一种基于自然语言和机器视觉实现机器人自主导航的方法
1.本发明涉及自然语言处理、图像处理、自主导航的技术领域,尤其是指一种基于自然语言和计算机视觉实现移动机器人室内自主导航的方法。
背景技术:
2.近年来,机器人自主导航在生产生活中应用越来越广泛,越来越多的应用场景需要精确且高效的自主导航技术。以往的自主导航方法,需要先对环境进行一次扫描,获取精确的度量地图,根据精确度量地图进行自主导航。获取精确的度量地图需要消耗大量的人力和物力,并且基于精确度量地图的自主导航方法,难以迁移到未知环境下。因此基于自然语言和计算机视觉的自主导航方法的研究具有重大意义。
3.目前,机器人自主导航研究方面主要采用基于精确度量地图的方法,但还面临如下问题:
4.(1)获取精确度量地图需要消耗大量的资源和时间对环境预先进行扫描,获取精确度量地图的成本较大。
5.(2)在一些难以观测的复杂场景下,获取精确度量地图的难度和开销更大,基于精确度量地图的导航方法可能无法实施。
6.(3)导航效果取决于度量地图的精确程度,一些难以获取精确度量地图的场合,导航效果会变得很差。
7.(4)基于精确度量地图的自主导航方法,是基于环境的度量信息进行导航的,没有利用到语义信息,视觉信息,这使这类方法难以迁移到未知环境中。
技术实现要素:
8.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于自然语言和机器视觉实现移动机器人室内自主导航的方法,能够利用机器人所处环境的视觉信息和自然语言对话记录,在无需预先获取精确度量地图的条件下进行机器人的自主导航。
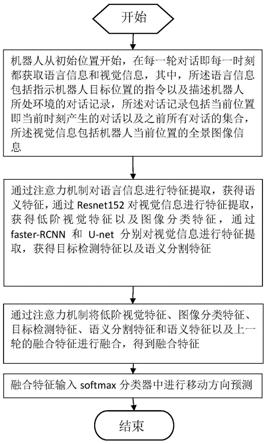
9.为实现上述目的,本发明所提供的技术方案为:一种基于自然语言和机器视觉实现机器人自主导航的方法,包括以下步骤:
10.1)机器人从初始位置开始,在每一轮对话即每一时刻,都获取语言信息和视觉信息;其中,所述语言信息包括指示机器人目标位置的指令以及描述机器人所处环境的对话记录,所述对话记录包括当前位置即当前时刻产生的对话以及之前所有对话的集合,所述视觉信息包括机器人当前位置的全景图像信息;
11.2)通过注意力机制对语言信息进行特征提取,获得语义特征;通过resnet152对视觉信息进行特征提取,获得低阶视觉特征以及图像分类特征;通过faster
‑
rcnn和u
‑
net分别对视觉信息进行特征提取,获得目标检测特征以及语义分割特征;
12.3)通过注意力机制将当前时刻以及前一时刻的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征和语义特征进行融合,得到融合特征;
13.4)将融合特征输入softmax分类器中进行当前时刻的移动方向预测,其中在每一时刻,机器人都通过融合特征预测移动方向,最后当预测结果为停止时,即到达目标位置。
14.在步骤1)中,所述机器人所处环境的对话记录是指两个人类用户在机器人所处环境中进行导航时产生的交流记录,其中,一个人类用户提取知道了整个室内环境的拓扑信息,通过与另一个人类用户的问答交流指示其行走;每一个对话记录用h
t
=d1,d2,...,d
i
,...,d
t
‑1表示,h
t
表示第t轮对话时的对话记录,d
i
表示第i轮对话;机器人所处环境的视觉信息对应的全景图像被表示为c,该全景图像被拆分为12个子图,分别表示12个方向,并表示为c=c1,c2,...,c
i
,...,c
12
,其中,c
i
表示第i个子图。
15.在步骤2)中,通过注意力机制对语言信息进行特征提取,获得语义特征,包括以下步骤:
16.2.1)每个包含t轮对话的对话记录h以及每个包含l个单词的一轮对话记录d描述为:
17.h={d1,d2,...,d
i
,...,d
t
}
[0018][0019]
其中,d
i
表示第i轮对话,表示一轮对话中的第i个单词;
[0020]
2.2)将对话记录通过embedding层进行向量化,对应的向量化结果e描述为:
[0021]
e={g1,g2,...,g
i
,...,g
t
}
[0022]
g
i
={g1,g2,...,g
i
,...,g
l
}
[0023]
其中,g
i
表示语义地图中第i轮对话的embedding向量,一共t轮对话;g
i
表示一轮对话中第i个单词的embedding向量,一共l个单词;
[0024]
2.3)将对话记录的embedding向量通过lstm网络进行编码,获取特征向量,获取特征向量的过程描述为:
[0025]
{h
i,1
,h
i,2
