一种基于深度学习的轻量级超分辨率图像重建方法
1.本发明属于人工智能领域,涉及一种基于深度学习的轻量级超分辨率图像重建方法。
背景技术:
2.近年来,基于深度学习方法的图像超分辨率算法取得了卓越的成果。从2012年开始,alexnet网络的出现使得卷积神经网络的变得更深更宽,将卷积神经网络的性能得到了很大的提升,推动了卷积神经网络领域的发展。为了使网络的性能提升,众多的学者开始了更深的网络尝试,如vgg、googlenet,更深的网络结构带来了更好的训练效果。
3.但是,大多数的研究主要关注算法在各个基准测试数据集上的客观精度指标的提升,从而在设计上采用维数很高的网络。在网络深度在更深处发展时,计算量也在变得越来越大,复杂的网络结构使得计算复杂度也在提升。但由于硬件方面存在着内存瓶颈,如果参数的数量很大,就会严重影响硬件的处理速度,很难做到快速计算,延迟将会成为一个普遍的问题。并且嵌入式终端受有限的存储空间和低功率的限制,这使得现有的神经网络模型在资源有限、实时性要求高的终端硬件部署与实现时面临着巨大的挑战。所以如果要将卷积神经网络的方法应用到实际场景,需要同时考虑计算量和参数量。
技术实现要素:
4.本发明为了解决现在神经网络深度过大,难以部署在移动设备上的缺陷。本发明通过借鉴浅层卷积网络的方法优势,从硬件实现上对经典的fsrcnn网络模型进行优化,提出了轻量级的超分辨率浅层卷积神经网络tiny
‑
fsrcnn,并且根据此方法设计了一种基于深度学习的轻量级超分辨率图像重建方法,通过硬件电路加速方法的计算,使得小型终端提高了图像重建速度,同时也保证了重建图像的质量。
5.本发明的主要实现步骤如下:
6.步骤1、图像输入
7.用构建好的fpga芯片接收摄像头图像的输入,对采集到的视频图像经过预处理,得到指定大小的图像,将预处理后的视频图像存储到fpga芯片片外的存储区域的ddr0x区域,进行三帧缓存;用于解决图像写入过程与第一层卷积计算过程中的内存冲突。
8.步骤2、图像重建
9.fpga芯片对缓存在片外内存的图像进行读取,使用calc_top模块进行卷积计算操作,卷积计算的内存模型使用通道优先模型,所述的通道优先模型为:内存中图像数据的存储顺序为“通道
‑
行
‑
列”,比如2行2列2维即2*2*2的数据,内存中的存放顺序为(1,1,1)、(1,1,2)、(1,2,1)、(1,2,2)、(2,1,1)、(2,1,2)、(2,2,1)、(2,2,2)。卷积核的存储顺序同样为“通道
‑
行
‑
列”,从图像数据中取出与卷积核相同大小的一组数据分别与多个卷积核进行计算,计算结果恰好为一个通道的数据。故图像数据经过卷积计算后,计算结果存储顺序同样为“通道
‑
行
‑
列”,这样的存储顺序同样便于下一次卷积的计算。
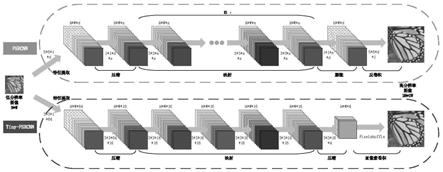
10.卷积计算使用的是基于脉动架构的向量计算单元,所述的脉动架构为:采用脉动阵列处理方式,每一个处理单元会以预定的步骤和它相邻的处理单元进行数据传输,第一个处理单元取数,经过处理后被传递到下一个处理单元同时第二个数据进入第一个处理单元,依次类推;从第一个数据到达最后一个处理单元开始,以后的每个周期都能得到一个计算结果。
11.脉动结构本身只是一种由数据流关系制约的结构,根据不同的应用会有不同的数据进行流动以及不同的流动方向,依靠紧密耦合的处理单元组成,其中每一个节点都会与一个或者多个周围的节点发生数据交互,结果或将存储在处理单元的内部,或将传递给下游处理单元。
12.对于卷积计算操作,这里的脉动阵列具体为:采用16个乘加模块,每个模块计算每一维的数据,第一个模块计算第一维的数据,第二个模块计算第二维的数据并且在计算第二维数据后再加上第一个模块计算的结果,这样第16个模块在计算完成后,输出数据就是这一通道的卷积计算结果。
13.经过计算得到的第一层卷积计算结果缓存在存储区域中的ddr1x区域中,其中ddr1x区域包括ddr10与ddr11,接下来的卷积计算特征图在ddr10与ddr11中进行相互缓存,节省内存的资源消耗;
14.步骤3、图像输出
15.当calc_top模块计算到卷积神经网络的最后一层时,输出计算得到的特征图存储到存储区域中的ddr2x的区域中,输出的图像同样进行三帧缓存,防止图像的输出显示出现撕裂。所述的图像输出的过程中按照pixelshuffle进行周期筛选输出。
16.本发明相当于现有技术的有益效果为:
17.1、相比于现有的fsrcnn网络模型,本发明设计的网络模型由于了实现少量的权重参数和规则的网络结构,减小了网络的规模,且降低了网络的参数计算,使得更容易部署在移动设备中。
18.2、网络设计过程中结合fpga硬件架构的设计,对网络的卷积进行了手工设计,将每层网络的卷积通道和个数设计为16的倍数,每次卷积的步进为1,这样硬件的基本设计单元可以设计为16并行度,使网络模型更适合硬件的部署。
