一种双流解码跨任务交互网络的光学遥感图像显著目标检测方法
1.本发明属于计算机视觉处理技术,具体涉及一种双流解码跨任务交互网络的光学遥感图像显著目标检测方法。
背景技术:
2.显著目标检测主要是模仿人类的视觉注意机制,从整个视野中提取视觉上独特的目标。显著目标检测的目标是完全分割显著性目标,生成像素级显著性图。显著目标检测的处理过程分为两个阶段:(1)从背景中成功确定显著区域;(2)准确分割显著目标。
3.虽然近几十年来对自然场景图像显著目标检测的研究取得了显著的成功,但针对光学遥感图像显著目标检测的研究却非常有限。通常,光学遥感图像覆盖范围广,背景复杂,噪声干扰多样。光学遥感图像的显著目标检测等研究具有极其实用的价值,作为预处理技术被广泛应用于遥感场景中的各种视觉应用,如图像融合、场景分类、目标检测等。
4.不同于摄影师用手持相机拍摄的自然场景图像,光学遥感图像是通过部署在卫星或飞机上的各种传感器自动采集的,只有极小的人为干预,这导致了自然场景和遥感场景中显著目标检测之间有明显差距。光学遥感图像是通过高空拍摄获得的,传感器和目标的距离是灵活的。而自然场景图像通常是从一个手动调整得到合适的距离拍摄获得的。因此,自然场景图像中目标的尺度变化差异相对较小。相比之下,在光学遥感图像中出现的目标,即使是同一类别,也表现出很大的尺度差异。因此,自然场景图像显著目标检测方法在处理尺度变化大的遥感显著目标时,其准确率会降低。由于光学遥感图像是从俯视视角拍摄的,被包含的目标不可避免地有不同的方向。而在近距离自然场景图像中,目标的旋转问题很大程度上可以忽略。遥感场景背景噪声更加多样,受各种成像条件(如拍摄时间、光照强度等)影响导致的阴影、强曝光等问题,进一步增加光学遥感图像提取显著性线索的难度。综上所述,光学遥感图像具有覆盖范围广、目标多样性、类间和类内差异大、背景信息复杂等特点。因此,将现有的自然场景图像显著目标检测方法直接应用于光学遥感图像是不可靠的。
5.目前,光学遥感图像显著目标检测仍然面临着一些严重阻碍其检测性能的挑战。主要是目标检测不完整和边界预测模糊问题。为了缓解这些问题,目前的研究人员在显著目标检测方法中,成功地采用了注意力机制来学习更具判别力的特征,抑制背景干扰。然而,目前的方法只考虑利用注意力对前景特征进行优化,忽略了对背景特征的学习,从而获得次优的检测性能。事实上,前景特征优化和背景特征优化是两个相辅相成的任务。通过多层前景特征和背景特征的交互学习得到的线索对最终的预测有积极的影响。
技术实现要素:
6.发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种双流解码跨任务交互网络的光学遥感图像显著目标检测方法ddcinet,本发明通过多层前景特征、背景
特征的交互式学习来克服背景混乱、目标检测不完整和显著目标尺度差异大等问题。
7.技术方案:本发明的一种双流解码跨任务交互网络的光学遥感图像显著目标检测方法,包括以下步骤:
8.步骤s1、将待检测图像输入神经网络,其中使用在imagenet数据集上预训练的resnet
‑
50卷积神经网络作为网络主干;
9.步骤s2、使用金字塔型非局部提取模块pnem提取图像中的尺度差异大的目标,以及获取全局上下文信息和长距离依赖关系;得到侧输出特征f
ci
,
10.步骤s3、通过转换模块首先将网络主干中多层特征的通道数统一至128,并将非局部提取模pnem获取的全局上下文信息传递至所有低层特征,来优化主干网络特征;
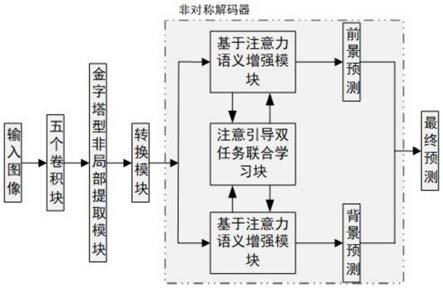
11.步骤s4、在非对称解码器中分别对前景特征和背景特征使用基于注意力的语义增强模块asem,将高层的语义信息传递到低层特征中,使得目标的定位更加准确;
12.步骤s5、在上述步骤s4分别对前景特征和背景特征进行增强的过程中,同时使用注意力引导双任务联合学习模块adjlb对前景特征和背景特征之间联合学习以及互相优化;通过该操作使得前景特征和背景特征相互指导并融合,最后得到更加完善的前景特征和背景特征;
13.步骤s6、将前景预测图p1和背景预测图p2相减得到最终预测图。
14.为减少计算量,本发明采用resnet
‑
50卷积神经网络作为网络主干,且共设有5个卷积块,每个卷积块是由多个卷积层构成,每个卷积块的输出通道分别为64、256、512、1024和2048,并将最后一个卷积块的通道数从2048减少至128,得到d5。
