用于GPU的L1高速缓存共享方法
用于gpu的l1高速缓存共享方法
技术领域
1.本发明涉及gpu技术领域,具体涉及一种用于gpu的l1高速缓存共享方法。
背景技术:
2.图形处理器(graphics processing unit,gpu)是一种用于做图像和图形相关运算工作的微处理器,gpu因其强大的计算能力在云计算平台和数据中心被广泛应用,为用户提供所需要的计算。与只在gpu上运行一个任务的单任务gpu相比,多任务gpu可以在gpu上同时运行多个任务,能够有效提高资源的利用率。具体地,多任务gpu可以在一个gpu上同时运行计算密集型程序和存储密集型程序,gpu上的计算资源和存储资源可以同时得到充分的利用。
3.目前主要采用空间多任务方式实现gpu同时运行多个任务,具体地,在空间多任务方式中,gpu上的所有sm(streaming multiprocessor,流多处理器)平均分为两组,每一组sm用来运行一个应用程序。空间多任务gpu通过空间上的共享,能够同时运行计算密集型程序和存储密集型程序,提高计算资源和存储资源的利用率。
4.然而,同时运行计算密集型程序和存储密集型程序的空间多任务gpu虽然能够有效地提高系统的整体资源利用率,但是在不同的sm上运行不同的程序将导致sm上资源尤其是l1高速缓存(一级高速缓存,l1 cache)资源利用不平衡,影响多任务gpu性能的进一步提升。具体地,对于运行存储密集型程序的sm而言,这类程序会产生大量的访存请求,导致l1高速缓存资源被过度使用,l1高速缓存失效率较高,而失效的请求通过片上互联网络被发送到l2高速缓存(二级高速缓存,l2 cache)以及存储系统,将带来较大的访存开销;对于运行计算密集型程序的sm而言,这类程序的访存请求很少,导致l1高速缓存资源无法得到充分利用。
技术实现要素:
5.为解决上述现有技术中存在的部分或全部技术问题,本发明提供一种用于gpu的l1高速缓存共享方法。
6.本发明公开了一种用于gpu的l1高速缓存共享方法,包括以下步骤:
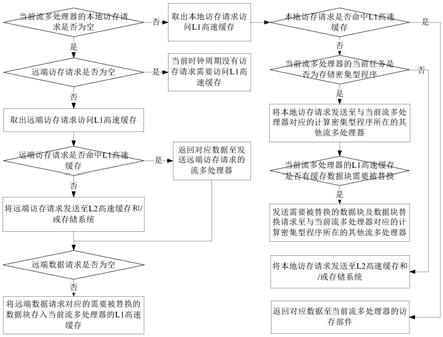
7.s11,判断当前流多处理器的本地访存请求是否为空,若是,执行步骤s21,若否,执行步骤s12;
8.s12,取出所述本地访存请求访问l1高速缓存;
9.s13,判断所述本地访存请求是否命中l1高速缓存,若是,返回对应数据至所述当前流多处理器的访存部件,若否,执行步骤s14;
10.s14,判断所述当前流多处理器的当前任务是否为存储密集型程序,若是,将所述本地访存请求发送至与所述当前流多处理器对应的计算密集型程序所在的其他流多处理器,并执行步骤s15,若否,将所述本地访存请求发送至l2高速缓存和/或存储系统;
11.s15,判断所述当前流多处理器的l1高速缓存是否有缓存数据块需要被替换,若
是,发送需要被替换的数据块及数据块替换请求至与所述当前流多处理器对应的计算密集型程序所在的其他流多处理器;
12.s21,判断远端访存请求是否为空,若否,执行步骤s22,其中,所述远端访存请求表示其他流多处理器发送至所述当前流多处理器的访存请求;
13.s22,取出所述远端访存请求访问l1高速缓存;
14.s23,判断所述远端访存请求是否命中l1高速缓存,若是,返回对应数据至发送所述远端访存请求的流多处理器,并执行步骤s24,若否,将所述远端访存请求发送至l2高速缓存和/或存储系统,并执行步骤s24;
15.s24,判断远端数据请求是否为空,若否,将所述远端数据请求对应的需要被替换的数据块存入所述当前流多处理器的l1高速缓存,其中,所述远端数据请求表示其他流多处理器发送至所述当前流多处理器的数据块替换请求。
16.在一些可选的实施方式中,在流多处理器中创建本地访存请求队列单元,用于以队列结构存储当前流多处理器产生的访存请求。
17.在一些可选的实施方式中,所述取出所述本地访存请求访问l1高速缓存,包括:
18.取出所述本地访存请求队列单元中位于本地访存请求队列的头部的访存请求访问所述当前流多处理器的l1高速缓存。
