一种基于时序用水数据的工商户聚类方法与流程
本发明涉及用户聚类技术领域,特别是涉及一种基于时序数据的工商户聚类方法。
背景技术:
现有的对用户聚类的方法的研究中,kmeans算法在静态数据的聚类中发挥了出色的效果,但其采用欧氏距离计算工商户之间的相似度,无法考虑时间点的先后顺序,只能捕捉用水量大小的相似性,无法刻画用水特征随着时间变化的趋势。
而工商户用水数据是时间序列数据,是按固定时间间隔,例如日、周、月等记录的工商户日、周、月用水量,隐藏了许多工商户潜在的时序用水特征,例如用水周期、用水模式等潜在特征。时序数据内样本某时刻的状态变化会与之前后时刻状态相关,所以如何结合前后时刻状态去分析时序数据内的变化规律是一个难点。
技术实现要素:
本发明为克服现有技术存在的不足之处,提供一种基于时序数据的工商户聚类方法,以期能通过lstm模型实现对工商户时序用水数据中隐含的用水模式的学习以及表征,并结合kmeans算法对工商户进行用水趋势和用水范围两方面特征的聚类,并提高聚类的准确性,有利于挖掘出时序用水数据中隐含的丰富的变化规律和趋势,从而准确完整地刻画出工商户的用水模式。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种基于时序用水数据的工商户聚类方法的特点是按如下步骤进行:
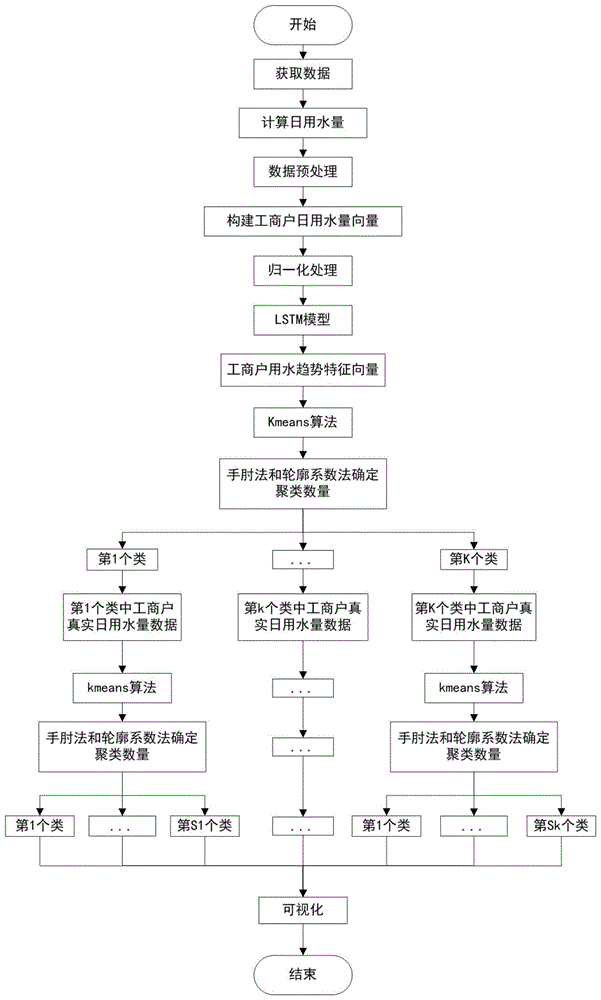
步骤1、构建工商户的日用水量数据;
步骤1.1、获取工商户的远程水表数据,提取所述远程水表数据中的工商户id、水表更新时间、用水累计流量、工商户远程水表地址、工商户名称;
步骤1.2、对所述工商户远程水表地址进行经纬度转换,获得工商户的经纬度信息;
步骤1.3、根据工商户id将所述所述远程水表数据进行分割,得到以工商户id命名的m份水表数据文件,并将水表数据文件中的所有数据按照水表更新时间的先后顺序进行排列;其中,m表示工商户的总数量;
步骤1.4、对每个工商户在每天的第一次水表更新时间的用水累计流量值和最后一次水表更新时间的用水累计流量值进行求差处理,从而构建m个工商户的t日的日用水量向量
步骤1.5、对所述样本特征集a进行异常值的检测与处理,得到异常处理后的样本特征集x′;
步骤1.6、对处理后的样本特征集a′进行缺失值的处理,得到缺失处理后的样本特征集x″;
步骤2、基于lstm模型的时序用水数据的特征表示;
步骤2.1、对缺失处理后的样本特征集x″进行归一化处理,得到归一化后的样本特征集,记为
步骤2.2、预训练lstm模型;
将归一化后的样本特征集
将所述训练集输入所述lstm模型中得到验证集的预测序列,然后采用均方根误差计算所述lstm模型输出的预测序列与所述验证集之间的误差,从而完成lstm模型的一次训练,当训练次数达到所述epoch值时,停止训练,从而得到训练好的lstm模型并作为商户时序用水特征提取模型;
步骤2.3、将所有工商户的日用水量数据输入所述商户时序用水特征提取模型中,从而输出每个工商户的用水特征向量y={yi|i=1,2,...,m};其中,yi表示第i个工商户的用水特征向量,且
步骤3、采用kmeans聚类算法对每个工商户的用水特征向量y={yi|i=1,2,...,m}进行基于用水趋势的工商户聚类;
步骤3.1、采用手肘法和轮廓系数法联合确定最佳聚类数量,记为k;
步骤3.2、基于所述最佳聚类数量k,以所述第i个工商户的用水特征向量yi作为待测样本,并输入至kmeans算法中,从而每个工商户的用水特征向量y中的工商户聚成k个簇,并利用式(1)随机初始化k个簇中心的坐标:
式(1)中,
步骤3.3、利用式(2)计算待测样本yi到第k个簇中心
