身份、位置和动作识别方法、系统、电子设备及存储介质
1.本发明涉及与智能空间结合的安防领域,尤其涉及一种身份、位 置和动作识别方法、系统、电子设备及存储介质。
背景技术:
2.现代社会的很多公共场所如市政场所、工业区、医院、校园、体 育馆、商场、饭店、商业写字楼等,人口密集且流动性大,为了保证 正常运转,通常设置了大量工作人员来维持良好的秩序并应对突发状 况。随着现代信息技术的发展,很多场所安装了具有视频监控系统的 安防系统,然而目前安防系统中,视频监控系统与报警系统往往相互 独立,视频监控系统依旧是传统的被动监控模式,只能对异常情况进 行视频记录。
3.智慧空间是嵌入了计算、信息设备和多模态的传感装置的工作或 生活空间,具有自然便捷的交互接口,以支持人们方便地获得计算机 系统的服务。可以应用到学校、医院、行政机构、商场、食堂、体育 馆等场景,用于智能视频监控、智能考勤和智能教学等功能,形成物 理空间与网络信息空间的融合,未来在智能家居,智能安防,人机交 互等众多领域有着广阔的应用前景,对于构建数字化、网络化和智能 化的智慧城市具有重要的现实意义。
技术实现要素:
4.本发明的目的是提供一种身份、位置和动作识别方法、系统、电 子设备及存储介质,用以至少部分解决现有技术中存在的问题。
5.具体地,本发明实施例提供了以下技术方案:
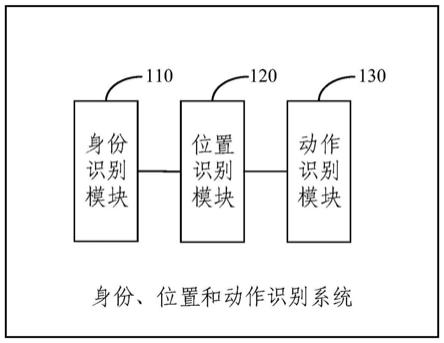
6.第一方面,本发明提供了一种身份、位置和动作识别系统,包括: 身份识别模块、位置识别模块和/或动作识别模块;
7.所述身份识别模块用于基于人员的图像识别所述人员的身份;
8.所述位置识别模块用于基于从相对位置固定的多个摄像装置同 时获取的所述人员的图像识别所述人员的位置;
9.所述动作识别模块用于基于包括所述人员的图像的视频帧序列 识别所述人员的动作。
10.可选地,所述身份识别模块包括人脸识别模块,所述人脸识别模 块用于:
11.用openpose对所述人员的图像中的人脸图像进行特征点捕捉。
12.基于所述特征点将所述人脸图像旋转到水平位置;
13.将水平位置的所述人脸图像分成五部分输入tp
‑
gan,得到正面 人脸图像;
14.使用dlib中的resnet
‑
29网络从所述正面人脸图像提取特征向量;
15.基于所述特征向量使用存储有与身份信息对应的图像数据的数 据库进行相似度判别,识别所述人员的身份。
16.可选地,所述基于所述特征点将所述人脸图像旋转到水平位置包 括:
17.计算所述人脸图像中左眼和右眼的像素坐标之差,得到待旋转角 度;
18.以左眼像素坐标为旋转中心,将人脸图像旋转待旋转角度,得到 水平位置的所述人脸图像。
19.可选地,将水平位置的所述人脸图像分成五部分输入tp
‑
gan包 括:
20.从所述人脸图像裁剪出左眼部分、右眼部分、鼻子部分、嘴巴部 分;
21.将所述人脸图像、左眼部分、右眼部分、鼻子部分以及嘴巴部分 按比例保真地缩放,作为tp
‑
gan的输入。
22.可选地,所述基于从相对位置固定的多个摄像装置同时获取的所 述人员的图像识别所述人员的位置包括:
23.使用openpose单姿态估计算法对所述多个摄像装置中的每个摄 像装置获取的所述人员的图像进行二维像素坐标定位,得到每个图像 中人体的二维像素坐标;
24.通过摄像装置标定获取所述多个摄像装置的内外参数;
25.基于所述每个图像中人体的二维像素坐标和所述多个摄像装置 的内外参数,重建人体三维位置坐标,从而识别所述人员的位置。
26.可选地,所述动作识别模块包括数据处理子模块、特征提取子模 块以及动作分类子模块;
27.所述数据处理子模块包括数据预处理过程和视频帧采样过程;
28.所述特征提取子模块包括融入注意力的残差网络;
29.所述动作分类子模块包括两层长短时记忆网络。
30.可选地,所述数据预处理过程采用数据增强算法,所述数据增强 算法将所述视频帧序列中的每张图像按原有顺序,以在给定范围内的 随机单位长度和随机方向进行水平方向上的平移。
31.可选地,所述视频帧采样过程采用视频帧采样算法,所述视频帧 采样算法对所述视频帧序列的中间段进行采样。
32.可选地,所述融入注意力的残差网络的残差部分包括分别使用1
ꢀ×
1、3
×
3和1
×
1卷积核的三个卷积层。
33.第二方面,基于本发明第一方面所述的身份、位置和动作识别系 统所实现的身份、位置和动作识别方法,包括:
34.通过设置在空间中相对位置固定的摄像装置捕捉包括人员图像 的视频帧序列;
35.将所述视频帧序列输入身份、位置和动作识别系统,所述身份、 位置和动作识别系统通过身份识别模块识别所述人员的身份,通过位 置识别模块识别所述人员的位置,通过动作识别模块识别所述人员的 动作。
36.第三方面,本发明实施例还提供了一种电子设备,包括存储器、 处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处 理器执行所述程序时实现如第二方面所述身份、位置和动作识别方法 的步骤。
