一种基于kubernetes的大数据管理平台的制作方法
1.本发明涉及大数据和容器云平台领域,具体来说,涉及一种基于kubernetes的大数据管理平台。
背景技术:
2.hadoop是一个能将海量数据进行分布式存储和计算的开源软件框架。具有可扩展、高容错和高效性特征。随着大数据时代的到来,hadoop技术被越来越广泛的使用。但是随着集群越来越大,部署和维护集群的成本也越来越高,需要一个可以一键部署hadoop集群的低成本方案。
3.docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的linux机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。docker是应用最为广泛的容器技术,通过打包镜像,启动容器来创建一个服务。但是随着应用越来越复杂,容器的数量也越来越多,由此衍生了管理运维容器的重大问题,于是kubernetes(k8s)容器云管理工具应运而生。
4.大数据系统一般基于开源社区版本进行构建,常用的开源大数据平台管理工具为hdp或cdh,上述工具都以组件库的方式对可安装管理的大数据组件进行管理,能够通过可交互的用户页面对大数据组件(例如hadoop)进行安装,在页面配置大数据组件组件的参数,控制大数据组件的启动停止。支持搜集大数据组件的日志,对大数据组件的性能进行监控。但使用上述大数据管理平台,在其管理的集群内,对于一种组件只支持在集群内部署一个实例,无法支持多实例或者不同版本的大数据组件部署。
5.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
6.本发明的目的在于提供一种基于kubernetes的大数据管理平台,本发明拟基于kubernetes管理平台的特性,实现一个大数据平台管理工具,能够对大数据组件进行有效管理以解决上述背景技术中提出的问题。
7.为实现上述目的,本发明提供如下技术方案:
8.一种基于kubernetes的大数据管理平台,包括大数据组件软件管理、大数据组件安装和启动、大数据组件暂停、大数据组件恢复和大数据组件删除、大数据组件配置同步、大数据组件日志收集和大数据组件监控;
9.其中,所述大数据组件软件管理:将大数据组件封装成docker的形式,配合基于kubernetes可以解析的yaml文件进行管理,使用harbor或者git来管理charts包;
10.大数据组件管理平台提供应用商店管理所有大数据组件应用,在应用商店界面中添加harbor或者git地址,通过push的方式上传安装包,通过pull的方式下载安装包;
11.所述大数据组件安装和启动:大数据组件管理平台基于kubernetes特性,大数据组件完全封装进docker中,使用kubernetes中的不同类型的控制器进行部署;
12.大数据组件暂停:大数据组件暂停时,首先调用自定义api将pod信息存储到kubernetes crd中,保存状态完成后,调用kube
‑
apiserver中的statefulset scale api对pod安装序号从大到小的顺序进行缩容,直至pod数量为0,暂停操作完;
13.大数据组件恢复:大数据组件恢复时,首先调用api从kubernetes crd中取出需要恢复的组件信息,然后调用kube
‑
apiserver中的statefulset scale api对pod进行扩容,直至pod数量恢复至停止前数量,恢复操作完成;
14.大数据组件删除:可以直接使用kubernetes删除控制器,进而删除控制器管理的资源对象,达到删除组件的目的;
15.所述大数据组件配置同步:大数据管理平台中的组件通过kubernetes中的configmap进行配置同步;
16.所述大数据组件日志收集:本大数据管理平台上运行的组件都是docker封装的形式,基于kubernetes和docker特性,就可以收集到全部大数据组件的日志;
17.所述大数据组件监控:大数据组件管理平台基于kubernetes机制提供对部署其上的组件进行统一监控。
18.进一步的,使用configmap同步配置文件主要使用如下方式:
19.将环境变量直接定义在configmap中,pod启动时通过env引用configmap中定义的环境变量。
20.进一步的,使用configmap同步配置文件主还可以使用如下方式:
21.将一个完整的配置文件直接封装在configmap中,然后通过共享卷的方式挂载到pod中,实现给应用传参。