步骤3.4、根据待测样本yi到各个簇中心的欧式距离,将待测样本yi划分到欧式距离最近的簇中;
步骤3.5、将所有待测样本划分到所属的簇后,得到k个类,并获取每个类中工商户的集合为
利用式(6)计算第k个类中工商户的特征向量的均值
式(6)中,
步骤3.6、重复步骤3.3至步骤3.5,直到所述簇中心不再变化时输出最终的簇中心以及每个类中的工商户id,从而将用水趋势相似的工商户聚为一类;
步骤4、基于用水量范围的工商户聚类;
步骤4.1、基于所述工商户的用水趋势聚类的结果,获取每个类中工商户的集合为bk={bj|j=1,2,...,s′k},其中,bj表示第k个类中的第j个工商户,k∈{1,2,...,k},s′k表示聚类算法收敛时第k个类中的工商户数量;
步骤4.2、获取归一化后的第k个类中第j个工商户bj在t日的真实日用水量数值记为
步骤5、聚类结果的可视化;
步骤5.1、以步骤4的聚类结果中每个类的所有工商户的日用水量向量的均值向量作为类中心,计算每个类中的工商户日用水量均值,通过绘制二维坐标系分别对每个类中的工商户用水情况、类中心以及日用水量均值进行分类可视化;
步骤5.2、获取步骤5.1中计算的所有簇中的类中心,通过绘制二维坐标系对k个类中心同时进行可视化;
步骤5.3、获取步骤4.2的聚类结果中每个类中的工商户id,并根据工商户的经纬度信息,绘制地图从而对每个类中工商户的地理位置进行可视化。
与已有技术相比,本发明有益效果体现在:
1、本发明通过对累计流量数据进行求差处理,并采用相邻数据对缺失值和异常值进行数据补全,构建出每个工商户的日用水量数据,从而完成对时序用水数据的预处理过程,大大提高了数据挖掘模式的质量,有利于提升实际数据挖掘的效率。
2、本发明构建并训练一个lstm模型,学习工商户时序用水数据中隐含的丰富的用水模式,将时序数据表征为指定维度的静态特征向量,实现对工商户用水趋势的特征表示,有利于准确地刻画工商户的用水变化规律,提升后续聚类算法的准确率;
3、本发明结合kmeans算法,对lstm模型表征出的工商户用水特征向量进行相似性计算,从而完成对工商户基于用水趋势方面的聚类,将用水趋势相似的工商户聚为一类,有利于挖掘和分析不同聚类结果中呈现出的不同的用水变化规律;
4、本发明针对用水趋势相似的工商户类中,基于真实日用水量数据再次使用kmeans算法,完成对工商户基于用水量范围方面的聚类,从而将用水趋势和用水量范围都相似的工商户聚为一类,有利于分析和比较用水趋势相似的聚类结果中不同工商户用水量范围的差异,从而准确完整地刻画出工商户的用水模式。
附图说明
图1是本发明的工商户聚类流程图;
图2是本发明长短期记忆模型(lstm)的单个细胞状态结构图;
图3是本发明kmeans聚类算法的流程图。
具体实施方式
本实施例中,一种基于时序用水数据的工商户聚类方法,具体的说,如图1所示,是按如下步骤进行:
步骤1、构建工商户的日用水量数据;
步骤1.1、获取工商户的远程水表数据,提取远程水表数据中的工商户id、水表更新时间、用水累计流量、工商户远程水表地址、工商户名称;
具体实施中,远程水表数据中共记录了2020-01-01到2020-12-31这366天所有工商户的累计用水流量,其中水表在整点时每间隔一小时更新一次累计流量。其次,原始数据是散乱无序排列的,并且属于大型csv文件,所以先抽取工商户id、水表更新时间、用水累计流量、工商户远程水表地址、工商户名称等需要的列,以减小文件内存;
步骤1.2、对工商户远程水表地址进行经纬度转换,获得工商户的经纬度信息;
本实施例中,通过调用高德地图api,将用户的所在地址名称转换成经纬度信息,包括以下步骤:
step1:获取该地址在高德地图上的url,然后在url的keywords里传入该地址,从而得到该地址的url。
