一种基于深度散列与多特征融合的增量图像检索方法
1.本发明属于图像处理方法技术领域,具体涉及一种基于深度散列 与多特征融合的增量图像检索方法。
背景技术:
2.图像检索是一种视觉搜索任务,即是将给定的一张查询图像在一 个非常大的图像数据库中进行检索,进而得到在该数据库中所有与查 询图像具有相同实例对象的图像。图像检索技术目前已在多个领域有 广泛应用,例如在网络上进行反向传播搜索或者组织个人照片收集。 然而,随着计算机和人工智能等相关技术的高速发展及5g通信时代 的迅速推进,包括图像和视频在内的多媒体数据量每天都呈指数增长, 而最新的图像检索模型并不总是及时可用,一旦出现新的概念,就必 须对检索模型进行更新,从而导致模型训练的时间成本大大增加。因 此,提出一种能够直接提取新图像的特征信息同时不用再次训练旧图 像的增量图像检索方法是图像检索技术领域急需解决的问题。
3.在ilsvrc
‑
2012比赛中,krizheysky等人设计了一种深度卷积 神经网络模型alexnet,该模型将图像分类错误率从26.2%降到15.3%, 远远领先于其他算法(krizhevsky a,sutskeveri,hinton g e.imagenetclassification with deep convolutional neural networks[c]//internationalconference on neural information processing systems.lake tahoe, nevada,usa:nips press.2012:1106
‑
1114.)。这使得cnn(卷积神经 网络)在视觉图像领域得到极大的重视,使其一跃成为图像检索基础 模型的首选。随后babenko等人利用大型卷积神经网络的顶层的激活 作为图像检索的描述符(babenko a,slesarev a,chigorin a,et al. neural codes for image retrieval[c]//european conference on computervision.switzerland,zurich:springer press,2014:584
‑
599.)。该方法通 过对相似数据上的模型进行重新训练,然后提取神经代码作为描述符, 进一步提升了检索结果。曹等人提出了hashnet深度体系结构,通过 延续方法生成散列码,它学习非平滑的二进制激活,使用延续方法从 不平衡的相似性数据生成二进制散列码(cao zhangjie,longmingsheng,wang jianmin,et al.hashnet:deep learning to hash bycontinuation[c]//proceedings of the ieee international conference oncomputer vision.venice,italy:ieee press,2017:5608
‑
5617.)。白等人 提出了一个深度渐进式哈希(dph)模型,通过利用逐步扩展的显著区 域生成一系列二进制码(bai jiale,ni b,wang m,et al.deepprogressive hashing for image retrieval[j].ieee transactions onmultimedia,2019,21(12):3178
‑
3193.)。王等人提出了一种深度位置感 知哈希(dpah)模型,它限制了数据样本与类中心之间的距离,以提 高图像检索中二进制散列码的识别能力(wang ruikui,wangruiping,qiaoshishi,et al.deep position
‑
aware hashing for semanticcontinuous image retrieval[c]//ieee winter conference onapplications of computer vision.snowmass,co,usa:ieee press, 2020:2493
‑
2502.)。
[0004]
近年来,基于深度学习的方法已经在图像检索方面取得了巨大的 进步,但在对于大量新图像的出现时导致的模型更新训练时间长,检 索模型的适应性差等问题还没有完全解决,当新的图像出现时,如何 不用再次训练模型就能实现模型的更新是目前图像检索领域的重要 课题。
技术实现要素:
[0005]
本发明的目的是提供一种基于深度散列与多特征融合的增量图 像检索方法,解决了现有图像检索中新类别图像出现时重新训练模型 困难、耗时长的问题。