,...,h
i,l
}=lstm({w
i,1
,w
i,2
,...,w
i,j
,...,w
i,l
})
[0026]
d
i
=h
i,l
[0027][0028]
其中,w
i,j
表示第i轮对话中的第j个单词的embedding向量,h
i,l
表示lstm网络的最后一个时刻的状态向量,用d
i
来表示h
i,l
,是由对话记录的前面t
‑
1个特征向量构成的特征矩阵;
[0029]
2.4)将对话记录的特征矩阵和当前对话的特征向量分别通过注意力机制进行融合,融合过程描述为:
[0030][0031][0032][0033][0034]
其中,d
t
和d
i
分别表示状态向量h
t,l
和h
i,l
,a(d
t
,d
i
)表示向量d
t
对于d
i
的注意力,
w
q
、w
k
、w
v
表示模型的参数,c表示向量d
t
和d
i
的维度;softmax表示softmax函数,concat表示向量的合并;是由注意力值和所有d
i
加权合并的结果,表示第t轮对话的对话历史对应的语义特征,由和d
t
合并得到;
[0035]
通过resnet152对视觉信息进行特征提取,获得低阶视觉特征以及图像分类特征,通过faster
‑
rcnn和u
‑
net分别对视觉信息进行特征提取,获得目标检测特征以及语义分割特征:是指在每轮对话中,机器人来到新的位置,然后获取该位置下的全景视图,在t轮对话时的对应的全景视图表示为p
t
,将p
t
通过神经网络模型resnet152进行特征提取,得到的特征结果作为低阶视觉特征,表示为v
t
,得到的图像分类结果作为图像分类特征,表示为c
t
;将p
t
输入到faster
‑
rcnn网络中,得到的目标检测结果作为目标检测特征,表示为o
t
;将p
t
输入到u
‑
net网络中,得到的语义分割结果作为语义分割特征,表示为s
t
。
[0036]
在步骤3)中,通过注意力机制将当前时刻以及前一时刻的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征和语义特征进行融合,得到融合特征,包括以下步骤:
[0037]
3.1)将低阶视觉特征、图像分类特征、目标检测特征、语义分割特征与t
‑
1轮对话即t
‑
1时刻对应的融合特征进行融合,融合的过程描述为:
[0038][0039][0040][0041][0042]
其中,v
t,i
、c
t,i
、o
t,i
、s
t,i
分别表示t轮对话的第i个子图的低阶视觉特征向量、图像分类特征向量、目标检测特征向量、语义分割特征向量,它们分别是低阶视觉特征矩阵v
t
、图像分类特征矩阵c
t
、目标检测特征矩阵o
t
、语义分割特征矩阵s
t
的向量;表示t
‑
1时刻中获得的融合特征,f
v
和f
vlm
表示非线性映射函数,l表示的向量维度;融合后的低阶视觉特征向量、融合后的图像分类特征向量、融合后的目标检测特征向量、融合后的语义分割特征向量分别为特征向量分别为
[0043]
3.2)将融合的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征与语义特征通过注意力机制进行进一步融合,其过程描述为:
[0044][0045][0046]
[0047][0048][0049]
其中,分别表示t轮对话时经过融合的低阶视觉特征矩阵、图像分类特征矩阵、目标检测特征矩阵、语义分割特征矩阵;表示t轮对话时的语义特征,经过和参数相乘,映射为h表示t轮对话时的语义特征的维度;softmax表示softmax函数;分别表示经过注意力机制融合后的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征;
[0050]
3.3)将融合的特征经过lstm网络做进一步处理,并最终合并成最终编码特征,过程如下:
[0051][0052][0053][0054][0055][0056]
其中,分别表示经过lstm网络处理的低阶视觉特征,图像分类特征、目标检测特征、语义分割特征;concat表示向量的合并;表示t轮对话对应的融合特征,即最终编码特征。
[0057]
在步骤4)中,将融合特征输入softmax分类器中进行移动方向预测,包括以下步骤:
[0058]
4.1)将最终编码特征用激活函数进行映射,其过程如下:
[0059][0060]
其中,σ为sigmoid激活函数,f
m
为非线性映射函数,为激活结果;
[0061]
4.2)将激活结果经过softmax函数计算最后结果,过程如下:
[0062][0063]
