一种基于递归神经网络模型的代码注释生成方法
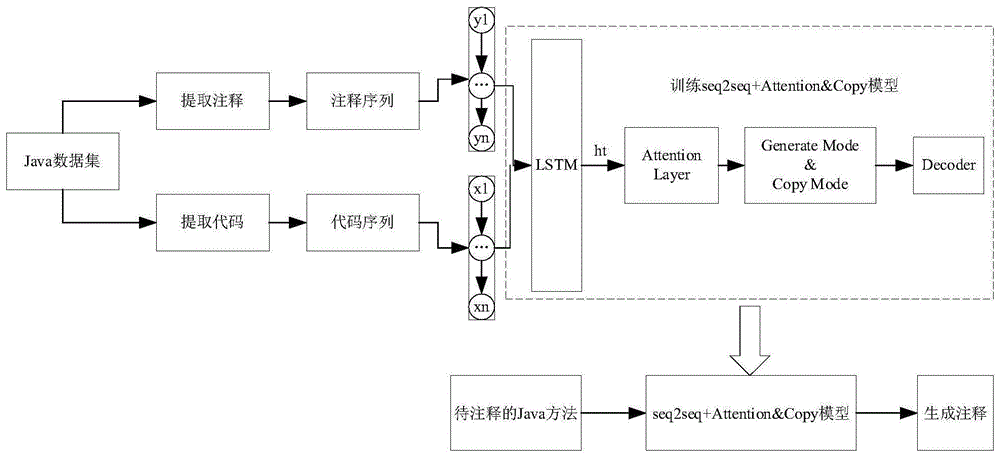
本发明属于机器学习技术领域,具体涉及一种基于递归神经网络模型的代码注释生成方法。
背景技术:
随着软件项目规模的增加,开发人员越来越难以理解代码,代码注释对程序理解很有帮助。不幸的是,由于紧迫的开发进度或许多项目中的其他原因,代码注释可能经常会丢失,不匹配或过时,自动代码注释生成不仅可以帮助开发人员理解源代码,还可以节省编写注释所需的时间。
代码注释生成的过程类似于机器翻译过程,但是,与机器翻译相比,代码注释生成更具挑战性,因为存在两个主要挑战:(1)源代码是结构化的:用编程语言编写的源代码是结构化且明确的;(2)词汇:自然语言语料库的词汇量通常限制为30,000个单词,但是在java代码语料库中,获得794,711个唯一标记,如果将常用的30,000个令牌用作词汇表,则大约95%的标识符将被视为未知令牌,即“unk”,因此不适合目前的任务。
技术实现要素:
本发明要解决的技术问题是提供一种基于递归神经网络模型的代码注释生成方法,不仅可以帮助开发人员理解源代码,还可以节省编写注释所需的时间。
为解决上述技术问题,本发明的实施例提供一种基于递归神经网络模型的代码注释生成方法,包括如下步骤:
s1、使用scrapy从开源社区上爬取评分高的代码项目,获得java数据集;
s2、对步骤s1获得的java数据集进行筛选和处理,对于一些简单的注释和方法进行剔除,优化java数据集;
s3、将步骤s2处理过的java数据集输入seq2seq+attention©模型中,进行信息编码;
s4、将步骤s3输出的信息编码输入attention机制层和copy机制层得到上下文向量;
s5、将信息编码和上下文向量输入解码层,生成输出代码注释。
其中,步骤s1的具体步骤为:
s1.1、根据github上的编程语言流行指标,选择排名靠前的java语言作为代码注释的目标;
s1.2、从github上爬取评分较高的java项目,获得java数据集。选取高评分的java项目可以避免一些错误和简单的java项目,提高数据集的质量,可以保证训练模型时的数据的准确性。
其中,步骤s2的具体步骤为:
s2.1、对获得的java数据集进行筛选和处理:在每个存储库中选择具有相应javadoc的java方法,并将javadoc中的第一句话用作java方法的目标注释;
s2.2、优化java数据集:省略java数据集中基本测试方法的注释和方法,;手动检查处理后的样本,并省略覆盖方法以减少重复,分别得到方法序列和注释序列;
其中,步骤s3的具体步骤为:
s3.1、在对数据集进行预处理之后,得到的方法序列生成抽象语法树ast:第一步进行词法分析,读取代码从java方法中提取tokens,标记化方法体,使用camelcase分类每个token并且删除重复的token,最后将代码分割成一个tokens列表;第二步进行语法分析,将词法分析所得到的tokens列表转化成树形的表达形式;
s3.2、使用一种平衡二叉搜索树avl来遍历抽象语法树ast,具体采用前序遍历的方法对抽象语法树(ast)进行遍历。查找token节点类型中代码词典,生成代码序列;
对于每一个结点调用insert()函数,在执行完insert()操作后,avl的性质不满足,再调用maintain()函数来修复avl;
s3.3、调用serialize()函数对ast进行序列化操作,将得到的ast序列输入到seq2seq模型之中;
s3.4、seq2seq模型的主流是编码器-解码器架构,并且融入attention机制和copy机制,编码器是一个两层双向lstm网络,解码器是一个单层lstm网络,对于给定的输入x=(x1,x2,…,xt),在t时刻的状态信息xt和上一状态隐含状态st-1经过长短记忆神经网络lstm模型,生成当前隐含状态序列st和状态信息xt的编码输出ht。
