一种基于GAN的局部写实感漫画风格迁移系统及方法
一种基于gan的局部写实感漫画风格迁移系统及方法
技术领域
1.本发明涉及图像处理技术领域,具体的说,涉及一种基于gan的局部写实感漫画风格迁移系统及方法。
背景技术:
2.动漫是现在非常流行的一种艺术表现形式,这种艺术形式广泛的应用与社会的诸多方面,包括广告、游戏、影视作品和摄影等多个方面。现在这个时代的年轻人大多受到过日本漫画的影响,而日本漫画也确实在全世界有很大的影响力,但是由于漫画的绘制和生成大多采用的是手工绘图后再通过电脑渲染来制作,花费的时间和人力都相对较多,这对于一般没有绘图基础的人将无法完成制作。因此希望可以通过电脑将现实世界的图片自动转换为具有漫画风格的图片。同时可以人为的调控其是对人像或者是背景进行风格迁移以满足不同人对图片的要求。
3.目前,基于深度学习的图像风格迁移已经取得了相对较好的效果,所以深度学习成为了目前图像到图像转换的常用方法。该方法通过对风格图像的样式学习,将学习的样式应用于输入的内容图像以生成结合了内容图像的内容和风格图像的风格的新图像。这些方法主要利用深度特征之间的相关性和基于优化方法对图像的视觉风格进行编码。
4.在2016年gatys等人率先采用深度学习提出了图像样式迁移的方法,其方法主要通过模拟人类视觉的处理方式,结合训练多层卷积神经网络,使计算机辨别并且学会艺术风格,从而用到原始图像上,使原始图像富有艺术感。该方法很好的达到了风格迁移的目的但是迁移效果较为僵硬且会出现内容扭曲同时生成速度较慢。
5.a radford和l metz等人在2015年提出了基于卷积生成对抗网络的无监督学习方法为人们在图像风格迁移提供了新的研究方法,经由实验发现该方法在图像数据集上进行训练所得出的处理结果有着十分不错的效果。但是由于该网络需要成对的数据集,而且获取转移的对应图像是十分困难的所以该模型显得不切实际,为了解决这个问题在后续提出了循环生成对抗网络,它是一个能够采用不成对训练数据进行训练的图像翻译架构,解决了诸多训练数据集不匹配的问题。但是循环生成对抗网络的样式化不能很好的捕捉卡通图案,输出的图像对输入图的语义内容不能充分的保留。
6.2018年yang chen等人在对抗生成网络的基础上提出了cartoongan(漫画生成对抗网络),其采用了新颖的网络架构,其网络结构可以使用不成对的数据集进行训练同时能在最大程度上呈现出漫画的风格特点。但是cartoongan所生成的图像在人像方面会出现严重的歧义色块导致。
7.在2019年由jie chen等人对其进行改进并且提出了animegan(动画生成对抗网络)其引入了灰度图像并且更改了原漫画生成对抗网络所采用的损失函数消除了人物出现歧义色块的问题,但是其为了保证颜色的真实性导致人像和风景部分在风格迁移过程中的诸多细节丢失,包括人脸部分的众多重要的纹理特征丢失。
技术实现要素:
8.本发明的目的在于提供一种基于gan的局部写实感漫画风格迁移系统及方法,采用expressiongan(表情生成对抗网络)和scenerygan(背景生成对抗网络)分别针对animegan和cartoongan进行改进,并且对模型deeplabv3+生成的掩码图进行边缘优化处理,实现局部写实感漫画风格迁移。
9.为达到上述目的,本发明采用技术方案为:
10.本发明提供一种基于gan的局部写实感漫画风格迁移系统,包括:
11.表情生成对抗网络,背景生成对抗网络,deeplabv3+网络和图像融合模块;
12.所述表情生成对抗网络用于基于真实人物图像生成人像全局迁移图;
13.所述背景生成对抗网络用于基于真实背景图像生成背景全局迁移图;
14.所述deeplabv3+网络用于将需要进行局部风格迁移的图像生成人像掩码图和背景掩码图;
15.所述图像融合模块用于将真实人物图像,人像掩码图和人像全局迁移图进行融合得到人像局部迁移图;以及,将真实背景图像,背景掩码图和背景全局迁移图进行融合得到背景局部迁移图。
16.进一步的,所述表情生成对抗网络在动画生成对抗网络基础上引入压缩激发残差块和漫画人脸检测模块;
17.所述漫画人脸检测模块用于对输入的真实人物图像进行筛选,检测出含有人脸的图像;
18.所述压缩激发残差块用于增强脸部特征。
19.进一步的,所述背景生成对抗网络在漫画生成对抗网络基础上采用分布偏移卷积代替标准卷积。
20.本发明还提供一种基于gan的局部写实感漫画风格迁移方法,包括:
21.获取原始数据集以及将原始数据集划分训练集和测试集;所述原始数据集包括真实人物图像,真实人物图像的灰度图,真实背景图像,漫画图像和去线条化漫画图像;
22.采用训练集训练表情生成对抗网络和背景生成对抗网络;
