一种针对信号调制类型分类的鲁棒性评估和分析方法及系统
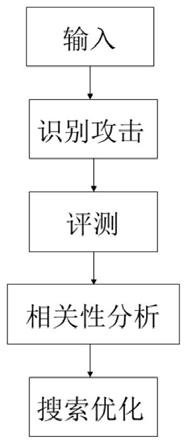
1.本发明涉及无线电调制分类模型安全领域,特别是涉及一种针对信号调制类型分类的鲁棒性评估和分析方法及系统。
背景技术:
2.现如今深度学习模型的鲁棒性和安全性成为一个大问题,这自然就迫切需要分析和验证深度学习模型的行为,以确保它们在实际部署中的可靠性和安全性。分析模型的良好性能表明了深度学习模型的鲁棒性和通用性。对于最先进的深度神经网络,能够很好的完成各项识别任务,这种网络可以对输入的扰动具有鲁棒性,即因为细小的扰动不能改变图像的任意类别。然而,对抗样本在不可察觉的非随机扰动下,可以任意改变网络的预测值,同时我们发现对抗样本是相对鲁棒的,能够在不同层数,不同激活函数,不同训练方式,不同的训练样本集上的dnn模型共享,即我们用一个神经网络生成一组对抗样本,在不同的模型上也会表现出对抗样本的特性,也就是说dnn模型具有非直观的特性和固有的盲点,其结构与数据分布的关系不明显。对于对抗性攻击样本的存在,一个普遍接受的解释是,它们在自然图像的多个区域之外运行,模型在训练期间没有接触到这些区域,因此它的行为可以被任意操纵。图像数据一般为二维数据,而信号数据一般为一维时序数据,虽然它们的本质含义有着很大的差别。可以尝试将图像领域的攻击方法应用于无线电信号领域。信号分类模型的鲁棒性分析也引起了很多通信学者的关注
3.已有专利:
4.申请号为202010799032.8的专利所公开的技术方案,人工智能图像分类模型的鲁棒性评估和增强系统,其包括白盒评估模块,黑盒评估模块和防御增强模块,通过多种鲁棒性评估指标优化鲁棒性评估流程,通过内置的多种技术对模型进行防御。其采用的指标不够全面,没有涉及到模型内部神经元相关的测试指标,没有对多维指标进行分析和整合,没有给出一个直观评价。本专利基于信号领域,提出基于特征子空间的一系列指标,丰富了整个指标体系。整合神经元相关的测试指标,模型结构相关的鲁棒性指标,攻击相关的攻击指标得到对于模型鲁棒性的综合评价,经过指标之间的相关性分析,筛选掉部分相关性极高的指标,经过随机森林的机器学习算法,生成模型鲁棒性的判定准则,评价报告和直观评价。
5.针对鲁棒性分析的工作,当下在图像领域已经有较为完善的分析方法,但针对信号领域的领域非常少。
技术实现要素:
6.本发明要提供一种针对信号调制类型分类的鲁棒性评估和分析方法及系统,以解决上述现有技术存在的问题,使能在信号领域通过全面的指标分析分类模型的鲁棒性。
7.为实现上述目的,本发明提供如下方案:
8.本发明提供一种针对信号调制类型分类的鲁棒性评估和分析方法及系统,包括以
下步骤:
9.s1:使用无线电信号作为样本数据,选取最新的深度学习模型,选取最新的深度学习模型攻击方法,将生成的对抗样本和原始样本一一对应保存;
10.s2:将原始样本输入不同参数,结构的模型得到特征子空间指标;
11.s3:将原始样本和攻击样本输入模型得到攻击驱动的攻击指标,将原始样本直接输入模型根据不同神经元激活情况,得到模型本身的测试指标,通过对原始模型的不同层进行计算得到模型本身的鲁棒性指标;
12.s4:通过指标相关性分析,筛选掉相关性过高的指标,并把输出的指标保存下来;
13.s5:将输出指标分为训练集和验证集,训练随机森林模型,优化模型参数,制作鲁棒性评价分析模块。
14.进一步的,所述步骤s1具体包括:
15.s1.1:使用无线电信号作为样本数据:
16.本发明使用两种无线电信号数据集进行评估,rml2016.10a:数据集为爱丁堡大学公开的调制信号数据集,它使用gnu radio合成信号样本,它包含11种调制类型,信号信噪比(snr,signal
‑
to
‑
noise ratio)范围从
‑
20db到18db,间隔2db均匀分布。每个无线电信号样本的尺寸为128x2,训练集样本数为176000,测试集样本数为44000。sig2019
