一种基于改进YOLOv4的轻量级行人车辆检测方法
一种基于改进yolo v4的轻量级行人车辆检测方法
技术领域
1.本发明涉及计算机视觉领域,具体涉及一种基于改进yolo v4的轻量级行人车辆检测方法。
背景技术:
2.随着人工智能的快速发展,作为计算机视觉领域的一个分支,目标检测技术取得了许多突破性成果。得益于技术的突破,目标检测技术开始逐渐向实际应用迈进,被广泛应用于自动驾驶、视频监控和国防军事等多个领域。对于自动驾驶,快速准确地对行人车辆进行识别是保障自动驾驶安全性的重要环节。虽然现阶段行人车辆检测技术已经取得了长足的发展,但是仍然存在一些问题。首先,对于自动驾驶的交通场景,目标检测算法更多的需要部署在边缘和移动设备中,这对于设备的算力和内存来说都是一个挑战。现有的许多方法体积大、检测速度较慢,无法兼顾准确性和实时性的需求。其次,现有的方法不能很好的解决多尺度问题,尤其对于小目标存在漏检或误检现象。
3.目前基于深度学习的目标检测算法大致分为两类:基于区域建议的两阶段(two
‑
stage)检测算法和基于回归预测的单阶段(one
‑
stage)检测算法。其中,两阶段方法一般检测精度高,但检测速度慢,单阶段方法检测精度较低但速度快。典型的单阶段算法有ssd(single shot multibox detector)和yolo(you only look once:unified,real
‑
time object detection)等系列,其网络模型参数相对较少,虽然准确度相对较低,但在实时性上表现优越。随着技术的不断发展,现有的许多目标检测算法已经拥有较高的检测精度,但体积较大,不适用于车辆系统这种边缘设备,检测速度仍有提升空间。
技术实现要素:
4.为了克服已有方法体积大、检测速度慢的不足,本发明提供一种基于改进yolo v4的轻量级行人车辆检测方法,有效降低模型的参数量,在保证检测精度的同时提升模型的目标检测速度。
5.为实现上述目的,本发明采用的技术方案是:
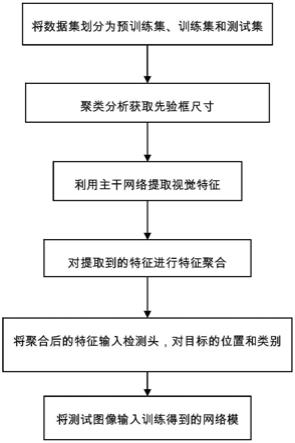
6.一种基于改进yolo v4的轻量级行人车辆检测方法,所述方法包括以下步骤:
7.1)将数据集划分为训练集、验证集和测试集,分别用于模型的训练和测试;
8.2)对数据集标签中的真实目标框进行聚类分析,分别得到9种不同的先验框尺寸;
9.3)利用主干网络提取数据集的视觉特征,过程如下:
10.利用ghost模块构造bottleneck,使用bottleneck搭建主干网络。所述ghost模块包含卷积操作和线性操作,特征图输入ghost模块后,依次经过卷积层、归一化层和激活层后获得中间特征图,将所述中间特征图送入线性分支后与所述中间特征图堆叠后输出。每个bottleneck包括ghost模块、bn层和激活函数,共同构成网络参数θ,主干网络可表征为函数f
θ
。将高为h,宽为w的样本数据输入主干网络,分别在网络第5、第11、第16个bottleneck后分批次输出三组不同尺寸的特征图,该过程公式如下:
11.feat1=f
θ1
(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
12.feat2=f
θ2
(feat1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
13.feat3=f
θ3
(feat2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
14.式中x为输入图像,且x∈r3×
h
×
w
,feat1、feat2、feat3分别代表输出的三组特征值,其中feat1∈r
40
×
h
×
w
,feat2∈r
112
×
h
×
w
,feat3∈r
160
×
h
×
w
。
15.4)对提取到的特征进行特征聚合,过程如下:
16.将步骤3)提取到的三组特征,分别输入到三个不同扩张率的空洞卷积层中,通过变化感受野,提升模型的多尺度感知能力。feat1对应的空洞卷积扩张率为1,负责感知特征图中的小尺寸目标;feat2对应的空洞卷积扩张率为2,负责感知特征图中的中尺寸目标;feat3对应的空洞卷积扩张率为3,负责感知特征图中的大尺寸目标。各层扩张率与感受野的关系如下式:
17.r=k+(k
‑
1)
×
(d
‑
1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
18.式中,r为感受野尺寸,k为卷积核尺寸,d为扩张率。
19.将空洞卷积层输出的特征送入特征聚合网络,对特征图进行降采样、升采样、拼接、卷积和bn操作,其中卷积层由卷积模块和dbm模块构成,以进一步缩减模型参数量,输出三组聚合后的特征图用于最终的检测;
20.所述dbm模块结构为:特征图输入模块,依次经过一个逐通道卷积层,一个批次归一化层,一个relu6激活层,一个逐点卷积层,一个批次归一化层,再经过relu6激活函数后输出。
21.5)将聚合后的特征输入yolo检测头,对目标的位置和类别进行预测,利用损失函数训练模型;
22.6)将测试集图像输入训练得到的网络模型进行检测,输出目标的检测结果。
23.进一步,所述步骤1)的操作为:将kitti数据集划分为最终的训练集、验证集和测试集。其具体步骤为:合并、删除数据集中的部分类别,最终的类别包括行人、汽车;将数据集按照voc数据集的文件路径存放;将数据集的注释文件由txt格式转换为xml格式;将数据集按照8:1:1的比例划分为训练集、验证集、测试集。
24.再进一步,所述步骤2)的操作为:利用k
‑
means算法对数据集标签中的真实目标框进行聚类分析。其中,采用框与框之间的交并比(iou)构建距离度量函数s,函数s如下:
25.s=1
‑
iou(box1,box2)
ꢀꢀꢀ
(5)。
26.所述步骤5)的操作为:将步骤4)聚合得到的特征图分别输入三个yolo检测头,对目标的位置和类别进行预测,各分支分别输出一组形式为n
×
n
×3×
(4+1+c)的向量,n表示该尺度分支下的特征图尺寸,3表示该尺度分支下的预测框数量,4和1分别表示预测框的坐标和置信度,c表示数据的类别数量;
27.利用损失函数对模型进行训练,损失函数采用complete
‑
iou loss,如下式:
[0028][0029]
式中,l
ciou
为预测框的位置损失,b,b
gt
分别为预测框和真实框,b,b
gt
分别为预测框和真实框的中心点坐标,ρ2()表示欧氏距离,c包含预测框与真实框的最小矩形的对角线长度,α为权重函数,v函数用于度量长宽比的相似性,α,v函数的定义分别如下:
[0030][0031][0032]
式(9)中,w
gt
,h
gt
分别表示真实框的宽和高,w,h分别表示预测框的宽和高;
[0033]
设置网络模型参数型输入图像的尺寸、9个先验框尺寸、识别种类的数量和标注的各种类名称、初始学习率以及学习率调整策略,对模型进行训练;训练过程中使用验证集进行验证,训练至网络模型收敛后保存最终的权重文件。
[0034]
所述步骤6)的操作为:加载所述步骤5)训练得到的模型权重,将测试集输入网络,进行特征提取及特征聚合后,由检测头得到可能包含行人、车辆目标的边界框坐标、置信度和类别概率,利用非极大值抑制去除冗余的检测框,产生最终的检测结果。
[0035]
本发明的有益效果主要表现在:
[0036]
(1)利用ghost模块搭建主干网络,用于提取图像特征,分批次输出三组特征,在保证特征质量的前提下缩减了模型的参数量。
[0037]
(2)在主干网络和特征聚合网络之间分别嵌入不同扩张率的空洞卷积,在不增加计算量的前提下,提升网络模型对于不同尺寸目标的感应能力。
[0038]
(3)利用深度可分离卷积构建dbm模块,在特征聚合网络中使用dbm模块。相较于普通卷积模块,显著缩减了模型的参数量。
[0039]
(4)针对实际应用中移动端设备对于模型大小和实时性的需求,本发明提出一种基于改进yolo v4的轻量级行人车辆检测方法,模型参数量较小、检测速度快,且在一定程度上保有了精度,可更好的适应移动端设备,为目标检测的实际应用创造条件。
附图说明
[0040]
图1为本发明方法的流程图;
[0041]
图2为本发明的网络结构图;
[0042]