step2:对此url发出请求,使用python中request.get(url).text方法得到该url对应的页面信息,并将其转为字符串类型数据。
step3:基于step2中得到页面数据的返回类型是json格式,使用python中json.loads()方法对其进行json数据的解析,从而转换为字典类型的数据。
step4:提取step3中得到的数据,根据字典中的key值和value值即可提取经纬度信息。
步骤1.3、根据工商户id将远程水表数据进行分割,得到以工商户id命名的m份水表数据文件,并将水表数据文件中的所有数据按照水表更新时间的先后顺序进行排列;其中,m表示工商户的总数量;
具体实施中,提取出关键列之后的数据仍然很庞大,会导致运算效率大大降低。处理方法是根据工商户id列对大型csv文件进行文件分割,分割后的文件以每个工商户的id进行命名,至此,获取到了每个工商户单独的远程水表记录数据。
步骤1.4、对每个工商户在每天的第一次水表更新时间的用水累计流量值和最后一次水表更新时间的用水累计流量值进行求差处理,从而构建m个工商户的t日的日用水量向量
本实施例中,拥有2020-01-01到2020-12-31这366天完整用水记录的一共有2158户工商户,假设工商户a在2020年1月1日00时刻的累计流量为x,2020年1月1日24时刻的累计流量为y,那么工商户a在2020年1月1日的日用水量值为(x-y),以此类推,可以计算出所有工商户的366天的日用水量数据。
步骤1.5、对样本特征集a进行异常值的检测与处理,得到异常处理后的样本特征集x′;
由于远传水表记录中存在某日初始时刻用水累计流量或最后时刻用水累计流量的缺失,导致日用水量计算过程中出现异常值。对异常值进行赋特殊值(空值)处理;
具体实施中,由于远传水表记录异常,会出现某个工商户在某日的00时刻累计流量为0或24时刻累计流量为0,导致无法计算出正确的日用水量数值。所以在计算日用水量数据的时候,需要设置条件语句的判断:if(00时刻累计用水流量==0or24时刻累计用水流量==0),可对该日日用水量先赋空值处理;else:日用水量=24时刻累计用水流量-00时刻累计用水流量;
步骤1.6、对处理后的样本特征集a′进行缺失值的处理,得到缺失处理后的样本特征集x″;
由于远传水表记录中存在缺失某工商户某日的用水记录的情况,导致无法正确计算改日的日用水量。对缺失的日用水量数据赋特殊值(空值)处理;
具体实施中,由于远传水表记录异常,会出现某些工商户某日的全部数据缺失,导致无法计算出该缺失日的日用水量数值,所以需要设置条件语句的判断:if(xx年-xx月-xx日=null)可先将该缺失日的日用水量赋空值处理;
本实施例中,可用python中的fillna()方法对空值进行填充,因为工商户用水一般都是大型用水用户,所以用水量较稳定,相邻日的日用水量数值比较相似,所以方法中的参数可以选择为fillna(method=”ffill”,axis=1),用于将空值用该值同行前一个(列)数值进行填充,或者选择为fillna(method=”backfill”,axis=1),用于将空值用该值同行后一个(列)数值进行填充;
步骤2、基于lstm模型的时序用水数据的特征表示;
步骤2.1、对缺失处理后的样本特征集x″进行归一化处理,得到归一化后的样本特征集,记为
其中,归一化处理的公式如下:
式(1)中,
步骤2.2、预训练lstm模型;
将归一化后的样本特征集
将训练集输入lstm模型中得到验证集的预测序列,然后采用均方根误差计算lstm模型输出的预测序列与验证集之间的误差以完成模型的一次训练,当训练次数达到预先确定的epoch值时停止训练,从而得到训练好的lstm模型并作为商户时序用水特征提取模型;