23.将测试集图像输入到训练好的表情生成对抗网络得到人像全局迁移图,以及输入到训练好的背景生成对抗网络得到背景全局迁移图,以及将真实人物图像输入到deeplabv3+网络生成人像掩码图和背景掩码图;
24.将真实人物图像,人像掩码图和人像全局迁移图进行融合得到人像局部迁移图;以及,将真实背景图像,背景掩码图和背景全局迁移图进行融合得到背景局部迁移图。
25.进一步的,所述真实人物图像的灰度图通过gram矩阵将真实人物图像转换得到;
26.所述去线条化漫画图像通过高斯平滑对漫画图像进行处理得到。
27.进一步的,所述采用训练集训练表情生成对抗网络,包括:
28.将训练集中的真实人物图像输入到表情生成对抗网络中,经漫画人脸检测模块筛选,将检测到人脸的图像输入到表情生成对抗网络生成器中;
29.在表情生成对抗网络生成器中依次进行三个卷积核大小为7
×
7,卷积核个数为64,步长为1的平坦卷积,进行卷积核大小为3
×
3,卷积核个数为128,步长为2的向下卷积,以及进行卷积核大小为3
×
3,卷积核个数为256,步长为1的向下卷积;
30.经过向下卷积后经压缩激发残差块进行脸部特征增强操作;
31.脸部特征增强后进行卷积核为3
×
3,卷积个数为256,步长为1/2和卷积核为3
×
3,卷积个数为64,步长为1的两个向上卷积,以及进行卷积核为7
×
7,卷积个数为3,步长为1的标准卷积,得到输出图像;
32.将真实人物图像的灰度图,表情生成对抗网络生成器输出图像,漫画图像和去线条化漫画图像输入到表情生成对抗网络鉴别器;所述鉴别器为训练好的vgg-19网络;
33.通过迭代学习对表情生成对抗网络生成器进行训练直至达到终止条件。
34.进一步的,所述进行脸部特征增强操作包括:
35.图像经过向下卷积后进行标准卷积;
36.标准卷积的输出经过平均池化,进行压缩计算:
[0037][0038]
其中,f
sq
(
·
)表示压缩操作,zc为压缩计算结果,下标c为通道数,uc表示第c个二维矩阵,w为图像的宽度,h为图像的高度;
[0039]
然后,进行激发计算:
[0040]
sc=sigmod(w2*relu(w1zc))
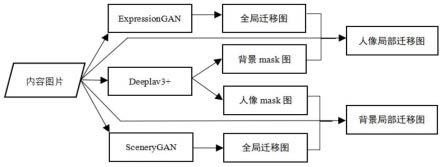
[0041]
其中,sc为激发计算结果,sigmod为sigmoid函数,relu为relu激活函数,w1为全连接层参数,w2=c/r,c为通道数,r为缩放系数;
[0042]
然后,计算:
[0043][0044]
通过值来对脸部特征进行增强调控。
[0045]
进一步的,采用训练集训练背景生成对抗网络包括:
[0046]
将训练集中的真实背景图像输入到背景生成对抗网络生成器网络中,通过三个平坦卷积后进行两个向下卷积,经过八个相同的残差块后进行两个向上卷积,最后通过平坦卷积,得到输出图像;
[0047]
将背景生成对抗网络生成器网络输出图像,漫画图像和去线条化漫画图像输入到背景生成对抗网络鉴别器,所述鉴别器为训练好的vgg-19网络;
[0048]
通过迭代学习对背景生成对抗网络生成器网络进行训练直至达到终止条件。
[0049]
进一步的,还包括:
[0050]
通过5
×
5的卷积将deeplabv3+网络生成的人像掩码图和背景掩码图进行卷积使得其边缘模糊化。
[0051]
进一步的,
[0052]
将人像掩码图的人像和背景分别选为(0,1),之后融合得到人像局部迁移图;
[0053]
将背景掩码图的人像和背景取反,之后融合得到背景局部迁移图。
[0054]
本发明达到的有益效果为:
[0055]
本发明方法在animegan的基础上se-residual-block和漫画人脸检测模块,采用se-residual-block可以避免最大化池暴力筛选导致特征信息丢失而且se-residual-block通过特征通道间相关性进行建模,把重要的特征进行强化从而很大程度上提升了训
练的针对性,大大提升了对易于丢失的细节纹理的恢复。
[0056]
本发明方法在cartoongan基础上采用分布偏移卷积代替标准卷积,通过可变量化内核中存储整数值来实现较低的存储器使用和较高的速度,同时通过应用基于内核和基于通道的分布偏移来保持和原始卷积相同的输出。
附图说明
[0057]
图1是本发明的局部写实主义漫画模型结构图。
[0058]
图2是本发明中expressiongan网络结构图。
[0059]
图3是本发明中se-residual-block结构图。
[0060]
图4是本发明中se-residual-block工作流程图。
[0061]