‑
12:数据集由团队仿真生成,并在仿真时考虑了一个真实通信系统存在的一些影响,它包含12种调制类型:bpsk、qpsk、8psk、oqpsk、2fsk、4fsk、8fsk、16qam、32qam、64qam、4pam和8pam。原始信息数据以随机方式产生,从而保证传输比特等概率取值。脉冲成形滤波器采用升余弦滤波器,滚降系数在[0.2,0.7]范围内随机取值。相位偏差在[
‑
π,π]范围内随机取值,归一化载波频偏(相对于采样频率)在[
‑
0.1,0.1]范围内随机选择。snr范围从
‑
20db到30db,间隔2db均匀分布。每个数据样本包含64个符号,每个符号的采样点数为8,因此每个样本的采样点数为512。训练集和测试集的大小分别为312,000和156,000,每类调制信号样本量相同;
[0017]
s1.2:选取最新的信号调制类型分类模型包括1d_cnn,2d_cnn,alexnet,nin模型;
[0018]
s1.3:选取最新的深度学习模型攻击方法包括jsma,pgd,deepfool攻击方法,将生成的对抗样本和原始样本一一对应保存。
[0019]
进一步的,所述步骤s2具体包括:
[0020]
s2.1:根据模型的不同层,生成不同类的样本特征子空间:
[0021]
本发明将样本批量输入到不同的模型中,取出不同模型不同层的输出,若数据维度大于label维度,使用tsne使数据降维到label维度,tsne的方法可以使得高维映射到低维的同时,保证相互之间的分布概率不变,将降维后的数据按照训练时的真实标签保存到样本特征子空间数组中。
[0022]
s2.2:根据样本特征子空间计算特征子空间指标:
[0023]
本发明设计了三种特征子空间指标:fsa(同类数据特征子空间聚合度),
[0024]
[0025][0026]
上述公式1中,n表示特征子空间数组的标签维度,p
i
表示这个特征子空间内在i标签维度的向量,p
ci
是通过计算所有同一真实标签下的特征子空间数据行的平均值数据行中在i标签维度的向量,dist表示同类特征子空间向量与此类中心向量之间的距离,dist
k
表示任取一个同类特征子空间向量与此类中心向量之间的距离,其归一化后取平均之后的值得到fsa(同类特征子空间聚合度);
[0027][0028][0029]
上述公式3中,n表示特征子空间数组的标签维度,p
c1i
表示真实标签属于c1类的中心向量在i标签维度的向量,p
c2i
表示真实标签属于c2类的中心向量在i标签维度的向量,dist
c
表示c1类中心向量和c2类中心向量之间的距离,dist
ck
表示任取两类的中心向量之间的距离,其归一化后取平均得到fsd(不同类特征子空间距离);
[0030]
dist
r
=dist
t
+dist
u
‑
dist
c
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0031][0032]
上述公式5中,dist
t
表示任取的随机的特征子空间数组中的一行数据行与该类中心向量之间的距离,dist
u
不与dist
t
同属一类特征子空间数组中的一行数据行与该类中心向量之间的距离,dist
r
表示dist
t
类中心向量和dist
u
类中心向量之间的距离,dist
rk
表示任取特征子空间数组的一行数据行相对于两个类的中心向量之间的距离,并减去两个类中心向量之间的距离,其归一化后取平均得到fsc(特征子空间重合度)。
[0033]
进一步的,所述步骤s3的具体包括:
[0034]
s3.1:将原始样本和攻击样本输入模型计算攻击驱动的攻击指标:
[0035]
