一种面向多点地质统计随机模拟过程的混合并行方法
1.本发明涉及一种面向多点地质统计随机模拟过程的混合并行方法,属于地质建模领域。
背景技术:
2.多点地质统计学方法能够表征空间多点之间的相关关系,通过最大化期望和模式学习的方式表征参考模型(训练图像)中的复杂模式,从而对地下空间的各向异性复杂地质结构模型进行自动构建,以更好地重现地质模型属性地非均质性。多点地质统计学方法结合了基于对象和基于像素随机模拟方法的优点,已经成为复杂三维地质模型自动构建与模拟领域的重要分支,并已在储层建模、地震反演、矿产预测等多个地学领域取得了良好的应用。
3.多点地质统计学方法旨在直接从参考模型(训练图像)中提取各向异性空间模式来描述空间异构几何特征,目前多点地质统计学方法对模拟网格进行模拟时均采用串行多点地质统计随机模拟方法,步骤为:首先会获取网格中的所有待模拟结点,确定随机模拟路径;随后每次从随机模拟路径中取出一个待模拟结点,随后获取待模拟结点周围的条件点数据;使用这些条件点匹配训练图像中存在的数据事件,就可以通过模式学习或最大化期望对随机变量的值进行模拟;直到随机路径中的所有待模拟结点被遍历,模拟结束;由上可知串行多点地质统计随机模拟方法在对模拟网格进行模拟时,需要按照模拟路径依次访问模拟网格中的每个待模拟结点;造成大量的计算消耗,同时计算效率也较低,不满足实际应用中对大规模高精度模型构建的需求,同时多点地质统计随机模拟方法均根据蒙特卡洛进行随机模拟,因此模拟邻域内所有空间位置的模拟结果都可能影响当前待模拟空间位置的模拟结果,即正在模拟的空间位置位于当前模拟任务的模拟邻域内,则表示该模拟结果会影响当前模拟任务,导致模拟发生冲突,目前的串行多点地质统计随机模拟方法无法很好的解决这一问题。
技术实现要素:
4.为了解决现有技术的不足,本发明提供了一种面向多点地质统计随机模拟过程的混合并行方法,该方法嵌入混合并行策略利用粗粒度并行策略、细粒度并行策略将原有的串行计算改为并行计算,同时具备有在多个节点上分别运行多个进程,由多个节点合作完成一个参考模型的效果,实现进程级和线程级并行效果,以此来提高计算效率和减少计算消耗。且对模拟发生冲突这一问题来进行处理,来提高模拟结果的准确性。
5.本发明为解决其技术问题所采用的技术方案是:一种面向多点地质统计随机模拟过程的混合并行方法,根据粗粒度并行策略将计算节点分为主节点和从属处理器,主节点根据模拟路径将所求的模拟任务进行划分为多个子模拟任务,并获取模拟子模拟任务所对应的模拟信息,当获取模拟信息后,主节点从节点负载列表中寻找到计算负载最小的从属处理器,并将模拟信息和对应的子模拟任务发送给该从属处理器;从属处理器再对子模拟
任务进行模拟工作,当从属处理器完成子模拟任务的模拟工作后,将子模拟结果返回给主节点,主节点收到子模拟结果后对节点负载列表进行更新,当所有子模拟任务完成后,对子模拟结果进行汇总得到模拟结果。
6.根据细粒度并行策略将模拟任务进行划分为多个子模拟任务的步骤和将模拟信息和对应的子模拟任务发送给该从属处理器的步骤同步进行。
7.所述子模拟任务的数量大于所述从属处理器个数。
8.所述模拟信息包括了子模拟任务的在模拟空间中的模拟邻域、模拟窗口大小和模拟空间位置之间的映射关系。
9.从属处理器再对子模拟任务进行模拟的过程中,会进行冲突处理策略,即对其在模拟空间中的模拟位置a1进行判断,并根据判断结果处理,具体如下:
10.1)若该模拟位置a1不在该子模拟任务在模拟空间中的模拟邻域内,则使用该模拟位置a1进行模拟工作;