37.第四方面,本发明实施例还提供了一种非暂态计算机可读存储介 质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第 二方面所述身份、位置和动作识别方法的步骤。
38.第五方面,本发明实施例还提供了一种计算机程序产品,所计算 机程序产品包括有计算机程序,该计算机程序被处理器执行时实现如 第二方面所述身份、位置和动作识别
方法的步骤。
39.根据本发明实施例提供的身份、位置和动作识别系统和方法,通 过身份识别模块、位置识别模块及动作识别模块能够在人流密集的空 间中识别人员身份,确定人员位置及该人员的行为,从而节省工作人 员的精力,实现智能化、主动化的监控。
附图说明
40.图1是本发明实施例提供的身份、位置和动作识别系统的结构示 意图;
41.图2是本发明实施例提供的数据处理过程的流程图;
42.图3是本发明实施例提供的残差网络与传统网络的结构图;
43.图4是本发明实施例提供的改进的残差网络的结构图;
44.图5是本发明实施例提供的通道注意力模块的结构图;
45.图6是本发明实施例提供的融入注意力的残差网络的结构图;
46.图7是本发明实施例提供的身份、位置和动作识别方法的流程图;
47.图8是本发明实施例提供的电子设备的结构示意图。
具体实施方式
48.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结 合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、 完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是 全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有 做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护 的范围。
49.本发明实施例提出一种身份、位置和动作识别方法、系统、电子 设备及存储介质,可以利用rikibot ros机器人搭载深度摄像头与 激光雷达对空间进行slam定位与建图,采集局部细节,构建全面监控 区域。在该空间中可以设置多个相机对人员进行信息捕捉,依托网络 服务器,实时识别人员身份、所处位置以及正在执行的动作,并与报 警系统连接,当系统检测到人员的异常行为,如肢体冲突、意外摔倒、 非法入侵等,可实现自动报警功能。
50.参考图1,图1是本发明实施例提供的身份、位置和动作识别系统 的结构示意图,本发明实施例提供的身份、位置和动作识别系统包括 身份识别模块110、位置识别模块120和动作识别模块130。
51.所述身份识别模块110用于基于人员的图像识别所述人员的身份;
52.所述位置识别模块120用于基于从相对位置固定的多个相机(摄 像装置)同时获取的所述人员的图像识别所述人员的位置;
53.所述动作识别模块130用于基于包括所述人员的图像的视频帧序 列识别所述人员的动作。
54.其中身份识别模块110包括人脸识别模块。人脸识别作为最重要 的生物特征识别技术之一,与其他需要被检测者辅助的技术相比,具 有明显的被动优势。而基于面部特征的识别可以应用于低成本的视觉 传感器,因此在日常生活中得到了广泛的应用。典型的人脸识别系统 一般由检测模块、对齐模块、表示模块和匹配模块组成。检测模块用 于定位人脸区域。对准模块将检测到的面部区域与参考面部特征点进 行变换。表示模块将人脸图像
映射到用于识别的向量空间。在匹配模 块,通过相似性度量方法对人脸描述符向量进行比较,以区分它们是 否是同一个人。对于多角度人脸的识别,该方法主要有整体方法、基 于特征的方法等。近年来,利用深度学习算法很好地解决了越来越多 的计算机视觉问题,其在目标识别和图像生成方面也取得了很好的进 展。
55.本发明实施例提出的人脸识别模块将视频作为输入,提出了包括 人脸旋转方法和基于gan的正面人脸生成与识别方法,对于视频帧, 首先用openpose进行特征点捕捉,捕捉的特征点用于将人脸旋转到水 平位置,之后将图像切割成五部分以通过tp
‑
gan生成正面人脸。接 下来使用dlib中的resnet
‑
29网络作为本系统的特征提取模型。该模型 可将输入的面部图像转化为128维向量,并与提前向量化的本地人像 数据库进行比对。本系统使用欧式距离进行相似度判别,该模型定义 当两组向量的欧式距离小于0.6时,可将其视为相似向量,即二者身 份信息匹配为同一人。最终可输出图像中包含的身份信息。
56.在大多数情况下,视频中捕捉到的面部往往是倾斜的。为了使用 tp
‑
gan生成正面人脸,本发明实施例的系统使用基于面部特征点的 旋转面部的方法。
57.本系统中的面部定位模型基于openpose,openpose是基于部分亲 和场和关节亲和场的人体关键点估计方法。对于一个人,面部定位模 型可以检测到70个面部关键点。以图像所在的平面为x、y轴所在的平 面,建立(x,y,z)直角坐标系,每个关键点具有位置(x,y)和检 测置信度c。为了将面部旋转到水平方向,计算左眼和右眼像素坐标 之差,得到待旋转的角度θ:
[0058][0059]
其中(x
reye
,y
reye
)是右眼的坐标,(x
leye
,y
leye
)是左眼的坐标。
[0060]
得到角度θ后,使用上述面部关键点将图像旋转到水平位置。在 本发明实施例中,以左眼坐标(x
leye
,y
leye
)作为旋转中心。常用的图像旋 转方法是选择图像的中心作为旋转中心,但这种旋转方法不适合用 于人脸旋转,因为人脸并不总是在图像的中心。当角度θ很大时,使 用常规方法来旋转,可能会将面部区域旋转出图像区域。
[0061]
得到将面部旋转到水平方向的图像后,通过计算得到旋转后的 面部关键点的坐标,以用来裁剪面部区域。具体地,为了提高系统 的运行速度,可以将整个旋转过程视为绕z轴旋转θ度的过程,建立 旋转矩阵,如式(2)所示:
[0062][0063]
其中(x
reye
,y
reye
)是旋转中心,b是原始坐标系,a是旋转坐标系。
[0064]
将原始图像的面部关键点的坐标通过变换成为矩阵形式的
b
p, 则通过旋转矩阵,得到旋转后的图像面部关键点的坐标矩阵
a
p:
[0065]
[0066]
接下来将图像分成五部分以通过tp
‑
gan生成正面人脸。 tp
‑
gan是一个双通路网络,包括全局通路和局部通路。前者侧重 于面部轮廓,后者侧重于局部纹理。两个路径对应的特征图的组合 将生成正面的面部图像。
[0067]
本发明实施例提供的身份、位置和动作识别系统使用了keras 和tensorflow来实施tp
‑
gan,采用python在anaconda上开发。 具体地,使用cmu muliti
‑
pie人脸数据库进行训练,该数据库包含 超过337位受试者的75000张图像,其中受试者被从15个视角捕捉 图像。首先,使用一个轻型cnn模型训练新的分类器,并根据 muliti
‑
pie微调提取器。经过微调后,训练模型的损失值为0.997。 然后,在谷歌ml引擎上训练gan模型。最终,本发明实施例提供 的tp
‑
gan取得了较好的面部生成效果。
[0068]
为了提取特征,将图像分成的五部分:128
×
128分辨率的人脸 图像、40
×
40分辨率的左眼和右眼图像、40
×
32分辨率的鼻子图像 和40
×
32分辨率的嘴巴图像。由于所需图像的分辨率远远低于输入 图像的分辨率,可以使用一个合适的缩放比例来不失真地缩放。
[0069]
首先,在旋转后的128
×
128像素的图像中缩放脸部部分的尺寸。 使用通过上述式(3)得到的旋转后的图像面部关键点的坐标,建立 旋转图像和缩放图像之间的数学关系。具体地,将人脸部分所需图 像边界设为f:
[0070]
[x
left
,x
right
,y
upper
,y
lower
]
f
ꢀꢀꢀꢀꢀꢀ
(4)
[0071]
然后,对128
×
128分辨率的人脸图像中的眼睛、鼻子和嘴巴部 分进行裁剪。为了获得目标分辨率的截图,使用的缩放比例为 旋转后的眼、鼻、口的坐标表示为(x
n
,y
n
),其在128
ꢀ×
128分辨率的人脸图像中的位置为(u
n
,v
n
),通过式(5)可得:
[0072][0073]
所需部分图像的高度和宽度为(h,w)。则其边界可以表示为:
[0074][0075]
最后,将通过式(6)得到128
×
128分辨率的人脸图像中的眼睛、 鼻子和嘴巴部分等四部分的图像,以及通过式(4)得到的128
×
128 分辨率的人脸图像,共五部分图像作为tp
‑
gan的输入,生成正面 人脸图像。
[0076]
得到正面人脸图像后,为了识别该人的身份,使用dlib中的 resnet
‑
29网络作为本系统的特征提取模型,将人脸图像转化为128 维的特征向量,使用欧几里得距离来度量生成图像与本地数据集之 间的相似性,并取最小值作为最终结果,当两张人脸图像的特征向 量之间的欧氏距离小于0.6时,可以认为是同一个人,完成身份识别。
[0077]
根据本实施例提供的身份识别模块通过用openpose对包括人 脸图像的视频帧进行特征点捕捉,基于捕捉的特征点将人脸旋转到 水平位置,将旋转后的图像分成五部分输入tp
‑
gan,得到正面人 脸图像,使用dlib中的resnet
‑
29网络作为特征提取模型提取特征 向量,将提取的向量与数据库中的特征向量进行相似度判别,识别 身份信息。本实施例提供的身份识别模块可以将包括多个人的画面 中的所有人脸旋转到水平方向,即使部分人脸被覆盖。本发明实施 例提供的身份识别模块在大姿态人脸识别方面具有更好的性能,如 与没有采用本发明提出的人脸旋转方法和基于gan的正面人脸生 成与识别方法的dilb中
的resnet
‑
29网络相比,本发明实施例提供 的身份识别模块可以对受试者头部偏转角度大于
‑
60
°
的人脸图像进 行特征提取并识别身份,还可以对受试者头部偏转角度大于+50