具体实施中,lstm模型的单个细胞状态结构图如图2所示,预训练lstm模型包括如下步骤:
step1:训练遗忘门,其过程表示为:
ft=σ(wftxt+wfhht-1+bf)
式中,xt为输入样本,ft为遗忘门样本,σ(·)表示激活函数,使用sigmod,wft和wfh分别表示遗忘门与xt和ht-1间的权重系数,ht-1表示t-1时刻的隐藏状态,bf为遗忘门偏置系数;
step2:训练输入门,其过程表示为:
gt=σ(wgtxt+wghht-1+bg)
式中,gt表示输入门样本,wgt和wgh分别表示输入门与xt和ht-1间的权重系数,bg为输入门偏置系数;
step3:更新记忆单元,其过程表示为:
st=ftst-1+gttanh(wstxt+wshht-1+bs)
式中,st为细胞状态,wst和wsh分别表示细胞与xt和ht-1间的权重系数,bs为细胞对应的偏置系数;
step4:对输出门当前的状态进行更新,其中的激活函数选用tanh函数;
step5:重复step1~step4,直至模型达到收敛。
步骤2.3、将所有工商户的日用水量数据输入商户时序用水特征提取模型中,从而输出每个工商户的用水特征向量y={yi|i=1,2,...,m};其中,yi表示第i个工商户的用水特征向量,且
步骤3、采用kmeans聚类算法对每个工商户的用水特征向量y={yi|i=1,2,...,m}进行基于用水趋势的工商户聚类,如图3所示;
步骤3.1、采用手肘法和轮廓系数法联合确定最佳聚类数量,记为k;
采用手肘法和轮廓系数法两种方法联合确定最佳聚类数量,记为k;其中,手肘法的公式如下:
式(2)中,k是簇的个数,ci表示第i个簇,p是ci中的样本点,mi是ci的质心(ci中所有样本的均值),sse是所有样本的聚类误差平方和;
随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和sse会逐渐变小;当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故sse的下降幅度会很大,而当k到达真实聚类数时,sse的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,sse和k值的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数;
其次,轮廓系数法的公式如下:
式(3)中,s(i)表示第i个样本的轮廓系数,a(i)为簇内不相似度,表示第i个样本到它所属的簇中其他样本的距离的均值,b(i)为簇间不相似度,表示第i个样本到各个非本身所在的簇中所有样本的平均距离的最小值;所有样本的轮廓系数s(i)的均值称为聚类结果的轮廓系数;
s(i)∈[-1,1],轮廓系数越接近1,说明样本i聚类越合理,所以选择使轮廓系数较大所对应的k值;
本实施例中,可同时计算并绘出sse、轮廓系数与k值的关系图,结合sse与k值的关系图的“肘部”以及轮廓系数与k值关系图的局部最优点,从而确定一个最佳的k值,使得聚类结果里类中相似度尽可能越高,类间相似度尽可能越低;
步骤3.2、基于最佳聚类数量k,以第i个工商户的用水特征向量yi作为待测样本,并输入至kmeans算法中,从而每个工商户的用水特征向量y中的工商户聚成k个簇,并利用式(1)随机初始化k个簇中心的坐标:
式(1)中,
步骤3.3、利用式(2)计算待测样本yi到第k个簇中心
步骤3.4、根据待测样本yi到各个簇中心的欧式距离,将待测样本yi划分到欧式距离最近的簇中;
步骤3.5、将所有待测样本划分到所属的簇后,得到k个类,并获取每个类中工商户的集合为