11.2)若模拟位置在该子模拟任务在模拟空间中的模拟邻域内,则找到模拟位置a1沿模拟路径的下一个待模拟位置a2,并利用待模拟位置a2替换模拟位置a1重新判断;
12.2.1)若重新判断次数在阈值范围内,且待模拟位置an不在该子模拟任务在模拟空间中的模拟邻域内,则使用该模拟位置an进行模拟工作
13.2.2)若重新判断次数在阈值范围外,则记录模拟位置as,s>n,则放弃模拟工作,并记录模拟位置as,当所有子模拟任务完成后,对该子模拟任务在模拟位置as上单独模拟。
14.主节点和从属处理器之间为统一的数据转换接口,该数据转换接口将模拟空间位置之间的映射关系转换为相应的数值关系并将其矢量化,且在矢量化一个多重映射时需要逐层剥离相应的信息。
15.该方法采用的具体步骤如下:
16.(1)根据粗粒度并行策略将计算节点分为主节点和从属处理器,主节点读取训练图像、样本数据以及算法的参数信息,加载待模拟网格数据,并根据其空间位置将已知样本数据分配到模拟网格中;
17.(2)主节点将训练图像和参数信息发送给每个从属处理器;
18.(3)主节点确定一个包含所有待模拟网格的随机路径sim_path;
19.(4)如果存在待模拟网格结点sim_path.size,即sim_path.size()>0,则转步骤(5),否则转步骤(15);
20.(5)主节点获取当前空闲的从属处理器,并基于冲突处理策略从模拟路径中选出一个无冲突的待模拟结点x;
21.(6)主节点以当前待模拟结点x为中心,根据给定的搜索邻域r,获取已知网格结点,构成此次模拟的数据事件n
x
;
22.(7)主节点使用数据转换接口将待模拟结点x的空间坐标、数据事件n
x
等模拟信息转换为数据流d;
23.(8)主节点将数据流d发送给空闲的从属处理器;
24.(9)从属处理器使用数据转换接口将数据流d解析为待模拟结点x的模拟信息;
25.(10)从属处理器基于空间分区的并行策略随机扫描训练图像t
i
,针对每个结点y,计算数据事件n
x
与n
y
之间的差异程度d(n
x
,n
y
);
26.(11)当d(n
x
,n
y
)小于预设的差异性度量阈值t时,执行步骤(13),否则转步骤(12);
27.(12)当扫描训练图像ti的比例大于预设的比例阈值f时,执行步骤(13),否则执行步骤(10);
28.(13)从属处理器得到最佳匹配结点y*后,将结点y*的值作为结点x的模拟结果,并发送给主节点;
29.(14)主节点将模拟结果填入模拟网格中的相应位置,从模拟路径sim_path中移除当前模拟结点x,并转步骤(4);
30.(15)保存结果,结束本次模拟;
31.(16)主节点向从属处理器发送终止模拟信号,并结束进程;
32.(17)从属处理器接收到终止模拟信号后结束进程。
33.步骤(5)中冲突处理策略包括如下步骤
34.(5.1)如果存在待模拟结点,即sim_path.size()>0,且冲突次数小于设定的最大上限,即conflictscnt<max,则转步骤(2),否则转步骤(5);
35.(5.2)根据当前待模拟结点x周围的条件点确定冲突范围re;
36.(5.3)如果正在模拟的结点集s∩re不为空集,证明此时发生冲突,冲突次数自加并转步骤(4),否则转步骤(5);
37.(5.4)将待模拟结点x放回模拟路径中,取出另一个待模拟结点,并转步骤(2);
38.(5.5)冲突处理完成。
39.步骤(10)所述的基于空间分区的并行策略是依照线程池中的线程数量将需要扫描的训练图像ti分区;针对不同的线程分配不同的扫描区域;多个线程同时进行数据事件的扫描比对;当某一个线程获得最佳数据事件匹配结果时,通过线程间通信结束整个扫描比对过程。
