一种基于分布式双向链表的数据处理方法与流程
1.本发明属于互联网信息技术领域,尤其涉及一种基于分布式双向链表的数据处理方法。
背景技术:
2.每个数据结点中都有两个指针,分别指向直接后继和直接前驱的一种链表,并且从任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点,就是双向链表。
3.数据处理贯穿于社会生产和社会生活的各个领域,数据处理技术的发展及其应用的广度和深度,极大地影响了人类社会发展的进程。数据处理包括数据存储与数据获取。数据处理过程中使用到数据库,用于存储数据的一类库存就是数据库。传统的数据库即磁盘数据库,使用磁盘进行存储,并且从磁盘上读取数据,执行过程中产生大量的磁盘与网络i/o(输入/输出)消耗。
4.磁盘数据库存在如下不足:
5.(1)需要频繁地访问磁盘来进行数据的操作,由于对磁盘读写数据的操作一方面要进行磁头的机械移动,另一方面受到系统调用(通常通过cpu中断完成,受到cpu时钟周期的制约)时间的影响,当数据量很大,操作频繁且复杂时,时间较长,效率较低;
6.(2)可扩展性比较差,无法较好的支持海量数据存储,传统爬虫只单机采集数据,采集速度慢;
7.(3)数据模型过于死板,事务机制还会影响系统的整体性能,无法较好支持互联网复杂场景。
技术实现要素:
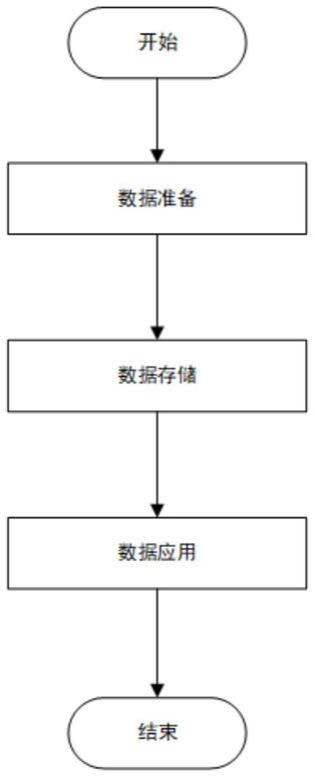
8.发明目的:本发明所要解决的技术问题是高效处理数据,以分布式双向链表存储数据,提供一套高效数据处理方法。本发明具体提供了一种基于分布式双向链表的数据处理方法,包括如下步骤:
9.步骤1,数据准备;
10.步骤2,数据存储;
11.步骤3,数据应用。
12.步骤1包括:根据指定规则生成所需要的数据,并存入到链表集合中。
13.步骤1中,所述指定规则,是指将数据封装成面向对象的数据模型。这里以电商优惠券促销为例,如需要生成10万张满100减50的全场通用券,用户可在指定时间领取。根据指定规则创建优惠券数据模型,包括券唯一编号、券面额、券使用阈值,使用while循环生成10万个对象存入到链表集合中。
14.步骤2包括:将所述链表集合存储到数据库中,分为磁盘数据库存储和内存数据库存储;
15.将所述链表集合以x为步长切割成两个以上数据集合然后组成集合组,再遍历所
述集合组,将所述集合组中的数据集合分别存储到磁盘数据库与内存数据库;如
16.所述磁盘数据库存储,是指将所述集合组中的数据集合循环执行批量存储接口存储到磁盘数据库中,从而将所述链表集合数据持久化到磁盘中;
17.步骤2中,所述内存数据库指redis(remote dictionary server)缓存数据库,将所述链表集合存入到redis缓存数据库中,使用pipeline管道技术将所述集合组中的数据集合作为参数对象,通过插入命令存储到redis缓存数据库的双向链表数据结构,具体操作为通过pipeline管道技术将所述集合组中数据集合的操作指令进行打包并一次性批量推送到redis缓存数据库中,无需等待redis缓存数据库响应状态即一次性发送两条以上操作指令,并最终一次性读取redis缓存数据库中所述操作指令的全部响应状态。因为考虑效率的问题,使用批量存储的方法提高存储速度,减少i/o消耗。将所述链表集合以x为步长切割成若干个小集合组成集合组,再遍历所述集合组,将所述集合组中的集合分别存储到磁盘数据库与内存数据库,考虑到网络i/o消耗,如果使用循环执行插入操作效率低下且还会影响数据库性能,因此使用批量存储操作的方式大大提高性能。
18.步骤3包括:使用lpop获取命令依次从redis缓存数据库的双向链表数据结构中获取单条数据a,获取成功即在redis缓存数据库的双向链表数据结构中移除所述单条数据a,获取到的数据a此时是字符串模型数据,将字符串模型数据a通过反序列化生成面向对象数据模型的数据a',将所述数据a'作为消息发送到消息队列中,消息队列的消费者监听到消息后异步处理所述数据a',并把所述数据a'更新到磁盘数据库中,直到redis缓存数据的双向链表被获取完。
19.本发明具有以下控制优点:
