一种基于负样本多样性的问答模型集成方法
本发明涉及自然语言处理领域,具体涉及问答系统中模型集成的处理。
模型集成是自动问答系统中提升问答模型性能的重要方法与关键技术。
背景技术:
医疗问答模型是自动问答模型的一个应用分支,随着自然语言处理技术的提升已经成为一个重点研究和应用。相应的,越来越多患者倾向于通过线上健康社区寻求医疗帮助。然而,急剧增长的问题数量给医生带来了巨大的回复负担。为了缓解医生的工作负担以及满足用户快速得到答案的需求,大量研究者们投身于医疗问答领域的研究。而在医疗问答系统中,保证模型的准确性和鲁棒性是一个技术难点,为此,一些学者通过集成学习来关注更多数据信息,同时提升问答系统的性能。
目前中文医疗领域的模型集成方法在训练数据方面通常对负样本进行随机采样,或基于单一相似度距离分段采样,这些方法只关注了样本中实体间某一层次上的关联性对负样本进行采样,没有充分挖掘负样本的多样性。
技术实现要素:
针对现有技术不足,本发明提出了一种基于负样本多样性的问答模型集成方法,在多相似度距离下对负样本进行分段采样,以此来构建多个训练集,并基于它们训练出多个基模型,旨在借助负样本的多样性来保证基模型的多样性,最终提高了生成的集成模型的准确性和鲁棒性。
医疗问答作为一种为用户提供医疗和健康类咨询的服务平台,需要具备较高的准确性和稳定性。在问答系统的问答匹配阶段,集成模型往往比使用单个学习器有更好的准确性和鲁棒性,因此集成学习也被引入问答领域的研究。模型观察不同的负样本能学到不同的语言表示信息,而目前针对集成模型的研究在模型训练阶段往往对负样本的多样性考虑不足,导致基模型的多样性有限,因此影响了最终集成模型的预测性能。
针对上述问题,本发明以提升中文医疗问答模型的稳定性和鲁棒性为目的,提出了一种基于负样本多相似度分段采样的模型集成方法。该方法根据正负样本间的多种相似度距离分别对负样本进行排序和分段采样,由此构成多个训练样本集,并基于它们训练出多个基模型,最后将基模型进行集成。
为了实现上述目的,本发明给出的技术方案为:
本发明提供一种基于知识图谱的医疗查询扩展方法,包括:
步骤1、对医疗问答对数据集进行预处理;
步骤2、负样本相似度排序;
步骤3、结合步骤2得到的负样本排序结果,对负样本进行分段采样,构建多个训练集并训练基模型;
步骤4、利用加权平均对步骤3中得到的基模型进行集成,从而得到最终的问答模型。
有益效果
本发明针对现有提升中文医疗问答模型性能的模型集成方法对负样本的多样性考虑不足的问题,设计了一种基于负样本多相似度分段采样的模型集成方法。该方法根据正负样本间的多种相似度距离分别对负样本进行排序和分段采样,以此得到多个训练样本集,并基于它们训练出多个基模型最后进行模型集成。该方法通过充分挖掘负样本的多样性来得到多样性的基模型,从而提高了最终集成模型的准确率。这对智慧社区场景下为居民提供便利的线上及时医疗服务、缓解医生的工作负担具有重大意义。
附图说明
附图是对本发明的进一步说明,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但不构成对本发明的限制。在附图中:
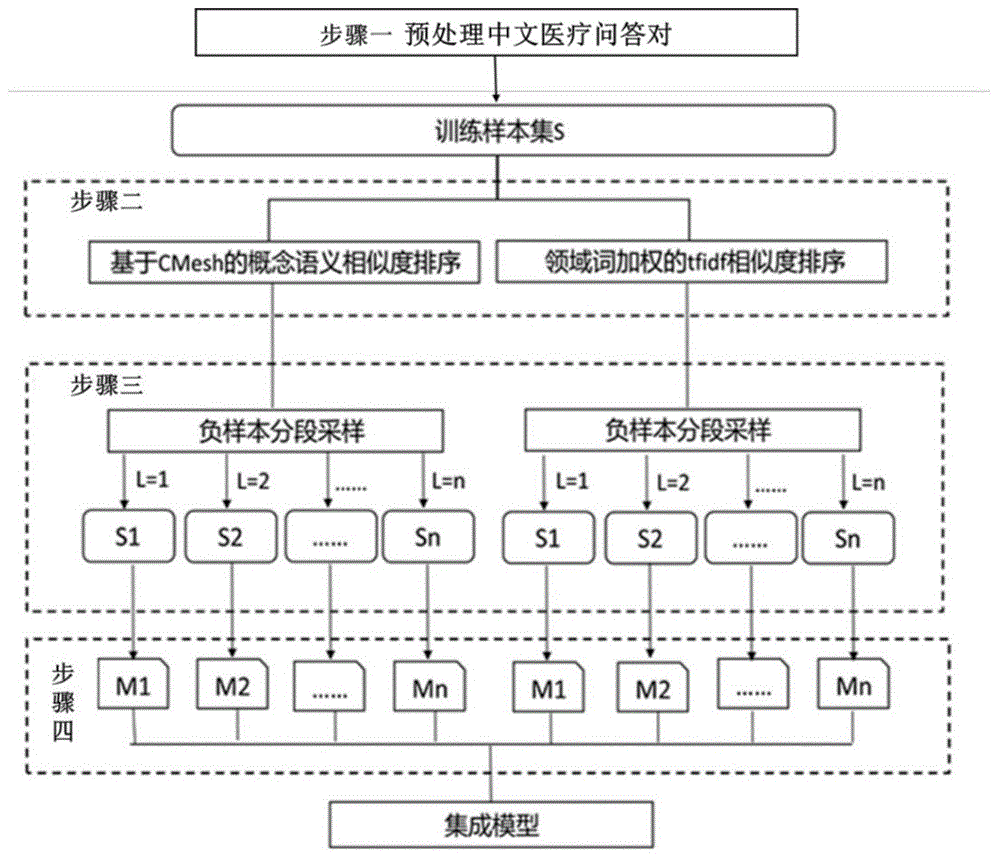
图1为模型集成方法的流程示意图;
图2为步骤二中确定词形相似度中词汇权重的预实验结果;
