一种基于证据森林的信息不确定条件目标意图识别方法
本发明属于目标意图识别技术领域,具体涉及一种基于证据森林的信息不确定条件目标意图识别方法。
背景技术:
目标意图是指目标希望达到某种目的的基本设想和预设行为,这里的预设行为是指目标计划或预定要达到的结果。战场目标战术意图识别就是在作战的特殊环境下,结合各种信息源得到的目标信息,然后对战场态势和敌方战术意图进行有效分析的过程。目标意图识别过程中,信息源得到的信息很大程度上都具有不确定性,因此如何处理这种不确定性信息是当前面临的一个问题。
在现有的机器学习算法中,决策树方法是最常用的方法之一。决策树的特点是,它可以将复杂的决策问题分解为几个简单的问题。虽然决策树很流行和有效,但它们不适合处理具有不确定性信息的问题。不确定性可能会影响分类结果,甚至会做出错误的决策。信度函数理论为处理决策树技术中的不确定性提供了一个方便的框架。信度决策树结合了决策树技术和信念函数理论的优势来解决认知不确定性的分类问题。
随机森林是使用装袋算法和随机子空间技术的决策树的组合。传统的随机森林算法使用投票或平均的方法来获得每个决策树的结果的最终类结果。当面对不确定的分类问题时,精度有限。为了更好地处理不确定性问题,提出了一种可以处理具有不确定性信息的证据森林算法,并且用于不确定性目标意图识别。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于证据森林的信息不确定条件目标意图识别方法。通过建立证据森林模型,将具有不确定性信息的待测数据输入到证据森林模型中,得到目标的意图识别结果,很好的解决了具有不确定性信息的目标意图识别问题,充分提高意图识别的准确性。
为解决上述技术问题,本发明采用的技术方案是:一种基于证据森林的信息不确定条件目标意图识别方法,其特征在于,包括以下步骤:
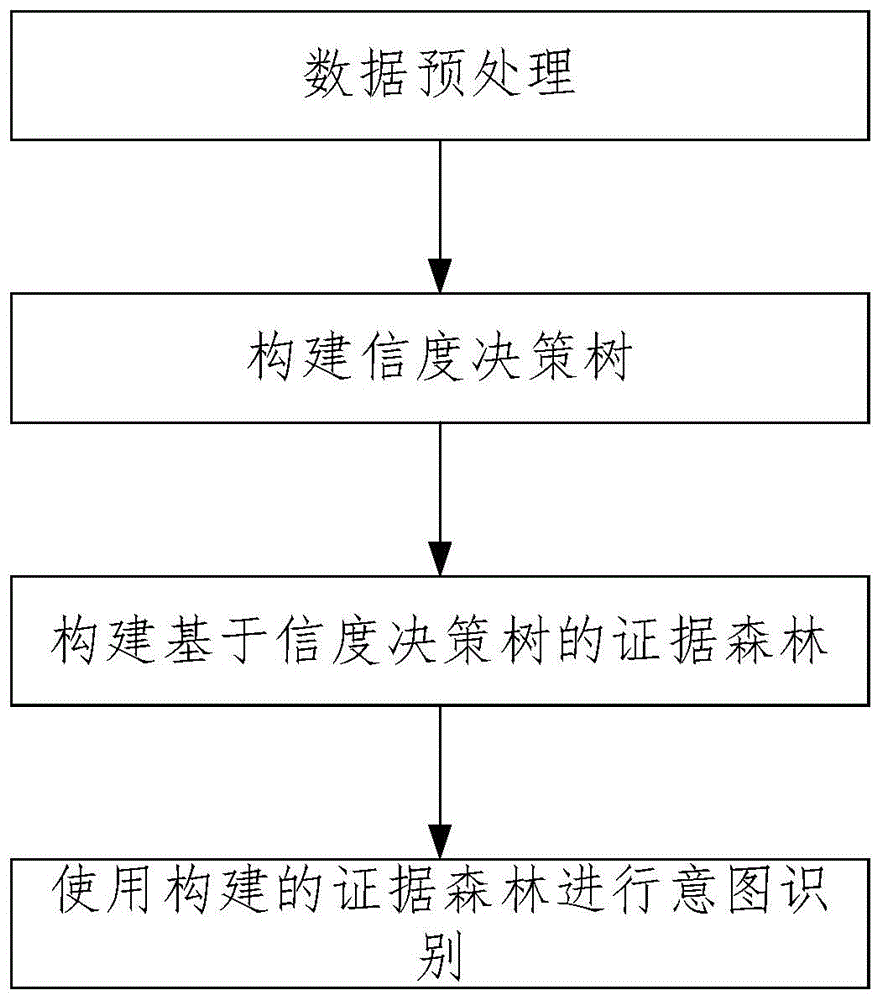
步骤一、数据预处理:
步骤101:输入n个目标训练样本,包括属性特征向量x=[x1,x2,…,xv],其中v为属性个数,xi,i=1,2,…,v表示每个属性特征的测量值,对应每个样本的意图y,y的辨识框架为θy={y1,y2,…,yw},w表示辨识框架中意图的个数;
步骤102:对每个属性特征建立高斯模糊数f[c:(μ,δ)],μ和δ表示高斯模糊数c的均值和方差,辨识框架
步骤103:根据公式
步骤104:将意图取值为yp的样本的不同属性
步骤105:根据公式
步骤106:属性特征辨识框架元素组合
步骤二、构建信度决策树:
步骤201:根据公式
步骤202:根据公式
步骤203:根据公式
步骤204:计算属性xi取值到模糊类别fj下每条样本的意图基本概率分布[m(y1),m(y2),…,m(y1,y2,…,yw)]对[m(y1)=1],[m(y2)=1],…,[m(yw)=1]的证据距离(d1,d2,…,dw),所述的证据距离计算公式为
步骤205:根据公式
步骤206:根据公式
步骤207:每次选择完一个分裂属性,重复步骤201-206,直到满足该节点只剩下一个训练样本或者多个同类别的样本,该节点作为叶子节点将存放这些样本的意图的基本概率分布;
步骤三、构建基于信度决策树的证据森林:
步骤301:采用重复采样技术,训练证据森林的每棵树都为不同的训练样本,避免过拟合;
步骤302:对于步骤301得到的训练样本,从个数为v的属性中,随机无放回的选择m1个属性,作为训练信度决策树的训练样本;
步骤303:设定证据森林中信度决策树的个数n,根据步骤二建立多棵信度决策树构成证据森林;