进一步,步骤s3.4的具体步骤为:
s3.4.1、假设eij为当前隐藏状态序列si-1和上一状态信息的编码输出hj的匹配程度的记号,计算公式如下:
eij=a(si-1,hj)式(ⅰ),
其中,si-1为第i-1位置的隐藏状态序列,hj为第j位置状态信息的编码输出;
s3.4.2、定义α为归一化概率权重,表示输入的第j个信息和当前输出的关系概率:
其中,eij为si-1和hj之间匹配程度的记号;
s3.4.3、权重α和编码输出hj之间的匹配程度得到上下文向量c,c的计算公式如下:
其中,αij为归一化概率权重,hj为第j时刻的编码输出。
s3.4.4、为了解决得到的上下文向量c中出现的未知词汇(oov),融入copy机制。采用generate-mode©-mode两个模式,对未知词汇(oov)采用直接copy-mode的方式从源代码词汇中直接复制词汇,来缓解未知词汇的问题,提高上下文向量c中的有效词汇,对于已有的词汇采用generate-mode模式直接从词汇中生成。最后,将generate-mode©-mode输出的概率进行加和,作为最终词的概率分布;
其中,步骤s5中将信息编码和上下文向量输入解码层,由源代码注释和序列概率分布生成输出序列,概率分布计算公式如下:
p(yt|y1,y2,…,yt-1,c)=g(yt-1,hi,c)式(ⅳ),
其中,yt为t时刻预测的结果,c为上下文向量,hi为第i个时刻的编码输出,g()为yi时刻的概率。
本发明的上述技术方案的有益效果如下:本发明提出了一种全新的代码注释方法,以同时分析抽象语法树(ast)和源代码,分别从ast和源代码中学习语法和词汇信息,ast转换为序列,然后再输入到模型中;新的基于结构的遍历(avl)方法来遍历ast,为了解决词汇挑战,,分析了标识符的组成并发现标识符通常由多个单词组成,例如toint→{to,int},用于表示变量或方法的功能。本发明中,自动代码注释生成不仅可以帮助开发人员理解源代码,还可以节省编写注释所需的时间。
附图说明
图1为本发明的流程图;
图2为本发明中一个具体方法的源代码图;
图3为本发明中ast抽象语法树提取方法实例示意图;
图4为本发明中avl前序遍历算法图;
图5为本发明中seq2seq模型示例图;
图6为本发明中模型效果图;
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明提供了一种基于递归神经网络模型的代码注释生成方法(如图1所示),主要用于解决开发人员节省编写注释所需的时间。
一、java数据集获取
java代码语料库的获取,使用scrapy从开源社区上爬取评分高的代码项目,获得java代码语料库,具体步骤如下:
s1.1、根据github上的编程语言流行指标,选择排名靠前的java语言作为代码注释目标;
s1.2、从github上爬取评分较高的java项目,获得java数据集,选取高评分的java项目可以避免一些错误和简单的java项目,提高数据集的质量,可以保证训练模型时的数据的准确性。
二、java数据集进行筛选和处理
对获得的java数据集进行筛选和处理,对于一些简单的注释和方法进行剔除,优化java数据集;具体步骤如下:
s2.1、对获得的java数据集进行筛选和处理:在每个存储库中选择具有相应javadoc的java方法,并将javadoc中的第一句话用作java方法的目标注释,因为注释中的第一句话通常表明该方法的含义。
s2.2、优化java数据集:省略java数据集中基本测试方法的注释和方法,;手动检查处理后的样本,并省略覆盖方法以减少重复。然后手动检查处理后的样本,并省略覆盖方法以减少重复;在对数据集进行预处理之后,得到487,168个注释向量和代码向量组。
三、java数据集输入seq2seq+attention©模型