°
的 人脸图像进行特征提取,而没有采用本发明提出的人脸旋转方法和 基于gan的正面人脸生成与识别方法的dilb中的resnet
‑
29网络无 法做到。
[0078]
本发明另一实施例提供的身份识别模块可以包括步态识别模块, 步态识别是通过人们走路的姿态进行身份识别,具有非接触、远距 离识别和不容易伪装的优点,在智能视频监控领域具有明显优势。 由于行人在肌肉力量、肌腱和骨骼长度、骨骼密度、重心等方面有 一定的差异,基于上述这些差异可以唯一地标注一个人,利用这些 特性可搭建人体运动模型或直接从人体轮廓里提取特征实现步态识 别。步态识别模块主要包括步态采集、步态分割、特征提取、特征 比对等模块。步态识别模块的输入是一段行走的视频图像序列,该 视频序列捕获了行人在行走过程中的持续变化,步态识别算法从中 挖掘该行人的步态特征,并将这些新获取的步态特征与数据集中存 储的步态特征进行比对,进而完成识别。
[0079]
本发明另一实施例提供的身份识别模块可以包括行人重识别模 块,在智慧空间人员身份行为实时分析与报警系统中,由于相机分 辨率和拍摄角度的缘故,可能无法得到质量非常高的人脸图片。因 此当人脸识别失效的情况下,行人重识别技术(re
‑
id)便成为一项 非常重要的替代品技术。
[0080]
行人重识别(person re
‑
identification)也称行人再识别,被广泛认 为是一个图像检索的子问题,是利用计算机视觉技术判断图像或者 视频中是否存在特定行人的技术。行人重识别技术可以弥补目前固 定摄像头的视觉局限,并可与行人检测、行人跟踪技术相结合,应 用于视频监控、智能安防等领域。
[0081]
在本系统中,当相机无法检测到人脸图像时(如面部遮挡、光 线不足等),采用行人重识别技术作为替代方案,将行人重识别技术 与动作识别、位置识别等技术相结合,实时分析室内人员身份与行 为动作。
[0082]
本发明实施例提供的身份、位置和动作识别系统包括位置识别 模块120,本发明实施例提供的身份、位置和动作识别方法包括基于 多相机的人体位置获取方法。
[0083]
在室外环境中,人体位置定位主要由卫星导航技术实现。在室 内环境中,蓝牙定位、wi
‑
fi定位、红外定位、uwb定位、rfid定 位等技术正不断发展并应用到人们的日常生活中,室内定位技术在 教室、实验室等场所可以对人员进行实时定位。在智能安防领域, 当定位对象被检测出危险时,可立即发出报警并确定人员位置。在 应急场景下,如消防救援、应急疏散、抗震救灾等,室内定位信息 显得尤为重要。
[0084]
本发明实施例提供的位置识别模块120包括从相对位置固定的 多个相机获取人体图像,上述多个相机具有设定的内外参数,并对 焦于同一区域,同时获取人体图像。获取的人体图像用于结合相机 的内外参数,重建人体关节点三维坐标,计算人体所在区域。
[0085]
本发明实施例提供的人体位置获取方法包括使用相机获取人体 图像;计算人体图像中的人体二维像素坐标;通过相机标定获取相 机内外参数;基于人体二维像素坐标和相机内外参数重建人体关节 点三维坐标,基于人体关节点三维坐标计算得到人体位置。
[0086]
其中对于单相机中的人体二维像素坐标定位,本实施例采用基 于openpose的单姿态估计算法对相机采集的人体图像进行处理,在 图像中定位人体的二维关节点。其中openpose开源程序是由美国卡 耐基梅隆大学开发的人体姿态识别项目,是基于卷积神经
网络和监 督学习并以caffe为框架开发的开源库。可以实现人体动作、面部表 情、手指运动等方面的姿态估计,适用于单人和多人,具有极好的 鲁棒性。
[0087]
通过相机标定获取相机内外参数,是人体关节点从二维到三维 转换的前提。对于多个相机标定的问题,本实施例首先采用张正友 双目标定法获取两两相机之间的位置关系,例如相机1与相机2、相 机2与相机3、相机3与相机4等;然后通过变换矩阵的传递性,计 算得到相机1、相机2、相机3、相机4等多个相机相对于世界坐标 系的位置变换矩阵(外部参数);完成多相机标定,得到多个相机的 内外参数。
[0088]
由相机的成像原理可知,空间中三维坐标点显示在相机二维像 素平面的过程实际上是空间点由世界坐标系转换到二维像素坐标系 的过程。在此过程中首先把世界坐标系转换到相机坐标系,然后将 相机坐标系转换到相机物理坐标系,最后将相机物理坐标系转化到 像素坐标系。对于单相机而言,根据相机的内外参数和空间点投影 该相机的二维像素点坐标,可推算出该相机中心点到空间点的射线 方程(世界坐标系下),因此可推断空间点在所求直线上。若计算该 空间点的三维坐标,需计算该空间点与另外某相机的连线,然后计 算两条直线的交点为该空间点,以上内容属于传统的双目视觉定位 问题,然而应用该方法需要人体分别在两相机中清晰成像,对相机 的要求较高,并且在存在遮挡物的情况下,不能满足实际需求,针 对这一问题本发明实施例在双目的基础上引入了多相机,因此三维 重建问题变成多条射线求解交点的问题。然而数据存在不可避免的 噪声,噪声导致由计算估计的射线偏离实际的射线,从而产生多条 直线的交点不存在的问题。因此估算目标点时本研究采用最小二乘 法估计目标关节点。