[0006]
本发明所采用的技术方案是,一种基于深度散列与多特征融合的 增量图像检索方法,具体包括以下步骤:
[0007]
步骤1、将cifar
‑
10数据集和nus
‑
wide数据集按比例划分出 查询集图像、原始数据集和增量数据集;
[0008]
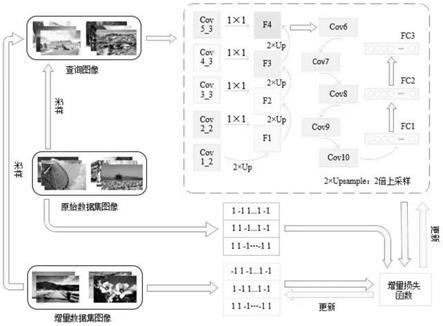
步骤2、使用卷积神经网络vgg
‑
16将查询图像的每一层特征图 像输出;
[0009]
步骤3、将提取的特征图像从高维图像到低维逐层做双线性插值 处理,以匹配上一层特征图像的尺寸大小,并且将双线性插值处理过 的特征图像逐层上采样得到融合的特征图像;
[0010]
步骤4、将步骤3的特征图像输入到五个普通卷积层 conv6
‑
conv10,尺寸大小都为7
×
7,维度分别为64,192,384,256 和256维,输出得到特征图像f;
[0011]
步骤5、经过步骤3和步骤4,将vgg
‑
16改进后得到新的模型, 即为idfh模型,将步骤4中输出的特征像图f进行散列函数学习, 使用idfh模型构造散列函数,使特征图像f的最后一个全连接层的 长度输出为k,即是二进制散列码的长度;
[0012]
步骤6、使用增量损失函数保持查询点和数据库点之间的相似性。
[0013]
本发明的特点还在于,
[0014]
步骤1中,在cifar
‑
10数据集中随机选取1000张图像作为查 询集图像,每个类100张图像,其余的作为数据集图像;同样的在 nus
‑
wide数据集中随机选择2100张图像作为查询集图像,每个概 念相关的有100张图像,其余的作为数据集图像,形成r张图像的查 询集;然后将数据集图像分为原始数据集和增量数据集两个部分;其 中cifar
‑
10数据集图像的原始数据集和增量数据集的类别比例为 7/3,nus
‑
wide数据集的原始数据集和增量数据集的类别比例为 18/3。
[0015]
步骤2中,具体为:在查询集图像中随机选取一张作为 查询图像d
i
输入到基础卷积神经网络vgg
‑
16中,并输入到基础卷积 神经网络vgg
‑
16中,基础网络vgg
‑
16的每一个大卷积层,即 conv1
‑
2,conv2
‑
2,conv3
‑
3,conv4
‑
3和conv5
‑
3分别提取到的特征 图命名为第一层特征图像f1,第二层特征图像f2,第三层特征图像f3, 第四层特征图像f4,第五层特征图像f5,相邻的最大特征图之间相差 步幅为2的空间分辨率,输出的特征图像的大小依次为224
×
224、 112
×
112、56
×
56、28
×
28和7
×
7。
[0016]
步骤3中,将步骤2中输出的第五层特征图像f5采用双线性插值 扩大长宽为原来的两倍,然后与上采样后得到的第四层特征图像f4融合,得到特征图像f4;再将特征图像f4采用双线性插值扩大长宽 为原来的两倍,然后再与f3进行融合得到特征图像f3;将特征图像 f3采用双线性插值扩大长宽为原来的两倍,然后再与f2进行融合得到 特征图像f2;将特
征图像f2采用双线性插值扩大长宽为原来的两倍, 然后再与f1进行融合得到特征图像f1。
[0017]
步骤5中,深度散列函数的公式如式(2)所示:
[0018][0019]
式中,b
si
表示有r张图像的查询图像数据集中的散列码, sign()是符号函数,f(
·
)表示最后一个全连接层的输出。
[0020]
步骤6中,具体为:在步骤5之后,将原始数据集图像和增量数 据集图像的索引分别表示为α={1,2,3,
…
,p}和 β={1+p,2+p,3+p,
…
p+q},将原始数据集和增量数据集采样的查询图 像的索引分别表示为和然后 设计了一个增量损失函数使得现有的原始图像的散列码去训练查询 图像的散列码,同时直接优化增量图像的散列码增量损失函数中使用 成对的标签l去减少或扩大相似或不相似对的二进制码之间的汉明 距离,同时采用l2范数损失来最小化二进制编码对的内部乘积与相 似性之间的差异,并将步骤5中学习到的散列函数整合到损失函数中, 从而保持
‑
1和1在所有查询图像中的数量近似相等从而使得每一位 散列码达到平衡,具体如式(3)所示;
[0021][0022]
式中,b’表示有q张图像的增量图像数据集学习到的 散列码,并且并且是b
i
的转置,λ和μ是超参数; a
j
是增量图像数据集中的第i张图像;b
j
是增量图像数据集中的每一 张图像的散列码;当g
ij
=+1表明a
i
和d
j
在语义上是相似的,相反的当 g
ij
=
‑
1则是不相似的,tanh(
·