所述的攻击指标具体包括:攻击成功率mr,对抗样本攻击成功后最大类预测值acac,对抗样本攻击后真实标签的预测值actc,对抗样本与原样本距离ald,对抗样本与原样本结构相似程度ass,对抗样本的扰动敏感距离psd,对抗样本抗扰动nte,对抗样本对高斯噪声的鲁棒程度评估rgb,其中mr指标表示不同攻击对模型的有效性,是一个直观指标,有丰富的理论依据;acac指标寻找攻击前后最大类的上界,一类广泛使用的合理判据;actc指标寻找攻击前后真实标签类的变化情况,通用性强;ald指标衡量对抗样本与原样本之间的距离;ass从结构分析攻击前后样本的变化程度;psd指标衡量触发标签变化的最小攻击扰动;nte指标衡量从置信度分析样本的抗扰动能力;rgb衡量高斯噪声对标签分类的影响。
[0036]
s3.2:将原始样本直接输入模型根据不同神经元激活情况,得到模型本身的测试指标:
[0037]
所述的测试指标包括:神经元覆盖率nc,k多节神经元覆盖率knc,神经元边界覆盖率nbc,基于可能性的意外充分性lsa,基于距离的意外充分性dsa,其中nc指标表示统计样本输入模型后,模型激活神经元与所有神经元的比值;knc指标表示样本输入模型后,不同
层超过阈值的神经元与所有神经元的比值;nbc指标表示样本输入模型后,超过阈值的上下边界除以所有边界;lsa指标表示使用高斯核函数计算输入和测试输入之间激活迹的差值;dsa指标表示在类不相同的用例之间寻找到最小距离的比。
[0038]
s3.3:将原始样本直接输入模型得到基于模型本身的鲁棒性指标:
[0039]
所述的鲁棒性指标包括:利普希茨常数(lipschitz constant),cl(clver score),其中利普希茨常数衡量模型对对抗样本的敏感性;cl指标计算给定输入被错误分类的最小扰动,与攻击无关,有丰富的理论依据。
[0040]
进一步的,所述步骤s4具体包括:
[0041]
s4.1:选取两种相关性算法,计算不同指标之间的相关性:
[0042]
选取kendall相关系数作为衡量指标之间相关性的方法,kendall系数是一个用来测量两个随机数相关性的统计值,将保存好的指标csv文件进行kendall相关系数计算。
[0043]
s4.2:根据指标之间的相关性,筛选出相关性值较高的两两指标,选取其中一个指标,并把结果保存下来:
[0044]
当相关系数大于0.8,或小于
‑
0.8时,那么表示这指标之间存在很强的相关性,对后续的分类可能造成过拟合等不良影响,除去掉两两相关性高于0.8或小于
‑
0.8两列中的一列,并将筛选后的指标保存下来。
[0045]
进一步的,所述s5具体步骤为:
[0046]
s5.1将输出指标分为训练集和验证集,设计经验损失函数:
[0047]
将输出指标按照2:1的比例划分训练集与验证集,保证训练集中鲁棒模型指标和不鲁棒模型指标相同。按照指标体系的输出指标,设计经验损失函数,使得鲁棒模型和不鲁棒模型的指标分布相距更远。本发明提出的经验损失函数如下:
[0048][0049]
公式(7)中,η1为1,η2为0.7,η3为0.5,η4为0.5,loss
特
表示特征子空间指标,loss
鲁
表示鲁棒性指标,loss
测
表示测试指标,loss
攻
表示攻击指标。
[0050]
s5.2优化模型参数,训练随机森林模型:
[0051]
本发明先通过不断迭代随机森林决策树数量这一重要参数,使得上述的经验损失函数更大,鲁棒模型和不鲁棒模型的指标分布相距更远;之后使用网格迭代法寻优,找到决策树深度,最大分叉树等一系列参数的最优解,进一步扩大指标的分布距离。
[0052]
实施本发明的一种针对信号模型分类的鲁棒性评估和分析方法的系统,包括识别攻击模块,评测模块,相关性分析模块,搜索优化模块:
[0053]
所述识别攻击模块,选取爱丁堡大学公开的调制信号数据集rml2016.10a作为使用数据集,选取最新的深度学习模型包括1d_cnn,2d_cnn,alexnet,nin模型,选取最新的深度学习模型攻击方法包括jsma,pgd,deepfool攻击方法,将信号数据输入到深度学习模型中得到其调制分类,并保存中间层的神经元输出。用攻击方法在以及训练好的模型上生成攻击样本,保存所述模型和攻击样本。
[0054]
