一种仓储环境下基于连续时隙分组的RFID防碰撞方法
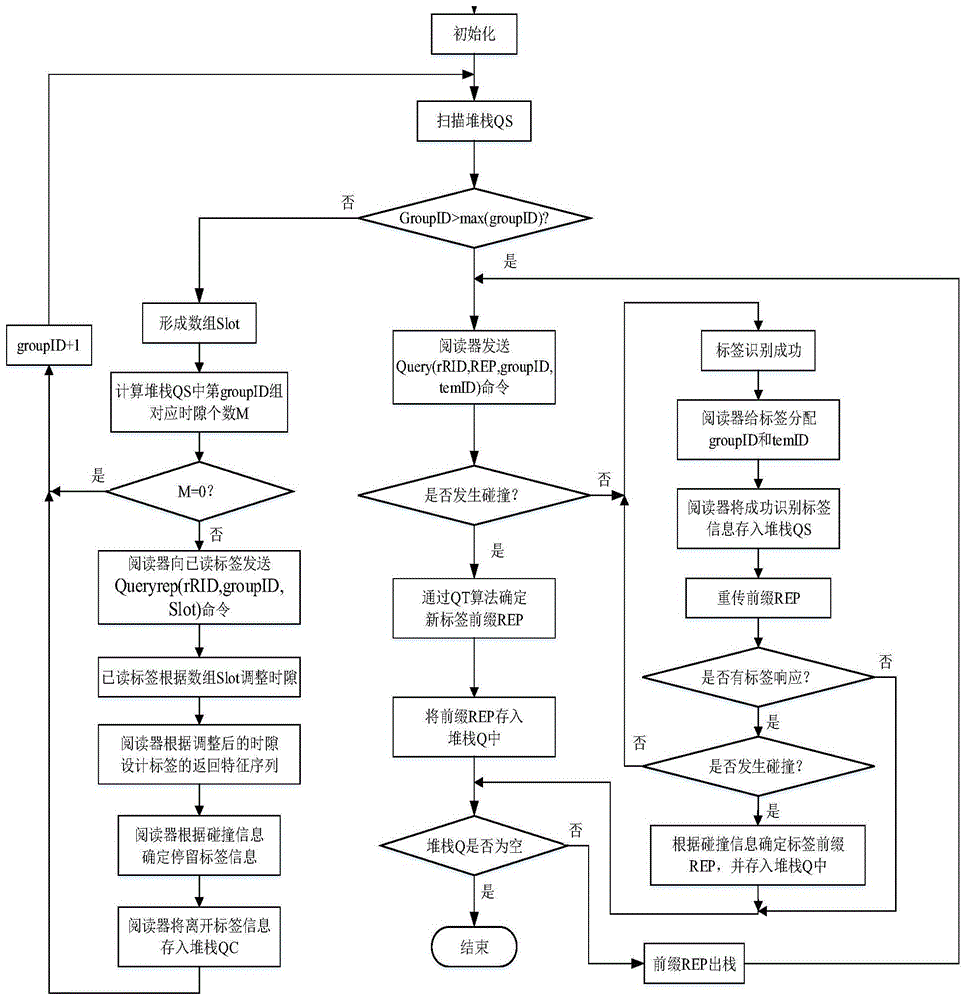
本发明涉及一种仓储环境下基于连续时隙分组的rfid防碰撞方法,属于无线射频通信
技术领域:
。
背景技术:
:仓储作为货物流通的桥梁和纽带,主要负责货物的出库、入库、盘点、信息统计等工作。传统的仓储多采用扫描条形码的方式来记录货物信息,但存在工作量大、易出错、数据滞后、货物漏读、效率低下等问题。随着物联网技术的快速发展,仓储物流开始向数字化转型,其中应用无线射频技术(rfid)更是仓储物流转型过程中必不可少的一个环节。通过应用rfid技术,对货物信息进行自动化采集,可以保证仓储各个环节的货物信息都可以被快速、精准的统计,从而实现仓储的智能化、精细化管理。但是在rfid系统中,由于所有的标签在传输数据时都是采用同一信道的,所以极易发生标签碰撞问题,从而导致阅读器无法正确地读取标签信息。另外,在仓储环境中,又由于每个标签距离阅读器的距离都不同,阅读器接收到每个标签的信号强度也不同,从而就会导致捕获效应的发生,即信号强的标签覆盖信号弱的标签,这样阅读器就会识别信号强的标签,遗漏信号弱的标签。因此解决仓储环境下的标签碰撞和漏读问题对rfid技术的广泛应用具有重要的作用。目前存在的防碰撞算法多是针对静态环境下的标签碰撞问题,若将其应用到仓储环境中,则会消耗大量的时隙,从而降低系统效率。技术实现要素:本发明的目的是提供一种仓储环境下基于连续时隙分组的rfid防碰撞方法,有效的解决仓储环境中标签的碰撞、漏读问题。为了实现上述目的,本发明采用的技术方案是:一种仓储环境下基于连续时隙分组的rfid防碰撞方法,采用标签预处理、时隙分组、设计返回序列、前缀重传的方法对仓储环境下的已读标签、新加入标签和捕获标签进行识别。本发明技术方案的进一步改进在于:所述方法包括如下步骤:步骤1)初始化,将阅读器当前的查询组号groupid置为1,并将阅读器内部的堆栈q置为空;步骤2)阅读器扫描堆栈qs,判断当前的查询组号groupid是否大于max(groupid),若大于,则阅读器执行步骤4),开始识别新加入标签;否则,阅读器根据堆栈qs中第groupid组的时隙标志位flag形成一个数组slot,并计算第groupid组对应的时隙个数m,若m等于0,则开始查询第groupid+1组,重新执行步骤2);若m不等于0,则执行步骤3);步骤3)阅读器发送queryrep(rrid,groupid,slot)命令,已读标签接收到该命令后,首先根据数组slot调整组内时隙temid,调整结束后,将新的temid发送给阅读器,阅读器根据碰撞信息识别该组标签,并将离开的已读标签信息从堆栈qs中删除,存入堆栈qc,同时令当前的groupid加1,然后执行步骤2);步骤4)阅读器发送query(rrid,rep,groupid,temid)命令,此时若新加入标签的前缀rep与阅读器发送的rep相同,则新加入的标签开始响应阅读器,并将自身的识别码发送给阅读器;步骤5)阅读器判断标签是否发生碰撞,若发生碰撞,则阅读器可以通过qt算法预测出新加入标签的前缀为rep,并将rep存入堆栈q中,然后执行步骤7);若未发生碰撞,则识别成功,阅读器给成功识别的标签分配临时的groupid和temid,并将该标签信息存入堆栈qs中,同时将标签内部的计数器trid与阅读器内部的计数器rrid相关联,然后执行步骤6);步骤6)阅读器重新发送query(rrid,rep,groupid,temid)命令,若有标签响应,则说明标签发生捕获,然后阅读器判断捕获标签是否发生碰撞,若未发生碰撞,则执行步骤5);若发生碰撞,则阅读器根据返回的碰撞信息确定捕获标签的前缀rep,并将其存入堆栈q中,同时执行步骤7);若无标签响应,则无标签发生捕获,直接执行步骤7);步骤7)阅读器判断堆栈q是否为空,若堆栈q不为空,则将rep出栈,并跳至步骤4);若堆栈q为空,则查询结束。本发明技术方案的进一步改进在于:当堆栈qs中的时隙存在时,则将该时隙的标志位flag设置为1,当堆栈qs中的时隙不存在时,则将该时隙的标志位flag设置为-1,形成所述步骤2)中的数组slot。本发明技术方案的进一步改进在于:所述步骤3)中的已读标签的判断标准为trid和rrid相等。本发明技术方案的进一步改进在于:所述步骤5)中通过分配的临时tid给新加入标签分配groupid和temid,使其变成已读标签,分配规则如下:(1)当堆栈qs为空时,则说明不存在已读标签,于是阅读器令时隙tid为初始值(初始值为1),从而得到已读标签的组号groupid=tid/8+1,组内时隙temid=tid%8;(2)当堆栈qs不为空时,则说明存在已读标签,于是阅读器首先判断堆栈qc是否为空,若为空,则阅读器将要分配的时隙tid设置为堆栈qs中的max(tid)+1,从而得到组号groupid=(max(tid)+1)/8+1,组内时隙temid=(max(tid)+1)%8;若不为空,则阅读器将要分配的时隙tid设置成堆栈qc中的min(tid),从而得到组号groupid=(min(tid))/8+1,组内时隙temid=(min(tid))%8。本发明中用到的符号含义具体如下:堆栈q:存储新加入标签前缀;堆栈qs:存储已读标签信息;堆栈qc:存储离开标签信息;tid:阅读器为标签分配的时隙;temid:分组后已读标签存储的组内时隙;rrid:阅读器内部计数器;groupid:分组后已读标签存储的组号;trid:标签内部计数器;rep:新加入标签的自身前缀;rep:阅读器内标签对应的前缀。max(groupid):堆栈qs中存储的最大组号。由于采用了上述技术方案,本发明取得的技术效果有:本发明通过将标签的识别过程分为已读标签的识别、新加入标签的识别和捕获标签的识别三个过程,并采用标签预处理、时隙分组、设计返回序列、前缀重传的方法对仓储环境下的标签进行识别,通过验证发现该方法在发生捕获效应时、已读标签数量变化时、已读标签离开时、新标签加入时、总标签数量变化时,均能保持良好的性能,适合在大规模标签的仓储环境中应用。附图说明图1为本发明的整体流程图;图2为曼彻斯特码响应过程;图3为发生捕获效应时,本发明方法与其它方法消耗的时隙数目比较;图4为已读标签数量变化时,本发明方法与其它方法的系统效率比较;图5为离开标签数量变化时,本发明方法与其它方法的系统效率比较;图6为新加入标签数量变化时,本发明方法与其它方法的系统效率比较;图7为总标签数量变化时,本发明方法与其它方法的系统效率比较。