基于注意力机制和非合理动作抑制的机械臂自主抓取方法
1.本发明属于智能控制领域,具体涉及基于注意力机制和非合理动作抑制的机械臂自主抓取方法。
背景技术:
2.机械臂抓取任务是机器人任务中的一项基本任务,具有广泛的应用场景。基于强化学习的机械臂自主抓取是该领域的一个研究热点,强化学习方法通过奖励函数来指导智能体自主学习高效有用的抓取策略,能够实现在无结构复杂环境下的自主抓取。本发明在机械臂抓取强化学习网络中引入注意力机制使网络能够关注有效的物体抓取区域,同时设计非合理动作抑制策略来抑制不合理的抓取动作,大大提升了复杂环境中物体抓取的成功率,具有重要的理论价值和实际意义。
技术实现要素:
3.本发明针对现有技术的不足,提供了一种基于注意力机制和非合理动作抑制的机械臂自主抓取方法。
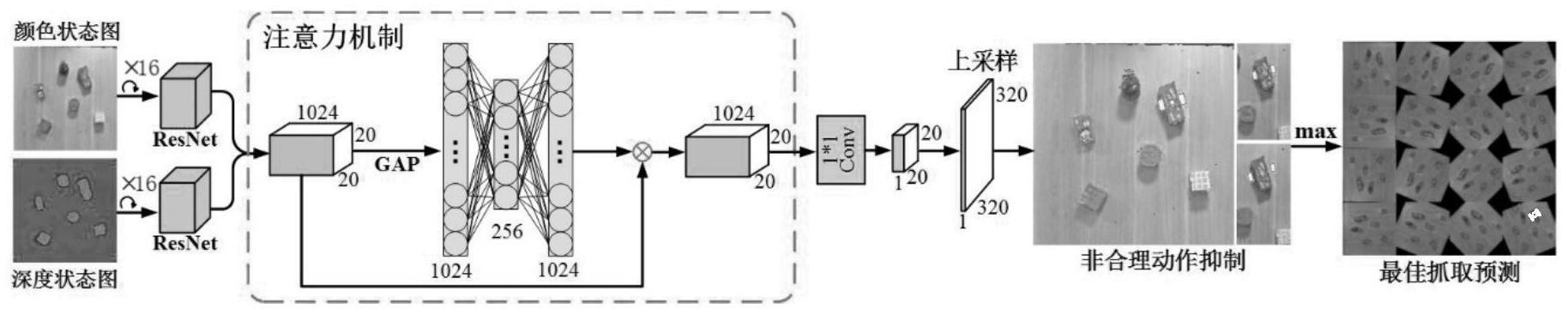
4.本发明一种基于注意力机制和非合理动作抑制的机械臂自主抓取方法,该方法具体包括以下步骤:
5.步骤(1):利用rgb
‑
d相机采集目标区域的深度图i
depth
和彩色图i
color
,尺寸为h
×
w,将彩色图i
color
和深度图i
depth
以δθ为旋转间隔逆时针旋转d次,得到d组具有不同旋转方向的彩色图和深度图记为状态s
t
,其中t表示当前时刻;
6.步骤(2):构建深度强化学习网络,网络由特征提取层、注意力机制层、上采样层和非合理动作抑制层组成;
7.(a)特征提取层:
8.将d组彩色图和深度图输入网络,对每一组进行特征提取;以第d
i
组为例,和各自通过一个经过imagenet预训练的resnet
‑
50网络的卷积层部分进行特征提取操作得到颜色特征图和深度特征图
9.(b)注意力机制层:
10.将颜色和深度特征图进行通道拼接操作得到融合特征图然后将经过一个注意力机制模块,让网络持续关注杂乱物体中较好的抓取位置区域,得到
11.注意力机制的操作步骤如下:
[0012][0013][0014]
[0015][0016]
注意力机制模块中首先将特征图沿着空间维度进行全局平均池化操作得到将通过一个全连接层l1和rectified linear unit激活层,对每个通道的特征信息进行特征融合;接着再经过一个全连接层l2和sigmod激活层得到注意力机制模块的权重的维度与输入特征图通道维度一致;将和进行乘法操作得到最终的输出
[0017]
其中avgpool(
·
)表示空间全局平均池化操作,l1(
·
)和l2(
·
)表示全连接层,σ(
·
)表示rectified linear unit激活层,sigmod(
·
)表示sigmod激活层,bn(
·
)表示batch normalization操作;
[0018]
(c)上采样层:
[0019]
将注意力特征图经过一个卷积核大小为1
×
1的卷积层、batch normalization层和rectified linear unit激活层得到特征图实现通道降维;然后,将特征图进行顺时针旋转,使其回到与彩色图i
color
一样的角度方向,再进行上采样操作得到尺寸为h
×
w的上采样图d组颜色状态图和深度状态图获得d组上采样图进行通道拼接操作得到d维尺寸为h
×
w的像素级别的动作预测q(s
t
,a;θ);
[0020]
其中,θ为网络参数,a表示抓取动作的动作空间,该动作空间由机械臂的执行位置(x
w
,y
w
,z
w
)和夹爪旋转角度θ组成;
[0021]
(d)非合理动作抑制层:
[0022]
根据q(s