所述评测模块,输入保存的模型和中间层结果计算模型的测试指标和特征子空间指标,输入保存的模型和对应的模型结构评测模型的鲁棒性指标,输入保存的模型和对应
的攻击样本评测模型的攻击驱动指标,并将上述评测的指标保存成字典形式。
[0055]
所述相关性分析模块,输入指标字典,选取kendall相关性算法,计算不同指标之间的相关性。根据指标之间的相关性,筛选出相关性值较高的两两指标,选取其中一个指标,并把结果保存下来;
[0056]
所述搜索优化模块,将输出指标按照2:1的比例划分训练集与验证集,保证训练集中鲁棒模型指标和不鲁棒模型指标相同。不断迭代随机森林决策树数量这一重要参数,使得上述的经验损失函数更大,鲁棒模型和不鲁棒模型的指标分布相距更远。之后使用网格迭代法寻优,找到决策树深度,最大分叉树参数的最优解,进一步扩大指标的分布距离。
[0057]
所述识别攻击模块,所述评测模块,所述相关性分析模块,所述搜索优化模块依次链接。
[0058]
本发明公开了以下技术效果:
[0059]
1.本发明不需要使用信号数据的各种先验知识,在信号调制类型分类模型的脆弱性分析具有普适性。
[0060]
2.本发明将图像的模型分析方法引入信号领域,根据信号的特点对指标进行修改,使得其可以分析信号分类模型的性质。
[0061]
3.模型的分析过程中,很难有一个确切的标准去评价模型的鲁棒性,针对目前主流的攻击驱动的评价指标可能存在不全面的弊端,本发明提出了基于特征子空间的一系列指标,整合神经元相关的测试指标,模型结构相关的鲁棒性指标,构成多方位评价模型的指标评价体系。
[0062]
4.损失函数由四部分组成,使得鲁棒模型和不鲁棒模型的指标分布相距更远。提出的经验损失函数如下:
[0063][0064]
其中η1为1,η2为0.7,η3为0.5,η4为0.5,loss
特
表示特征子空间指标,loss
鲁
表示鲁棒性指标,loss
测
表示测试指标,loss
攻
表示攻击指标。可以通过不断迭代随机森林决策树数量这一重要参数,使得上述的经验损失函数更大,鲁棒模型和不鲁棒模型的指标分布相距更远。之后使用网格迭代法寻优,找到决策树深度,最大分叉树等一系列参数的最优解,进一步扩大指标的分布距离。
[0065]
5.本发明搭建了识别攻击、评测,相关性分析,搜索优化的鲁棒性分析方法,先对数据集进行识别和攻击,在识别和攻击的过程中,评测对应模型的属性和特征,对属性和特征进行筛选。根据损失函数搜索优化随机森林参数。
附图说明
[0066]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0067]
图1为一种针对信号模型分类的鲁棒性评估和分析方法流程图;
[0068]
图2为一种针对信号模型分类的鲁棒性评估和分析方法整体结构;
[0069]
图3为用户输入已有样本和模型的输入模块;
[0070]
图4为用户输入测试样本的输入模块;
[0071]
图5为评测和分析模块;
[0072]
图6为一种针对信号模型分类的鲁棒性评估和分析方法及系统;
具体实施方式
[0073]
现详细说明本发明的多种示例性实施方式,该详细说明不应认为是对本发明的限制,而应理解为是对本发明的某些方面、特性和实施方案的更详细的描述。
[0074]
应理解本发明中所述的术语仅仅是为描述特别的实施方式,并非用于限制本发明。另外,对于本发明中的数值范围,应理解为还具体公开了该范围的上限和下限之间的每个中间值,在任何陈述值或陈述范围内的中间值以及任何其他陈述值或在所述范围内的中间值之间的每个较小的范围也包括在本发明内。这些较小范围的上限和下限可独立地包括或排除在范围内。
[0075]
除非另有说明,否则本文使用的所有技术和科学术语具有本发明所属领域的常规技术人员通常理解的相同含义。虽然本发明仅描述了优选的方法和材料,但是在本发明的实施或测试中也可以使用与本文所述相似或等同的任何方法和材料。本说明书中提到的所有文献通过引入并入,用以公开和描述与所述文献相关的方法和/或材料。在与任何并入的文献冲突时,以本说明书的内容为准。
