基于音视频的鲁棒情感建模系统
本发明涉及多模态情感识别领域,尤其涉及基于音视频的鲁棒情感建模系统。
背景技术:
二十世纪以来,随着人工智能技术的飞速发展,各类智能机器逐渐进入人们的日常生活,扮演着日益重要的角色。与此同时,人们渴望与智能机器进行交流,这促使了社交网络机器人与类人机器人的发展,其中一个关键问题在于机器对人的理解,而情感在其中扮演着重要的角色。情感有助于快速传递信息和理解用户真实意图,是人机交互的关键部分。
人们通过多种方式表达情感,不同表达方式之间存在着互补作用。多模态情感识别能够有效提高情感识别性能以及系统鲁棒性,因此本文围绕着多模态情感识别技术开展研究。
公开号为cn111292765a的专利公开了一种融合多个深度学习模型的双模态情感识别方法,包括步骤:a)采集音视频信号,获得音频数据样本和视频数据样本;b)构建音频深度卷积神经网络和多模视频深度卷积神经网络,获得高层次音频特征和高层次视频特征;c)构建高层次的音视频统一特征,建立由受限玻尔兹曼机构成的深度信念网络,深度信念网络最后一层隐藏层的输出做平均池化之后与线性支持向量机分类器相连;d)获得音视频情感识别分类结果,验证深度信念网络的识别率。
公开号为cn110852215a的专利公开了一种多模态情感识别方法、系统及存储介质,所述方法包括:响应所监听到的情感识别任务请求,采集音视频数据;从音视频数据中提取视频情感特征、音频情感特征和语义情感特征;将视频情感特征、音频情感特征和语义情感特征进行特征融合;依据融合情感特征进行情感特征识别。所述系统包括cpu、fpga和存储单元;cpu能够执行前述方法步骤,fpga能够执行前述方法中的特征提取及特征融合步骤。
但是,在实际场景中,音视频数据难免存在噪声干扰,这影响着多模态情感识别系统的性能。如何增强音视频情感识别系统在实际场景中的鲁棒性是目前亟待解决的关键问题。
技术实现要素:
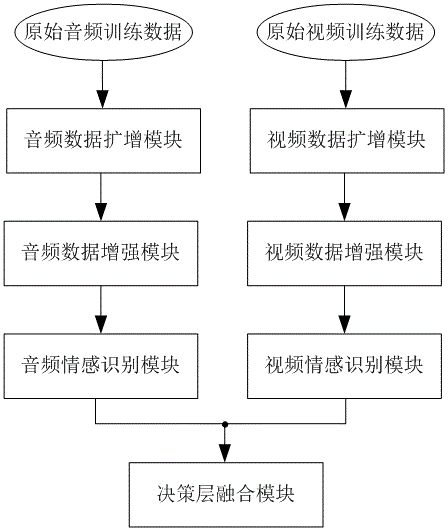
有鉴于此,本发明提供一种基于音视频的鲁棒情感建模系统,包括:音频数据扩增模块、音频数据增强模块、音频情感识别模块、视频数据扩增模块、视频数据增强模块、视频情感识别模块和决策层融合模块;
训练过程:原始音频训练数据通过所述音频数据扩增模块进行数据扩增,得到带噪音频训练数据,应用所述带噪音频训练数据去训练音频数据增强模块,使所述音频数据增强模块具备剔除音频数据中的噪声信息的能力,剔除所述带噪音频训练数据中的噪声信息,得到增强语音训练数据,将所述增强语音训练数据输入所述音频情感识别模块,进行训练并识别音频训练情感状态;原始视频训练数据通过所述视频数据扩增模块进行数据扩增,得到带噪视频训练数据,应用所述带噪视频训练数据去训练视频数据增强模块,使所述视频数据增强模块具备剔除视频数据中的噪声信息的能力,剔除所述带噪视频训练数据中的噪声信息,得到增强视频训练数据,将所述增强视频训练数据输入所述视频情感识别模块,进行训练并识别视频训练情感状态;所述决策层融合模块将所述音频训练情感状态和所述视频训练情感状态融合,进行训练并输出情感识别预测结果;
识别过程:将音频数据输入训练好的音频数据增强模块,剔除音频数据中的噪声信息,得到增强语音数据,将所述增强语音数据输入训练好的音频情感识别模块,得到音频情感状态;视频数据输入训练好的视频数据增强模块,剔除视频数据中的噪声信息,得到增强视频数据,将所述增强视频数据输入训练好的视频情感识别模块,得到视频情感状态;将所述音频情感状态和所述视频情感状态输入训练好的所述决策层融合模块进行特征融合,并并输出情感识别结果。
优选的,所述音频数据扩增模块进行数据扩增的具体方法为:
根据设置的音频信噪比数值,将所述原始音频训练数据为y与噪声数据逐一采样点相加,从而获取带噪音频训练数据,所述带噪音频训练数据为x。
优选的,所述音频数据增强模块剔除所述带噪音频训练数据中的噪声信息,得到增强语音训练数据的具体方法为:
所述带噪音频训练数据x被分解为t个长度为l的重叠段,x=[x1,x2,…xt],其中
利用一维卷积网络
其中,隐层音频特征
再利用一维卷积网络,预测隐层音频特征
其中,
为了使所述掩蔽向量属于[0,1]之间,将掩蔽向量输入到sigmoid激活函数,得到激活后的掩蔽向量,
