一种基于片段统计特征比较的时序数据异常波动检测算法的制作方法
本发明涉及一种新的数据异常波动检测算法—一种基于片段统计特征比较的时序数据异常波动检测算法。
背景技术:
数据异常检测是数据分析挖掘的重要研究内容之一。自工业互联网概念提出以来,工业界积累了大量工业设备运行数据。通过对数据进行分析挖掘异常,进而分析工业设备运行特点,了解设备运行状态成为重要的研究内容。尤其是通过对数据异常的发现,对设备的潜在异常进行及时的诊断在保障设备安全运行方面有着重要的意义。
在传统的设备安全保障工作中,通常通过人工对设备进行定期的维护和检修外。通过数据诊断技术保障工业设备安全首要的任务是发现数据中的异常。近年来,工业界也在尝试利用积累的工业设备运行时以及实时监测的设备数据进行相关研究以实现更高效的设备监控和数据异常诊断功能。
当前,对于数据进行异常检测的算法主要可以分为以下几类:基于统计模型、基于聚类、基于相似性度量、基于约束规则等。而这些常见的异常检测方法往往针对有限的数据集规模,且不具备实时性检测能力,一般较难满足大数据量的实时工业数据流异常检测的需求。尤其是面对复杂的工业场景这些算法在计算量和检测效果上都有待提升。传统的异常检测方法并非针对工业实时大数据而设计,例如基于统计的异常检测方法适用于检测离群值异常和波动异常等情况,但对于工业生产中出现的持续的异常区间不能够有效的识别。基于聚类的异常检测方法,主要量化异常点和正常点之间的距离来判断离群点,很难适用于大数据集和实时数据流上的异常检测。且其计算量普遍较大,检测效果依赖聚类的质量。基于相似性度量的异常检测方法主要通过计算序列之间的相似性,来判断目标检测数据是否异常,但此方法计算时间开销较大且时效性不高。基于规则约束的异常检测方法中主要通过顺序依赖、速度约束技巧有效利用时间序列中的时序特征,对高度异常的数据进行修复,但此方法通常难以满足模式多变的序列异常检测的需求。
技术实现要素:
发明目的:本发明针对工业时序数据流异常波动检测需求,提出一种新的数据异常波动检测算法—一种基于片段统计特征比较的时序数据异常波动检测算法。该算法满足工业数据流中的对于数据异常波动时效性和准确性的要求。相对于传统的异常检测算法,该算法专为工业时序数据流所设计,结合了基于统计模型以及相似度衡量的检测方法的优点。降低了计算量,使其能够适应于大数据流,对实时数据流中的异常波动进行及时的检测和识别。通过实际应用证明了算法具备较高的准确性,该算法能够适应工业数据流中的工况变化,减少误报率,对工业时序数据流的异常波动进行准确识别。
技术方案:一种基于片段统计特征比较的时序数据异常波动检测算法,主要包括以下步骤:
步骤1:数据准备;
步骤2:数据片段构建;
步骤3:数据片段统计特征计算;
步骤4:检测执行;
步骤5:结果输出;
根据本发明的一个方面,所述构建目标数据片段表示为:ftt:<d,t,t>。
根据本发明的一个方面,所述对数据片段进行统计特征计算包括但不限于如数据本身,时间标记,均值,以及方差,并将目标数据片段特征构建为目标数据片段特征组:
根据本发明的一个方面,根据gd所包含的数据特征生成个数为n的邻居集数据片段特征组g:
根据本发明的一个方面,在获取了g以及gd后,对于目标数据片段gd的检测,主要使用了基于闵式距离来评价gd与其邻居集g之间的相似性,并获取结果数据集:r=usi。
根据本发明的一个方面,获得了检测结果数据集r,我们要利用该数据集去判断包含检测目标的数据片段ftt是否存在异常:
设置参数ε(ε>0)与λ(λ∈(0,1)),其中ε表示gi与gd允许的距离上限,即当r<ε(r∈r)时,认为数据gd正常;
在结构数据集r中计算认为数据gd正常时gi的个数n,当n/n低于λ时,我们认为数据片段ftt存在异常。
有益效果:本发明的显著优点是通过构建数据片段统计特征,对检测目标进行异常波动检测。与现有的异常检测相比,可以通过有限邻居集数据片段对目标数据片段进行检测,降低计算时间,提高检测效率,使其满足工业大数据检测的时效性。同时检测目标从传统的单点目标检测,优化为片段检测,提升了对检测目标异常波动识别准确度。