[0076]
在不背离本发明的范围或精神的情况下,可对本发明说明书的具体实施方式做多种改进和变化,这对本领域技术人员而言是显而易见的。由本发明的说明书得到的其他实施方式对技术人员而言是显而易见得的。本技术说明书和实施例仅是示例性的
[0077]
关于本文中所使用的“包含”、“包括”、“具有”、“含有”等等,均为开放性的用语,即意指包含但不限于。
[0078]
本发明中所述的“份”如无特别说明,均按质量份计。
[0079]
假设无线电信号数据集为o,选取的最新深度学习模型为cnn,选取最新的攻击方法为att,且无线电数据集分为iq两路数据存储。
[0080]
s1:使用无线电信号作为样本数据,选取最新的深度学习模型,选取最新的深度学习模型攻击方法,将生成的对抗样本和原始样本一一对应保存;
[0081]
s2:将原始样本输入不同参数,结构的模型得到特征子空间指标m
f
;
[0082]
s2.1:根据模型的不同层,生成不同类的样本特征子空间;
[0083]
s2.2:根据样本特征子空间计算特征子空间指标;
[0084]
s3:将原始样本和攻击样本输入模型得到攻击驱动的攻击指标m
a
,将原始样本直接输入模型根据不同神经元激活情况,得到模型本身的测试指标m
n
,通过对原始模型的不同层进行计算得到模型本身的鲁棒性指标m
l
;
[0085]
s3.1:将原始样本和攻击样本输入模型计算攻击驱动的攻击指标;
[0086]
s3.2:将原始样本直接输入模型根据不同神经元激活情况,得到模型本身的测试指标;
[0087]
s3.3:将原始样本直接输入模型得到基于模型本身的鲁棒性指标;
[0088]
s4:通过指标相关性分析,筛选掉相关性过高的指标,并把输出的指标保存下来。
[0089]
s4.1:选取两种相关性算法,计算不同指标之间的相关性;
[0090]
s4.2:根据指标之间的相关性,筛选出相关性值较高的两两指标,选取其中一个指标,并把结果保存下来。
[0091]
s5:将输出指标分为训练集和验证集,训练随机森林模型,优化模型参数,制作鲁棒性评价分析模块:
[0092]
s5.1将输出指标分为训练集和验证集,设计经验损失函数;
[0093]
s5.2优化模型参数,训练随机森林模型;
[0094]
所述步骤s1中,使用无线电信号数据集进行评估,rml2016.10a:数据集为爱丁堡大学公开的调制信号数据集,它使用gnu radio合成信号样本,它包含11种调制类型,信号信噪比(snr,signal
‑
to
‑
noise ratio)范围从
‑
20db到18db,间隔2db均匀分布。每个无线电信号样本的尺寸为128x2,训练集样本数为176000,测试集样本数为44000。sig2019
‑
12:数据集由团队仿真生成,并在仿真时考虑了一个真实通信系统存在的一些影响,它包含12种调制类型:bpsk、qpsk、8psk、oqpsk、2fsk、4fsk、8fsk、16qam、32qam、64qam、4pam和8pam。原始信息数据以随机方式产生,从而保证传输比特等概率取值。脉冲成形滤波器采用升余弦滤波器,滚降系数在[0.2,0.7]范围内随机取值。相位偏差在[
‑
π,π]范围内随机取值,归一化载波频偏(相对于采样频率)在[
‑
0.1,0.1]范围内随机选择。snr范围从
‑
20db到30db,间隔2db均匀分布。每个数据样本包含64个符号,每个符号的采样点数为8,因此每个样本的采样点数为512。训练集和测试集的大小分别为312,000和156,000,每类调制信号样本量相同;选取最新的信号调制类型分类模型包括1d_cnn,2d_cnn,alexnet,nin模型;选取最新的深度学习模型攻击方法包括jsma,pgd,deepfool攻击方法。将生成的对抗样本和原始样本一一对应保存。
[0095]