利用式(6)计算第k个类中工商户的特征向量的均值
式(6)中,
步骤3.6、重复步骤3.3至步骤3.5,直到簇中心不再变化时输出最终的簇中心以及每个类中的工商户id,从而将用水趋势相似的工商户聚为一类;
具体实施中,步骤3基于步骤2的长短期记忆模型学习并输出的工商户的用水趋势特征向量,采用以欧氏距离为相似度度量方法的kmeans算法对工商户进行聚类,此时lstm模型的网络学习到工商户时序用水序列长期状态下存储的内容、丢弃的内容以及读取的内容,检测到时序用水数据中的长期用水趋势,那么基于模型输出的64维特征向量,结合kmeans算法可以实现对工商户基于用水趋势方面的聚类;
步骤4、基于用水量范围的工商户聚类;
步骤4.1、基于工商户的用水趋势聚类的结果,获取每个类中工商户的集合为bk={bj|j=1,2,...,s′k},其中,bj表示第k个类中的第j个工商户,k∈{1,2,...,k},s′k表示聚类算法收敛时第k个类中的工商户数量;
步骤4.2、获取归一化后的第k个类中第j个工商户bj在t日的真实日用水量数值记为
本实施例中,基于步骤3的聚类结果,会存在许多用水趋势非常相似用水量范围相差很大的工商户聚为一类,而我们旨在将用水趋势相似且用水量范围区别不大的工商户聚为一类,因此,在步骤3完成对用水趋势相似的工商户聚类的基础上,我们继而在每个用水趋势相似的类中,基于类中工商户的原始日用水量数据,再次采用kmeans算法,此时已经无需捕捉时序用水数据中的用水模式,所以利用kmeans算法对数值敏感从而可以区别用水量大小的特点,在用水趋势相似的聚类基础上,再依据用水量范围再进行聚类,并且,在聚类过程中,仍然结合手肘法和轮廓系数法确定最佳聚类数量,实现类中相似度尽可能高,类间相似度尽可能低。最终,实现将用水趋势和用水量范围都相似的工商户聚为一类;
步骤5、聚类结果的可视化;
步骤5.1、以步骤4的聚类结果中每个类的所有工商户的日用水量向量的均值向量作为类中心,计算每个类中的工商户日用水量均值,通过绘制二维坐标系分别对每个类中的工商户用水情况、类中心以及日用水量均值进行分类可视化;
具体实施例中,以日期为x轴,日用水量数值为y轴,对类中所有工商户的真实日用水量信息、类中心坐标以及类中工商户日用水量均值进行可视化;
步骤5.2、获取步骤5.1中计算的所有簇中的类中心,通过绘制二维坐标系对k个类中心同时进行可视化;
本实施例中,以日期为x轴,日用水量数值为y轴,对所有的类中心坐标向量进行可视化;
步骤5.3、获取步骤4.2的聚类结果中每个类中的工商户id,并根据工商户的经纬度信息,绘制地图从而对每个类中工商户的地理位置进行可视化。
具体实施中,对类中工商户地理位置的可视化包括以下步骤:
step1:根据每个类中工商户的id以及该id对应的经纬度信息,生成经纬度字典,key为工商户id,value为经度和纬度
step2:通过引入pyecharts绘图工具中的geo包,绘制一张幕布即展示地图的区域,在区域的正上方通过获取每个类中数据的条数来显示该类中工商户的数量,每一个工商户表示为一条数据,并且设置幕布的大小、背景颜色、字体以及字体大小等格式;
step3:使用geo.add()函数,并设置参数maptype=”合肥”,在幕布中加载出合肥市的地图资源包;
step4:在step3中绘制的合肥市地图上,将step1中得到的经纬度字典逐一进行散点标记,并设置散点的大小、形状、颜色等格式;
step5:根据工商户id获取每个工商户的名称信息,加上该工商户的经纬度信息以图例的形式展示在散点上;
step6:将step1~step5绘制的地图以及可视化结果存为.html文件,至此,完成了对每个类中工商户地理位置的可视化。
- 还没有人留言评论。精彩留言会获得点赞!