图3为ghost模块的结构图;
[0043]
图4为bottleneck的结构图;
[0044]
图5为主干网络的结构图
[0045]
图6为dbm模块的结构图。
具体实施方式
[0046]
为了使本发明的目的、技术方案及优点更加明确清晰,以下结合附图对本发明中的具体实施细节做进一步阐述。
[0047]
参照图1~图6,一种基于改进yolo v4的轻量级行人车辆检测方法,包括以下步骤:
[0048]
1)、整合训练、测试所需的目标检测数据集;
[0049]
所述步骤1)的操作为:将kitti数据集划分为最终的训练集、验证集和测试集。其具体步骤为:合并“行人”、“骑自行车的人”和“坐着的人”三种类别,合并“卡车”、“货车”、
“
轿车”、“有轨电车”四种类别,并删除数据集中的部分类别,最终的类别包括行人、汽车;将数据集按照voc数据集的文件路径存放,即标签文件夹annotations、图片文件夹pngimages和目录文件夹imagesets;将数据集的注释文件由txt格式转换为xml格式;将数据集按照8:1:1的比例划分为训练集、验证集、测试集。分别生成训练集、验证集和测试集的目录txt文件,命名为train.txt、val.txt、test.txt。再根据train.txt、val.txt、test.txt生成按行存储图片绝对路径和标签位置及类别的汇总文件kitti_train.txt、kitti_val.txt、kitti_test.txt。
[0050]
2)、利用k
‑
means算法对数据集标签中的真实目标框进行聚类分析。其中,采用框与框之间的交并比(iou)构建距离度量函数s,函数s如下:
[0051]
s=1
‑
iou(box1,box2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0052]
其中,
[0053][0054]
式中area表示区域的面积。
[0055]
11最终得到9种不同的先验框(anchor
‑
box)尺寸,分别为[8,71],[9,24],[14,33],[19,54],[23,163],[26,38],[37,67],[59,109],[97,197]。
[0056]
3)、利用主干网络提取数据集的视觉特征;
[0057]
所述步骤3包括:
[0058]
(3.1)利用ghost模块构造bottleneck,使用bottleneck搭建主干网络,其中,ghost模块的结构如图3所示,bottleneck的结构如图4所示,搭建的主干网络结构如图5所示,主干网络可表征为函数f
θ
;
[0059]
(3.2)将尺寸为416
×
416的图像输入主干网络,分别在网络第5、第11、第16个bottleneck后分批次输出三组不同尺寸的特征图,其尺寸分别为[52,52,40]、[26,26,112]、[13,13,160]。
[0060]
该过程作如下表示:
[0061]
feat1=f
θ1
(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0062]
feat2=f
θ2
(feat1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0063]
feat3=f
θ3
(feat2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0064]
式中x为输入图像,且x∈r3×
416
×
416
,feat1、feat2、feat3分别代表输出的三组特征值,其中feat1∈r
40
×
52
×
52
,feat2∈r
112
×
26
×
26
,feat3∈r
160
×
13
×
13
。
[0065]
4)、对提取到的特征进行特征聚合;
[0066]
所述步骤4过程如下:
[0067]
(4.1)将步骤3提取的三组特征,分别输入到三个不同扩张率的空洞卷积层中,通过变化感受野,提升模型的多尺度感知能力。扩张率与感受野的关系如下式:
[0068]
r=k+(k
‑
1)
×
(d
‑