具体实施方式下面结合附图及具体实施例对本发明做进一步详细说明,以便于本领域技术人员可以更好的理解本发明,但并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。一种仓储环境下基于连续时隙分组的rfid防碰撞方法,具体实施步骤如图1所示,主要包括以下步骤:步骤1)初始化,将阅读器当前的查询组号groupid置为1,并将阅读器内部的堆栈q置为空;步骤2)阅读器扫描堆栈qs,判断当前的查询组号groupid是否大于max(groupid),若大于,则阅读器执行步骤4),开始识别新加入标签;否则,阅读器根据堆栈qs中第groupid组的时隙标志位flag形成一个数组slot,当堆栈qs中的时隙存在时,则将该时隙的标志位flag设置为1,当堆栈qs中的时隙不存在时,则将该时隙的标志位flag设置为-1,并存入数组slot中,然后计算第groupid组存在的时隙个数m,若m等于0,则开始查询第groupid+1组,并重新执行步骤2);若m不等于0,则执行步骤3)。步骤3)阅读器发送queryrep(rrid,groupid,slot)命令,标签接收到该命令后,首先判断trid和rrid是否相等,若相等,则该标签为已读标签,同时如果已读标签的groupid与阅读器发出命令的groupid相同,则该标签开始响应阅读器,并根据数组slot调整对应的时隙数,具体的调整规则如下:假设堆栈qs中存在a、b、c、d四个标签,对应的时隙如表1所示:表1堆栈qs中的时隙对应情况表首先阅读器通过扫描堆栈qs可以得到数组slot={1-111-1-11-1},然后标签根据空闲时隙数量(即数组slot中flag为-1的元素)调整对应的时隙数,用当前标签的时隙数减去空闲时隙的数量,从而得到调整后的标签时隙分布情况,如表2所示:表2标签时隙调整情况表时隙数调整方法调整后标签时隙11133-1244-1377-1-1-14等标签的时隙数调整结束后,标签向阅读器返回新的时隙信息,从而得到设计的返回特征序列为:00,01,....,0i-1,1i,0i+1,....,0l-1,0l其中:i为标签存储的temid值;l为调整后标签的max(temid)。当阅读器收到已读标签返回的信息后,首先根据停留时隙的数量(即数组slot中flag为1的元素)调整堆栈qc中的时隙数,用当前的时隙数加上停留时隙的数量,从而得到堆栈qc调整后的时隙分布情况,如表3所示。表3堆栈qc时隙调整情况表时隙数调整方法调整后标签时隙22+1+1+1555+1666+17888等时隙调整结束后,阅读器开始判断返回信息的各个比特是否发生碰撞,判断过程如图2所示,若发生碰撞,则说明碰撞位对应的标签仍在阅读器的工作范围内,若未发生碰撞,则说明未碰撞位对应的标签已经离开了阅读器的工作范围,然后阅读器将该标签对应的groupid、temid和id信息从堆栈qs中删除,存入堆栈qc中,同时令当前的groupid加1,并执行步骤2);步骤4)阅读器发送query(rrid,rep,groupid,temid)命令,此时若新加入标签的前缀rep与阅读器发送的rep相同,则新加入的标签开始响应阅读器,并将自身的识别码发送给阅读器;步骤5)阅读器判断标签是否发生碰撞,若发生碰撞,则阅读器按照qt算法的方式确定新加入标签的前缀rep,并将rep存入堆栈q中,然后执行步骤7);若未发生碰撞,则识别成功,阅读器给成功识别的标签分配临时的groupid和temid,其分配规则如下:(1)当堆栈qs为空时,则说明不存在已读标签,于是阅读器令时隙tid为初始值(初始值为1),从而得到已读标签的组号groupid=tid/8+1,组内时隙temid=tid%8。