一种融合微博主题及评论的深度学习谣言检测方法
1.本发明涉及自然语言处理技术领域,尤其是指一种融合微博主题及评论的深度学习谣言检测方法。
背景技术:
2.如今,网络社交媒体非常流行,数十亿人在这里表达自己的观点,传播信息。在社交媒体上发布的谣言通常传播迅速,因此有必要尽快发现这些谣言,将损失降到最低。用户通常在新浪微博上发布微博来表达他们的观点和分享信息。由于微博是不断产生的,仅靠人工处理很难对谣言进行分析和检测。与网络新闻(也是谣言的主要来源之一)不同的是,网络社交媒体上的微博正文通常篇幅较短,这可能会导致缺乏词汇的稀缺性问题。此外,我们经常可以在相应的微博上找到额外的社会信息,比如评论,这些评论可以为发现谣言带来积极的影响。
3.随着深度学习的发展,利用深度神经网络(dnns)自动提取高维语义特征是一种常用的方法。近年来,将dsss与附加的社会信息相结合来提高谣言检测性能成为一种流行的方案。例如:
4.jin和他的同事们提出了一种基于神经网络的模型,该模型带有一种关注机制,通过融合发布在同一条推文上的图像和文本来检测谣言(jin z,cao j,guo h,et al.multimodal fusion with recurrent neural networks for rumor detection on microblogs[c].proceedings of the 25th acm international conference on multimedia.2017:795
‑
816);
[0005]
yuan及其同事利用基于cnn的模型学习微博的语义表示,并将源推文与转发文、用户融合用于谣言检测(yuan c,ma q,zhou w,et al.jointly embedding the local and global relations of heterogeneous graph for rumor detection[c].2019 ieee international conference on data mining(icdm).ieee,2019:796
‑
805);
[0006]
ma和他的同事们提出了一个新的gan的框架,该框架使用源推文的响应来学习更强的谣言指示性表示(ma j,gao w,wong k f.detect rumors on twitter by promoting information campaigns with generative adversarial learning[c].the world wide web conference.2019:3049
‑
3055)。
[0007]
虽然以上方法是有效的,但是大多数模型都没有考虑到微博正文的稀疏性问题,检测有效性和效率低。
技术实现要素:
[0008]
为此,本发明所要解决的技术问题在于克服现有技术中由于网络社交媒体上的微博通常篇幅较短,这可能会导致文字缺乏造成的稀疏问题,且现有的语义检测方法难以对微博谣言检测,检测有效性和效率低的问题。
[0009]
为例解决上述技术问题,本发明提供了一种融合微博主题及评论的深度学习谣言
检测方法,包括:
[0010]
步骤1:对于一条微博的微博正文及其微博评论,获取微博正文的词序列表示形式及微博正文的词袋模型形式;
[0011]
步骤2:将微博正文的词序列表示形式经过embedding得到向量表示;
[0012]
步骤3:将所述向量表示与微博正文的词袋模型形式输入到tmn结构中,得到融合了主题信息的微博正文特征;
[0013]
步骤4:将融合了主题信息的微博正文特征通过cnn提取微博正文的特征表示;
[0014]
步骤5:对每条微博评论经过embedding后进行拼接得到的向量通过cnn抽取,得到微博评论的特征表示;
[0015]
步骤6:融合微博正文的特征表示与微博评论的特征表示,并将融合结果作为输入特征输入到分类器中,得到微博是否属于谣言的预测结果。
[0016]
在本发明的一个实施例中,所述微博评论为由one
‑
hot编码组成的评论。
[0017]
在本发明的一个实施例中,所述步骤2中,对于微博正文的词序列表示形式,使用预训练单词向量得到embedding。
[0018]
在本发明的一个实施例中,所述步骤3包括:对于微博正文的词序列表示形式,计算每个主题和每个单词的匹配程度:
[0019][0020]
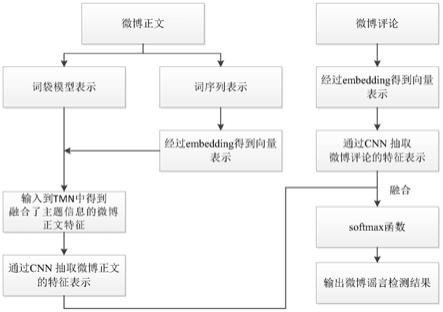
其中,使用预训练单词向量得到embedding记作第i个微博正文中第j个单词的embedding记作s为源记忆矩阵,σ是sigmoid激活函数,w
s
和b
s
是训练过程中得到的参数,k为主题的数量。
[0021]
在本发明的一个实施例中,所述步骤3中,融合了主题信息的微博正文特征tr:
[0022]
tr=ξt
[0023]
其中,t为目标记忆矩阵,ξ为记忆权重。
[0024]
在本发明的一个实施例中,所述记忆权重ξ,其在k个主题中的定义如下:
[0025]
ξ
k
=γ∑
j
p
k,j
+θ
k
[0026]
其中,γ是预定义的系数,θ
k
为主题分布。
[0027]
在本发明的一个实施例中,所述步骤4中,微博正文的特征表示:
[0028][0029]
在本发明的一个实施例中,所述步骤5包括:对第i条微博的微博评论集合c
i
=[c
i1
,c
i2
,...,c
il
],使用预训练词语向量得到embedding形式记作使用连接操作整合embedding中的c
i
中的所有评论记作
[0030][0031]
对使用cnns,得到微博评论的特征表示
[0032][0033]
在本发明的一个实施例中,所述步骤6中,使用连接操作融合微博正文的特征表示与微博评论的特征表示为r:
[0034][0035]
在本发明的一个实施例中,所述步骤6中,使用softmax函数得到实例是否属于谣言的预测,使用r作为输入特征,得到第i个微博预测标签的分布:
[0036]
p
i
=softmax(r)。
[0037]
本发明的上述技术方案相比现有技术具有以下优点:
[0038]
本发明提出了一种基于dnns的新型融合模型,利用主题记忆网络将潜在主题与原始微博进行融合,解决了微博正文文本短而导致的稀疏性问题。
[0039]