[0089]
为了准确估计人体三维位置信息,本实施例获取人体25个关节 点的三维位置坐标,例如头部[x
1 y
1 z1]
t
,肩部[x
4 y
4 z4]
t
, 肘部[x
12 y
12 z
12
]
t
,腕部[x
25 y
25 z
25
]
t
等。计算得到人体空间 位置如下式:
[0090][0091][0092]
z
→
[min
i
z
i
,max
i
z
i
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7) 根据式(7)可以确定三维空间中人体所在的最小区域,即获取到的 人体位置。
[0093]
本发明实施例提供的身份、位置和动作识别系统包括动作识别 模块130。
[0094]
动作识别的目标是判断视频中人体正在执行的动作,早期的动 作识别研究中,国内外学者设计了多种手工特征,并进行了大量实 验,如轮廓剪影,人体关节点,时空兴趣点,运动轨迹等。由于依 赖人工特征提取,其抗扰性和泛化能力都较差,无法得到广泛应用。 相比之下,深度学习方法能够自主学习数据特征,并且更加高效准 确。因此,基于深度学习的特征提取方法逐渐取代了人工提取特征 的过程。ji等人第一次提出3d
‑
cnn算法,对时间轴上的视频帧运 用3d卷积核来捕捉时空信息,并将其用于人体动作的识别。tran d 等人提出了c3d网络,并将其用于动作识别、场景识别、视频相似 度分析等领域。carreira等人将2d卷积膨胀为了3d卷积,形成了 膨胀3d卷积网络i3d。donahue等提出了lrcn模型,该网络用 卷积神经网络(convolutional neural network,cnn)提取特征,再 用lstm实现动作分类。在动作识别中,cnn与lstm的使用, 很大程度上提高了识别精度,减少了工作量。然而,随着cnn加 深,将出现严重的梯度消失和网络退化问题。为了解决该问题,本 申请采
用由卷积注意力模块(convolutional block attention module, cbam)和残差网络(resnet)构成的注意力残差网络提取特征。
[0095]
在视频动作识别中,处理的数据不再是单独的一张图像,而是 具有时间顺序的图像序列。如果把视频中的每一帧都作为输入数据 来处理,将极大的增加模型的计算成本。因此,从每个视频中取16 帧作为样本。然后,把样本输入到模型中,进行网络权重的学习。 最后,用softmax分类器对动作进行分类。本发明实施例提供的动 作识别模块130包括三个子模块:数据处理、特征提取以及动作分 类。
[0096]
如图2所示,数据处理子模块主要包括:数据预处理过程和视 频帧采样过程。
[0097]
由于视频数据的原始分辨率通常较大,直接使用计算成本较高, 所以需要对其进行预处理。一种数据预处理过程如下:
[0098]
用ffmpeg模块把视频解析为视频帧序列;
[0099]
对原始的视频帧按训练要求等比例缩放;
[0100]
将缩放后的视频帧进行中心裁剪;
[0101]
把裁剪后的视频帧转换成张量形式;
[0102]
对张量进行正则化。
[0103]
上述数据预处理过程存在两个问题:一,视频帧的中心裁剪会 造成边缘信息丢失;二,动作识别数据集样本容量相对较小,训练 时极易出现过拟合问题。因此,为至少部分解决以上问题,本发明 提出了一种针对视频的数据增强算法,具体过程如算法1所示。
[0104][0105]
在算法1中,用视频帧序列{f1,f2,
…
,f
n
}表示每个动作视频v, 便于使用图像处理的方法间接地对视频数据进行处理。具体而言, 算法1把视频帧序列中的每一张图像按照原来顺序,在给定范围内 进行水平方向上的平移(平移的单位长度和方向是随机的,n=
‑
1, 表示向左平移;n=1,表示向右平移)。如果一个动作视频包含50 帧,且生成随机数的范围是(
‑
6,6),那么经过数据增强处理,最多 可以将数据扩充600倍。与此同时,对视频帧图像进行了水平方向 的平移,还能缓解由中心裁剪造成的边缘信息丢失问题。所以,本 文将数据增强算法加入到了数据预处理中,改进后数据预处理过程 如下:
[0106]
使用数据增强算法把视频解析为视频帧序列;
[0107]
将视频帧序列按训练要求等比例缩放;
[0108]
将缩放后的视频帧进行中心裁剪;
[0109]
把裁剪后的视频帧转换成张量形式;
[0110]
对张量进行正则化。
[0111]
在视频动作识别中,由于动作拍摄的起止与动作本身的起止难 以同步,所以视频的开始和结束阶段通常存在大量的冗余帧。视频 帧采样方法,是在视频帧序列的全时段上采样,其具体过程为:
[0112]
在(0,r
‑
16)之间随机生成一个数l,其中r是视频解析成视频帧 序列后的长度;
[0113]