步骤304:计算证据森林中每棵树的权重,每棵信度决策树可以得到训练样本的识别结果ms(l)=[ms′(y1),ms′(y2),…,ms′(y1,y2,…,yw)]l,l=1,2,…,n,计算每棵树的识别结果ms(l)和样本真实意图[m(y1),m(y2),…,m(y1,y2,…,yw)]的证据距离(d1,d2,…,dn),计算相似度[(1-d1),(1-d2),…,(1-dn)],计算每棵树对所有样本的平均相似度
步骤305:根据公式
步骤306:求解每棵信度决策数的权重wl,根据步骤305得出的可能性测度和必要性测度,得出权重约束条件q(a2)≤[w(o1)+w(o2)+…+w(on)]≤p(a2),w(o1)+w(o2)+…+w(on)=1,其中a2=[(o1),(o2),…,(on)],融合所有树的识别结果
步骤四、使用构建的证据森林进行意图识别:
步骤401:将待测的原始样本经过步骤102处理,得到处理后的样本
步骤402:将属性的辨识框架拓展为
步骤403:根据公式bel[mt](yp)=∑bel[mχy](yp)*m(χ),χ∈θf,计算待测样本mt关于意图yp的置信函数值,即每个联合焦元在信度决策树所对应的叶子节点中mχy对意图yp的置信函数值bel[mχy](yp)与每个联合焦元的基本概率分布值m(χ)的乘积再多个联合焦元求和,得到待测样本mt对意图yp的置信函数值,若一个联合焦元在信度决策树中对应多个叶子节点,多个叶子节点对yp的置信函数值bel[mχy](yp)=bel{m[χ1]y}(yp)∨bel{m[χ2]y}(yp),其中∨表示公式
步骤404:根据步骤403得到待测样本mt关于意图的置信函数bel[mt](yp),yp∈[y1,y2,…,(y1,y2),…,(y1,y2,…,yw)],根据公式
步骤405:根据公式
本发明与现有技术相比具有以下优点:
1、本发明可以解决具有不确定性信息的目标意图识别问题。
2、本发明提出的基于证据相似度计算不确定信息的信息熵,可以解决具有不确定信息的信息熵的计算方法。
3、本发明提出了基于可能性理论的信度决策树权重的计算方法,更加合理计算每棵树的权重。
综上所述,本发明通过建立证据森林模型,将具有不确定性信息的待测数据输入到证据森林模型中,得到目标的意图识别结果,很好的解决了具有不确定性信息的目标意图识别问题,充分提高意图识别的准确性。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明的流程框图
图2为速度属性的高斯模糊数图
图3为证据森林中信度决策树的示意图
表1为一条训练数据的所有属性转化后的概率分布数据
表2为不同属性模糊类别组合后的数据
表3为属性模糊类别组合相同的所有样本相加合并后的意图。
具体实施方式
下面结合实施例对本发明的方法作进一步详细的说明。
如图1所示,本发明包括以下步骤:
步骤一、数据预处理:
步骤101:输入n个目标训练样本,包括属性特征向量x=[x1,x2,…,xv],其中v为属性个数,xi,i=1,2,…,v表示每个属性特征的测量值,对应每个样本的意图y,y的辨识框架为θy={y1,y2,…,yw},w表示辨识框架中意图的个数;
实际使用时,目标的属性特征包括{速度x1,距离x2,高度x3,航向角x4},意图的类别包括{攻击y1,侦察y2,巡航y3,撤退y4,其他y5};
步步骤102:对每个属性特征建立高斯模糊数f[c:(μ,δ)],μ和δ表示高斯模糊数c的均值和方差,辨识框架
实际使用时,对每个属性建立三个高斯模糊数
步骤103:根据公式
以步骤102的速度转化后的基本概率分布为例,根据公式计算可以得到速度的概率分布{p(f1)=0,p(f2)=0.069,p(f3)=0.931};
步骤104:将意图取值为yp的样本的不同属性
