取到的网易云音乐歌单数据按1:9的比例分为测试集歌单ltest和训练集歌单ltrain。使用ltrain创建歌单异构图gl,运用基于节点偏好异构图的元路径歌单特征采样方法提取歌单的邻居信息,获取歌单的歌曲异构特征信息
本发明提供了一种融合节点偏好的歌单异构图多标签推荐模型,从歌单数据稀疏且歌单数据间的关联度不均匀等特点出发,把歌单数据多维信息之间的关联关系应用于推荐模型中,通过运用基于异构图和word2vec技术的包含邻居特征的歌单连续特征表示方法来表示歌单信息,并且使用谱聚类算法分析歌单的类别聚类特征,应用其中的歌单类别权重wlabel,最后将包含歌单类聚的歌单集特征与歌单集的类别群体特征结合使用局部敏感哈希技术进行歌单多标签推荐任务。本文提出的标签推荐模型的推荐准确性有较大的提升,且得益于推荐模型较低的计算复杂度,使其推荐效率也得到了一定的提升。并且相对于基于深度学习算法的推荐模型,本发明所提方法与当前在线音乐平台所采用的基于协同过滤算法的推荐方法具有更好的兼容性,升级系统推荐算法的成本和风险更低。
一种融合节点偏好的异构图歌单多标签推荐系统,包括
下面为具体实施例。
实施例1
表1实验数据集
参见表1,本发明首先从网易云音乐平台上抓取了10万歌单数据,共有73种不同的标签tag,有16449种不同的歌单标签组合ltag,将歌单数据按照1:9的比例分为测试集歌单ltest和训练集歌单ltrain。
参见图1,图1为本发明提出的融合节点偏好的歌单异构图多标签推荐方法的模型架构图,主要包括异构图构建与融合节点偏好的邻居采样方法,歌单节点特征表示与聚类分析方法以及基于歌单聚类结果的多标签推荐方法。
参见图2为歌单异构示例,本发明将歌单数据中的歌曲信息、歌手信息和用户信息作为歌单的异构特征信息,并基于这些信息构建歌单异构图。网易云歌单数据集中包含n各歌单的集合l={l1,l2,…,ln}。集合中的每个歌单都包含3种类型的特征信息
此歌单异构图为无向图,表示为gl={v,e},其中,异构图中由四种类型节点,表示为v={vl,vm,vs,vu},而每种类型节点中都由若干个该类型节点集组成,分别为:歌单节点
歌单异构图的构建步骤如下:
步骤1:给定歌单节点
步骤2:给定歌单节点
步骤3:定歌单节点
图3为本发明的基于异构图的歌单节点歌曲邻居特征采样方法示意图,参见图3,在歌单多标签推荐任务中,更好更多的利用歌单所具有的异构信息,能够更准确的表示歌单之间的关联关系,因此,本发明的歌单邻居节点采样方法中,通过节点偏好充分考虑节点之间的关联性,使其邻居节点的采样更有意义,在网易云歌单异构图gl中,通过基于歌曲的元路径rm采样和基于歌手元路径rs采样,元路径的定义如下:
其中,基于歌曲的元路径rm采样与基于歌手的元路径rs采样方法相同,即得到包含歌手邻居特征的歌单信息的方法与得到包含歌曲邻居特征的歌单信息的方法相同。以下为基于歌曲元路径的采样,该方法接收两个输入参数,分别为歌单节点的一阶歌曲邻居数nms和一阶歌单邻居数nl,其方法的具体步骤如下:
步骤1:选择一个歌单节点
步骤2:若歌单节点
步骤3:通过备选歌曲邻居
步骤4:根据歌单节点偏好
步骤5:通过歌单邻居集
步骤6:最终整合歌单节点
步骤7:通过如上步骤将所有歌单节点
图4是本发明中歌单节点特征向量化表示示意图,参见图4,为了从歌单节点特征方面进一步刻画歌单数据,因此本发明希望能对包含邻居信息的歌单节点进行聚类分析,得到五类歌单数据群体,但由于歌单特征的离散性,所以本发明需要先对歌单特征进行连续特征表示。因为歌单异构图gl中各节点的度是具有幂律分布特征的,而节点偏好也符合这种分布特征,因此,通过基于节点偏好的邻居采样的歌单特征也遵循幂律定律,而这种分布和word2vec模型中文本单词的频率分布特征类似,因此本发明通过使用word2vec中的skip-gram模型学习歌单节点的嵌入表示,这一过程即就是将歌单节点中经过游走采样的包含邻居的歌曲列表
步骤1:初始化歌单歌曲特征word2vec语言模型modelm和歌单歌手特征word2vec语言模型models,其输出向量长度和模型迭代次数都为输入参数值;
步骤2:将歌单节点的歌曲特征集合作为句子输入到模型modelm,将歌单节点的歌手特征集合作为句子输入到模型models中;
步骤3:两种模型分别训练完成后输出歌单节点集合的歌曲特征向量化表示集合vecm和歌单节点的歌手特征向量化表示集合vecs,如下公式所示,其中
步骤4:歌单节点
表2网易云音乐歌单标签类别
歌单多标签推荐任务本身可认为是多分类任务,在网易云歌单数据的标签类型中,如上表2所示,共有五种标签导航类,每种导航类又有多种情感标签类。