所述步骤s2.1中将样本批量输入到不同的模型中,取出不同模型不同层的输出,若数据维度大于label维度,使用tsne使数据降维到label维度,tsne的方法可以使得高维映射到低维的同时,保证相互之间的分布概率不变。将降维后的数据按照训练时的真实标签保存到样本特征子空间数组中。
[0096]
所述步骤s2.2中设计了三种特征子空间指标:fsa(同类数据特征子空间聚合度),
[0097][0098][0099]
上述公式(1)中,n表示特征子空间数组的标签维度,p
i
表示这个特征子空间内在i标签维度的向量,p
ci
是通过计算所有同一真实标签下的特征子空间数据行的平均值数据行中在i标签维度的向量,dist表示同类特征子空间向量与此类中心向量之间的距离,dist
k
表示任取一个同类特征子空间向量与此类中心向量之间的距离,其归一化后取平均之后的值得到fsa(同类特征子空间聚合度);
[0100][0101][0102]
上述公式3中,n表示特征子空间数组的标签维度,p
c1i
表示真实标签属于c1类的中心向量在i标签维度的向量,p
c2i
表示真实标签属于c2类的中心向量在i标签维度的向量,dist
c
表示c1类中心向量和c2类中心向量之间的距离,dist
ck
表示任取两类的中心向量之间的距离,其归一化后取平均得到fsd(不同类特征子空间距离);
[0103]
dist
r
=dist
t
+dist
u
‑
dist
c
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0104][0105]
上述公式(5)中,dist
t
表示任取的随机的特征子空间数组中的一行数据行与该类中心向量之间的距离,dist
u
不与dist
t
同属一类特征子空间数组中的一行数据行与该类中心向量之间的距离,dist
r
表示dist
t
类中心向量和dist
u
类中心向量之间的距离,dist
rk
表示任取特征子空间数组的一行数据行相对于两个类的中心向量之间的距离,并减去两个类中心向量之间的距离,其归一化后取平均得到fsc(特征子空间重合度)。
[0106]
所述的s3.1中,所述的攻击指标包括攻击成功率mr,对抗样本攻击成功后最大类预测值acac,对抗样本攻击后真实标签的预测值actc,对抗样本与原样本距离ald,对抗样本与原样本结构相似程度ass,对抗样本的扰动敏感距离psd,对抗样本抗扰动nte,对抗样本对高斯噪声的鲁棒程度评估rgb,其中mr指标表示不同攻击对模型的有效性,是一个直观指标,有丰富的理论依据;acac指标寻找攻击前后最大类的上界,一类广泛使用的合理判据;actc指标寻找攻击前后真实标签类的变化情况,通用性强;ald指标衡量对抗样本与原样本之间的距离;ass从结构分析攻击前后样本的变化程度;psd指标衡量触发标签变化的最小攻击扰动;nte指标衡量从置信度分析样本的抗扰动能力;rgb衡量高斯噪声对标签分类的影响。
[0107]
所述的s3.2中,测试指标包括:神经元覆盖率nc,k多节神经元覆盖率knc,神经元边界覆盖率nbc,基于可能性的意外充分性lsa,基于距离的意外充分性dsa,其中nc指标表示统计样本输入模型后,模型激活神经元与所有神经元的比值;knc指标表示样本输入模型后,不同层超过阈值的神经元与所有神经元的比值;nbc指标表示样本输入模型后,超过阈值的上下边界除以所有边界;lsa指标表示使用高斯核函数计算输入和测试输入之间激活迹的差值;dsa指标表示在类不相同的用例之间寻找到最小距离的比。
[0108]
所述的s3.3中,鲁棒性指标包括:利普希茨常数(lipschitz constant),cl(clver score),其中利普希茨常数衡量模型对对抗样本的敏感性,cl指标计算给定输入被错误分类的最小扰动,与攻击无关,有丰富的理论依据。
[0109]
所述的s4.1中,选取kendall相关系数作为衡量指标之间相关性的方法,kendall系数是一个用来测量两个随机数相关性的统计值,将保存好的指标csv文件进行kendall相关系数分析。