图5是本发明中scenerygan生成器网络图。
具体实施方式
[0062]
下面对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
[0063]
如图1所示,本发明提出一种全新的局部写实主义漫画模型,该模型由基于animegan(动画生成对抗网络)改进的expressiongan(表情生成对抗网络)、基于cartoongan(漫画生成对抗网络)改进的scenerygan(背景生成对抗网络)和deeplabv3+网络模型组成。
[0064]
expressiongan是在animegan的基础上引入se-residual-block(压缩激发残差块)和漫画人脸检测模块。采用se-residual-block(压缩激发残差块)代替原animegan中inverted-residual-block(反转残差块),se-residual-block可以避免最大化池暴力筛选导致特征信息丢失而且se-residual-block通过特征通道间相关性进行建模,把重要的特征进行强化从而很大程度上提升了训练的针对性,大大提升了对易于丢失的细节纹理的恢复。
[0065]
scenerygan是在cartoongan基础上采用dsconv(分布偏移卷积)代替原有的conv(标准卷积)得到scenerygan。dsconv通过可变量化内核(vqk)中存储整数值来实现较低的存储器使用和较高的速度,同时通过应用基于内核和基于通道的分布偏移来保持和原始卷积相同的输出。
[0066]
deeplabv3+用于生成掩码图,采用卷积块对deeplabv3+生成的掩码图进行边缘优化。
[0067]
作为本发明的一个实施例,提供一种基于gan的局部写实感漫画风格迁移方法,具体步骤如下:
[0068]
步骤1:从雅虎旗下的flicker网站下载5890张含有人物的真实图片用于expressiongan训练;从网站中下载6153张大小为256
×
256的真实图片这些图片用于scenerygan中,其中5402张图像作为训练集,其余图片作为测试集;最后,通过关键字截取的方式对宫崎骏电影进行图像截取,截取到4500张漫画图像,这些漫画图像将作为expressiongan和scenerygan所共用的数据集。
[0069]
步骤2:采用高斯平滑对漫画图像进行处理得到去线条化漫画图像,再采用gram矩
阵将真实图像转换为灰度图。
[0070]
步骤3:将得到的漫画图像输入到opencv_训练级联分类器中进行训练。
[0071]
步骤4:将5890张真实人物图像、5890张真实人物图像的灰度图、4500张漫画图像和4500张去线条化漫画图像,输入到expressiongan中训练网络。
[0072]
步骤5:将5402张真实背景图像、4500张漫画图像和4500张去线条化漫画图像输入到scenerygan中训练网络。
[0073]
步骤6:将步骤1中的测试集图像输入到训练好的expressiongan和scenerygan中生成全局漫画风格迁移图。
[0074]
步骤7:将真实人物图片输入到deeplabv3+中得到人像掩码图和背景掩码图。
[0075]
步骤8:通过卷积的手段对人像掩码图和背景掩码图进行边缘优化处理。
[0076]
步骤9:将expressiongan生成的全局漫画风格迁移图、5402张真实图像和边缘优化后的人像掩码图进行融合得到人像局部迁移图。将scenerygan生成的全局漫画风格迁移图、真实图像和边缘优化后的背景掩码图进行融合得到背景局部迁移图。
[0077]
作为本发明的另一个实施例,一种基于gan的局部写实感漫画风格迁移方法,具体步骤如下:
[0078]
(1)将5890张真实人物图像、5890张真实人物图像的灰度图、4500张漫画图像和4500张去线条化漫画图像输入到网络中,其中5890张真实人物图像输入到expressiongan生成器网络中,5890张真实人物图像的灰度图、4500张漫画图像和4500张去线条化漫画图像输入到expressiongan鉴别器网络中。生成器和鉴别器结构图如图2所示。
[0079]
(2)5890张真实人物图像输入到expressiongan生成器网络中首先通过漫画人脸检测模块,漫画人脸检测模块将数据集中的图片进行筛选,将检测到人脸的图像输入到expressiongan生成器网络中。
[0080]
(3)进入expressiongan生成器网络的图片先经过三个卷积核大小为7
×
7,卷积核个数为64,步长为1的平坦卷积。随后经过卷积核大小为3
×
3,卷积核个数为128,步长为2的向下卷积和经过卷积核大小为3
×