图5为歌单特征聚类分析的示意图,图6为歌单聚类中各类别的导航类占比。参见图5和图6,聚类分析作为机器学习领域中的数据挖掘工具,其可被用于数据归类,让相似的数据能聚到同一类中,而让不相同的数据分到不相同的类别中,而且可以使用类别的不同找出各类别之间的隐性关联。在多种聚类方法中,作为建立在图论基础之上的谱聚类方法,其拥有可以在任何形状的空间样本上进行聚类并且可以收敛到全局最优的优点,本发明将其用于歌单数据的聚类分析中,但本发明的聚类分析算法并不是将歌单分到某一类而结束,而是通过歌单被聚类的类别计算出每类中各导航类标签的权重值,以便后续推荐。这是因为,若某歌单的标签组合为[“孤独”,“伤感”,“思念”],那么其导航类就应为[“情感”]类,该歌单被分到“情感”聚类类别中是合适的,而当某歌单的标签组合为[“摇滚”,“欧美”,“兴奋”],那么其导航类应为[“风格”,“语种”,“情感”]类,而该歌单只可能被分到一种聚类类别中,但分到任何一种都是不适宜的,因此本发明通过聚类算法仅将歌单训练集特征进行聚类,计算出每种类别的导航类权重后,再使用原聚类模型对歌单测试集数据进行聚类分析,该聚类模型需要输入的参数是聚类的类别数n_cluster,其歌单特征聚类步骤如下:
步骤1:根据聚类的类别数n_cluster初始化聚类模型modelcluster;;
步骤2:将歌单训练集数据
步骤3:根据歌单的训练集标签
步骤4:将歌单测试集特征集
步骤5:输出测试集歌单类别
图7为训练集歌单-歌曲集的哈希分桶示意图,图8为基于歌单聚类结果的多标签推荐方法示意图,本发明从歌单的五种导航类标签[“语种”,“场景”,“主题”,“风格”,“情感”]出发,对训练集的歌单按导航类分为五大类,再使用lsh/minhash算法计算各导航类的歌单哈希桶,接着再结合歌单聚类分析结果,最终完成标签推荐任务。该方法接收含有邻居信息的歌单训练集数据
步骤1:根据歌单训练集
步骤2:使用分组歌单集对其进行lsh/minhash哈希分桶计算,得到byz语种类哈希桶、bzt主题类哈希桶、bcj场景类哈希桶、bfg风格类哈希桶以及bqg情感类哈希桶,其中根据歌单歌曲集和歌单歌手集使的每种导航类分别生成两种数据哈希桶,如公式如下所示::
步骤3:从测试集
步骤4:将目标歌单的歌曲集
步骤5:根据目标歌单检索出的相似歌单集simij以及权重wij更新每个标签的推荐指标
步骤6:最后将带推荐标签集rtag中各标签按照其推荐指标
本发明具有的优点:
相比于传统的协同过滤推荐方法,本算法推荐准确率高,推荐速度快的特点,方法简单有效。
图9所示为本发明提出的融合节点偏好的歌单异构图多标签推荐方法(grac)和传统协同过滤推荐方法(trad)在推荐准确率和推荐效率方面的比较。其推荐方法的效果评估是通过精确率recp和召回率recr计算f1值,使用f1值作为推荐结果的评价指标,以下是其定义:
精确率:
其中,其中rt表示推荐正确的标签数,nr表示推荐的标签数。精确率越高,则表示推荐正确的标签数占推荐的总标签数的比例越大。
召回率:
其中,其中nt表示真实正确的标签数,则表示推荐正确的标签数占实际正确的总标签数的比例越大。
f1值:
f1值作为对精确率和召回率的加权调和,其综合考虑了两者对模型准确性评价的影响,f1值越高,表示推荐模型的整体准确性越稳定,反之亦然。
表3实验方法描述
表4消融实验方法描述
表3以及图9所示是在真实歌单数据上本发明与传统协同过滤方法在不同数据集规模下的歌单多标签推荐的对比结果。比较的结果说明了本发明在不同歌单数据规模下都能极好的提升歌单标签推荐任务的效果,具有更好的推荐准确性和推荐实时性。表4及图10所示是为了验证本发明提出的各项优化方法在不同数据规模下的推荐有效性,结果表明本发明中的改进方式能较好的提升推荐效果。
本发明深入研究了异构图信息在推荐场景下的应用,提出了基于节点偏好的异构图多标签推荐方法,该方法通过歌单异构信息网络提升了目标歌单节点的表达能力,并且使用信息聚合技术增强每类歌单数据的关联性,其主要做了如下三个方面的工作:1)为充分利用歌单数据的异构关系,本方法使用歌单、歌曲和歌手之间的关系构建歌单异构图,并且在图构建时,通过计算不同节点之间的偏好度建立边权重信息,充分利用每对节点的多维偏好信息。针对目标歌单多种类型的特征,本方法提出了基于节点偏好的二阶邻居随机采样方法,充分利用邻居歌单与目标歌单的关系构造目标歌单的节点特征。2)为提升计算相似歌单集的准确性,本方法提出基于邻居特征表示和谱聚类算法对歌单数据进行聚类分析,将歌单分为五种导航类,每种类别都得出其聚类结果准确度,并将其作为类别权重应用于下游推荐中。3)为优化推荐效率,本方法在利用异构图构建歌单节点特征以及谱聚类算法对节点进行聚类分析的基础之上,进一步融合了基于局部敏感哈希的协同过滤算法进行最终的标签推荐任务,使其不仅提升了算法的推荐准确性,也大幅提高了推荐的高效性。基于网易云音乐真实歌单数据的实验结果表明,该发明推荐推荐效果比传统的协同过滤方法有较大幅度提升,且平均运行时间相较于传统协同过滤方法有了极大的改善。
- 还没有人留言评论。精彩留言会获得点赞!