t
,a;θ)得到每个通道维度下的最大动作预测值,即最佳抓取位置(x
w
,y
w
,z
w
)和夹爪旋转角度θ,共获得d维最佳动作预测;
[0023]
在每个维度中,沿着各自的最佳动作方向,经过不同的偏移后,得到不同掩码区域k表示不同的掩码区域,d表示维度;具体的,掩码区域是以该维度下的最佳抓取位置沿着抓取方向偏移不同像素后的像素点为中心,尺寸为(h
g
,w
g
)的长方形区域;掩码区域的长边w
g
与抓取方向垂直;
[0024]
表示在掩码区域内属于物体区域的概率,对同一个动作方向不同偏移值下的进行求均值操作得到该动作方向上最终的概率p
d
;
[0025][0026]
其中,k表示每个动作方向上的掩码区域数量;
[0027]
p
d
越小表示成功抓取物体的概率越大,碰撞的概率越小;因此,非合理动作抑制策略π(s
t
)为:
[0028]
π(s
t
)=1
‑
p
d
ꢀꢀꢀ
(6)
[0029]
将d维的非合理动作抑制策略π(s
t
)与d维的最大动作预测值q(s
t
,a;θ)进行通道相乘操作,最终获得时刻t下的最佳动作a
t
;
[0030]
步骤(3):设计奖励函数,训练强化学习网络;
[0031]
①
奖励函数设计:
[0032]
抓取奖励r
g
定义如下:
[0033]
r
g
=g
‑
λδψ
ꢀꢀꢀ
(7)
[0034]
δψ=|ε
θ
‑
ο
θ
|∈[0
°
,90
°
]
ꢀꢀꢀ
(8)
[0035]
其中,g表示抓取的结果,如果抓取成功g=1.5,如果抓取失败g=0;δψ表示抓取角度的偏差,由夹爪实际旋转角度ε
θ
与该物体实际角度ο
θ
的绝对差计算得到,λ表示该角度偏差对于抓取奖励的影响程度;
[0036]
②
采用时间差分的双重q学习更新方式对网络进行训练;
[0037]
在时间t,采集机械臂工作区间的rgb
‑
d图像得到状态s
t
,将s
t
输入当前网络得到最佳执行动作a
t
(x
w
,y
w
,z
w
,θ);执行该动作a
t
后,再次采集rgb
‑
d图像得到下一个状态s
t+1
,根据物体是否抓取成功,给动作a
t
的一个奖励r
g
;采用时间差分法来最小化当前状态下执行动作的动作预测值q(s
t
,a
t
;θ)与带有未来期望奖励的目标值之间的时间差分误差;该目标值y
t
采用双重q学习方法定义:
[0038][0039]
其中,参数θ
target
表示动作价值目标网络,该参数来自于δt时刻前的网络参数;γ表示衰减因子;
[0040]
步骤(4):完成步骤(3)的训练后,将训练好的网络参数直接从仿真环境迁移到真实环境中,通过realsense
‑
435i相机对机械臂工作区间环境进行图像采集,进而得到状态s
t
;将状态s
t
输入网络得到最佳执行动作a
t
(x
w
,y
w
,z
w
,θ),通过ros moveit运动规划库对机械臂抓取的路径进行规划与控制。
[0041]
作为优选,为了防止机械臂与物体之间的碰撞,本发明设置抓取控制时的最低安全高度z
safe
,保证抓取过程的安全性。首先,根据最佳动作位置(x
w
,y
w
),将其沿着夹爪旋转角度θ方向进行像素偏移操作(偏移的像素值根据夹爪的初始打开宽度获得),得到两个表示夹爪末端位置的区域。其次,将该区域的最大高度值与工作空间桌面高度的绝对差值作为系统的最低安全高度z
safe
。在抓取过程中,抓取高度z
w
为:
[0042]
z
w
=z
w
+z
safe
ꢀꢀꢀ
(10)。
[0043]
本发明具有以下有益的效果:
[0044]
本发明采用深度强化学习方法通过奖励函数指导智能体进行物体的自主抓取技能的学习。利用注意力机制使得网络在试错中持续关注能够提升抓取成功率的抓取位置区域;设计的非合理动作抑制策略,能够有效解决强化学习方法从仿真迁移到真实环境中存在状态差异的问题,保证物体的抓取过程安全高效,具有很高的环境适应性及抓取成功率。通过学习后,该方法能够在复杂环境下完成物体的自主抓取任务。
附图说明
[0045]
图1为基于注意力机制和非合理动作抑制的机械臂自主抓取流程图。
具体实施方式
[0046]
本发明专利提供了基于注意力机制和非合理动作抑制的机械臂自主抓取方法,包括以下步骤:
[0047]
步骤(1):利用rgb
‑
d相机采集目标区域的深度图像i
depth
和颜色图像i
color
,尺寸大小为320
×
320,将上述颜色图i
color
和深度图i
depth
以δθ=22.5
°
为旋转间隔逆时针旋转d=16次,得到d组具有不同旋转方向的颜色状态图和深度状态图记为状态s
t
,其中t表示当前时刻。
[0048]
步骤(2):构建深度强化学习网络,网络(见附图1)由特征提取层、注意力机制层、上采样层和非合理动作抑制层组成。
[0049]
(a)特征提取层:
[0050]
将d组颜色状态图和深度状态图输入抓取网络,以第d
i
组为例,和各自通过一个经过imagenet预训练的resnet
‑
50网络的卷积层部分进行特征提取操作得到颜色特征图和深度特征图
[0051]
(b)注意力机制层:
[0052]
将颜色和深度特征图进行通道拼接操作得到融合特征图然后将经过一个注意力机制模块,让网络持续关注杂乱物体中较好的抓取位置区域,得到
[0053]
注意力机制的操作步骤如下:
[0054][0055][0056][0057][0058]
注意力机制模块中首先将特征图沿着空间维度进行全局平均池化操作得到将通过一个全连接层l1和rectified linear unit激活层,对每个通道的特征信息进行特征融合。接着再经过一个全连接层l2和sigmod激活层得到注意力机制模块的权重的维度与输入特征图通道维度一致。将和进行乘法操作得到最终的输出
[0059]
其中avgpool(
·
)表示空间全局平均池化操作,l1(
·
)和l2(
·
)表示全连接层,σ(
·
)表示rectified linear unit激活层,sigmod(
·
)表示sigmod激活层,bn(
·
)表示batch normalization操作。
[0060]
(c)上采样层:
[0061]
首先,将注意力特征图经过一个卷积核大小为1
×
1的卷积层、batch normalization层和rectified linear unit激活层得到特征图实现通道降维。然后,
将特征图进行顺时针旋转,使其回到与彩色图i
color
一样的角度方向,再进行上采样操作得到尺寸为320
×
320的上采样图最终,d组颜色状态图和深度状态图获得d组上采样图进行通道拼接操作得到d维尺寸为320
×
320的像素级别的动作预测值q(s
t
,a;θ)。
[0062]
其中,θ为网络参数,a表示抓取动作的动作空间,该动作空间由机械臂的执行位置(x
w
,y
w
,z
w
)和夹爪旋转角度θ组成。
[0063]
(d)非合理动作抑制层:
[0064]
根据q(s
t
,a;θ)得到每个通道维度下最大动作预测值和对应的最佳抓取位置(x
w
,y
w
,z
w
)和夹爪旋转角度θ,共可获得d维最佳动作。
