一种基于机器视觉的基本苗统计方法
本发明涉及只能农业领域,具体为一种基机器视觉的基本苗统计方法。
背景技术:
基本苗是指单位面积上植株个体的总数,是诸多经济作物的重要指标[1]。基本苗的数目与不同生育期分蘖、叶龄、株高、次生根条数、干物质累积量、抽穗期叶面积和成穗有着密不可分的关系。由于基本苗的数目与苗木生长周期中的各个参数都有直接和间接的关系[2],所以对基本苗进行统计,是农业生产中必不可少的一个环节。然而,现有的基本苗统计的方法大多是通过农业作业者通过人工的方法测量,对于面积较小的农田人工的方法易于达到预期效果,但是对于面积较大的农田,此方法不仅会消耗大量的人力成本,测得的结果还会不准确。这样的统计方法需要大量的人工成本,而且人员在田间活动,可能会造成幼苗的损伤。
机器视觉是一种利用计算机模拟人类视觉的技术,广泛的用于图像信息的提取与物体识别。随着计算机算力的提高和视觉算法的不断发展和完善,机器视觉在越来越多的领域都扮演者重要的角色。在传统行业的现代化转型的过程中发挥重要作用。机器视觉在农业中的应用是最为成功的案例之一。机器视觉是促进农业信息获取的重要手段,在国内外的农业领域得到充分的发展,例如种子质量检测、无人机自主撒药、田间杂草识别、病虫害识别和种子优选等。
机器视觉对提高农业生产效率、促进农业生产质量有着重要的意义,可以预测农业产量和及时更改施肥策略从而改善产量。与工业机器视觉相比,机器视觉在农业中的应用环境情况更为复杂,这也是机器视觉在农业应用时应着重突破的技术难点。
技术实现要素:
本发明的目的在于提供一种基于机器视觉的基本苗统计方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明是通过以下技术方案实现的:
基本苗的数目与苗木生长周期中的各个参数都有直接和间接的关系,所以对基本苗进行统计,是农业生产中必不可少的一个环节。机器视觉是促进农业自动化的重要手段和方法,为了提高基本苗统计效率和精准度,本文设计了一种新的机器视觉统计方法。在基本苗统计的过程中,统计的目标多为绿色,与背景颜色差距较大,根据图像在hsv空间的良好性质确定兴趣区域,通过图像腐蚀与膨胀算法去除噪声获得利于提取的连通域达到最后统计的目标。本实验结果验证了基于机器视觉的水稻基本苗统计方法的有效性,与传统方法相比提高了统计效率。
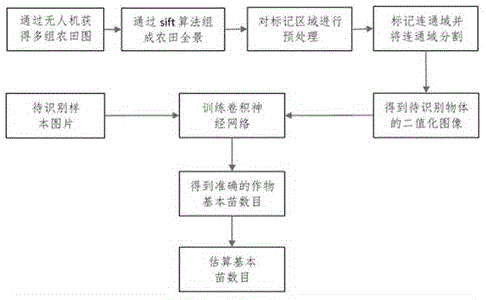
第一步,通过无人机搭载的照相机垂直于地面分块拍摄农田照片。
第二步,通过sift算法将分块拍摄的图片组合成一张高像素的农田整体图。
第三步,将整体图片通过色彩空间转换的方法,将原本处于rgb色彩空间的原始农田全景图转换为在hsv空间下的全景图。
rgb色彩空间转化为hsv色彩空间的数学模型如下所示:
色调(h)计算为:
饱和度(s)计算为:
明度(v)计算为:
其中
进一步的,将所得hsv空间图像通过查询hsv空间色彩阈值选择表进行二值化;
进一步的,对二值化分割出来的图像进行直方图统计,直方图中最大值对应的色域值
通过此计算,与原本直接查表选择阈值相比,可以大量过滤不必要的早点,更准确的定位兴趣区域;
第四步,利用卷积核再图像上进行滑窗操作,每次卷积取数值大小位于中间的替换原像素的值,这有利于去除类似与椒盐噪声的点状噪声信号;
第五步,hsv空间转化为二值化空间时,图像中不可避免的会出现影响统计结果的噪声信号,通过腐蚀和膨胀的操作使图像变得易于定位。通过原图根据上一步骤得到的位置信息截取图片;
第六步,通过收集的基本苗图片,训练改进的vgg-16卷积神经网络,在改进的vgg网络中那个,将每次降维的后的特征图重新整合,得到4含有不同尺度信息的混合特征图信息,这样兼顾了各个维度的特征信息。与原本的网络分类结果相比较,分类精准度提高了8个百分点;
第七步,截取的图像输入进神经网络若判断为真数量累加,反之忽略,最后得到准确数目。
附图说明
图1为基于机器视觉的基本苗统计方法的系统结构图;
图2为vgg-16网络结构图;
图3为hsv空间色彩阈值选择表。
具体实施方式
拍摄得到的图片进行特征点检测得到关键点,关键点是一些十分突出的不会因光照、尺度、旋转等因素而消失的点,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。此步骤是搜索所有尺度空间上的图像位置。通过高斯微分函数来识别潜在的具有尺度和旋转不变的兴趣点。在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。然后基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。通过构建图像高斯金字塔,hog空间极值检测,关键点方向分配,关键点描述并匹配,得到拼接图象
rgb色彩空间和hsv色彩空间所表示的是同一图像,但是为了区分opencv和其他的图像处理的python开源库,都将hsv空间图像以相应的三通道信息在rgb色彩空间中显示。考虑到水稻幼苗为绿色,所以我们只要提取绿色区域为我们的兴趣区域,通过查阅表3得到兴趣区域。这样得到的图像包含大量的孤立的脉冲噪声信号,通过中值滤波去除这些噪声得到的图象经过腐蚀和碰撞最后得到易于提取的连通域图。最后通过连通域提取得到结果,此步骤中值滤波的卷积窗口大小为7*7,腐蚀膨胀的卷积窗口为11*11。
彩色图像有rgb三个颜色通道,分别是红、绿、蓝三个通道,这三个通道的像素可以用二维数组来表示,其中像素值由0到255的数字来表示。比如一张160x60的彩色图片,可以用160*60*3的数组表示。在进行卷积操作的过程中,处于中间位置的数值容易被进行多次的提取,但是边界数值的特征提取次数相对较少,为了能更好的把边界数值也利用上,所以给原始数据矩阵的四周都补上一层0。在进行卷积操作之后维度会变少,得到的矩阵比原矩阵要小,不方便计算,原矩阵加上一层0的padding操作可以很好的解决该问题,卷积出来的矩阵和原矩阵尺寸一致。经过卷积操作后我们提取到的特征信息,相邻区域会有相似特征信息,这是可以相互替代的,如果全部保留这些特征信息会存在信息冗余,增加计算难度。通过池化层会不断地减小数据的空间大小,参数的数量和计算量会有相应的下降,这在一定程度上控制了过拟合。在训练过程中,按照一定的比例将网络中的神经元进行丢弃,可以防止模型训练过拟合的情况。vgg网络训练是batch为256,dropout比例设置为0.5,学习率初始化为0.01。本方法改进了原有的vgg,将每次降维的后的特征图重新整合,得到4含有不同尺度信息的混合特征图信息(图2),这样兼顾了各个维度的特征信息。与原本的网络分类结果相比较,分类精准度提高了8个百分点。
- 还没有人留言评论。精彩留言会获得点赞!