从第l帧开始,依次选取16帧图像作为模型的输入。
[0114]
上述采样方法,虽然解决了网络模型由于输入造成的计算成本 问题,却没有考虑到在整个视频帧序列中,各个时段所包含的信息 量并不对等的问题。如果随机生成的起始帧位于整个视频中信息量 很低的时段,那么通过上述采样方法得到的输入数据,反而会对模 型产生干扰。
[0115]
本发明实施例对采样方法进行了改进,通过对视频的中间段进 行采样来提升输入信息的质量,如算法2所示。
[0116][0117]
在算法2中,当视频的帧数较小时(n≤48),本实施例采取的 措施是忽略冗余帧的影响,在(0,n
‑
16)范围内随机生成一个整数k, 然后再从第k帧起依次选取16帧图像;当视频的帧数较大时,则剔 除起止时间段内的冗余帧,在(n/3
‑
16,2n/3
‑
16)范围内随机生成一
个 整数k,然后再从第k帧起依次选取16帧图像。
[0118]
对于特征提取子模块,本发明实施例在特征提取过程中,采用 了融入注意力的残差网络结构(resnet+cbam),其原因如下:一, 残差网络中的捷径连接结构(shortcut connection),解决了深层网络 训练中的梯度消失和网络退化问题;二,在残差网络中加入卷积注 意力模块(cbam),能使网络更有针对性地提取特征,增强了其对 判别性特征的表示。
[0119]
相对于传统网络,残差网络(resnet)在其基础上加入了捷径 连接,二者结构对比如图3所示。
[0120]
在图3(b)中,右侧的曲线代表捷径连接,它可以直接把输入x 传递到输出位置,而左侧虚线框中的结构对应残差网络的残差部分, 其输出为f(x)。所以残差网络的输出结果是:
[0121]
h(x)=f(x)+x
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0122]
当f(x)=0时,则h(x)=x,此时为恒等映射。如果浅层网络 已达到了饱和的准确率,那么通过在其后面加上几个恒等映射层, 就能实现增加网络深度而不增大训练误差的目的,也即解决了深层 网络的退化问题。因此,残差网络将残差结果f(x)逼近于0作为学 习目标。此外,由公式(8)可以看出,残差网络在进行误差反向传 播时,由于x的导数恒为1,所以即使f(x)的链式求导趋近于0,也 能有效避免梯度消失问题,进而确保网络权重得到更新。
[0123]
此外,残差网络结构中的两个卷积层通常采用3
×
3的卷积核, 随着网络进一步加深,容易出现参数冗余和计算量倍增的问题。针 对这一问题,本发明实施例采用了图4所示的残差网络改进结构, 它的残差部分由三个卷积层构成,并且分别使用了1
×
1、3
×
3和1
×
1 的卷积核。这里通常用1
×
1卷积核把输入张量的通道降维,使得3
×
3 卷积核作用在size相对较小的张量上,达到提高计算效率的目的, 然后再用1
×
1卷积核把张量的通道升维。对于图4中的捷径连接部 分,若x与f(x)维度不同,则需要使用一个1
×
1卷积对x进行维度 调整。
[0124]
从图5可以看出,通道注意力模块首先利用全局平均池化和最 大池化对输入特征图f进行压缩,然后再把压缩后的两部分特征同时 输入到一个多层感知器mlp(multi
‑
layer perceptron,mlp)中作降维 升维操作,最后将mlp输出的两个向量进行求和运算,再经过 sigmoid函数就得到了通道注意力加权系数m
c
,如式9所示。
[0125][0126]
式中,σ表示sigmoid激活函数,w0和w1是多层感知机mlp 中的权值矩阵,和分别表示平均池化特征和最大池化特征。
[0127]
cbam把输入特征f与通道注意力加权系数m
c
相乘,得到了新 的特征f
′
。然后,将f
′
输入到空间注意力模块得到空间注意力加权系 数m
s
。最后,让m
s
与f
′
相乘就得到了最终的注意力特征f
″
,如式(10) 和式(11)所示。
[0128]
[0129][0130]
如图6所示,本发明实施例中的融入注意力的残差网络 (resnet+cbam)先利用cbam模块先提取输入特征中的关键信 息,再将提取到的关键信息输入到改进后的残差网络中进一步提取 其深度特征。
[0131]
传统的循环神经网络(recurrent neural network,rnn),能够 处理时序问题,但当输入序列较长时,会因梯度消失而无法学习。 为解决这一问题,schmidhuber等提出了长短时记忆网络(lstm), 作为一种特殊结构的rnn,lstm擅长处理长时间序列信息。所以, 在动作分类部分,本发明实施例采用了两层lstm来学习视频帧序 列之间的时序关系,然后利用softmax分类器分类到相应的动作类 别。
[0132]
lstm的基本结构为通过输入门、遗忘门和输出门,完成信息 的输入和输出。其中,输入门由上图中间的σ层、tanh层以及一个 逐点相乘构成,决定了当前时刻的输入x
t
,有多少需要保存 到当前的单元状态c
t