22.进一步的,所述大数据组件日志收集中,收集日志主要有以下方式:
23.基于kubernetes daemonset控制器的特性会在每个kubernetes nodes上启动一个工作负载,所以使用kubernetes daemonset控制器的方式启动日志收集模块fluentd,统一收集所有大数据组件容器产生的日志,在kubernetes每个node上启动一个fluentd,收集docker的日志,从而收集所有大数据组件的日志。
24.进一步的,所述大数据组件日志收集中,收集日志还可以有以下方式:在大数据组件的工作负载中集成一个日志收集容器,使用emptydir的共享卷方式让日志收集容器读取到大数据组件产生的日志,然后发送日志到指定目标。
25.根据本发明的另一个方面,提供一种大数据组件安装和启动方法,该方法包括以下步骤:
26.s11、选择主机:基于kubernetes nodeselector或者pv绑定主机,实现主机选择;
27.s12、下载:将大数据组件封装成docker镜像,上传到镜像服务器;
28.s13、分发配置:大数据组件管理平台通过kubernetes中的configmap实现大数据组件的配置映射同步配置;
29.s14、启动顺序控制:大数据组件实例彼此之间存在着关联关系,有次序、角色方面的相关性,大数据组件启动时要按照模块间依赖关系按顺序启动,只有基于kubernetes有状态控制器statefulset机制才可以实现组件顺序启动;
30.s15、多实例管理:大数据组件启动后,会作为kubernetes的一中控制器的负载进行管理,kubernetes支持多个控制器单独部署,只要在同一命名空间内名称不同即可。
31.进一步的,所述步骤s12下载:将大数据组件封装成docker镜像,上传到镜像服务器具体包括以下步骤:
32.s121、编写kubernetes可以解析的yaml文件用于安装大数据组件;
33.s122、用户安装时大数据管理平台解析yaml文件;
34.s123、启用yaml文件中定义的控制器,并下载文件里配置的大数据组件docker镜像。
35.根据本发明的另一个方面,提供了一种大数据组件暂停方法,该方法包括以下步骤:
36.s21、基于kubernetes api
‑
server记录工作负载原来状态,并新建一种crd资源,记录负载命名空间、负载名称、负载数量等并保存在kubernetes中;
37.s22、基于kubernetes statefulset的机制,将工作负载的数量调整为0,实现暂停的效果。
38.与现有技术相比,本发明具有以下有益效果:本发明实现了高效构建大数据管理平台。解决传统开源大数据管理平台(hdp、cdh)无法多实例部署大数据组件的问题。本发明拟基于kubernetes管理平台的特性,实现一个大数据平台管理工具,能够对大数据组件进行有效管理,管理功能包括大数据组件管理,大数据组件安装、启动、暂停、恢复和删除,大数据组件配置修改与同步,大数据组件日志搜集,大数据组件监控。
附图说明
39.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
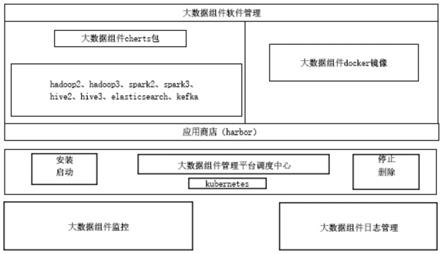
40.图1是根据本发明实施例的一种基于kubernetes的大数据管理平台的大数据组件管理平台整体架构图;
41.图2是根据本发明实施例的一种基于kubernetes的大数据管理平台中大数据组件安装启动流程图;
42.图3是根据本发明实施例的一种基于kubernetes的大数据管理平台中大数据组件暂停恢复流程图;
43.图4是根据本发明实施例的一种基于kubernetes的大数据管理平台中大数据组件日志收集流程图。
具体实施方式
44.下面,结合附图以及具体实施方式,对发明做出进一步的描述:
45.请参阅图1
‑
4,根据本发明实施例的一种基于kubernetes的大数据管理平台,包括大数据组件软件管理、大数据组件安装和启动、大数据组件暂停、大数据组件恢复和大数据组件删除、大数据组件配置同步、大数据组件日志收集和大数据组件监控。
46.如图1所示,其中,对于大数据组件软件管理来说,传统的大数据管理平台一般采用将大数据组件制作成rpm包或者deb包的形式,用户安装软件时后台调用yum或者apt
‑
get
命令进行安装。
47.本大数据组件管理平台采取将大数据组件封装成docker的形式,配合基于kubernetes可以解析的yaml文件进行管理。使用harbor或者git来管理charts包。