15.进一步地,所述非对称解码器中将背景检测任务作为辅助任务,将前景检测任务作为主要任务;前景目标检测能够将光学遥感图像的目标检测出来,但是遥感场景中,有时背景更加简单目标更复杂,因此本发明将背景检测任务作为辅助任务,能够进一步避免显著目标分割不完整。
16.进一步地,所述金字塔型非局部提取模块包含4个平行的分支,每个分支的输入为d5;其中三个分支的结构相似,包含卷积核大小为3的空洞卷积(膨胀率分别为1,3,5)和non
‑
local模块;这三个分支空洞卷积的卷积核大小不同,用于捕获不同的感受野,从而更加适应尺度差异大的目标;剩余的一个分支利用全局平均池化来提取全局上下文信息;最后将四个分支全部级联得到的特征使用卷积核大小为1的卷积层把通道数降至128得到f
p
;
17.然后使用元素级乘法和加法操作,将resnet
‑
50五个卷积块的侧输出f
convi
与f
p
结合得到新的五个侧输出特征f
ci
。
18.进一步地,所述resnet
‑
50五个卷积块的侧输出f
convi
与f
p
结合的具体操作为:
[0019][0020]
其中,i=1,2,3,4,5,cv是卷积核大小为1的卷积层;f
convi
是resnet
‑
50五个卷积块的侧输出;f
p
是金字塔型非局部提取模块的输出特征,mc(*)是由卷积核大小为3的卷积层、batchnorm和relu函数组成,f
tr
是新的五个侧输出。
[0021]
进一步地,将f
tr
中相邻不同层次的特征作为基于注意力的语义增强模块的输入;为消除冗余信息,针对不同层次的特征,使用不同的注意力来提高重要信息的表达,并且抑制不重要区域信息;
[0022]
对于低层特征,首先对其分别使用平均池化和最大池化,并级联两个池化的结果,再使用卷积层得到2维的空间注意力图,具体为:
[0023][0024][0025]
其中,conv表示卷积层,avgpooling和maxpooling分别表示平均池化和最大池化,cat表示特征按通道维度级联;σ(*)表示sigmoid激活函数;
[0026]
对于高层特征,首先将低分辨率特征上采样至与低层特征尺寸大小相同,然后使用注意力机制自动获取每个特征通道重要性;具体地,使用全局平均池化将高层特征的全局空间信息压缩到一个通道描述符中;
[0027]
为利用挤压操作后的信息,首先使用两个全连接层和一个relu函数来限制复杂度,然后使用门控学习得到权值向量,权值向量对每个原始特征通道进行加权;操作为:
[0028][0029]
其中ψ(*,w
i
)代表以w
i
(w1∈r1×1×
c/16
,w2∈r1×1×
c
)为参数的全连接层,ρ(*)代表relu函数,σ(*)代表sigmoid函数;
[0030]
最后结合高层特征和低层特征,采用元素级乘法和加法操作,具体操作为:
[0031][0032]
其中tmconv(*)代表三个连续的mc(*)操作;
[0033]
由于最高层只有一个输入,所以使用三个连续的卷积层代替基于注意力的语义增强模块。
[0034]
进一步地,所述注意力引导双任务联合学习模块的输入包括前景特征和背景特征,分别对前景特征和背景特征进行处理,在处理过程中,背景特征和前景特征互相完善对方特征信息,且这两种特征的处理过程是对称结构。
[0035]
当需要进行前景特征处理时,使用平均池化和最大池化处理输入的前景特征,之后使用含一个隐含层的感知器来处理池化之后的特征,具体操作为:
[0036][0037]
其中,o
es
是输入的特征,其中o∈{f,b};sn(*)是具有一个隐藏层的多层感知器,是ca模块之后的结果;
[0038]
为避免前景信息在传输过程丢失,采用背景特征来辅助前景特征的提取,用元素级乘法和加法来为不完整的前景信息补充,具体操作为:
[0039]
[0040]
f
rs
和分别代表通过感知器之后的前景特征和背景特征,和分别代表注意力引导的前景特征和背景特征;
[0041]
之后前景特征和背景特征相互指导并融合,得到更加完善的前景特征和背景特征,具体操作为:
[0042][0043]
f
rs'
和是注意力引导双任务联合学习模块adjlb的输出。
[0044]
进一步地,前景特征检测时,在前景检测分支的第i(i=1,2...5)层增加边界辅助模块,此边界辅助模块能够提高输出的边界特征的准确度;包含四个平行的分支,第k个分支包含k
‑
1个卷积核大小为3的卷积层,然后把四个分支的级联起来,并用卷积核大小为1的卷积层将通道数减到128;最终,使用交叉熵损失来使得边界特征更加精确,具体操作为:
[0045][0046]
其中p
b
和g
b
分别代表预测边界图和真值边界标签。
[0047]