40.由上述技术方案可知:(1)本发明提供的方法采用粗粒度并行策略,利用主从结构将计算节点分为主节点和从属节点,有在从属节点上分别处理多个子模拟任务,由多个节点合作完成一个模拟任务,来提高模拟效率,同时保证了大量节点用于模拟,来充分调动计算力。
41.(2)本发明提供的方法采用细粒度并行策略,使多个程序在同一时刻运行,即使指令和操作同时运行,来避免计算力的浪费。
42.(3)本发明提供的方法采用细粒度并行策略,在多点地质统计随机模拟时的模式匹配过程中将模式库进行了搜索区域划分,以充分利用计算节点内部的线程资源。
43.(4)本发明提供的方法中数据转换接口,在主节点和从属节点进行数据传输的过程中,将多种数据结构的模拟信息通过多重映射的方式转换为数据流,以保证模拟信息的传输效率,避免了在传输模拟信息时多次建立通信导致的并行效率降低的问题。
44.(5)本发明提供的方法采用冲突处理策略,使正在模拟的空间位置位于当前模拟任务的模拟邻域之外,来避免模拟结果影响当前模拟任务。
附图说明
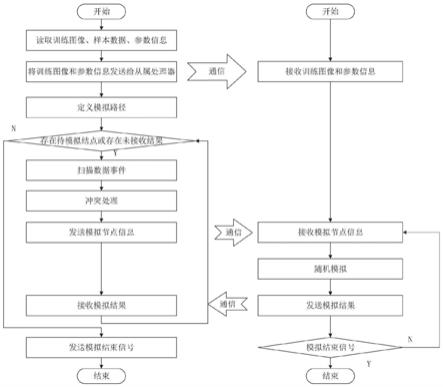
45.图1是本发明的总体流程图。
46.图2是本发明在并行冲突发生时的冲突处理策略流程图。
47.图3是本发明中二维模拟实验案例中使用的训练图像。
48.图4是图3中使用的3000个条件数据点的训练图像。
49.图5是图4实验模拟出的二维河道图。
50.图6是图5参照二维模拟实现结果对应画出的整体变差函数曲线。
51.图7是图6参照二维模拟实现结果在x方向上的空间连通性曲线。
52.图8是本发明中三维模拟实验案例中使用的训练图像。
53.图9为图8中使用的100个钻孔数据。
54.图10为图9的三维实验案例输出的模拟结果。
55.图11为图10参照三维模拟实现结果对应画出的整体变差函数曲线。
56.图12为图11参考三维模拟实现结果在x方向上的空间连通性曲线。
57.图13为图11参考三维模拟实现结果在y方向上的空间连通性曲线。
58.图14为二维模拟实验中本方法采用的方法与串行算法、并行算法的变差函数曲线。
59.图15为三维模拟实验中本方法采用的方法与串行算法、并行算法的变差函数曲线。
60.图16为二维模拟实验中本方法采用的方法与串行算法、并行算法在x方向上的空间连通性曲线。
61.图17为三维模拟实验中本方法采用的方法与串行算法、并行算法在x方向上的空间连通性曲线。
62.图18为验证本发明的并行效率设计的并行模拟实验图。
具体实施方式
63.下面结合附图和实施例对本发明进行详细具体说明,本发明的内容不局限于以下实施例。
64.参考图1,一种面向多点地质统计随机模拟过程的混合并行方法,根据粗粒度并行策略将计算节点分为主节点和从属处理器,普遍情况下让一个计算集群中的0号节点作为主节点,其余节点为从属处理器。主节点根据模拟路径将所求的模拟任务进行划分为多个子模拟任务,子模拟任务的数量大于所述从属处理器个数,并获取模拟子模拟任务所对应的模拟信息,所述模拟信息包括了子模拟任务的在模拟空间中的模拟邻域、模拟窗口大小和模拟空间位置之间的映射关系,当获取模拟信息后,主节点从节点负载列表中寻找到计算负载最小的从属处理器,并将模拟信息和对应的子模拟任务发送给该从属处理器,根据细粒度并行策略将模拟任务进行划分为多个子模拟任务的步骤和将模拟信息和对应的子模拟任务发送给该从属处理器的步骤同步进行;从属处理器再对子模拟任务进行模拟工作,当从属处理器完成子模拟任务的模拟工作后,将子模拟结果返回给主节点,主节点收到子模拟结果后对节点负载列表进行更新,当所有子模拟任务完成后,对子模拟结果进行汇总得到模拟结果。