20.(1)批量存储:链表集合分隔成若干个集合组,执行批量入库操作,提高存储速度,减少i/o消耗;
21.(2)内存数据库存储:使用redis缓存存储数据,提高读取与写入速度,减少磁盘数据库的压力,增加数据处理速度;
22.(3)双向链表存储:使用双向链表存储有如下优点:
23.双端:链表节点都有前向和后向指针,这样获取一个节点的前置节点的算法复杂度都为o(1),获取数据效率高。
24.无环:第一个节点(头节点)的前向指针和最后一个节点(尾节点)的后向指针都指向null。
25.带表头指针和表尾指针:通过链表的头和尾两个指针,可以随意的从链表的头和尾进行操作。
26.带链表长度计数器:可以通过计算长度方法来获取链表的节点个数,复杂度o(1)。
27.多态:链表可以保存任意类型的值。
28.(4)管道技术:使用管道技术高效存储海量数据到双向链表中。
29.(5)消息队列处理数据:采用rabbitmq消息队列异步处理数据对象信息,客户端不用等待服务端响应,由消息队列处理数据后续的入库操作,缓解系统压力;
附图说明
30.下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或
其他方面的优点将会变得更加清楚。
31.图1是本发明方法流程图。
32.图2是数据准备流程示意图。
33.图3是数据存储流程示意图。
34.图4是数据应用流程示意图。
具体实施方式
35.下面结合附图及实施例对本发明做进一步说明。
36.如图1所示,本发明提供了一种基于分布式双向链表的数据处理方法,将本发明应用于电商优惠券促销领域,包括数据准备、数据存储、数据应用。
37.如图2所示,本发明的数据准备流程是负责快速生成数据,根据指定规则生成所需要的数据集合。所述指定规则,是指将数据封装成面向对象的数据模型。这里以电商优惠券促销为例,需要生成10万张满100减50的全场通用券,用户可在指定时间领取。根据指定规则创建优惠券数据模型,包括券唯一编号、券面额、券使用阈值,使用while循环生成10万个对象存入到链表集合中。
38.如图3所示,本发明的存储流程主要是将所述链表集合存储到数据库中,分为磁盘数据库存储和内存数据库存储。因为考虑效率的问题,使用批量存储的方法提高存储速度,减少i/o消耗。这里以电商优惠券促销领域为例,将所述链表集合以1000为步长切割成若干个小集合组成集合组,再遍历所述集合组,将所述集合组中的集合分别存储到磁盘数据库与内存数据库,考虑到网络i/o消耗,如果使用循环执行插入操作效率低下且还会影响数据库性能,因此使用批量存储操作的方式大大提高性能。
39.所述磁盘数据库存储是指将所述集合组中的数据集合循环执行批量存储接口存储到磁盘数据库中,从而将所述链表集合数据持久化到磁盘中。
40.所述内存数据库指redis缓存数据库,将所述链表集合存入到redis缓存数据库中,使用pipeline管道技术将所述集合组中的数据集合作为参数对象,通过插入命令存储到redis缓存数据库的双向链表数据结构,具体操作为通过pipeline管道技术将所述集合组中数据集合的操作指令进行打包并一次性批量推送到redis缓存数据库中,无需等待redis缓存数据库响应状态即一次性发送两条以上操作指令,并最终一次性读取redis缓存数据库中所述操作指令的全部响应状态。
41.如图4所示,本发明的数据应用流程以电商优惠券促销领域为例,使用lpop获取命令依次从redis缓存数据库的双向链表数据结构中获取单张优惠券a,获取成功即在redis缓存数据库的双向链表数据结构中移除所述单张优惠券a,获取到的优惠券a此时是字符串模型数据,将字符串模型优惠券a通过反序列化生成面向对象数据模型的优惠券a',将所述优惠券a'作为消息发送到消息队列中,消息队列的消费者监听到消息后异步处理所述优惠券a',并把所述优惠券a'更新到磁盘数据库中,直到redis缓存数据的双向链表被获取完。
42.本发明提供了一种基于分布式双向链表的数据处理方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1