48.大数据组件管理平台提供应用商店管理所有大数据组件应用。在应用商店界面中添加harbor或者git地址。通过push的方式上传安装包,通过pull的方式下载安装包。
49.以管理hadoop组件为例:首先制作hadoop镜像,上传到harbor。然后编写yaml文件,制作成charts包,使用push的方式上传到harbor中。用户从应用商店选择指定的hadoop组件进行安装时,helm客户端会pull charts安装包到kubernetes中的tiller服务器,tiller服务器接收到请求解析出charts的依赖关系,调用helm install进行安装,并在kubernetes中生成一个release文件。删除指定的大数据组件时,helm客户端发送请求到tiller服务器,tiller服务器调用helm delete删除指定release。
50.请参阅图2
‑
图3,对于大数据组件安装启动、暂停、恢复和删除来说,传统大数据管理平台启动大数据组件时,一般有以下流程:
51.步骤a,选择主机:选择需要安装的主机;
52.步骤b,下载:下载大数据组件安装包;
53.步骤c,分发配置:统一分发大数据配置文件;
54.步骤d,启动顺序控制:调用启动脚本,按顺序启动各个组件。
55.这种方式只能在一个集群安装单一版本的大数据实例,无法满足用户多版本多实例的要求。
56.本大数据组件管理平台基于kubernetes特性,大数据组件完全封装进docker中,使用kubernetes中的不同类型的控制器进行部署,kubernetes可以同时部署多个不同类型的控制器,因此可以部署多实例多版本的大数据组件。具体流程如下:
57.步骤s11,选择主机:基于kubernetes nodeselector或者pv绑定主机,实现主机选择。
58.步骤s12,下载:将大数据组件封装成docker镜像,上传到镜像服务器。将需要安装的大数据组件定义为kubernetes的一种控制器,具体方式就是编写kubernetes可以解析的yaml文件用于安装大数据组件。用户安装时大数据管理平台会解析yaml文件,启用yaml文件中定义的控制器,并下载文件里配置的大数据组件docker镜像。
59.步骤s13,分发配置:大数据组件管理平台通过kubernetes中的configmap实现大数据组件的配置映射同步配置。具体实现方式有以下几种:1、将环境变量直接定义在configmap中,kubernetes控制器启动时通过env引用configmap中定义的环境变量。2、将一个完整的配置文件直接封装在configmap中,然后通过共享卷的方式挂载到kubernetes控制器启动的pod中,实现给应用传参。
60.步骤s14,启动顺序控制:大数据组件实例彼此之间存在着关联关系,有次序、角色方面的相关性。所以大数据组件启动时要按照模块间依赖关系按顺序启动。只有基于kubernetes有状态控制器statefulset机制才可以实现组件顺序启动,具体原理:statefulset控制器为每个大数据组件的实例提供稳定且唯一的网络标识符,稳定且持久的存储,有序、优雅地部署和扩展,有序、优雅地删除和终止,有序而自动地滚动更新。稳定的含义就是大数据组件实例重启后,控制器生成的容器主机名称不会改变,其绑定的后端
存储也不会丢失。因此利用这种特性可以实现大数据组件在管理平台上的顺序启动。
61.步骤s15,多实例管理:大数据组件启动后,会作为kubernetes的一中控制器的负载进行管理。kubernetes支持多个控制器单独部署,只要在同一命名空间内名称不同即可。基于上述能力,可以实现大数据组件的多实例管理。
62.大数据组件管理平台支持大数据组件的暂停,组件暂停时,进程停止运行,但是运行状态需要保存,需要记录之前所在的主机以及组件之前的配置信息,以便再次启动时恢复。基于kubernetes的具体实现方式为:
63.步骤21,kubernetes根据当前工作负载的数量自动调整。所有工作负载都会停止运行,但是停止前的运行状态和配置信息都会保留,具体实施方式是基于kubernetes api
‑
server记录工作负载原来状态,并新建一种crd资源,记录负载命名空间、负载名称、负载数量等并保存在kubernetes中。
64.步骤22,组件暂停时需要停止工作负载,但是要保留运行状态,无法直接调用kubernetes进行删除操作。本发明基于kubernetes statefulset的机制,将工作负载的数量调整为0,实现暂停的效果。