本发明使用了最广泛的在线社交媒体之一新浪微博上进行谣言检测。本专利将谣言检测任务建模为一个二元分类问题,并提出了一个基于深度神经网络的topcom模型。该模型利用主题记忆网络将潜在主题信息与原始微博进行融合,解决了短文本微博正文带来的稀疏性问题。
[0040]
本发明所述的提出了一种基于dnns的topcom模型,通过融合潜在主题和相应评论来训练谣言检测模型,使用该模式可判断微博是否属于谣言,无需人工处理;通过在微博谣言数据集上与对不同指标基线方法的比较,表明了本专利所提topcom模型方法的有效性和效率;在公开可用的主题词谣言数据集上开展的额外实验结果也表明展示了所提模型方法的通用性;本发明所提出的topcom模型融合了潜在主题和评论的优点,在基于微博的谣言检测任务中取得了良好的性能。
附图说明
[0041]
为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明,其中
[0042]
图1是本发明的融合潜在主题和相应评论来训练谣言检测模型的步骤流程图。
具体实施方式
[0043]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0044]
本发明为了解决微博正文的稀疏性问题,充分利用网络社交信息,提出了一种基于主题评论的谣言检测模型(topcom),将谣言检测问题建模为一个二元分类任务。topcom模型使用类似主题记忆力网络(topic memory networks,tmn)(zeng j,li j,songy,et al.topic memory networks for short text classification[c].proceedings of the 2018 conference on empirical methods in natural language processing.2018:3120
‑
3131)的主题记忆力机制来融合潜在主题。
[0045]
参照图1所示,本发明的模型主要包括:将微博正文的词序列表示形式经过序列embedding得到向量表示;将其与微博正文的词袋模型形式输入到tmn结构中得到融合了主题信息的微博正文特征;提取相应微博评论的语义特征;将融合了主题信息的微博正文特征与微博评论的语义表示联合训练分类器。给定一个实例x
i
=[m
i
,c
i
],目标是训练一个分类器c对于一个标签y
i
进行预测。m
i
是指第i个微博正文,其词袋模型表示形式记为其词序列表示形式记为c
i
是指第i个微博正文的由l
‑
hot编码(one
‑
hot encoding)
组成的评论,是其单词序列向量的形式;k为预定义的参数,表示潜在主题的数量。具体步骤过程如下:
[0046]
步骤1:爬取一段时间的微博及评论x
i
作为instance,x
i
=[m
i
,c
i
],m
i
是指第i个微博正文,c
i
是指第i个微博正文的评论,c
i
=[c
i1
,c
i2
,...,c
il
]。
[0047]
步骤2:将微博正文的词序列表示形式经过embedding得到向量表示
[0048]
步骤3:将向量表示与微博正文的词袋模型形式输入到tmn结构中,得到融合了主题信息的微博正文特征tr;
[0049]
步骤4:tr通过cnn提取第i条微博正文的特征表示
[0050]
步骤5:对于第i条微博的每条评论c
i
=[c
i1
,c
i2
,...,c
il
]经过embedding后拼接起来得到向量对通过cnn抽取第i条微博评论的特征表示
[0051]
步骤6:融合正文特征与评论特征记为r,将r作为输入到softmax函数(归一化指数函数)中,得到第i个instance的预测结果p
i
。
[0052]
步骤3中,提到的现有tmn结构:tmn结构提出了两个记忆矩阵,一个源记忆矩阵s和一个目标记忆矩阵t,tmn结构中设计的ntm(神经主题模型)模型收敛时可得到主题分布θ。
[0053]
步骤3中,在第i条微博中,计算每个主题和每个单词的匹配程度:
[0054][0055]
其中,使用预训练单词向量得到embedding记作第j个单词的embedding可以记作s为源记忆矩阵,σ是sigmoid激活函数,w
s
和b
s
是训练过程中得到的参数,通过主题分布θ总结第i条微博中的所有单词,得到整合后的记忆权重ξ,其在k个主题中的定义如下:
[0056]
ξ
k
=γ∑
j
p
k,j
+θ
k
[0057]
γ是预定义的系数。然后通过整合记忆权重ξ探寻目标记忆矩阵t来得到融合了主题信息的微博正文特征tr:
[0058]
tr=ξt
[0059]
使用添加操作融合主题代表tr,通过使用序列embedding,u作为微博的特征代表。使用cnn提取更高级的语义特征,用表示:
[0060][0061]
包含m
i
中原始文本的潜在主题,使得语义更加丰富且解决了稀疏问题。
[0062]
步骤5中提取评论语义特征:
[0063]
第i条微博的评论集合c
i
=[c
i1
,c
i2
,...,c
il
],使用预训练词语向量得到embedding形式记作使用连接操作整合embedding中的c
i
中的所有热门评论记作
[0064]
[0065]
包含所有热门评论的基本语义信息。为了对训练分类提取高级语义特征,对使用cnns,特征记为
[0066][0067]
和都由cnn获得,这种方式对于最后使用融合方法得到最终的微博表示r是合适的。使用连接操作融合主题包含文本和评论:
[0068][0069]
步骤6中:
[0070]
使用softmax函数得到实例是否属于谣言的预测,使用r作为输入特征,则第i个实例预测标签的可能分布如下:
[0071]
p
i
=softmax(r)
[0072]
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0073]
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0074]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0075]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0076]
显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1