)是连续松弛方法。
[0023]
本发明的有益效果是:
[0024]
本发明一种基于深度散列与多特征融合的增量图像检索方法,该 方法对vgg16输出的多个特征图像使用双线性插值处理,再融合到 上层特征层,使得特征获得更加完整和丰富的语义信息;在网络高层 增加五个小卷积层对特征进一步卷积,从而提高特征性能以及模型泛 化能力;此外,该方法直接使用学习新图像的散列码的同时保持旧图 像散列码不变,通过保留训练点之间的相似性来学习查询集的深度散 列函数。本发明实现了大规模中出现新的类别图像时不用再次训练模 型,从而提高检索效率,节约时间成本。
附图说明
[0025]
图1是本发明一种基于深度散列与多特征融合的增量图像检索 方法的流程图。
具体实施方式
[0026]
下面结合附图和具体实施方式对本发明进行详细说明。
[0027]
本发明一种基于深度散列与多特征融合的增量图像检索方法,如 图1所示,具体包括以下步骤:
[0028]
步骤1、将cifar
‑
10数据集和nus
‑
wide数据集按比例划分出 查询集图像、原始数据集和增量数据集;
[0029]
cifar
‑
10包括10个类中的60000幅彩色图像。nus
‑
wide包含 21个最常见的概念相关图像,其中每个概念图像都至少与5000张图 像关联,共有195834张图像。在cifar
‑
10数据集中随机选取1000 张图像作为查询集图像,每个类100张图像,其余的作为数据集图像; 同样的在nus
‑
wide数据集中随机选择2100张图像作为查询集图像, 每个概念相关的有100张图像,其余的作为数据集图像,形成r张图 像的查询集;然后将数据集图像分为原始数据集和增量数据集两个部 分。其中cifar
‑
10数据集图像的原始数据集和增量数据集的类别比 例为7/3,nus
‑
wide数据集的原始数据集和增量数据集的类别比例 为18/3,原始数据集中的图像最多与18个概念相关,而增量数据集 中的图像与其余3个概念的至少一个概念相关。
[0030]
步骤2、使用卷积神经网络vgg
‑
16将查询图像的每一层特征图 像输出;
[0031]
具体为:在r张图像的查询集中随机选取一张作为查询 图像d
i
输入到基础卷积神经网络vgg
‑
16中,并输入到基础卷积神经 网络vgg
‑
16中,基础网络vgg
‑
16的每一个大卷积层,即conv1
‑
2, conv2
‑
2,conv3
‑
3,conv4
‑
3和conv5
‑
3分别提取到的特征图命名为 第一层特征图像f1,第二层特征图像f2,第三层特征图像f3,第四层 特征图像f4,第五层特征图像f5,相邻的最大特征图之间相差步幅为 2的空间分辨率,输出的特征图像的大小依次为224
×
224、112
×
112、 56
×
56、28
×
28和7
×
7;
[0032]
步骤3、将提取的特征图像从高维图像到低维逐层做双线性插值 处理,以匹配上一层特征图像的尺寸大小,并且将双线性插值处理过 的特征图像逐层上采样得到融合的特征图像;
[0033]
将步骤2中输出的第五层特征图像f5采用双线性插值扩大长宽为 原来的两倍,然后与上采样后得到的第四层特征图像f4融合,得到特 征图像f4;再将特征图像f4采用双线性插值扩大长宽为原来的两倍, 然后再与f3进行融合得到特征图像f3;将特征图像f3采用双线性插 值扩大长宽为原来的两倍,然后再与f2进行融合得到特征图像f2; 将特征图像f2采用双线性插值扩大长宽为原来的两倍,然后再与f1进行融合得到特征图像f1;其具体计算公式如式(1)所示;
[0034]
f
n
=cat(f
n
,2
×
upsamplef
n+1
)(n=1,2,3,4)(1);
[0035]
式中,cat表示特征融合,f
n
表示第n层卷积输出的特征图,f
n
表示融合后的第n特征图,2
×
upsample表示2倍上采样。
[0036]
步骤4、将融合后的特征图像f1中输入五个卷积层进一步卷积增 强特征性能,再使用三个全连接层整合;
[0037]
将步骤3的特征图像f1输入到五个普通卷积层conv6
‑
conv10, 尺寸大小都为7
×
7,维度分别为64,192,384,256和256维从而增 加特征性能,输出得到特征图像f;
[0038]
步骤5、首先直接使用深度散列方法对增量数据库图像映射得到 散列码b
i
。经过步骤3和步骤4将vgg
‑
16改进后得到新的模型,将 新的模型命名为idfh模型,将步骤4中输出的特征像图f进行散列 函数学习,使用idfh模型构造散列函数,使特征图像f的最后一个 全连接层的长度输出为k,即是二进制散列码的长度,深度散列函数 的公式如式(2)所示:
[0039][0040]
式中,b
si
表示有r张图像的查询图像数据集中的散列码 且θ表示idfh模型中的参数(批处理数,学习 速率,初始学习率),sign()是符号函数,f(
·
)表示最后一个全连接层 的输出。
[0041]
idfh模型具体包括的五个大卷积层conv1(conv1
‑
1,conv1
‑
2), 长和宽为224
×
224,通道数为64,conv2(conv2
‑
1,conv2
‑
2),长和宽 为112
×
112,通道数为128,conv3(conv3
‑
1,conv3
‑
2,conv3
‑
3),长和 宽为56
×
56,通道数为256,conv4(conv4
‑
1,conv4
‑
2,conv4
‑
3),长和 宽为28
×
28,通道数为512,conv5(conv5
‑
1,conv5
‑
2,conv5
‑
3),长和 宽为14
×
14,通道数为512,以及五个普通卷积层conv6
‑
conv10,尺 寸大小都为7
×
7,通道数分别为64,192,384,256和256。
[0042]
步骤6、使用增量损失函数保持查询点和数据库点之间的相似性。
[0043]
具体为:在步骤5之后,将原始数据集图像和增量数据集图像的 索引分别表示为α={1,2,3,
…
,p}和β={1+p,2+p,3+p,
…
p+q},将原始数 据集和增量数据集采样的查询图像的索引分别表示为和然后设计了一个增量损失 函数使得现有的原始图像的散列码去训练查询图像的散列码,同时直 接优化增量图像的散列码增量损失函数中使用成对的标签l去减少 或扩大相似或不相似对的二进制码之间的汉明距离,同时采用l2范 数损失来最小化二进制编码对的内部乘积与相似性之间的差异,并将 步骤4中学习到的散列函数整合到损失函数中,从而保持
‑
1和1在所 有查询图像中的数量近似相等,从而使得每一位散列码达到平衡,具 体如式(3)所示;
[0044][0045]
式中,b’表示有q张图像的增量图像数据集学习到的 散列码,并且并且是b
i
的转置,λ和μ是超参数; g∈{
‑
1,+1}
(p+q)
×
r
表示训练期间成对监督的散列码,a
j
是增量图像数据 集中的第i张图像;b
j
是增量图像数据集中的第j张图像的散列码; 当g
ij
=+1表明a
i
和d
j
在语义上是相似的,相反的当g
ij
=
‑
1则是不相似 的,tanh(
·
)是连续松弛方法。
[0046]
利用上述步骤完成模型的更新以后,查询图像在包含增量数据集 的两个数据集cifar
‑
10和nus
‑
wide中检索,返回出前5000张图 片,并计算平均精度值(map),得到的结果以及与其它方法的比较 如表1所示;
[0047][0048]
式中,tp表示正确的图片数量,fp表示不正确的图片数量。
[0049]
表1两个数据集上的性能(map)对比
[0050][0051]
从表1中可以看出在cifar
‑
10数据集上的12bits、24bits、32bits 和48bits散列性能比之前的算法性能都要好,在散列码长度为12bits、 24bits、32bits、48bits时能达到0.8523、0.8700、0.8866、0.8842,比 dsah的map值分别高0.1123、0.084、0.0856、0.0642。在nus
‑
wide 数据集上时散列码长度为12bits、24bits、32bits时能达到0.8015、 0.8354、0.8570,比dpsh的map值分别高0.074、0.0105、0.0219。 本文模型在nus
‑
wide上的结果比cifar
‑
10要差一些,是因为该数 据集的图像类别距离没有完全明确划分,以及数据集较大导致训练比 较困难。但总的来说当本发明中的方法模型与表中其它算法相比较时, 在两个相同数据集上的性能表现得最好。
[0052]
本发明一种基于深度散列与多特征融合的增量图像检索方法,对 卷积神经网络输出的特征层进行至下而上的二倍上采样到上一层特 征,使得融合后的特征具有更好的低层位置信息和高层语义信息,从 而更好的描述图像;使用改进后的卷积神经网络直接学习新图像的散 列码同时保持旧图像散列码不变,通过增量损失函数保持查询训练点 和增量训练点之间的一致性。能提高检索精度,缩短大规模图像数据 集模型训练时间和改善模型适应性,实现了快速、高效、准确的目的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1