65.参考图2,从属处理器再对子模拟任务进行模拟的过程中,会进行冲突处理策略,即对其在模拟空间中的模拟位置a1进行判断,并根据判断结果处理,具体如下:
66.1)若该模拟位置a1不在该子模拟任务在模拟空间中的模拟邻域内,则使用该模拟
位置a1进行模拟工作;
67.2)若模拟位置在该子模拟任务在模拟空间中的模拟邻域内,则找到模拟位置a1沿模拟路径的下一个待模拟位置a2,并利用待模拟位置a2替换模拟位置a1重新判断;
68.2.1)若重新判断次数在阈值范围内,且待模拟位置an不在该子模拟任务在模拟空间中的模拟邻域内,则使用该模拟位置an进行模拟工作
69.2.2)若重新判断次数在阈值范围外,则记录模拟位置as,s>n,则放弃模拟工作,并记录模拟位置as,当所有子模拟任务完成后,对该子模拟任务在模拟位置as上单独模拟。
70.主节点和从属处理器之间为统一的数据转换接口,该数据转换接口将模拟空间位置之间的映射关系转换为相应的数值关系并将其矢量化,且在矢量化一个多重映射时需要逐层剥离相应的信息。
71.该方法采用的具体步骤如下:
72.(1)根据粗粒度并行策略将计算节点分为主节点和从属处理器,主节点读取训练图像、样本数据以及算法的参数信息,加载待模拟网格数据,并根据其空间位置将已知样本数据分配到模拟网格中;
73.(2)主节点将训练图像和参数信息发送给每个从属处理器;
74.(3)主节点确定一个包含所有待模拟网格的随机路径sim_path;
75.(4)如果存在待模拟网格结点sim_path.size,即sim_path.size()>0,则转步骤(5),否则转步骤(15);
76.(5)主节点获取当前空闲的从属处理器,并基于冲突处理策略从模拟路径中选出一个无冲突的待模拟结点x;
77.(6)主节点以当前待模拟结点x为中心,根据给定的搜索邻域r,获取已知网格结点,构成此次模拟的数据事件n
x
;
78.(7)主节点使用数据转换接口将待模拟结点x的空间坐标、数据事件n
x
等模拟信息转换为数据流d;
79.(8)主节点将数据流d发送给空闲的从属处理器;
80.(9)从属处理器使用数据转换接口将数据流d解析为待模拟结点x的模拟信息;
81.(10)从属处理器基于空间分区的并行策略随机扫描训练图像t
i
,针对每个结点y,计算数据事件n
x
与n
y
之间的差异程度d(n
x
,n
y
);
82.(11)当d(n
x
,n
y
)小于预设的差异性度量阈值t时,执行步骤(13),否则转步骤(12);
83.(12)当扫描训练图像ti的比例大于预设的比例阈值f时,执行步骤(13),否则执行步骤(10);
84.(13)从属处理器得到最佳匹配结点y*后,将结点y*的值作为结点x的模拟结果,并发送给主节点;
85.(14)主节点将模拟结果填入模拟网格中的相应位置,从模拟路径sim_path中移除当前模拟结点x,并转步骤(4);
86.(15)保存结果,结束本次模拟;
87.(16)主节点向从属处理器发送终止模拟信号,并结束进程;
88.(17)从属处理器接收到终止模拟信号后结束进程。
89.步骤(5)中冲突处理策略包括如下步骤
90.(5.1)如果存在待模拟结点,即sim_path.size()>0,且冲突次数小于设定的最大上限,即conflictscnt<max,则转步骤(2),否则转步骤(5);