65.组件恢复时,根据需要恢复的组件名称等从kubernetes crd资源中取出组件原来的信息,基于kubernetes statefulset控制器机制调整负载数量至原来数量。恢复操作完成。
66.大数据组件管理平台支持对已安装的组件进行删除操作:删除操作需要停止所有组件工作负载的运行,并且不需要保留运行状态,所以可以直接使用kubernetes删除控制器,进而删除控制器管理的资源对象,达到删除组件的目的。
67.对于上述技术而言,在一个实施例中,以hadoop为例:高可用hadoop集群各模块启动时使用kubernetes statefulset进行控制,确保pod启动的顺序并为每个pod维持一个唯一且固定的标识符。hadoop组件启动时调用kubectl发送请求到kube
‑
apiserver,kube
‑
apiserver调用etcd v3里的statefulsets接口将启动信息存储到etcd中并返回给kubelet。kubelet接收到信息调用kube
‑
apiserver从etcd中取出需要创建的pod信息,拉取镜像,启动容器。待各模块pod都启动且状态为active后,启动完成。
68.大数据组件暂停时,首先调用自定义api将pod信息存储到kubernetes crd中。保存状态完成后,调用kube
‑
apiserver中的statefulset scale api对pod安装序号从大到小的顺序进行缩容,直至pod数量为0,暂停操作完成。
69.大数据组件恢复时,首先调用api从kubernetes crd中取出需要恢复的组件信息,然后调用kube
‑
apiserver中的statefulset scale api对pod进行扩容,直至pod数量恢复至停止前数量,恢复操作完成。
70.对于大数据组件配置同步来说,大数据管理平台中的组件通过kubernetes中的configmap进行配置同步。使用configmap同步配置文件主要使用两种方式:1、将环境变量直接定义在configmap中,pod启动时通过env引用configmap中定义的环境变量。2、将一个完整的配置文件直接封装在configmap中,然后通过共享卷的方式挂载到pod中,实现给应用传参。
71.可以通过大数据管理平台界面修改大数据组件的configmap,kubernetes控制器控制的容器重启后会自动挂载最新的configmap同步修改后的配置文件。
72.如图4所示,对于大数据组件日志收集来说,传统大数据管理平台的日志收集一般需要指定到各个大数据组件日志目录,然后收集日志。
73.本大数据管理平台上运行的组件都是docker封装的形式,基于kubernetes和docker特性,不需要指定大数据组件具体日志路径,就可以收集到全部大数据组件的日志。收集日志主要有以下几种方式:1、基于kubernetes daemonset控制器的特性会在每个kubernetes nodes上启动一个工作负载,所以使用kubernetes daemonset控制器的方式启动日志收集模块fluentd,统一收集所有大数据组件容器产生的日志,在kubernetes每个node上启动一个fluentd,收集docker的日志,从而收集所有大数据组件的日志。2、在大数据组件的工作负载中集成一个日志收集容器,使用emptydir的共享卷方式让日志收集容器读取到大数据组件产生的日志。然后发送日志到指定目标。
74.对于大数据组件监控来说,大数据组件管理平台基于kubernetes机制提供对部署其上的组件进行统一监控。大数据组件管理平台通过部署node_exporter、大数据组件的自定义exporter和metric
‑
server实现对所有kubernetes node和部署其上的大数据组件pod的当前资源使用情况的信息收集,如kubernetes node的平均负载、cpu、内存、磁盘、网络等等多个维度的指标数据和pod使用内存和cpu等信息。大数据组件管理平台通过部署prometheus从exporter中拉取监控数据并存储。使用kube
‑
state
‑
metrics将prometheus拉取到的数据转换成kubernetes可以识别的数据类型。大数据组件管理平台集成了grafana对监控信息进行可视化展示,并且集成了alertmanager实现监控报警,可以通过邮件、短信等方式及时通知运维人员,以便实时了解并处理大数据组件管理平台上所有组件的运行情况。
75.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1