19.3、使用通道优先模型,这种方法计算得到的特征图在内存中存储的排列顺序为“通道
‑
行
‑
列”,使得数据可以顺序读取,顺序输出。相比于现有的行优先模型,其不连续的地址读写要慢于通道优先的连续地址读写。所以为了得到最大的内存带宽,采用了通道优先模式存储数据。
20.4、针对传统卷积计算加法树的不足,本发明使用了基于脉动架构的向量计算单元,减少了加法器模块的使用,将求和过程使用累加来实现。这一方法减少了fpga时序变化带来的影响,并且减少了加法器模块,使得整个计算单元结构得到优化。
附图说明
21.图1是tiny
‑
fsrcnn网络模型;
22.图2是硬件整体架构设计;
23.图3是通道优先计算模型;
24.图4是基于脉动架构的向量计算单元。
具体实施方式
25.下面结合附图和具体实施对本发明作进一步说明。
26.如图1所示,为tiny
‑
fsrcnn网络模型与fsrcnn的区别。tiny
‑
fsrcnn网络模型主要分为特征提取、压缩、映射和重建这几个部分,下面详细介绍各个部分的主要作用:
27.a)特征提取
28.相比fsrcnn中第一层5
×
5大小的感受野,conv(5,d,1)需5
×
5大小的卷积核做卷积运算,这里采用较小的3
×
3感受野、较大的64通道的卷积核,在特征提取效果减少不大的同时,减小了在算法的硬件实现阶段设计的复杂度,所有的卷积核大小都为3
×
3大小,这样硬件设计将更加简单,并且采用较小的3
×
3卷积设计,减少了卷积计算的复杂度。
29.b)压缩
30.这个阶段的作用是减小特征图的维度,采用3
×
3感受野来做通道的压缩,把64通道压缩至16通道,相比fscnn较小的1
×
1感受野,本文采用的卷积方式,在压缩过程,可以保留更多的特征信息,进而弥补上一阶段特征提取过程的特征图细节信息损失。
31.c)映射
32.这里采用大小为3
×
3的感受野,总共使用了4个非线性单元。通过卷积来完成特征提取能力,通过不同的卷积核滑窗操作,来提取不同的特征细节信息,把数据通过一个卷积核变化为特征,便于后面的分离。
33.d)拓展
34.在fsrcnn中,为了得到hr图像,那么就要进行增加扩展层,类似于压缩层的逆过程,用来扩展hr特征维数。但是在tiny
‑
fsrcnn中,因为重建实现方式不同于fsrcnn,所以,没有了拓展这个阶段,反而,是采用压缩的方式,把特征图通道数压缩到图像的放大倍数,大大降低了计算量。
35.e)重建
36.可以看成卷积的逆过程。这里采用由shi等人提出的一种高效亚像素卷积上采样pixelshuffle操作的方法来得到hr图像,把r2个通道的特征图通过周期筛选方法得到r倍大小的高分辨率图像。相比fsrcnn中采用卷积操作得到hr图像,pixelshuffle方法来得到hr图像的过程参数量更少、计算复杂度更小。
37.f)激活函数
38.fsrcnn采用prelu激活函数,但由于relu的计算更加简单,可以通过简单的逻辑判断来代替数值的计算,比较适合硬件电路的实现,所以这里激活函数采用relu实现。
39.如图2所示,为硬件整体架构设计。从数据的输入流程来看,摄像头输入视频图像,经过预处理后缓存到ddr0x内存中;cale_top模块处理缓存的图像,在ddr1x缓存中间的计算结果;经过卷积神经网络计算的图像输出到ddr2x进行缓存。
40.如图3所示,为通道优先计算模型。从图上可以看出通道优先的计算模型是特征图共享的。在特征图中取出一次卷积操作大小的特征图进行共享,与256个卷积核进行卷积操作,一次得到256个输出结果,对应输出特征图的一通道数据点的集合。在下次计算过程中,读取内存中存储的特征图可以按照顺序寻址访问内存,进行特征图读取,卷积的计算也是
按照通道进行排列并行计算,读出的数据不用经过处理,即可进行按照顺序进行计算。
41.如图4所示,为基于脉动架构的向量计算单元。从特征图与一个卷积核的卷积计算来进行分析,这里的计算是一维的计算,把特征图与卷积核都转换为通道优先的一维的向量,对应位置的数据相乘然后相加得到一个点的计算结果输出。
42.针对向量计算单元,三维的输入图像和三维的卷积核的乘加操作,针对通道数为16的卷积计算结构进行硬件结构改进,设计16并行度的加速方案。以大小为3
×3×
16卷积核为例进行分析,得到如图所示的基于脉动结构的向量计算单元,使用16个处理单元,每个单元实现的功能为乘加操作,得到16个数值的乘加结果,然后9个结果进行相加求和,得到一个输出点结果,在9个结果进行相加求和这里会增加一个额外的处理单元,当然这个处理单元不做乘法,只做加法即可,基本计算单元是乘加操作,其中每个处理单元由fpga内部的dsp资源来进行实现。
43.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1