将处理过的java数据集输入seq2seq+attention©模型中,进行信息的编码;具体步骤如下:
s3.1、在对数据集进行预处理之后,得到的方法序列生成抽象语法树ast,如图2,3是其中一个方法的源代码和ast抽象语法树提取的实例:第一步进行词法分析,读取代码从java方法中提取tokens,标记化方法体,使用camelcase分类每个token并且删除重复的token,最后将代码分割成一个tokens列表;第二步进行语法分析,将词法分析所得到的tokens列表转化成树形的表达形式;
s3.2、使用一种平衡二叉搜索树avl来遍历抽象语法树ast,具体采用前序遍历的方法对抽象语法树(ast)进行遍历,如图4是前序遍历方法的具体代码。查找token节点类型中代码词典,生成代码序列;
对于每一个结点调用insert()函数,在执行完insert()操作后,avl的性质不满足,再调用maintain()函数来修复avl;
s3.3、调用serialize()函数对ast进行序列化操作,将得到的ast序列输入到seq2seq模型之中;
s3.4、seq2seq模型的主流是编码器-解码器架构(如图5是seq2seq模型实现自动预测的一个实例),并且融入attention机制和copy机制,编码器是一个两层双向lstm网络,解码器是一个单层lstm网络,对于给定的输入x=(x1,x2,…,xt),在t时刻的状态信息xt和上一状态隐含状态st-1经过长短记忆神经网络lstm模型,生成当前隐含状态序列st和状态信息xt的编码输出ht。
四、输入attention©层
输入attention机制层,将隐含状态序列st和状态信息xt的编码输出ht输入attention机制层;具体步骤为:
s3.4.1、假设eij为当前隐藏状态序列si-1和上一状态信息的编码输出hj的匹配程度的记号,计算公式如下:
eij=a(si-1,hj)式(ⅰ),
其中,si-1为第i-1位置的隐藏状态序列,hj为第j位置状态信息的编码输出;
s3.4.2、定义α为归一化概率权重,表示输入的第j个信息和当前输出的关系概率:
其中,eij为si-1和hj之间匹配程度的记号;
s3.4.3、权重α和编码输出hj之间的匹配程度得到上下文向量c,c的计算公式如下:
其中,αij为归一化概率权重,hj为第j时刻的编码输出。
s3.4.4、为了解决得到的上下文向量c中出现的未知词汇(oov),融入copy机制。采用generate-mode©-mode两个模式,对未知词汇(oov)采用直接copy-mode的方式从源代码词汇中直接复制词汇,来缓解未知词汇的问题,提高上下文向量c中的有效词汇,对于已有的词汇采用generate-mode模式直接从词汇中生成。最后,将generate-mode©-mode输出的概率进行加和,作为最终词的概率分布。
五、生成代码注释
将信息编码和上下文向量输入解码层,生成输出代码注释,由源代码注释和序列概率分布生成输出序列,概率分布计算公式如下:
p(yt|y1,y2,...,yt-1,c)=g(yt-1,hi,c)式(ⅳ),
其中,yt为t时刻预测的结果,c为上下文向量,hi为第i个时刻的编码输出,g()为yi时刻的概率。
六、seq2seq+attention©模型训练效果
在代码语料库中我们共获得487,168个方法与注释向量组,抽象语法树的序列维度限制在300维度,最优梯度下降算法的梯度为90,所得到的结果能处理大量的unk未知词汇,代码注释的准确性也与传统方法比较起来得到提升。如图6根据本发明的方法对代码进行注释,图中注释能够准确的描述代码功能。
本发明中的基于递归神经网络模型的代码注释生成方法具有较高代码注释的准确率,能有效节约软件开发人员和维护人员注释代码的时间。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!