1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0069]
feat1对应的空洞卷积扩张率为1,负责感知特征图中的小尺寸目标;feat2对应的空洞卷积扩张率为2,负责感知特征图中的中尺寸目标;feat3对应的空洞卷积扩张率为3,负责感知特征图中的大尺寸目标。最终,送入特征聚合网络的特征图尺寸分别为[52,52,128]、[26,26,256]、[13,13,512]
[0070]
(4.2)利用深度可分离卷积构建dbm模块。dbm模块的结构如图6所示,特征图输入模块,依次送入一个逐通道卷积层,一个批次归一化层(batch normalization),一个relu6激活层,一个逐点卷积层,一个批次归一化层,再经过relu6激活函数后输出。
[0071]
(4.3)原有yolov4网络中,特征聚合网络在每次拼接操作后接有5个cbm卷积模块。如图2所示,使用dbm模块替换各cbm卷积模块组中的第2个和第4个cbm模块,卷积核数量设置为原有cbm模块的2倍。
[0072]
5)、将聚合后的特征输入检测头,对目标的位置和类别进行预测;利用损失函数对模型进行训练;
[0073]
所述将聚合后的特征输入检测头,对目标的位置和类别进行预测的过程为:
[0074]
将步骤4)聚合得到的特征图分别输入三个yolo检测头,对目标的位置和类别进行预测,各分支分别输出一组形式为n
×
n
×3×
(4+1+2)的向量,n表示该尺度分支下的特征图尺寸,3表示该尺度分支下的预测框数量,4和1分别表示预测框的坐标和置信度,2表示行人和车辆两种类别;
[0075]
所述利用损失函数对模型进行训练的操作为:
[0076]
(5.1)损失函数采用complete
‑
iou loss,如下式:
[0077][0078]
式中,l
ciou
为预测框的位置损失,b,b
gt
分别为预测框和真实框,b,b
gt
分别为预测框和真实框的中心点坐标,ρ2()表示欧氏距离,c包含预测框与真实框的最小矩形的对角线长度,α为权重函数,v函数用于度量长宽比的相似性,α,v函数的定义分别如下:
[0079][0080][0081]
式(8)中,w
gt
,h
gt
分别表示真实框的宽和高,w,h分别表示预测框的宽和高。
[0082]
(5.2)在ubuntu18.04系统下配置环境,keras框架下实现网络结构。
[0083]
(5.3)输入图像尺寸为416
×
416,预选框使用步骤2聚类分析得到的9种尺寸,批尺寸(batch size)设为8,训练轮数设为500,基础学习率设为0.001,采用余弦退火算法进行学习率衰减。
[0084]
(5.4)在kitti训练集上进行训练。训练过程中,通过kitti验证集的损失曲线观察网络的训练进度,训练至网络模型收敛,保存最终训练得到的权重文件。
[0085]
6)、利用kitti测试集对训练得到的网络模型进行性能测试。
[0086]
所述步骤6)的操作为:
[0087]
(6.1)载入训练得到的最优模型权重,将测试集送入训练好的网络模型中,经过ghost模块搭建的主干网络进行特征提取,输出三组尺寸为[52,52,40]、[26,26,112]、[13,13,160]的特征,再经过空洞卷积后送入特征聚合网络。最终由yolo检测头得到可能包含行人、车辆等目标的边界框坐标、置信度和类别概率,利用非极大值抑制去除冗余的检测框,产生最终的检测结果。
[0088]
(6.2)根据测试集的真实框位置和模型的预测结果,计算本实例网络模型的平均精度均值map(mean average precision),对模型的精度进行评价。其中,iou阈值设置为0.5。
[0089]
(3)统计模型的参数量,分别测试模型在gpu和cpu上的检测速度(fps),与现有的主流目标检测方法对比结果如表1所示:
[0090][0091][0092]
表1
[0093]
由测试结果可见,本实例的网络模型在保证精度的同时,拥有更小的参数量,检测速度较快,降低了模型对于硬件存储能力和计算能力的要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1