图3为步骤三中分段采样示例图;
图4为步骤三中确定最佳分段数的预实验结果。
具体实施方式
为了使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的具体实施方式进行清楚、完整的描述。应当理解的是,此处所描述的具体实施方法仅用于说明和解释本发明,并不用于限制本发明。
本发明的具体实施过程如图1所示,包括如下4个方面:
步骤1、对医疗问答对数据集进行预处理;
步骤2、负样本相似度排序;
步骤3、结合步骤2得到的负样本排序结果,对负样本进行分段采样,构建多个训练集并训练基模型;
步骤4、利用加权平均对步骤3中得到的基模型进行集成,从而得到最终的问答模型。
各个步骤详述如下。
第一步:中文医疗问答对数据集预处理,
1.1整合问答对数据集
删除一些未包含答案、表达不明确、问句或答句中包含图片的无效问答对。为了确保数据集的平衡性,删除疾病诊断类、疾病治疗类、疾病症状类、疾病原因类四大类之外的个别其他类问答句。将整合好的数据集提供给步骤1.2;
1.2去除停用词
利用停用词词表去除问答对数据集中问句的停用词,主要包括一些语气词、礼貌用语等使用频率较高又无实际含义的词汇。去除停用词后的结果提供给步骤1.3和步骤1.4;
1.3标注问答对正样本
对步骤1.2提供的数据集中每个问句对应的正确答案进行标注,由此获得问答对的正样本,将标注结果提供给步骤1.4。
1.4随机初始化问答对负样本
基于步骤1.3标注的问答对正样本,从步骤1.2提供的所有答案中随机给问句匹配答案,这个答案不能与正样本中答案相同,之后将这些问答对标注为负样本,从而完成问答对负样本的随机初始化。标注后即完成了步骤1对于问答对数据集的预处理工作,将预处理后的数据集中的问句提供给步骤2、步骤3和步骤4。
第二步:负样本相似度排序。
2.1计算正负样本的词性相似度
对步骤1得到的问答对正样本和负样本中的答案,利用能够基于统计的方法给出词语在文本中重要程度的tfidf算法计算答案之间的距离,将结果提供给步骤2.2。
2.2计算词汇权重
步骤1所提供的的问答语料属于医疗领域,其中领域词汇往往比普通词汇更具有区分度和重要性,因此本发明在步骤2.1的基础上,通过赋予医疗领域词汇更高的权重来凸显领域词汇的重要性,即采用领域词加权的tfidf算法对正负样本的词形相似度距离计算进行优化。
权重的取值会直接影响相似度算法的性能,本发明设计了预实验来确定步骤1提供的问答语料中领域词汇和普通词汇的权重比值。如图2所示,预实验以acc@1为评价指标,通过调整普通词汇与领域词汇的权重比例来比较初始集成模型性能的变化。这里,初始集成模型采用组合了6个基于负样本词形相似度分段采样得到的bigru_cnn模型。
由预实验的结果可以看出,当普通词汇与领域词汇的权重比为0.6时初始集成模型的效果最好。因此,在基于领域词加权的tfidf算法中,领域词汇与普通词汇的权重公式如公式(1)、(2)所示。其中ω1为领域词汇,c1为普通词汇,w′为基于词频和逆文本频率指数的原始权重,w(ω1)为加权后的领域词汇权重,w(c1)为加权后的普通词汇权重。
w(ω1)=1*w′(ω1)(1)
w(c1)=0.6*w′(c1)(2)
将w(ω1)和w(c1)引入到tfidf算法中,得到的词性相似度结果并进行由大到小排序,将排序后的结果提供给步骤3.
