一种基于最小类别混淆的跨个体脑电信号分类方法
本发明涉及脑电信号处理领域,具体涉及一种基于最小类别混淆的跨个体脑电信号分类方法。
背景技术:
脑电信号(electroencephalogram,eeg)是记录大脑活动的有力工具,能够更客观、可靠地捕捉人类的脑部状态。此外,随着可穿戴设备和干电池技术的迅速发展,脑电信号的获取更加便捷。因此,近些年来基于脑电信号的分类受到越来越多的关注,如癫痫检测、运动想象、情绪识别和睡眠分期等。有效的脑电信号分类方法对智能人机交互和医疗健康等领域具有重要意义。
利用机器学习来实现脑电信号分类已经有了广泛的研究,主要步骤是先从eeg中设计和提取特征,再将提取得到的特征训练分类器进行识别任务。常用的eeg特征包含有时域特征,频域特征和时频特征等。常用的分类器包括支持向量机(supportvectormachine,svm)、k近邻(k-nearestneighbor,knn)等传统机器学习算法,以及深度置信网络、卷积神经网络、长短时记忆网络等深度学习算法。然而,这些方法往往忽略不同eeg通道之间蕴含的空间信息。
由于个体间情绪反应的显著差异,现有的模型不能很好地将从其他被试学到的知识转移到新被试身上,这就需要从新被试身上获取大量带标签的样本来重新训练模型,这种做法消耗大量时间且无法适用于许多实际场景。近年来,一些研究人员试图利用域对抗神经网络(domainadversarialneuralnetwork,dann)、深度自适应网络(deepadaptationnetwork,dan)等领域自适应技术来解决跨个体的脑电分类问题。这些方法通过对训练个体(源域)和待预测个体(目标域)的特征进行对齐,在跨个体脑电信号分类任务中取得了较高的准确率。然而,为了保证特征对齐,它们会付出丢失一些类别信息的代价,从而降低特征的可辨别性。此外,当个体差异显著时,这些方法可能会导致负迁移,即在源域学习的知识会对目标域的预测产生负面作用。
技术实现要素:
本发明为克服现有技术的不足之处,提出一种基于最小类别混淆的跨个体脑电信号分类方法,以期能保证特征的可辨别性并避免负迁移,从而提高跨个体脑电信号分类的准确率。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种基于最小类别混淆的跨个体脑电信号分类方法的特点在于,包括以下步骤:
步骤1、获取一批训练个体的脑电信号及其对应的类别标签,获取一批待预测个体的脑电信号,提取训练个体和待预测个体的脑电信号中每个频段的频域特征并进行标准化处理,得到输入样本序列,其中,任意一个样本记为x,且
步骤2、构建基于最小类别混淆的gru-mcc网络模型;
步骤2.1、建立特征提取器,并将样本x输入到所述特征提取器中,得到深度特征hf;
步骤2.2、建立分类器,将所述深度特征hf输入到所述分类器中,得到输出结果z;
步骤2.3、将所述输出结果z输入到softmax函数层,得到所述样本x对于每种类别标签的概率值;
步骤2.4、计算所述输入样本序列中带情绪标签的训练个体的脑电信号所对应的源域样本的交叉熵损失;
步骤2.5、计算所述输入样本序列中待预测个体样本的脑电信号所对应的目标域样本xt的最小类别混淆损失;
步骤2.6、联合所述交叉熵损失和最小类别混淆损失来优化gru-mcc模型的参数,得到训练好的gru-mcc网络模型;
步骤3、以所述训练好的gru-mcc模型对一批待预测个体样本的脑电信号进行分类。
本发明所述的跨个体脑电信号分类方法的特点也在于,所述步骤2.1中的特征提取器是由门控循环单元和全连接层组成,并按如下过程对样本x进行处理:
所述样本x经过所述门控循环单元后得到空间表征序列h=[h1,h2,...,hi,...,hn],其中,hi是第i个通道的空间表征;
将所述空间表征序列h展开为长向量h',并经过所述全连接层进行降维处理,从而得到深度特征hf。
所述步骤2.5中的最小类别混淆损失是按如下过程计算:
步骤2.5.1、概率调节:
将所述输入样本序列中待预测个体样本的脑电信号所对应的目标域样本xt输入所述特征提取器和分类器中,并输出结果zt;
采用温度调节策略计算目标域样本xt的类别概率
步骤2.5.2、类别相关:
计算第j类和第j′类的类别相关系数
步骤2.5.3、不确定性加权:
计算第i个目标域样本对应的熵
利用softmax函数计算第i个目标域样本的权重wii,并将所述权重wii对应的对角矩阵w作为权重矩阵;
计算
步骤2.5.4、类别归一化:
利用归一化策略对所述带权重的类别相关矩阵c′的每一列进行归一化处理,得到归一化后的类别相关矩阵
步骤2.5.5、最小类别混淆:
计算所述归一化后的类别相关矩阵
与已有技术相比,本发明的有益效果体现在:
1、本发明提出利用最小类别混淆损失来优化模型参数,该损失定义了源域上训练的模型在分类目标域样本时对于不同类别样本的混淆程度,并通过减小这种类别混淆来增加转移收益,实现了高精度的跨个体脑电信号分类。
2、本发明构建基于门控循环单元的特征提取器来捕捉eeg通道之间的空间信息。具体来说,首先利用门控循环单元学习通道间的空间信息,门控循环单元可以捕捉长距离的空间依赖关系,同时具有参数少、易训练的特点;其次,为了不损失有效信息,将输出结果展开成高维向量,并通过全连接层进行降维,得到更具判别力的深度特征,最终提高了脑电信号分类精度。
附图说明
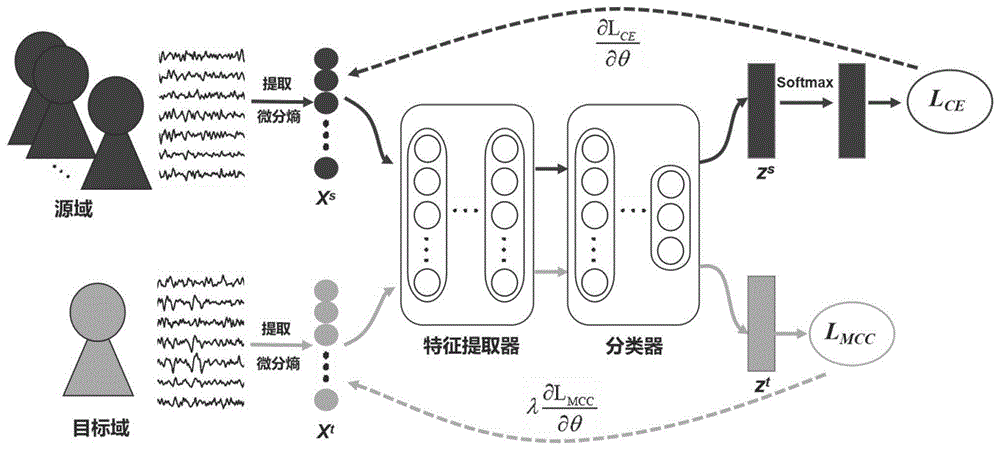
图1为本发明gru-mcc的网络结构图;
图2为本发明gru-mcc中特征提取器的结构图;
图3为本发明最小类别混淆损失的计算流程图。
具体实施方式
本实施例中,一种基于小类别混淆的跨个体脑电信号分类方法,包括如下步骤:
步骤1、获取一批训练个体的脑电信号及其对应的类别标签,获取一批待预测个体的脑电信号,提取训练个体和待预测个体的脑电信号中每个频段的频域特征并进行标准化处理,得到输入样本序列,其中,任意一个样本记为x,且
步骤1.1、从公开数据集seed获取实验所需的数据,seed数据集记录了了15名被试在观看情感电影片段时的脑电信号。每名被试做三次实验,每次实验观看15个约4分钟的电影片段(其中积极、中性、消极片段各5个)。根据国际10-20标准系统,62个通道的eeg信号被采集,并将采集到的信号降采样到200hz,为了滤除噪声和去除伪影,用0-75hz的带通滤波器对eeg数据进行处理。
采用留一(leave-one-subject-out,loso)交叉验证策略来训练gru-mcc模型。loso策略每次以一个被试作为待预测个体,其他14个被试作为训练个体。重复这个过程,使得每个被试都被用作待预测个体一次。获取训练个体的脑电信号及其对应的类别标签,获取一批待预测个体的脑电信号。
步骤1.2、提取训练个体和待预测个体的脑电信号中5个子频段的微分熵特征,包括delta(1-3hz),theta(4-7hz),alpha(8-13hz),beta(14-30hz)和gamma(31-50hz)。将微分熵特征按照个体进行z-score标准化,得到输入样本序列。对于任一微分熵特征de,可获得对应的输入样本x,公式如下:
式(1)中,μ和σ分别表示所在个体所有微分熵特征的均值和标准差,62指的是通道数目,5指的是每个通道的特征数目。