19.在一些可选的实施方式中,在流多处理器中创建远端访存请求队列单元,用于以队列结构存储其他流多处理器发送的访存请求。
20.在一些可选的实施方式中,所述取出所述远端访存请求访问l1高速缓存,包括:
21.取出所述远端访存请求队列单元中位于远端访存请求队列的头部的访存请求访问所述当前流多处理器的l1高速缓存。
22.在一些可选的实施方式中,在流多处理器中创建远端数据请求队列单元,用于以队列结构存储其他流多处理器发送的数据块替换请求。
23.在一些可选的实施方式中,所述将所述远端数据请求对应的需要被替换的数据块存入所述当前流多处理器的l1高速缓存,包括:
24.将所述远端数据请求队列单元中位于数据块替换请求队列的头部的数据块替换请求对应的需要被替换的数据块存入所述当前流多处理器的l1高速缓存。
25.在一些可选的实施方式中,在流多处理器中创建选择逻辑单元,所述选择逻辑单元用于本地访存请求、远端访存请求和远端数据请求的判断和选择。
26.在一些可选的实施方式中,通过所述当前流多处理器在当前程序运行中对l1高速缓存的访问频率来判断所述当前流多处理器的当前任务是否为存储密集型程序。
27.在一些可选的实施方式中,若所述当前流多处理器的l1高速缓存的每千条指令的访问数大于预设阈值,判定所述当前流多处理器的当前任务为存储密集型程序。
28.本发明技术方案的主要优点如下:
29.本发明的用于gpu的l1高速缓存共享方法能够实现运行存储密集型程序的流多处理器sm使用运行计算密集型程序的流多处理器sm上的l1高速缓存,充分利用gpu中的l1高速缓存资源,提高系统的资源利用率,解决空间多任务gpu中运行不同任务时流多处理器sm上l1高速缓存使用率不平衡的问题。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.图1为本发明一实施例的用于gpu的l1高速缓存共享方法的流程图;
32.图2为本发明一实施例的流式多处理器微体系架构示意图。
具体实施方式
33.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明具体实施例及相应的附图对本发明技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
34.以下结合附图,详细说明本发明一实施例提供的技术方案。
35.参见图1,本发明一实施例提供了一种用于gpu的l1高速缓存共享方法,该方法用于同时运行计算密集型程序和存储密集型程序的空间多任务gpu,空间多任务gpu采取均分的方式将gpu上的流多处理器sm分为两组,一组流多处理器sm运行计算密集型程序,另一组流多处理器sm运行存储密集型程序,运行存储密集型程序的流多处理器sm均有一个运行计算密集型程序的流多处理器sm与之对应,不同的流多处理器sm通过片上互联网络相互连接,实现各流多处理器之间的数据通信;该用于gpu的l1高速缓存共享方法包括以下步骤:
36.s11,判断当前流多处理器的本地访存请求是否为空,若是,执行步骤s21,若否,执行步骤s12;
37.s12,取出本地访存请求访问l1高速缓存;
38.s13,判断本地访存请求是否命中l1高速缓存,若是,返回对应数据至当前流多处理器的访存部件,若否,执行步骤s14;
39.s14,判断当前流多处理器的当前任务是否为存储密集型程序,若是,将本地访存请求发送至与当前流多处理器对应的计算密集型程序所在的其他流多处理器,并执行步骤s15,若否,将本地访存请求发送至l2高速缓存和/或存储系统;
40.s15,判断当前流多处理器的l1高速缓存是否有缓存数据块需要被替换,若是,发送需要被替换的数据块及数据块替换请求至与当前流多处理器对应的计算密集型程序所在的其他流多处理器;
41.s21,判断远端访存请求是否为空,若否,执行步骤s22,其中,远端访存请求表示其他流多处理器发送至当前流多处理器的访存请求;
42.s22,取出远端访存请求访问l1高速缓存;