[0065]
在每个维度中,沿着他们各自的动作方向,经过不同的偏移值s∈[11,13,15]之后,得到掩码区域具体的,掩码区域是以最大动作预测值对应的抓取位置沿着抓取方向θ偏移s∈[11,13,15]像素后的像素点为中心,与抓取方向θ垂直且尺寸为(h
g
,w
g
)=(8,15)的长方形区域。其中k=3表示该方向上的偏移值数量,d表示维度。将定义为在掩码区域内属于物体区域的概率,对同一个动作方向上的不同偏移值下的进行求均值操作得到该动作方向上最终的概率p
d
。
[0066][0067]
其中,k=6表示在每一个动作方向上掩码区域数量。
[0068]
p
d
越小表示成功抓取物体的概率越大,碰撞的概率越小。因此,我们的非合理动作抑制策略π(s
t
)为:
[0069]
π(s
t
)=1
‑
p
d
ꢀꢀꢀ
(6)
[0070]
将d维的非合理动作抑制策略与d维的最大动作预测值进行通道相乘操作,最终获得时刻t下的最佳动作a
t
。
[0071]
步骤(3):设计奖励函数,训练强化学习网络。
[0072]
①
励函数设计:
[0073]
抓取奖励r
g
定义如下:
[0074]
r
g
=g
‑
λδψ
ꢀꢀꢀ
(7)
[0075]
δψ=|ε
θ
‑
ο
θ
|∈[0
°
,90
°
]
ꢀꢀꢀ
(8)
[0076]
其中,g表示抓取的结果,如果抓取成功g=1.5,如果抓取失败g=0。δψ表示抓取角度的偏差,由夹爪实际旋转角度ε
θ
与该物体实际角度ο
θ
的绝对差计算得到,λ=0.02表示该角度偏差对于抓取奖励的影响程度。
[0077]
②
用时间差分的双重q学习更新方式对网络进行训练。
[0078]
在时间t,采集机械臂工作区间的rgb
‑
d图像得到状态s
t
,将s
t
输入当前策略(即网络)得到最佳执行动作a
t
(x
w
,y
w
,z
w
,θ)。执行该动作a
t
后,再次采集rgb
‑
d图像得到下一个状态s
t+1
,根据物体是否抓取成功,给动作a
t
的一个奖励r
g
。采用时间差分法来最小化当前状态下执行动作的动作预测值q(s
t
,a
t
;θ)与带有未来期望奖励的目标值之间的时间差分误差。
该目标值y
t
采用双重q学习方法定义:
[0079][0080]
其中,参数θ
target
表示动作价值目标网络,该参数来自于δt=200时刻前的网络参数;γ表示衰减因子。在实验中,设置γ=0.5。
[0081]
步骤(4):完成步骤(3)的训练后,将训练好的网络参数直接从仿真环境迁移到真实环境中,通过realsense
‑
435i相机对机械臂工作区间环境进行图像采集,进而得到状态s
t
。将状态s
t
输入网络得到最佳执行动作a
t
(x
w
,y
w
,z
w
,θ),通过ros moveit运动规划库对机械臂抓取的路径进行规划与控制。
[0082]
为了防止机械臂与物体之间的碰撞,本发明设置抓取控制时的最低安全高度z
safe
,保证抓取过程的安全性。首先,根据最佳动作位置(x
w
,y
w
),将其沿着夹爪旋转角度θ方向进行像素偏移操作(偏移的像素值根据夹爪的初始打开宽度获得),得到两个表示夹爪末端位置的区域。其次,将该区域的最大高度值与工作空间桌面高度的绝对差值作为系统的最低安全高度z
safe
。在抓取过程中,抓取高度z
w
为:
[0083]
z
w
=z
w
+z
safe
ꢀꢀꢀ
(10)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1