表1表示一条训练数据的所有属性转化后的概率分布数据,根据上述公式,得到组合后的数据如表2所示;
步骤105:根据公式
对所有样本相加合并,根据上述公式,得到数据如表3所示;
步骤106:属性特征辨识框架元素组合
步骤二、构建信度决策树:
步骤201:根据公式
步骤202:根据公式
步骤203:根据公式
步骤204:计算属性xi取值到模糊类别fj下每条样本的意图基本概率分布[m(y1),m(y2),…,m(y1,y2,…,yw)]对[m(y1)=1],[m(y2)=1],…,[m(yw)=1]的证据距离(d1,d2,…,dw),所述的证据距离计算公式为
步骤205:根据公式
步骤206:根据公式
步骤207:每次选择完一个分裂属性,重复步骤201-206,直到满足该节点只剩下一个训练样本或者多个同类别的样本,该节点作为叶子节点将存放这些样本的意图的基本概率分布;
实际使用时,生成的信度决策树如图2所示,其中m{ii},i=1,2,…,n表示存放在叶子节点中的样本的意图的基本概率分布;
步骤三、构建基于信度决策树的证据森林:
步骤301:采用重复采样技术,训练证据森林的每棵树都为不同的训练样本,避免过拟合;
步骤302:对于步骤301得到的训练样本,从个数为v的属性中,随机无放回的选择m1个属性,作为训练信度决策树的训练样本;
步骤303:设定证据森林中信度决策树的个数n,根据步骤二建立多棵信度决策树构成证据森林;
步骤304:计算证据森林中每棵树的权重,每棵信度决策树可以得到训练样本的识别结果ms(l)=[ms′(y1),ms′(y2),…,ms′(y1,y2,…,yw)]l,l=1,2,…,n,计算每棵树的识别结果ms(l)和样本真实意图[m(y1),m(y2),…,m(y1,y2,…,yw)]的证据距离(d1,d2,…,dn),计算相似度[(1-d1),(1-d2),…,(1-dn)],计算每棵树对所有样本的平均相似度
步骤305:根据公式
步骤306:求解每棵信度决策数的权重wl,根据步骤305得出的可能性测度和必要性测度,得出权重约束条件q(a2)≤[w(o1)+w(o2)+…+w(on)]≤p(a2),w(o1)+w(o2)+…+w(on)=1,其中a2=[(o1),(o2),…,(on)],融合所有树的识别结果
实际使用时,假设n=3,归一后的相似度为{s(1)=1,s(2)=0.3,s(3)=0.6},a=[(1,3)],根据上述公式可以计算出p(a)=1,g(a)=0.7,得出一个约束条件0.7≤w(1)+w(3)≤1,同理计算所有约束条件,根据优化目标求解最优解;
步骤四、使用构建的证据森林进行意图识别:
步骤401:将待测的原始样本经过步骤102处理,得到处理后的样本
步骤402:将属性的辨识框架拓展为
步骤403:根据公式bel[mt](yp)=∑bel[mχy](yp)*m(χ),χ∈θf,计算待测样本mt关于意图yp的置信函数值,即每个联合焦元在信度决策树所对应的叶子节点中mχy对意图yp的置信函数值bel[mχy](yp)与每个联合焦元的基本概率分布值m(χ)的乘积再多个联合焦元求和,得到待测样本mt对意图yp的置信函数值,若一个联合焦元在信度决策树中对应多个叶子节点,多个叶子节点对yp的置信函数值bel[mχy](yp)=bel{m[x1]y}(yp)∨bel{m[χ2]y}(yp),其中∨表示公式
步骤404:根据步骤403得到待测样本mt关于意图的置信函数bel[mt](yp),yp∈[y1,y2,…,(y1,y2),…,(y1,y2,…,yw)],根据公式
步骤405:根据公式
例如样本
以上所述,仅是本发明的实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!