中;遗忘门由上图左侧的σ层和一个逐点相乘 构成,决定了上一时刻的c
t
‑1是否保留到当前时刻的c
t
中;输 出门由上图右侧的σ层和一个逐点相乘构成,决定了当前的 单元状态c
t
有多少可以传递到lstm的当前输出值h
t
中。lstm的 更新递归公式如下:
[0133]
f
t
=σ(w
f
h
t
‑1+u
f
x
t
+b
f
ꢀꢀꢀꢀꢀꢀꢀ
(12)
[0134]
i
t
=σ(w
i
h
t
‑1+u
i
x
t
+b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0135][0136][0137]
o
t
=σ(w
o
h
t
‑1+u
o
x
t
+b
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0138]
h
t
=o
t
·
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0139]
式中:w
f
、w
i
、w
c
、w
o
以及u
f
、u
i
、u
c
、u
o
为相应的权重 矩阵;b
f
、b
i
、b
c
、b
o
为相应的偏置;σ和tanh为激活函数。
[0140]
本发明实施例提供的动作识别模块130通过采用数据增强算法 的数据预处理过程和采用视频帧采样算法的视频帧采样过程的数据 处理子模块、采用融入注意力的残差网络结构的特征提取子模块、 采用两层lstm的动作分类子模块,可以有效增加数据的多样性、 提高数据的质量、增强模型对判别性特征的提取,最终较好地识别 人体的动作。相比现有方法,本发明实施例提出的融入注意力机制 的深度学习动作识别方法能更有效地提取视频数据的空间信息和时 间信息,拥有更好的识别效果。
[0141]
在操作系统ubuntu16.04;深度学习框架pytorch1.6.0;通用并 行计算架构cuda10.2;深度神经网络gpu加速库cudnn7.6.5;显卡 geforce rtx 2080ti,显存11gb;显卡驱动nvidia450.80;硬盘512gb 的实施环境下,对本发明所提出的动作识别方法进行验证。
[0142]
本发明所提出的动作识别方法分别在ucf youtube数据集和 kth数据集上进行了验证。
[0143]
ucf youtube是由佛罗里达大学计算机视觉研究中心发布,包 含1600个视频,分为以下11个动作类别:投篮、高尔夫挥杆、荡 秋千、骑自行车、骑马、遛狗、跳水、颠球、打网
球、跳蹦蹦床、 排球扣球。每个类别包含25组视频,每组又至少包含4个视频片段, 其分辨率为320
×
240。
[0144]
kth数据集有600个视频,包含了尺度、衣着和光照的变化, 其分辨率为160
×
120。该数据集在4种不同场景下,由25个人执行 6类动作,具体包括:走路、慢跑、快跑、拍手、挥手、拳击。
[0145]
为了验证本发明所提出的方法的有效性,将ucf youtube数据 集按照60%作训练集,20%作验证集,20%作测试集来划分。对于 kth数据集,由于样本数量较少,采用5次交叉验证取平均值的方 法,其中每次取80%的数据进行训练,剩下20%进行测试。
[0146]
首先,对于ucf youtube数据集,其分辨率为320
×
240,直接 使用会因计算量过大而导致内存溢出,所以需将其进行缩放,而kth 数据集的分辨率仅为160
×
120,可以直接输入模型。其次,由于视 频动作识别对gpu算力要求很高,为了提升训练效率,对模型的特 征提取部分(resnet+cbam)运用了迁移学习,即:将resnet50 在imagenet上训练好的权重,迁移到本技术所用的resnet结构中。 为了进一步降低网络过拟合的风险,在所有的fc层都使用了 dropout技术,即让fc层的节点按照一定概率随机失活。最后,在 数据加载部分使用多线程技术来加快模型读取数据的速度。本测试 的实验参数设置如表1所示。
[0147][0148]
表1实验参数
[0149]
模型训练结束后,在ucf youtube数据集上本技术所提方法的 识别率达到了95.45%。有9种动作的识别率达到了90%以上。
[0150]
为了说明本技术的方法的优越性,在同一数据集ucf youtube 上分别对模型resnet+lstm,resnet+lstm+算法1, resnet+lstm+算法1+算法2,resnet+cbam+lstm+算法1+算 法2进行试验,然后与现有方法进行比较,如表2所示。
[0151][0152]
表2在ucf youtube上与其他方法的比较
[0153]
由表2可知,在ucf youtube数据集上,本技术提出的基于注 意力残差网络和lstm的视频动作识别方法优于现有的深度学习方 法deep
‑
temporal lstm、proposed db
‑
lstm和 inceptionv3+bi
‑
lstm
‑