2.3计算正负样本中领域词汇间相似度
由于cmesh(chinesemedicalsubjectheadings)中的树状结构能清晰地展示医疗领域词间的语义关系,本发明利用cmesh来计算步骤1提供的正负样本中答案所包含医学领域词汇间的相似度,并将该相似度结果提供给步骤2.4。具体的,通过医学领域词汇ω1,ω2间的语义距离来计算领域词汇间的语义相似度sim(ω1,ω2),相似度计算公式如公式(3)所示。其中,dist(ω1,ω2)代表领域词间的语义距离。
2.4计算正负样本的语义相似度
根据步骤2.3提供的领域词汇相似度,正负样本的答案间所对应的语义相似度按照公式(4)进行计算,并将计算结果由大到小排序后提供给步骤3。其中,m和n分别为两个句子中的词汇集合,n1,n2,…,nn为集合n中的词汇,医学领域词汇ω与句中词汇的最大相似度maxvalue(ω,n)的计算公式如公式(5)所示。
maxvalue(ω,n)=max(sim(ω,n1),sim(ω,n2),…,sim(ω,nn))(5)
第三步:结合步骤2.2和步骤2.4得到的负样本排序结果,对负样本进行分段采样,构建多个训练集并训练基模型。
3.1分段采样
针对步骤2.2和步骤2.4得到的负样本排序结果,分别在词形和语义这两个相似度序列上对负样本进行均匀分段,并在不同段内采样,以构成不同训练集。这里,每个分段l中第i个问题所采集的负样本集
如图3所示,以分段数l等于3为例,介绍了基于词形相似度分段采样负样本,样本间的远近由样本间的词形相似度距离决定。其中,s为正样本,s1-s9为负样本,第一个样本集中的负样本从第一段中的s1、s2、s3中抽取,第二个样本集中的负样本从第二段中的s4、s5、s6中抽取,以此类推,最终生成三个训练样本集。
3.2确定分段数
分段数将直接决定基模型的个数以及基模型的学习粒度,因此本发明通过设计一个预实验来确定适用的分段数。预实验以acc@1为评价指标,并基于bigru_cnn模型结构进行,实验结果如图4所示。实验结果表明,当分段数为3时,即分别将3个基于负样本语义相似度分段采样得到的基模型与3个基于负样本词形相似度分段采样得到的基模型集成在一起,acc@1效果最好。当分段数太少时不能发挥模型多粒度学习的优势,因此模型性能有限。但是,当分段数为4或5时,基模型之间的区分度降低,导致acc@1指标值比段数为3时略有减少,且产生的基模型个数过多导致算法计算时间较长,因此最终划定分段数为3。将分段数为3时采集到的负样本集分别与正样本结合,构成训练集并对模型进行训练,训练完毕后将得到基模型mi提供给步骤4。
第四步:利用加权平均对步骤3中得到的基模型进行集成,从而得到最终的问答模型。
对步骤3提供的全部基模型mi(i∈2l),按照加权平均的组合方式将各个基模型集成,权重wi(i∈2l)取决于基模型在验证集上的准确率pi,准确率高的基模型在整体模型中所占的权重比要更大。最终得到的集成模型预测概率h(x)如公式(6)、(7)所示。其中t为基模型的总个数,hi(x)为每个基模型预测的结果,wi是基模型各自对应的权重。
创新点
提出了一种基于负样本多样性的问答模型集成方法,与目前医疗问答领域的模型集成方法不同,本发明能利用多种相似度,对问句所对应答案的正负样本间距离进行计算,由此完成负样本的排序,避免了单一相似度导致模型准确率低的问题。之后利用分段采样的方法获取不同的负样本集,并将其分别作为训练数据集训练产生不同的基模型,最后通过加权平均实现基模型的集成。
本发明提出的模型集成方法在中文医疗问答对数据集上有较好的表现,提高了中文医疗问答系统的准确率。
- 还没有人留言评论。精彩留言会获得点赞!