91.(5.2)根据当前待模拟结点x周围的条件点确定冲突范围re;
92.(5.3)如果正在模拟的结点集s∩re不为空集,证明此时发生冲突,冲突次数自加并转步骤(4),否则转步骤(5);
93.(5.4)将待模拟结点x放回模拟路径中,取出另一个待模拟结点,并转步骤(2);
94.(5.5)冲突处理完成。
95.步骤(10)所述的基于空间分区的并行策略是依照线程池中的线程数量将需要扫描的训练图像ti分区;针对不同的线程分配不同的扫描区域;多个线程同时进行数据事件的扫描比对;当某一个线程获得最佳数据事件匹配结果时,通过线程间通信结束整个扫描比对过程。
96.为了说明本发明所提供并行方案的有效性,根据以上步骤分别实施了二维模拟实验、三维模拟实验和并行方案有效性实验。
97.参考图3~图7,图3为二维模拟实验所使用的训练图像,该训练图像为250
×
250的河道分布网格;图4中显示的是随机生成的3000个用于模拟的条件数据点;图5为参照二维训练图像中的空间模式和条件数据点得到的2000
×
2000实现结果。从二维的模拟实现结果可以看出,模拟出的河道纹理清晰,分布与训练图像类似。由此可以得出本发明提出的算法可以较好的模拟出河道分布情况。图6为二维模拟实验模拟出的10个不同的模拟结果与训练图像共同绘制的变差函数曲线,图7是10个不同的模拟结果与训练图像对应的x方向的连通性曲线。从变差函数图和连通性曲线图均可以看出,根据模拟实现结果所绘制的变差函数曲线(灰色)集中分布在训练图像对应的曲线(黑色)周围,由此可从统计特性看出,这10个不同的模拟实现结果都能够接近符合二维训练图像的变差特性和连通特性。
98.参考图8到图13,图8为三维模拟实验所使用的180
×
150
×
120训练图像;图9中显示的是从三维训练图像中抽取的100个用作条件数据的钻孔;图10为模拟出的三维实现结果。由三维模拟实现结果可以看出,本发明提出算法的模拟实现结果十分接近训练图像中岩层的分布模式;图11~图13分别为10个不同的模拟结果和训练图像共同绘制的变差函数曲线和连通性曲线。从变差函数曲线和连通性曲线可以看出这10个模拟结果均符合训练图像中的变差分布和连通性分布。
99.参考图14~图17,为了深层次地揭示本发明得到的模拟结果与串行算法模拟结果之间的差异,图14~图17中绘制了在二维和三维实验案例中串行和并行算法模拟实现之间的变差函数和连通性函数的比较结果。可以观察到使用本方案输出的变差函数和连通性曲线与串行算法是高度一致的。进一步证明了本方案不会影响模拟输出的效果。
100.参考图18为本发明设计的并行实验案例。在并行实验案例中,计算核数量由36逐步提升至96,在这一过程中本方案的并行效率(起点为100.0的线)和加速比(起点为1.00的线)并没有因为计算核数量的增加而减小,由此可以看出发明设计的并行方案有着高并行性和可扩展性。
101.上述实验案例表明本发明提供并行方案能够高效地实现属性比例再现、空间变异性刻画和空间结构连通性重建,这也证实了本发明提供的面向多点地质统计随机模拟过程的混合并行方案有着高效、优越地模拟地质异质性结构的能力。
102.以上实施例仅供说明本发明之用,而非对本发明的限制,有关技术领域的技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变换或变型,因此所有等同的技术方案,都落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1