[0110]
所述的s4.2中,当相关系数大于0.8,或小于
‑
0.8时,那么表示这指标之间存在很强的相关性,对后续的分类可能造成过拟合等不良影响,除去掉两两相关性高于0.8或小
于
‑
0.8两列中的一列,并将筛选后的指标保存下来。
[0111]
所述的s5.1中,将输出指标按照2:1的比例划分训练集与验证集,保证训练集中鲁棒模型指标和不鲁棒模型指标相同。按照指标体系的输出指标,设计经验损失函数,使得鲁棒模型和不鲁棒模型的指标分布相距更远。本发明提出的经验损失函数如下:
[0112][0113]
上述公式(7)中,η1为1,η2为0.7,η3为0.5,η4为0.5,loss
特
表示特征子空间指标,loss
鲁
表示鲁棒性指标,loss
测
表示测试指标,loss
攻
表示攻击指标。
[0114]
所述的s5.2中,先通过不断迭代随机森林决策树数量这一重要参数,使得上述的经验损失函数更大,鲁棒模型和不鲁棒模型的指标分布相距更远。之后使用网格迭代法寻优,找到决策树深度,最大分叉树等一系列参数的最优解,进一步扩大指标的分布距离。
[0115]
实施本发明的一种针对信号模型分类的鲁棒性评估和分析方法的系统,包括识别攻击模块,评测模块,相关性分析模块,搜索优化模块:
[0116]
所述识别攻击模块,具体包括:
[0117]
s1.1:使用无线电信号作为样本数据:
[0118]
使用两种无线电信号数据集进行评估,rml2016.10a:数据集为爱丁堡大学公开的调制信号数据集,使用gnu radio合成信号样本,包含11种调制类型,信号信噪比(snr,signal
‑
to
‑
noise ratio)范围从
‑
20db到18db,间隔2db均匀分布;每个无线电信号样本的尺寸为128x2,训练集样本数为176000,测试集样本数为44000;sig2019
‑
12:数据集由团队仿真生成,并在仿真时考虑了一个真实通信系统存在的一些影响,包含12种调制类型:bpsk、qpsk、8psk、oqpsk、2fsk、4fsk、8fsk、16qam、32qam、64qam、4pam和8pam。原始信息数据以随机方式产生,从而保证传输比特等概率取值。脉冲成形滤波器采用升余弦滤波器,滚降系数在[0.2,0.7]范围内随机取值。相位偏差在[
‑
π,π]范围内随机取值,归一化载波频偏(相对于采样频率)在[
‑
0.1,0.1]范围内随机选择;snr范围从
‑
20db到30db,间隔2db均匀分布;每个数据样本包含64个符号,每个符号的采样点数为8,因此每个样本的采样点数为512;训练集和测试集的大小分别为312,000和156,000,每类调制信号样本量相同;
[0119]
s1.2:选取最新的信号调制类型分类模型包括1d_cnn,2d_cnn,alexnet,nin模型;
[0120]
s1.3:选取最新的深度学习模型攻击方法包括jsma,pgd,deepfool攻击方法,将生成的对抗样本和原始样本一一对应保存。
[0121]
所述评测模块,输入保存的模型和中间层结果计算模型的测试指标和特征子空间指标,输入保存的模型和对应的模型结构评测模型的鲁棒性指标,输入保存的模型和对应的攻击样本评测模型的攻击驱动指标,并将上述评测的指标保存成字典形式;具体包括:
[0122]
设计三种特征子空间指标:同类数据特征子空间聚合度fsa,
[0123]
[0124][0125]
上述公式(1)中,n表示特征子空间数组的标签维度,p
i
表示这个特征子空间内在i标签维度的向量,p
ci
是通过计算所有同一真实标签下的特征子空间数据行的平均值数据行中在i标签维度的向量,dist表示同类特征子空间向量与此类中心向量之间的距离,dist
k
表示任取一个同类特征子空间向量与此类中心向量之间的距离,其归一化后取平均之后的值得到同类特征子空间聚合度fsa;
[0126][0127][0128]
上述公式(3)中,n表示特征子空间数组的标签维度,p