3,卷积核个数为256,步长为1的向下卷积。
[0081]
(4)图片经过向下卷积后进入到压缩激发残差块se-residual-block由标准卷积(conv-block)、平均化池(global pooling)、全连接层(fc)、sigmoid函数和实例归一化层(inst-norm)组成具体结构如3所示。se-residual-block工作流程如图4所示。
[0082]
标准卷积的输出经过平均池化,在压缩部分采用的是求平均的方法,将空间上所有点的信息平均成为一个值,这样做是因为最终的scale是对整个通道作用的,这需要通道整体信息来计算scale。压缩的计算公式为:
[0083][0084]
其中,下标c为通道数,uc表示第c个二维矩阵,w为图像的宽度,h为图像的高度。
[0085]
其次在激发部分,经过上述压缩过程得到结果z,通过全连接层w1乘以z,本发明实施例中取16。将w1×
z经过relu激活函数后维度不变再乘以w2,w2为c/r,最后将输出通过sigmoid函数。
[0086]
excitation计算公式为:
[0087]
s=sigmod(w2*relu(w1z))
ꢀꢀ
(2)
[0088]
其中,c为通道数,r为缩放系数,z为squeeze部分的输出,w1,w2为c/r。
[0089]
得到s后,将输入u与s代入:
[0090][0091]
通过值来对特征进行调控,在最大程度上将脸部特征增强,从而达到脸部纹理恢复的效果。
[0092]
(5)图像经过se-residual-block后经过卷积核为3
×
3,卷积个数为256,步长为1/2和卷积核为3
×
3,卷积个数为64,步长为1的两个向上卷积。最后经过卷积核为7
×
7,卷积个数为3步长为1的标准卷积输出图像。
[0093]
(6)将真实图像的灰度图,expressiongan生成器输出图,漫画图像和去线条化漫画图像输入到expressiongan鉴别器,漫画图像和去线条化漫画图像会先经过漫画人脸检测模块筛选出含有漫画人脸的图像,再将筛选后的图像输入到鉴别器中,鉴别器为训练好的vgg-19网络。
[0094]
本发明实施例中,expressiongan对animegan损失函数进行了修改。animegan通过使用灰度矩阵将原始卡通图像转换为灰度图像,这样做的目的在保留图像纹理的同时可以消除暗色干扰。animegan虽然解决了色块的问题但是无法改善图片颜色偏暗的问题。所以expressiongan在其颜色重建损失中进行了修改。
[0095]
(8)将5402张真实背景图像输入到scenerygan生成器网络中,图像先通过三个平坦卷积后进入到两个向下卷积,随后经过八个相同的残差块,通过残差块后经过两个向上卷积,最后通过平坦卷积输出生成图像。scenerygan采用和cartoongan相同的卷积核数量和卷积核大小,将原先的标准卷积块(conv)替换成了分布偏移卷积(dsconv)如图5所示。
[0096]
(9)将scenerygan生成器网络生成的图像、4500张漫画图像和4500张去线条化漫画图像输入到scenerygan的鉴别器中。
[0097]
(11)将需要进行局部风格迁移的图像,输入到训练好的deeplabv3+网络中,生成图像的人像掩码图和背景掩码图。
[0098]
通过5
×
5的卷积将生成的人像掩码图和背景掩码图进行卷积使得其边缘模糊化,从而使得边缘在贴合时更加自然。
[0099]
(12)将5890张真实人物图像、人像掩码图和人像全局漫画风格迁移图输入到图像融合算法中,将人像掩码图的人像和背景部分分别选为(0,1),之后对图像进行融合得到人像局部迁移图。将5402张真实背景图像、背景掩码图和背景全局迁移图输入到图像融合算法中并且将掩码图的人像和背景部分取反,最后融合得到背景局部迁移图。
[0100]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0101]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序
指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0102]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0103]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0104]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1