进一步地,为得到更加精细的特征,在前景检测分支还增加r模块来级联相邻层的图像特征,具体操作为:
[0048][0049]
其中f
c
是边界特征,r
b
和r
f
分别表示细化后的背景特征和前景特征;
[0050]
上述过程中为同时考虑像素之间的关系以及能够一致性高亮显著目标,此处将两种损失函数相结合
[0051]
其中,l
cel
为一致性增强损失函数,能处理由不同尺度物体引起的前景和背景区域之间像素不平衡的问题,具体为:
[0052][0053]
p
*
和g
*
分别代表预测显著图和真值标签;
[0054]
其中,l
j
为lov
á
sz损失函数,能够解决预测图中的空间不一致问题。具体为:
[0055][0056][0057]
其中,g
i
,
j
是图像的真值标签,s
r,c
是预测显著图。
[0058]
有益效果:本发明相较现有技术具有以下优点:本发明从前景特征和背景特征的交互式学习出发,通过所得线索克服阴影干扰、成像模糊等挑战,联合优化多层背景特征和背景特征,并将高层次的注意线索逐步转换为低层次的特征,生成高质量的预测图,得到更优的检测性能。
[0059]
综上所述,本发明联合优化多层前景特征和背景特征,并将高层次的全局线索逐步传输到低层次的特征,最终生成高质量的预测图。
附图说明
[0060]
图1为本发明的流程示意图;
[0061]
图2为本发明的检测网络模型示意图;
[0062]
图3为实施例中能够的p
‑
r曲线示意图;
[0063]
图4为实施例中平均精确率和平均召回率的对比图;
[0064]
图5为实施例中视觉对比示意图;
[0065]
图6为实施例中预测指标对比示意图;
[0066]
图7为实施例中max f
β
分数示意图。
具体实施方式
[0067]
下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
[0068]
如图1所示,本发明的双流解码跨任务交互网络的光学遥感图像显著目标检测方法,包括以下步骤:
[0069]
步骤s1、将待检测图像输入神经网络,其中使用在imagenet数据集上预训练的resnet
‑
50作为网络主干;
[0070]
步骤s2、使用金字塔型非局部提取模块pnem提取图像中的尺度差异大的目标,以及获取全局上下文信息和长距离依赖关系;得到侧输出特征f
ci
,
[0071]
步骤s3、通过转换模块首先将网络主干中多层特征的通道数统一至128,还同时将pnem获取的全局上下文信息传递至所有低层特征,优化主干网络特征;
[0072]
步骤s4、在非对称解码器中分别对前景和背景使用基于注意力的语义增强模块asem,将高层的语义信息传递到低层特征中,使得目标的定位更加准确;
[0073]
步骤s5、在上述步骤s4分别对前景特征和背景特征进行增强的过程中,同时使用注意力引导双任务联合学习模块adjlb对前景特征和背景特征之间联合学习以及互相优化;
[0074]
步骤s6、将前景预测图p1和背景预测图p2相减得到最终预测图。
[0075]
本发明通过前景检测和背景检测两个不同的任务互相学习来更加准确的检测出显著区域,此外本发明在前景检测分支融合有目标边界优化分支来细化目标边界特征的提取。因此,本发明不仅可以预测到更准确的目标边界,而且能够通过背景检测分支来辅助前景检测时得到更准确的显著区域。
[0076]
上述检测方法基于双流解码跨任务交互网络,其具体模型如图2所示。本发明的网络模型中,前景目标检测任务和背景检测任务的交互进行,并且每一个卷积块均依次经历转换模块、前景检测、背景任务以及注意力引导双任务联合学习模块等处理。
[0077]
实施例1:
[0078]
步骤1、本实施例采集对应光学遥感图像数据集,例如orssd、ors
‑
4199和eorssd。
[0079]
其中,orssd数据集包含600幅图像及其相应的真值标签。ors
‑
4199数据集包含
2000幅训练图像和2199幅测试图像,这是目前最大的显著目标检测数据集。eorssd数据集是orssd数据集的扩展版本,包括1400幅训练图像和600幅测试图像。
[0080]
步骤2、本实施例先对eorssd训练集进行随机翻转、旋转、裁剪和仿射变换,以增加训练样本的多样性。此处还扩充了ors
‑
4199训练集。为了使检测模型收敛,本实施例的检测网络在nvidia titan xp gpu上以22的批量大小训练了40次。同时该网络主干参数由resnet
‑
50确定,其他卷积层使用pytorch的默认设置初始化。该网络采用adams优化方法训练,学习率为10
‑4,输入尺寸为320