(2)当堆栈qs不为空时,则说明存在已读标签,于是阅读器首先判断堆栈qc是否为空,若为空,则阅读器将要分配的时隙tid设置为堆栈qs中的max(tid)+1,从而得到组号groupid=(max(tid)+1)/8+1,组内时隙temid=(max(tid)+1)%8;若不为空,则阅读器将要分配的时隙tid设置成堆栈qc中的min(tid),从而得到组号groupid=(min(tid))/8+1,组内时隙temid=(min(tid))%8。等分配结束后,阅读器将该标签的信息存入堆栈qs中,同时将标签内部的计数器trid与阅读器内部的计数器rrid相关联,然后执行步骤6)。步骤6)阅读器重新发送query(rrid,rep,groupid,temid)命令,若有标签响应,则说明标签发生捕获,然后阅读器判断捕获标签是否发生碰撞,若未发生碰撞,则执行步骤5);若发生碰撞,则阅读器根据返回的碰撞信息确定捕获标签的前缀rep,并将其存入堆栈q中,同时执行步骤7);若无标签响应,则无标签发生捕获,直接执行步骤7)。步骤7)阅读器判断堆栈q是否为空,若堆栈q不为空,则将rep出栈,并跳至步骤4),继续识别新加入标签;若堆栈q为空,则查询结束。本发明采用matlab软件对rfid的通信过程进行了仿真。假设标签数量从100至1000变化,并且随机生成长度为96bit的标签识别码,在仿真中取100次的平均值作为最后结果。下面模拟了仓储环境下的标签识别问题,运用控制变量法,通过仿真分析了仓储系统中捕获效应、总标签数量、已读标签数量、离开标签数量和新加入标签数量对标签识别的影响,并且比较了gqt1算法、gqt2算法(即完全的新标签识别方法)、sqt算法(即动态环境下已读标签不分组)和dgsqt算法(即动态环境下已读标签分组)系统效率的变化趋势,如图3-图7所示。(本发明中的方法为dgsqt算法)。在本发明中用捕获概率cap表征捕获效应发生的情况,捕获概率越大,则标签越容易被捕获;用n来表征系统中的总标签数量;用|ti|表征已读标签的数量;用m表征新加入的标签数量;用n表征离开的标签数量。在识别过程中,当n=1000,m=500,|ti|=500,n=0时,算法消耗的时隙数目随捕获概率cap的变化情况,如图3所示。在识别过程中,当cap=0.5,m=500,n=0时,算法的系统效率随已读标签数目的变化情况,如图4所示。在识别过程中,当cap=0.5,m=500,|ti|=500时,算法的系统效率随离开标签数量的变化情况,如图5所示。在识别过程中,当cap=0.5,|ti|=500,n=0时,算法的系统效率随新加入标签数目的变化情况,如图6所示。在识别过程中,当cap=0.5,m=n/2,|ti|=n/2,n=0,算法的系统效率随标签总数n的变化情况,如图7所示。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1