将激活后的掩蔽向量
其中,
利用反卷积网络将
其中,
优选的,所述应用所述带噪音频训练数据去训练音频数据增强模块选用最小均方误差损失函数mse,计算增强语音训练数据
优选的,所述将所述增强语音训练数据输入所述音频情感识别模块,进行训练并识别音频训练情感状态的具体方法为:
将增强语音训练数据
将
通过计算音频训练情感状态与真实情感标签之间的交叉熵损失函数,训练语音情感识别模型。
优选的,所述视频数据扩增模块进行数据扩增的具体方法为:
原始视频训练数据中包含t帧图像,对原始视频训练数据中每一帧进行数据扩增;定义原始视频训练数据为
,其中
根据设置的视频信噪比数值,将
优选的,所述视频数据增强模块剔除所述带噪视频训练数据中的噪声信息,得到增强视频训练数据的具体方法为:
利用二维卷积网络
再利用反卷积
重复得到增强视频训练数据的具体方法的步骤,得到增强视频训练数据:
优选的,应用所述带噪视频训练数据去训练视频数据增强模块选用最小均方误差损失函数mes,计算增强图像训练数据与原始视频训练数据中图像帧之间的相似性,损失函数定义为:
优选的,所述将所述增强视频训练数据输入所述视频情感识别模块,进行训练并识别视频训练情感状态的具体方法为:
利用卷积神经网络,从增强视频训练数据中获取隐层视频特征
将隐层视频特征
将视频级别的特征表示输入到单层感知机中,得到所述视频训练情感状态;通过计算所述视频训练情感状态与真实视频情感标签之间的交叉熵损失函数,训练所述视频情感识别模型。
优选的,利用权重系数将所述音频训练情感状态和所述视频训练情感状态融合,所述权重系数根据情感识别结果进行调节。
本发明实施例提供的上述技术方案与现有技术相比具有如下优点:
本发明实施例提供的该方法,
(1)在训练过程中引入数据扩增方法,能够模拟真实场景下的噪声情况,为增强模型提供训练数据;
(2)利用前端增强模型与后端识别模型结合,能够有效提升音视频情感识别系统的鲁棒性。
附图说明
图1为本发明实施例提供的一种基于音视频的鲁棒情感建模系统训练过程流程图;
图2为本发明实施例提供的一种基于音视频的鲁棒情感建模系统识别过程流程图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
如图1、图2所示,本发明实施例提供的基于音视频的鲁棒情感建模系统,包括:音频数据扩增模块、音频数据增强模块、音频情感识别模块、视频数据扩增模块、视频数据增强模块、视频情感识别模块和决策层融合模块;
训练过程:原始音频训练数据通过所述音频数据扩增模块进行数据扩增,得到带噪音频训练数据,应用所述带噪音频训练数据去训练音频数据增强模块,使所述音频数据增强模块具备剔除音频数据中的噪声信息的能力,剔除所述带噪音频训练数据中的噪声信息,得到增强语音训练数据,将所述增强语音训练数据输入所述音频情感识别模块,进行训练并识别音频训练情感状态;原始视频训练数据通过所述视频数据扩增模块进行数据扩增,得到带噪视频训练数据,应用所述带噪视频训练数据去训练视频数据增强模块,使所述视频数据增强模块具备剔除视频数据中的噪声信息的能力,剔除所述带噪视频训练数据中的噪声信息,得到增强视频训练数据,将所述增强视频训练数据输入所述视频情感识别模块,进行训练并识别视频训练情感状态;所述决策层融合模块将所述音频训练情感状态和所述视频训练情感状态融合,进行训练并输出情感识别预测结果;
识别过程:将音频数据输入训练好的音频数据增强模块,剔除音频数据中的噪声信息,得到增强语音数据,将所述增强语音数据输入训练好的音频情感识别模块,得到音频情感状态;视频数据输入训练好的视频数据增强模块,剔除视频数据中的噪声信息,得到增强视频数据,将所述增强视频数据输入训练好的视频情感识别模块,得到视频情感状态;将所述音频情感状态和所述视频情感状态输入训练好的所述决策层融合模块进行特征融合,并并输出情感识别结果。
根据上述方案,进一步,所述音频数据扩增模块进行数据扩增的具体方法为:
根据设置的音频信噪比数值,音频信噪比数值范围设置为0db~20db,将所述原始音频训练数据y与噪声数据逐采样点相加,从而获取带噪音频训练数据x。