c1i
表示真实标签属于c1类的中心向量在i标签维度的向量,p
c2i
表示真实标签属于c2类的中心向量在i标签维度的向量,dist
c
表示c1类中心向量和c2类中心向量之间的距离,dist
ck
表示任取两类的中心向量之间的距离,其归一化后取平均得到fsd(不同类特征子空间距离);
[0129]
dist
r
=dist
t
+dist
u
‑
dist
c
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0130][0131]
dist
t
[0132]
上述公式(5)中,dist
t
表示任取的随机的特征子空间数组中的一行数据行与该类中心向量之间的距离,dist
u
不与dist
t
同属一类特征子空间数组中的一行数据行与该类中心向量之间的距离,dist
r
表示dist
t
类中心向量和dist
u
类中心向量之间的距离,dist
rk
表示任取特征子空间数组的一行数据行相对于两个类的中心向量之间的距离,并减去两个类中心向量之间的距离,其归一化后取平均得到特征子空间重合度fsc。
[0133]
所述相关性分析模块,输入指标字典,选取kendall相关性算法,计算不同指标之间的相关性。根据指标之间的相关性,筛选出相关性值较高的两两指标,选取其中一个指标,并把结果保存下来;具体包括:
[0134]
s4.1:选取kendall相关性算法,计算不同指标之间的相关性;
[0135]
选取kendall相关系数作为衡量指标之间相关性的方法,kendall系数是一个用来测量两个随机数相关性的统计值,将保存好的指标csv文件进行kendall相关系数计算;
[0136]
s4.2:根据指标之间的相关性,筛选出相关性值较高的两两指标,选取其中一个指标,并把结果保存下来;
[0137]
当相关系数大于0.8,或小于
‑
0.8时,那么表示这指标之间存在很强的相关性,对后续的分类可能造成过拟合等不良影响,除去掉两两相关性高于0.8或小于
‑
0.8两列中的一列,并将筛选后的指标保存下来。
[0138]
所述搜索优化模块,将输出指标按照2:1的比例划分训练集与验证集,保证训练集中鲁棒模型指标和不鲁棒模型指标相同。不断迭代随机森林决策树数量这一重要参数,使得上述的经验损失函数更大,鲁棒模型和不鲁棒模型的指标分布相距更远。之后使用网格
迭代法寻优,找到决策树深度,最大分叉树参数的最优解,进一步扩大指标的分布距离。网格寻优法是一种常用的搜索算法,即在两个参数组成的平面上寻找最优解的算法;具体包括:
[0139]
s5.1将输出指标分为训练集和验证集,设计经验损失函数;
[0140]
将输出指标按照2:1的比例划分训练集与验证集,保证训练集中鲁棒模型指标和不鲁棒模型指标相同;按照指标体系的输出指标,设计经验损失函数,使得鲁棒模型和不鲁棒模型的指标分布相距更远;
[0141]
所述的经验损失函数如下:
[0142][0143]
上述公式(7)中,η1为1,η2为0.7,η3为0.5,η4为0.5,loss
特
表示特征子空间指标,loss
鲁
表示鲁棒性指标,loss
测
表示测试指标,loss
攻
表示攻击指标。
[0144]
s5.2优化模型参数,训练随机森林模型。先通过不断迭代随机森林决策树数量这一重要参数,使得上述的经验损失函数更大,鲁棒模型和不鲁棒模型的指标分布相距更远。之后使用网格迭代法寻优,找到决策树深度,最大分叉树等一系列参数的最优解,进一步扩大指标的分布距离。
[0145]
所述识别攻击模块,所述评测模块,所述相关性分析模块,所述搜索优化模块依次链接。
[0146]
本发明将图像的模型分析方法引入信号领域。提出了基于特征子空间的一系列指标,整合神经元相关的测试指标,模型结构相关的鲁棒性指标,构成多方位评价模型的指标评价体系。
[0147]
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1