一种基于长短期记忆模型的云服务负载通用预测方法与流程
本发明涉及一种基于长短期记忆模型的云服务负载通用预测方法,属于软件技术领域。
背景技术:
云服务负载预测用来预测在下个时间间隔内到达的作业或请求数量,是实现有效云服务自动扩展的主要需求。通过准确的负载预测,云服务用户或提供商可以设计更好的自动扩展策略或虚拟机调度机制。通过提前正确分配虚拟机或容器的物理资源,避免资源分配过度或不足,从而导致云资源使用成本过高或违反服务级别协议。
不同云服务的不同作业类型的负载模式具有巨大差异性,例如循环、渐变或突发,同时负载模式随着时间的推移而变化。负载模式的多样性需要针对每个负载类型调整和优化负载预测方法,从而能够准确识别和预测负载的各种模式。普通云服务用户通常不具备统计学、时间序列和机器学习方面的专业知识,难预测特定云服务的负载特征和数量。因此,需要提供通用的云服务负载预测方法,以准确预测各种动态负载。云服务提供商通过提供通用的负载预测方法,来帮助普通云服务用户根据预测的负载,为自动化伸缩操作提供决策依据。
已有负载预测方法通常面向特定应用类型,如云计算(charlesreiss,alexeytumanov,gregoryganger,randykatz,andmichaelkozuch.heterogeneityanddynamicityofcloudsatscale:googletraceanalysis.inacmsymp.oncloudcomputing,2012.)、网格计算(alexandruiosup,huili,mathieujan,shannyanoep,catalindumitrescu,lexwolters,anddickh.j.epema.thegridworkloadsarchive.futuregenerationcomputersystems,24(7),2008.),应对不同负载类型,例如作业到达率、资源需求。这些方法将负载表示为时间序列数据,以应用不同的时间序列模型,如es/wma(anshulgandhi,morharchol-balter,ramraghunathan,andmichaela.kozuch.autoscale:dynamic,robustcapacitymanagementformulti-tierdatacenters.acmtrans.oncomputersystems,30(4),2012.)、arima(haolin,xinqi,shuoyang,andsamuelp.midkiff.workload-drivenvmconsolidationinclouddatacenter.inieeeinternationalparallelanddistributedprocessingsymposium(ipdps),2015.)。然而,这些方法仅针对特定类型的云服务类型和工作负载进行模型训练,不同的预测方法仅针对特定的负载能够产生准确的预测结果,难以应用于不同或未知的负载模式,因此缺乏通用性。
技术实现要素:
本发明的目的:解决当前负载预测方法仅针对特定类型的云服务类型和工作负载进行模型训练,难以应用于不同或未知的负载模式,因而缺乏通用性的问题。
本发明的原理:提出一种通用的云服务负载预测方法,基于长短期记忆模型以准确预测各种类型各种云服务的动态负载。同时,采用了贝叶斯优化方法以训练模型的超参数,以生成针对特定负载的准确预测模型。可以跟踪数据中相对长期的相关性,从而能够预测负载中的各种模式。
本发明技术解决方案:一种基于长短期记忆模型的云服务负载通用预测方法,其特点在于实现步骤如下:
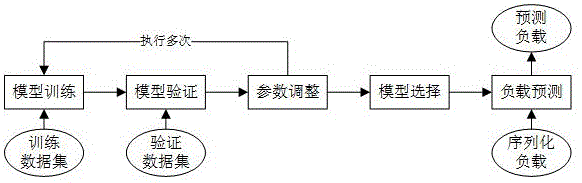
步骤1:模型训练。随机选择一组超参数,配置初始长短期记忆模型,然后使用训练数据集对其进行训练,经过训练得到新模型。
步骤2:模型验证。使用云服务负载数据集对模型进行交叉检验。将预测的作业到达率与实际的作业到达率进行比较,计算出模型的平均预测误差。具体步骤如下:
长短期记忆人工神经网络是循环神经网络的一种优化和延伸,通过上一个状态的输出和当前的输入两个值决定的,从而能够将以前的信息连接到当前任务以利用历史信息。然而,循环神经网络在当前任务和历史信息较远时无法有效的利用历史信息,为解决循环神经网络在长依赖上的问题,长短期记忆模型具有两个传递状态
(1)忘记阶段,作为门控状态,也就是所谓的“忘却门”,用于控制上个状态值
(2)选择记忆阶段,决定对输入
(3)输出阶段,对上一任务状态
步骤3:参数调整。根据模型超参数及其误差,使用贝叶斯优化从可能的超参数的预定义搜索空间中选择新的和可能的超参数集。然后,执行在步骤1,使用新的超参数集来配置和训练新的模型。主要包括以下超参数:
(1)历史长度n:当n太小时,模型很难学习跨越长时间的依赖性;当n太大时,模型可能学习不相关的依赖关系,并遭受爆炸/消失梯度问题,导致预测精度差并产生高计算开销。(2)单元存储器的大小(单元数量)s:单元存储器由长度为s的向量表示,如果s太大就会增加模型的复杂性,增加过度拟合的风险。模型可能与训练数据过于接近,失去预测未来数据的能力,导致更高的计算成本。如果s太小,则可能无法捕捉数据中复杂的时间相关性,从而导致较差的预测精度。(3)模型层数也有类似的问题。(4)批处理训练数据的大小,影响训练过程的有效性,从而影响训练模型的准确性。
本发明使用贝叶斯优化技术(jonasmockus.onbayesianmethodsforseekingtheextremumandtheirapplication.in7thifipcongressoninformationprocessing,1977.)为每个负载和/或负载的每个部分搜索更好的超参数集。贝叶斯优化用高斯过程的非线性回归来搜索更好的超参数。搜索是迭代优化过程,在每次迭代中,贝叶斯优化使用已经探索过的超参数集及相应的模型精度。用高斯过程建立回归模型,然后使用该模型预测可能更好的超参数以训练模型,该模型的精度通过交叉验证数据集进行评估。在若干次数的迭代之后,从这些迭代中找到最佳模型。
步骤4:模型选择。训练和优化过程重复执行多次迭代过程。在这些迭代之后,比较所有验证的模型,并且选择具有最低误差的模型作为最终模型。
步骤5:负载预测。使用预测步骤4得到的模型,根据历史云服务负载数据预测未来的作业到达率。
本发明与现有技术相比具有如下优点:
1)基于长短期记忆模型以准确预测各种类型各种云服务的动态负载;
2)基于贝叶斯优化方法训练模型超参数,以生成针对特定负载的预测模型;
3)可以跟踪数据中相对长期的相关性,从而能够预测负载中的各种模式。
附图说明
图1为云服务负载预测方法步骤。
具体实施方式
以下结合具体实施例和附图对本发明进行详细说明,如图1所示,本发明实施例方法流程:
云服务负载数据搜集:搜集来自不同类别的云服务负载用于评估负载预测方法,例如,web应用负载、高性能计算负载、公有云访问负载、数据中心工作负载等。为了评估负载预测方法在不同的负载模式下是否正常工作,这些负载以不同的间隔长度进行评估。
云服务负载预测模型构建:负载预测方法使用tensorflow、scikit-learn和gpyopt实现。对于长短期记忆模型训练,使用“均方误差”作为损失函数,adam优化算法作为优化器;对于贝叶斯优化,使用高斯过程作为概率模型以构建回归。基于以上方法。
云服务负载预测模型训练:训练集和交叉验证集的大小定义为:每个负载的前60%的作业到达率设置为训练集,20%用作交叉验证集,20%用于测试负载预测方法的准确性。
云服务负载预测模型参数优化:使用贝叶斯优化来搜索超参数需要定义搜索空间。搜索空间表示为超参数值的范围,包括历史长度的范围、长短期模型单元矢量大小、长短期模型层数和批量处理数据量、优化迭代的次数。迭代计数表示将使用贝叶斯优化生成的超参数集的数量,生成的集合越多,找到准确集合的机会就越大,但更多的迭代也需要更多的执行时间。
将当前云服务负载时间序列数据作为输入,基于以上构建的云服务负载预测模型进行预测,输出为下一个时间点的云服务负载量。
- 还没有人留言评论。精彩留言会获得点赞!