附图说明
图1是本发明的总体结构图。
图2是本发明的异常波动检测流程图。
具体实施方式
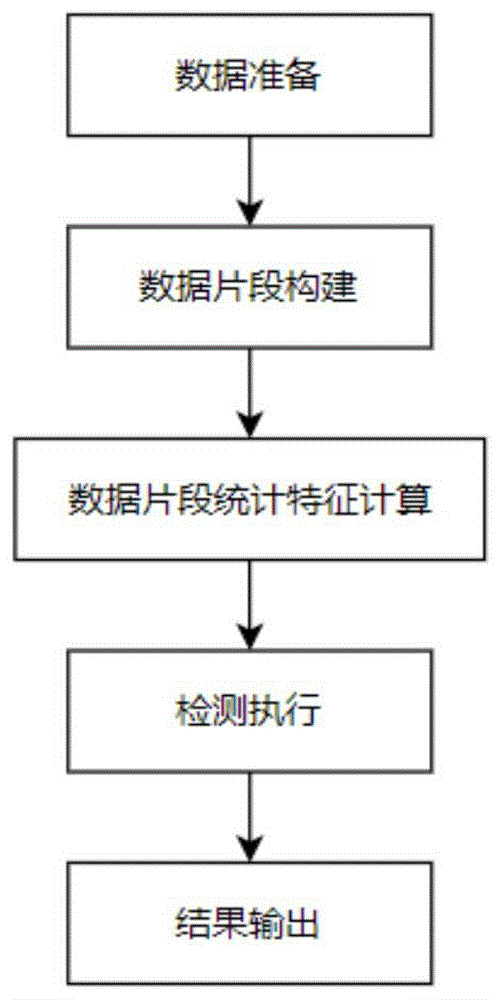
如图1所示,在本实施例中,一种基于片段统计特征比较的时序数据异常波动检测算法主要包括五个部分:
数据准备:是为检测任务准备数据,确定检测目标,是算法执行的准备工作;
数据片段构建:包括两部分,其一是检测目标的数据片段构建;其二是检测目标的邻居集数据片段构建;
片段特征计算:是诊断构建的数据片段,进行统计特征计算;
检测执行:是通过计算邻居集数据片段特征与检测目标数据片段的特征相似度,通过相似度衡量进而判断数据是否存在异常波动;
结果输出:进行结果输出,对检测目标进行异常判定。
下面详细进行说明。
步骤1:数据准备。
实时数据流dt={...,xt-3,xt-2,xt-1,xt}中每一条数据均有一个对应的唯一时间t。数据波动异常检测以实时数据流中的t时刻下的数据为检测目标。
步骤2:数据片段构建。
在实时数据流dt={...,xt-3,xt-2,xt-1,xt}中以xt为待检测目标,构建时间长度为t的检测目标数据片段。构建目标数据片段方法如下:ftt:<d,t,t>,其中d为当前是数据流,t为片段大小,t为片段的终止时刻。ftt为所构建的数据片段:ftt=xt-t,...,xt。
步骤3:数据片段统计特征计算。
数据片段特征是指算法所构建的数据片段所具备包括统计特征等数据信息,如数据本身,时间标记,均值,以及方差等。
其中数据本身指片段中的原始数据,即ftt=xt-t,...,xt;
时间标记指片段ftt=xt-t,...,xt中的时间t;
均值:平均值反应数据的一般趋势。其计算公式如下:
方差:方差是衡量数据离散程度的重要特征,在整个数据片段中,如果出现数据偏离一般趋势,其方差存在较大的变动。其计算公式如下:
最大值:反应数据的上限值:maxf;
最小值:反应数据的下限值:minf;
此处仅将常见的数据统计特征进行举例,在实际操作中,可以根据需要选择其他能够反应数据特点的统计特征,将目标数据片段特征构建为目标数据片段特征组:
通过构建目标数据片段特征组,将对于数据的异常波动检测转为对数据片段特征组的检测,能够有效的挖掘数据特征,提高检测的准确度。
步骤4:检测执行。
首先根据步骤3从历史数据中dt-1={...,xt-4,xt-3,xt-2,xt-1}中,根据gd所包含的数据特征生成个数为n的邻居集数据片段特征组g;数据如下:
在构建邻居集数据片段特征组g的过程中,主要考虑以下四个方面:
其一:时效性:对于时序性数据,当gd的时间标记为t时,gi的时间标记应在有效范围内,不应距离t较远;
其二:周期性:对于时序性数据,应当充分考虑其数据是否存在周期性特征,根据周期性特点构建相对应的gi;
其三:随机性:在考虑前两个要求的前提下,应尽可能在时间维度上随机地构建gi;
其四:设置合理的参数n:在获取了g以及gd后,对于目标数据片段gd的检测,主要使用了基于闵式距离来评价gd与其邻居集g之间的相似性:
使用带权闵式距离的优势是能够根据需要调节参数ωu以调整算法对
通过对检测点特征组的数据进行距离计算后,获取结果数据集r=usi。
步骤5:结果输出。
在步骤4中我们获得了检测结果数据集r,我们要利用该数据集去判断包含检测目标的数据片段ftt是否存在异常:
设置参数ε(ε>0)与λ(λ∈(0,1)),其中ε表示gi与gd允许的距离上限,即当r<ε(r∈r)时,认为数据gd正常;
在结构数据集r中计算认为数据gd正常时的gi个数n,当n/n低于λ时,我们认为数据片段ftt存在异常。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!