attention。此外,在resnet和lstm模型的 基础上,分别验证了算法1、算法2和cbam模块对于模型性能提 升的有效性,实验结果表明,各种改进后的模型
离开入侵区域检测、人员快速移动检测、物品拿取放置检测、徘徊 检测、人物聚集检测。
[0167]
图8示例了一种电子设备的实体结构示意图,如图8所示,该 电子设备可以包括:处理器(processor)810、通信接口(communicationsinterface)820、存储器(memory)830和通信总线840,其中,处理器 810,通信接口820,存储器830通过通信总线840完成相互间的通 信。处理器810可以调用存储器830中的逻辑指令,以执行身份、 位置和动作识别方法,该方法包括:通过设置在空间中相对位置固 定的相机捕捉包括人员图像的视频帧序列;将所述视频帧序列输入 身份、位置和动作识别系统,所述身份、位置和动作识别系统通过 身份识别模块识别所述人员的身份,通过动作识别模块识别所述人 员的位置,通过动作识别模块识别所述人员的动作。
[0168]
此外,上述的存储器830中的逻辑指令可以通过软件功能单元 的形式实现并作为独立的产品销售或使用时,可以存储在一个计算 机可读取存储介质中。基于这样的理解,本发明的技术方案本质上 或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软 件产品的形式体现出来,该计算机软件产品存储在一个存储介质中, 包括若干指令用以使得一台计算机设备(可以是个人计算机,服务 器,或者网络设备等)执行本发明各个实施例所述方法的全部或部 分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom, read
‑
only memory)、随机存取存储器(ram,random accessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0169]
另一方面,本发明还提供一种计算机程序产品,所述计算机程 序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所 述计算机程序包括程序指令,当所述程序指令被计算机执行时,计 算机能够执行上述各方法所提供的身份、位置和动作识别方法,该 方法包括:通过设置在空间中相对位置固定的相机捕捉包括人员图 像的视频帧序列;将所述视频帧序列输入身份、位置和动作识别系 统,所述身份、位置和动作识别系统通过身份识别模块识别所述人 员的身份,通过动作识别模块识别所述人员的位置,通过动作识别 模块识别所述人员的动作。
[0170]
又一方面,本发明还提供一种非暂态计算机可读存储介质,其 上存储有计算机程序,该计算机程序被处理器执行时实现以执行上 述各提供的身份、位置和动作识别方法,该方法包括:通过设置在 空间中相对位置固定的相机捕捉包括人员图像的视频帧序列;将所 述视频帧序列输入身份、位置和动作识别系统,所述身份、位置和 动作识别系统通过身份识别模块识别所述人员的身份,通过动作识 别模块识别所述人员的位置,通过动作识别模块识别所述人员的动 作。
[0171]
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离 部件说明的单元可以是或者也可以不是物理上分开的,作为单元显 示的部件可以是或者也可以不是物理单元,即可以位于一个地方, 或者也可以分布到多个网络单元上。可以根据实际的需要选择其中 的部分或者全部模块来实现本实施例方案的目的。本领域普通技术 人员在不付出创造性的劳动的情况下,即可以理解并实施。
[0172]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了 解到各实施方式可借助软件加必需的通用硬件平台的方式来实现, 当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者 说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该 计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、 磁碟、光盘等,
包括若干指令用以使得一台计算机设备(可以是个 人计算机,服务器,或者网络设备等)执行各个实施例或者实施例 的某些部分所述的方法。
[0173]
最后应说明的是:以上实施例仅用以说明本发明的技术方案, 而非对其限制;尽管参照前述实施例对本发明进行了详细的说明, 本领域的普通技术人员应当理解:其依然可以对前述各实施例所记 载的技术方案进行修改,或者对其中部分技术特征进行等同替换; 而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实 施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1