43.s23,判断远端访存请求是否命中l1高速缓存,若是,返回对应数据至发送远端访存请求的流多处理器,并执行步骤s24,若否,将远端访存请求发送至l2高速缓存和/或存储系统,并执行步骤s24;
44.s24,判断远端数据请求是否为空,若否,将远端数据请求对应的需要被替换的数据块存入当前流多处理器的l1高速缓存,其中,远端数据请求表示其他流多处理器发送至
当前流多处理器的数据块替换请求。
45.其中,若本地访存请求和远端访存请求均为空,则表示当前时钟周期没有访存请求需要访问l1高速缓存。
46.本发明一实施例中,针对图形处理器gpu的每一个流多处理器sm,均采用上述的l1高速缓存共享方法,能够实现运行存储密集型程序的流多处理器sm使用运行计算密集型程序的流多处理器sm上的l1高速缓存,充分利用gpu中的l1高速缓存资源,提高系统的资源利用率,解决空间多任务gpu中运行不同任务时流多处理器sm上l1高速缓存使用率不平衡的问题。
47.参见图2,本发明一实施例中,在流多处理器中创建本地访存请求队列单元,用于以队列结构存储当前流多处理器产生的访存请求。
48.进一步地,当本地访存请求以队列结构进行存储时,该l1高速缓存共享方法中,取出本地访存请求访问l1高速缓存,具体包括:
49.取出本地访存请求队列单元中位于本地访存请求队列的头部的访存请求访问当前流多处理器的l1高速缓存。
50.参见图2,本发明一实施例中,在流多处理器中创建远端访存请求队列单元,用于以队列结构存储其他流多处理器发送的访存请求。
51.进一步地,当远端访存请求以队列结构进行存储时,该l1高速缓存共享方法中,取出远端访存请求访问l1高速缓存,具体包括:
52.取出远端访存请求队列单元中位于远端访存请求队列的头部的访存请求访问当前流多处理器的l1高速缓存。
53.参见图2,本发明一实施例中,在流多处理器中创建远端数据请求队列单元,用于以队列结构存储其他流多处理器发送的数据块替换请求。
54.进一步地,当数据块替换请求以队列结构进行存储时,该l1高速缓存共享方法中,将远端数据请求对应的需要被替换的数据块存入当前流多处理器的l1高速缓存,具体包括:
55.将远端数据请求队列单元中位于数据块替换请求队列的头部的数据块替换请求对应的需要被替换的数据块存入当前流多处理器的l1高速缓存。
56.参见图2,本发明一实施例中,在流多处理器中创建选择逻辑单元,选择逻辑单元用于本地访存请求、远端访存请求和远端数据请求的判断和选择。
57.具体地,在流多处理器中创建了本地访存请求队列单元、远端访存请求队列单元和远端数据请求队列单元的基础上,选择逻辑单元分别与本地访存请求队列单元、远端访存请求队列单元、远端数据请求队列单元和l1高速缓存相互连接,选择逻辑单元判断和选取本地访存请求队列单元、远端访存请求队列单元和远端数据请求队列单元内部的请求,并将选取的请求发送至l1高速缓存。
58.由于应用程序的性能参数能够反映应用程序的特点和应用程序的运行类型,而相比于计算密集型程序,存储密集型程序在程序运行中对l1高速的访问频率较高;为此,本发明一实施例中,可以通过当前流多处理器在当前程序运行中对l1高速缓存的访问频率来判断当前流多处理器的当前任务是否为存储密集型程序。
59.具体地,若当前流多处理器的l1高速缓存的每千条指令的访问数apki大于预设阈
值,判定当前流多处理器的当前任务为存储密集型程序。
60.每千条指令的访问数(access per kilo
‑
instruction,apki)是反映应用程序访问内存的频率的参数,具有高apki值的应用程序拥有更多的内存访问。
61.其中,预设阈值例如可以为10。
62.需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。此外,本文中“前”、“后”、“左”、“右”、“上”、“下”均以附图中表示的放置状态为参照。
63.最后应说明的是:以上实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1