其中,softmax表示softmax函数,f
a
为非线性映射函数。
[0064]
本发明与现有技术相比,具有如下优点与有益效果:
[0065]
1、本发明提出使用视觉信息和自然语言进行机器人自主导航,节约了获取精确度量地图带来的开销并且可以适应复杂环境。
[0066]
2、本发明提出结合自然语言指令和机器视觉进行机器人自主导航,能够更方便,高效的进行机器人自主导航。
[0067]
3、本发明结合了自然语言指令和机器视觉,通过结合两种不同模态信息的特征进行机器人自主导航,在保证导航效果的同时提高了导航效率,节约了开销。
附图说明
[0068]
图1为本发明进行自主导航的流程示意图。
[0069]
图2为基于注意力机制的特征提取及导航指令预测的模型架构构造过程示意图。
[0070]
其中,对话历史表示机器人的提问以及人类用户的回答记录;当前时刻的对话表示本轮对话中机器人的提问以及人类用户的回答;encoding表示对对话信息进行编码处理,转化为embedding向量;机器视觉图像分别通过resnet152,faster r
‑
cnn,u
‑
net几种模型提取到低阶视觉特征图像分类特征目标检测特征语义分割特征等;attention表示注意力模块,该模块用于提取语义信息的特征视觉信息的特征提取,以及融合语义特征,视觉特征和t
‑
1轮对话即t
‑
1时刻中获得的融合特征等;分别表示与语义特征融合后的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征;融合后的特征被输入到softmax模块并计算出最后结果。
[0071]
图3为注意力机制原理示意图。其中,d
t
,d
i
分别表示被用来计算注意力的特征向量;w
q
,w
k
,w
v
是用来将d
t
和d
i
映射到同一维度的参数;matmul表示矩阵相乘;计算结果通过softmax模块进行归一化,得到注意力结果a(d
t
,d
i
);通过将所有注意力模块的结果合并,再合并d
t
,得到最后结果
具体实施方式
[0072]
下面结合具体实施例及附图对本发明作进一步说明,但本发明的实施方式不限于此。
[0073]
如图1至图3所示,本实施例所提供的基于自然语言和机器视觉实现机器人自主导航的方法,包括以下步骤:
[0074]
1)机器人从初始位置开始,在每一轮对话(每一时刻)都获取语言信息和视觉信息;所述语言信息包括指示机器人目标位置的指令以及描述机器人所处环境的对话记录,所述对话记录包括当前位置(即当前时刻)产生的对话以及之前所有对话的集合,所述视觉信息包括机器人当前位置的全景图像信息;所述机器人所处环境的对话记录是指两个人类用户在机器人所处环境中进行导航时产生的交流记录,其中,一个人类用户提取知道了整个室内环境的拓扑信息,通过与另一个人类用户的问答交流指示其行走;每一个对话记录用h
t
=d1,d2,...,d
i
,...,d
t
‑1表示,h
t
表示第t轮对话时的对话记录,d
i
表示第i轮对话;所述机器人所处环境的视觉信息对应的全景图像被表示为c,该全景图像被拆分为12个子图,分别表示12个方向,并表示为c=c1,c2,...,c
i
,...,c
12
,其中,c
i
表示第i个子图,如图2中的备选行动方向对应的图像所示。
[0075]
2)通过注意力机制对语言信息进行特征提取,获得语义特征,包括以下步骤:
[0076]
2.1)每个包含t轮对话的对话记录h以及每个包含l个单词的一轮对话记录d描述为:
[0077]
h={d1,d2,...,d
i
,...,d
t
}
[0078]
[0079]
其中,d
i
表示第i轮对话,表示一轮对话中的第i个单词;
[0080]
2.2)将对话记录通过embedding层进行向量化,对应的向量化结果描述为:
[0081]
e={g1,g2,...,g
i
,...,g
t
}
[0082]
g
i
={g1,g2,...,g
i
,...,g
l
}
[0083]
其中,g
i
表示语义地图中第i轮对话的embedding向量,一共t轮对话;g
i
表示一轮对话中第i个单词的embedding向量,一共l个单词;
[0084]
2.3)将对话记录的embedding向量通过lstm网络进行编码,获取特征向量,获取特征向量的过程描述为:
[0085]
{h
i,1
,h
i,2
,...,h
i,l
}=lstm({w
i,1
,w
i,2
,...,w
i,j
,...,w
i,l
})
[0086]
d
i
=h
i,l
[0087][0088]
其中,w