根据上述方案,进一步,所述音频数据增强模块剔除带噪音频训练数据中的噪声信息,得到增强语音训练数据的具体方法为:
所述带噪音频训练数据x被分解为t个长度为l的重叠段,x=[x1,x2,…xj…xt],其中
利用一维卷积网络
其中,隐层音频特征
再利用卷积网络,预测隐层音频特征
其中,
为了使所述掩蔽向量属于[0,1]之间,将掩蔽向量输入到sigmoid激活函数,得到激活后的掩蔽向量,
将激活后的掩蔽向量
其中,
利用反卷积网络将
其中,
根据上述方案,进一步,所述应用所述带噪音频训练数据去训练音频数据增强模块选用最小均方误差损失函数mse,计算增强语音训练数据
根据上述方案,进一步,所述将所述增强语音训练数据输入所述音频情感识别模块,进行训练并识别音频训练情感状态的具体方法为:
将增强语音训练数据
将
通过计算音频训练情感状态与真实情感标签之间的交叉熵损失函数,训练语音情感识别模型。
根据上述方案,进一步,所述视频数据扩增模块进行数据扩增的具体方法为:
原始视频训练数据中包含t帧图像,对原始视频训练数据中每一帧进行数据扩增;定义原始视频训练数据为
根据设置的视频信噪比数值,视频信噪比数值范围设置为0db~20db,将原始视频训练数据的图像帧
根据上述方案,进一步,所述视频数据增强模块剔除带噪视频训练数据中的噪声信息,得到增强视频训练数据的具体方法为:
利用卷积网络
再利用反卷积
重复上述步骤,得到增强视频训练数据
根据上述方案,进一步,应用所述带噪视频训练数据去训练视频数据增强模块选用最小均方误差损失函数mes,计算增强图像训练数据与原始视频训练数据中图像帧之间的相似性,损失函数定义为:
根据上述方案,进一步,所述将所述增强视频训练数据输入所述视频情感识别模块,进行训练并识别视频训练情感状态的具体方法为:
利用卷积神经网络,从增强视频训练数据中获取隐层视频特征
将隐层视频特征
将视频级别的特征表示输入到单层感知机中,得到所述视频训练情感状态;通过计算所述视频训练情感状态与真实视频情感标签之间的交叉熵损失函数,训练所述视频情感识别模型。
根据上述方案,进一步,利用权重系数将所述音频训练情感状态和所述视频训练情感状态融合,所述权重系数根据测试验证的情感识别结果调节。
具体而言,假设音频训练情感状态为pa,视频训练情感状态为pb,依据权重系数λ将pa和pb进行融合。其中,λ从[0,1]中进行选取。λ根据情感识别结果进行调节,使得情感识别准确率最高。
p=λpa+(1-λ)pb
应当理解,尽管在本发明可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本发明范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
虽然本说明书包含许多具体实施细节,但是这些不应被解释为限制任何发明的范围或所要求保护的范围,而是主要用于描述特定发明的具体实施例的特征。本说明书内在多个实施例中描述的某些特征也可以在单个实施例中被组合实施。另一方面,在单个实施例中描述的各种特征也可以在多个实施例中分开实施或以任何合适的子组合来实施。此外,虽然特征可以如上所述在某些组合中起作用并且甚至最初如此要求保护,但是来自所要求保护的组合中的一个或多个特征在一些情况下可以从该组合中去除,并且所要求保护的组合可以指向子组合或子组合的变型。
类似地,虽然在附图中以特定顺序描绘了操作,但是这不应被理解为要求这些操作以所示的特定顺序执行或顺次执行、或者要求所有例示的操作被执行,以实现期望的结果。在某些情况下,多任务和并行处理可能是有利的。此外,上述实施例中的各种系统模块和组件的分离不应被理解为在所有实施例中均需要这样的分离,并且应当理解,所描述的程序组件和系统通常可以一起集成在单个软件产品中,或者封装成多个软件产品。
由此,主题的特定实施例已被描述。其他实施例在所附权利要求书的范围以内。在某些情况下,权利要求书中记载的动作可以以不同的顺序执行并且仍实现期望的结果。此外,附图中描绘的处理并非必需所示的特定顺序或顺次顺序,以实现期望的结果。在某些实现中,多任务和并行处理可能是有利的。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!