步骤2、构建基于最小类别混淆(minimumclassfusion,mcc)的gru-mcc网络模型,如图1所示,模型由特征提取器和分类器组成,同时,计算交叉熵损失和最小类别混淆损失优化模型参数。
步骤2.1、构建如图2所示的特征提取器,特征提取器由门控循环单元(gatedrecurrentunit,gru)和全连接层组成。首先,将上述样本x输入到gru层:
式(2)中,
式(3)中,wf和bf分别代表权重和偏置,relu表示修正线性单元激活函数,表达式为:
步骤2.2、使用线性变化作为分类器,与特征提取器相连,用于脑电信号类别预测。将深度特征hf输入到分类器,得到输出向量z:
式(5)中,r表示类别数目,在本实施例中,r=3。步骤2.3、将输出结果z输入到softmax函数层,得到样本x对于每种类别标签的概率值,计算方式如下:
式(6)中,p(j|x)表示样本x属于第j类的预测概率。
步骤2.4、计算输入样本序列中带类别标签的训练个体的脑电信号所对应的源域样本的交叉熵损失。输入一批带标签的源域样本xs,可以计算其交叉熵损失:
式(7)中,bs表示源域的批处理大小,li是样本
步骤2.5、计算输入样本序列中待预测个体样本的脑电信号所对应的目标域样本xt的最小类别混淆损失。最小类别混淆损失的计算步骤如图3所示,按如下过程计算:
步骤2.5.1、概率调节:将输入样本序列中待预测个体样本的脑电信号所对应的目标域样本xt输入特征提取器和分类器中,并输出结果
深度学习趋向于做出过于自信的预测,为了减弱这种趋势,采用温度调节策略计算目标域样本xt的类别概率:
式(9)中,
步骤2.5.2、类别相关:第j类和第j′类的类别相关系数被定义如下:
式(10)中,
步骤2.5.3、不确定性加权:不同的样本对类别混淆的贡献不同。例如,那些被预测接近均匀分布(没有明显峰值)的样本贡献较小,而被预测有几个明显的峰值的样本,表明分类器在模糊类之间犹豫不决,对于体现类别混淆更为重要。因此,一个基于熵的加权机制被引入,赋予更确定性样本更高的权重:
式(11)-(13)中,
步骤2.5.4、类别归一化:利用归一化策略对带权重的类别相关矩阵c′的每一列进行归一化处理,得到归一化后的类别相关矩阵
步骤2.5.5、最小类别混淆:矩阵
步骤2.6、联合交叉熵损失和最小类别混淆损失来优化gru-mcc模型的参数,得到训练好的gru-mcc网络模型。在训练过程中,同时向模型中输入一批带标签的源域样本xs和一批无标签的目标域样本xt,分别计算交叉熵损失和最小类别混淆损失,并根据如下公式优化模型参数:
式(16)中,α表示学习率,λ表示两种损失之间的平衡。在本实施例中,α=0.001,λ=1。
步骤3、以训练好的gru-mcc模型对一批待预测个体样本的脑电信号进行分类。模型最终的性能由所有待预测个体的平均准确率和标准差来评估。
具体实施中,gru-mcc模型与svm,dann,dan,gru(移除最小类别混淆损失)以及mcc(用全连接层代替特征提取器)进行对比。15名待预测个体的平均准确率和标准差如表1:
表1.不同方法的分类性能
结果表明,本发明优于传统机器学习方法svm,以及基于特征对齐的领域自适应方法dann和dan,提高了跨个体脑电信号分类的准确率。与gru相比,本发明通过引入最小类别混淆损失在跨个体脑电信号分类任务上帮助提高了14.45%的准确率。与mcc相比,本发明设计的特征提取器在跨个体脑电信号分类任务上帮助提高了2.69%的准确率。此外,本发明的标准差最小,为5.27,这表明了gru-mcc的稳定性更好,对不同个体有更强的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!