i,j
表示第i轮对话中的第j个单词的embedding向量,h
i,l
表示lstm网络的最后一个时刻的状态向量,用d
i
来表示h
i,l
,是由对话记录的前面t
‑
1个特征向量构成的特征矩阵;
[0089]
2.4)将对话记录的特征矩阵和当前对话的特征向量分别通过注意力机制进行融合,注意力机制的原理以及注意力结果的计算过程如图3所示,融合过程描述为:
[0090][0091][0092][0093][0094]
其中,d
t
和d
i
分别表示状态向量h
t,l
和h
i,l
,a(d
t
,d
i
)表示向量d
t
对于d
i
的注意力,w
q
、w
k
、w
v
表示模型的参数,c表示向量d
t
和d
i
的维度;softmax表示softmax函数,concat表示向量的合并;是由注意力值和所有d
i
加权合并的结果,表示第t轮对话的对话历史对应的语义特征,由和d
t
合并得到;
[0095]
如图2所示,通过resnet152对视觉信息进行特征提取,获得低阶视觉特征以及图像分类特征,通过faster
‑
rcnn和u
‑
net分别对视觉信息进行特征提取,获得目标检测特征以及语义分割特征,具体是指在每轮对话中,机器人来到新的位置,然后获取该位置下的全景视图,在t轮对话时的对应的全景视图表示为p
t
;将p
t
通过神经网络模型resnet152进行特征提取,得到的特征结果作为低阶视觉特征,表示为v
t
,得到的图像分类结果作为图像分类特征,表示为c
t
;将p
t
输入到faster
‑
rcnn网络中,得到的目标检测结果作为目标检测特征,表示为o
t
;将p
t
输入到u
‑
net网络中,得到的语义分割结果作为语义分割特征,表示为s
t
。
[0096]
3)通过注意力机制将当前时刻以及前一时刻的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征和语义特征进行融合,得到融合特征,包括以下步骤:
[0097]
3.1)将低阶视觉特征、图像分类特征、目标检测特征、语义分割特征与t
‑
1轮对话
即t
‑
1时刻对应的融合特征进行融合,融合的过程描述为:
[0098][0099][0100][0101][0102]
其中,v
t,i
、c
t,i
、o
t,i
、s
t,i
分别表示t轮对话的第i个子图的低阶视觉特征向量、图像分类特征向量、目标检测特征向量、语义分割特征向量,它们分别是低阶视觉特征矩阵v
t
、图像分类特征矩阵c
t
、目标检测特征矩阵o
t
、语义分割特征矩阵s
t
的向量;表示t
‑
1时刻中获得的融合特征,f
v
和f
vlm
表示非线性映射函数,l表示的向量维度;融合后的低阶视觉特征向量、融合后的图像分类特征向量、融合后的目标检测特征向量、融合后的语义分割特征向量分别为特征向量分别为
[0103]
3.2)将融合的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征与语义特征通过注意力机制进行进一步融合,其过程描述为:
[0104][0105][0106][0107][0108][0109]
其中,分别表示t轮对话时经过融合的低阶视觉特征矩阵、图像分类特征矩阵、目标检测特征矩阵、语义分割特征矩阵;表示t轮对话时的语义特征,经过和参数相乘,映射为h表示t轮对话时的语义特征的维度;softmax表示softmax函数;分别表示经过注意力机制融合后的低阶视觉特征、图像分类特征、目标检测特征、语义分割特征;
[0110]
3.3)将融合的特征经过lstm网络做进一步处理并最终合并成最终编码特征,过程如下:
[0111]
[0112][0113][0114][0115][0116]
其中,分别表示经过lstm网络处理的低阶视觉特征,图像分类特征、目标检测特征、语义分割特征;concat表示向量的合并;表示t轮对话对应的融合特征,即最终编码特征。
[0117]
4)将融合特征输入softmax分类器中进行移动方向预测,包括以下步骤:
[0118]
4.1)将最终编码特征用激活函数进行映射,其过程如下:
[0119][0120]
其中,σ为sigmoid激活函数,f
m
为非线性映射函数,为激活结果;
[0121]
4.2)将激活结果经过softmax函数计算最后结果,过程如下:
[0122][0123]
其中,softmax表示softmax函数,f
a
为非线性映射函数。
[0124]
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1