×
320。
[0081]
步骤3、为便于定量评估,本实施例采用了四种广泛使用的指标。
[0082]
(1)p
‑
r曲线。利用真值标签和预测图计算精确率和召回率。通过精确率和召回率来绘制p
‑
r曲线。p
‑
r曲线越接近坐标(1,1),网络性能越好。
[0083]
(2)平均绝对误差(mae)。计算预测图(p)与真值标签(g)的差值,mae定义为:
[0084][0085]
其中w和h是真值标签的宽度和高度。
[0086]
(3)max f
‑
measure(max f
β
)。它被定义为精确率和召回率的加权调和平均值。f
‑
measure被表示为:
[0087][0088]
其中β2=0.3强调的是精确率而不是召回率。
[0089]
(4)s
‑
measure(s
m
)。s
m
计算预测图和真值标签之间的目标感知结构相似度(s0)和区域感知结构相似度(s
r
)。s
m
如下所示:
[0090]
s
m
=α
·
s0+(1
‑
α)
·
s
r
[0091]
其中α设置为0.5。
[0092]
步骤4、将本发明技术方案与其他现有技术比较。
[0093]
本实施例将本发明技术方案的网络与其他16种sod方法进行比较。
[0094]
比较方法不仅包括自然场景图像方法,还包括光学遥感图像方法。具体包括dafnet、pdf
‑
net、jrbm、lv
‑
net、minet、ldf、gcpanet、f3net、ras、r2net、cpd
‑
r、poolnet、egnet、scrn、aadfnet和enfnet,所有结果均由作者提供的代码生成。
[0095]
定量比较:
[0096]
如图6所示,本实施例在三个数据集上使用max f
β
、mae和sm来评估对应的预测图。
[0097]
在orssd数据集上,在三个评估指标方面,本发明技术方案比光学遥感图像中的最佳方法dfanet分别高出0.79%、17.6%和0.1%。与自然场景图像中的最佳方法f3net相比,分别提高了2.16%、13.4%和1.74%。
[0098]
在eorssd数据集上,本发明技术方案仅次于dafnet。主要原因是eorssd数据集是orssd的扩展版本,它扩展了小目标,使得本发明技术方案不如dafnet有效。然而,本发明技术方案比自然场景图像中的最佳方法ldf分别高出1.25%、22.47%和1.28%。在具有更多挑战的ors
‑
4199数据集中,本发明技术方案也排名最佳。
[0099]
如图3所示,本实施例使用p
‑
r曲线来评估所得预测图。本发明技术方案与其他技术方案进行比较。通过观察p
‑
r曲线,本发明技术方案在ors
‑
4199数据集上的性能与scrn相
当,并且比其他技术方案都要好得多。在orssd和eorssd数据集上,本发明技术方案所得曲线更接近于(1,1)坐标,这进一步验证本发明技术方案优于其他方法。
[0100]
如图4所示,本实施例中还计算了平均精确率和平均召回率。如从图4(a)至图4(c)的三个直方图可以看出,本发明技术方案不仅具有较高的平均准确率和平均召回率,而且两者误差较小。进一步证明了该方法的鲁棒性。
[0101]
定性评价:
[0102]
如图5所示,本实施进行与其他技术方案在最终视觉上的比较。在第1排、第6排和第8排上,有较强的背景干扰,如第1排储油罐旁有类似目标,第6排的白色高速线标记,第8排的白色候机大厅。
[0103]
目前现有大多数技术方法都将背景误检测为显著目标,但是本发明技术方案则可以避免这些背景干扰。在2、3、4、5和9排中,目标与背景的对比度很低,几乎所有的算法都不能完全检测出显著目标,本发明技术方案不仅能完全检测出目标,而且能得到很好的边界。在2、3、4和6排中,这些图像具有不同的目标大小。f3net可以探测到大的目标,但是会漏掉第3排中的小船。然而,大多数其他现有技术方法都遗漏了小目标或丢失了大目标的一部分,本发明技术方案则不存在这些问题。在第10和第11排中,物体本身比较复杂,导致桥梁不完整,建筑物内部结构不完整。
[0104]
基于ors
‑
4199的不同挑战上的性能:在具有挑战性的ors
‑
4199数据集中,每个图像都具有反映现实世界中光学遥感图像的挑战场景。这些标注属性有助于研究显著目标检测模型的优缺点。如图7所示为本发明技术方案的目标检测模型和目前最先进模型的max f
β
分数对比图,其中本发明在九个属性中的七个中排名第一;此外本发明的平均也排名第一。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1