一种在计算系统中实现卷积运算的方法及计算系统与流程
1.本发明涉及计算领域,更具体地,涉及一种在计算系统中实现卷积运算的方法及计算系统。
背景技术:
2.深度神经网络(dnn)是当前人工智能(ai)应用的基础,例如,语音识别,图像识别,视频处理,自动驾驶,癌症检测,游戏对抗等,而且在部分领域,dnn已经超过了人类的精确性。
3.图1显示了一个较为简单的神经网络计算过程:输入层的神经元将接收到的信息传递到神经网络中间层(也称为隐藏层),而隐藏层的“权重和”最终会传输到输出层,并最终呈现给用户。通常会把神经元的输入或输出称为“激活”(activation),而把突触称为“权重”(weight)。在本发明中,包括说明书及其附图中,后续会使用activation/weight、激活/权重、输入或输出/权重。本领域技术人员应该理解,这些术语是可以替换使用的。
4.图2展示了每层的计算: w
ij
是权重,x
i
是输入激活,y
j
是输出激活,f(.)是一个非线性函数,b则是偏置。
5.一种常用的dnn形式被称为卷积神经网络(cnn),含有多个卷积(conv)层。在这样的网络中,每层都会产生输入数据的高层次抽象,称为特征图(fmap或feature map)。一个典型的cnn模型如图3所示,会包含5到1000个conv层,以及在conv层之后包含1到3层的全连层。其余包含的非线性层、归一化层、池化层等,因为功耗极小不在本文讨论范围内。
6.一个2维卷积输入包括输入特征图(input fmap)和卷积核(filter或者称为weight),操作如下:1.输入特征图是h * w的矩阵,比如28x28的图片像素,卷积核是r * s的矩阵,比如3x3核,如图4所示;2.使用卷积核和输入特征图左上角对应大小的矩阵对应元素相乘并相加得到输出特征图最左上角的一个元素。对应相乘的操作,如图5所示;3.滑动卷积核与输入特征图对应大小矩阵继续对应元素相乘并得到输出特征图下一个元素,如图6所示。
7.当输入特征图具有多个通道(channel),一个具体的实例就是图片从黑白图片变成了彩色图片,于是具有rgb三个通道,则卷积操作变成图7所示,每个通道都有独立的输入特征图和卷积核,不同通道之间最终进行加法合并操作。
8.当输入特征图具有多个(比如n个)图片,且拥有多个卷积核(比如m个)时,卷积操作则为图8所示。
9.如此,得到了最终多维卷积操作公式如下:
式中各个参数如下:o
ꢀꢀ
输出特征图矩阵i
ꢀꢀ
输入特征图矩阵w
ꢀꢀ
卷积核矩阵b
ꢀꢀ
偏置矩阵n
ꢀꢀ
三维特征图批次大小m
ꢀꢀ
三维卷积核数目/输出特征图通道数目c
ꢀꢀ
输入特征图/卷积核通道数目h/w
ꢀꢀ
输入特征图平面高度/宽度r/s
ꢀꢀ
卷积核平面高度/宽度e/f
ꢀꢀ
输出特征图平面高度/宽度u
ꢀꢀ
切分窗口的步长一个典型的例子是alexnet,如图9所示,其对应的卷积操作参数如下。
10.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
h/w
ꢀꢀꢀꢀꢀꢀꢀꢀ
r/s
ꢀꢀꢀꢀꢀꢀꢀꢀ
e/f
ꢀꢀꢀꢀꢀꢀꢀꢀ
c
ꢀꢀꢀꢀꢀꢀ
m
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
uconv1
ꢀꢀꢀꢀꢀꢀ
227
ꢀꢀꢀꢀꢀꢀꢀꢀ
11
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
55
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ3ꢀꢀꢀꢀꢀꢀ
96
ꢀꢀꢀꢀꢀꢀꢀꢀ
4conv2
ꢀꢀꢀꢀꢀꢀ
21
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ5ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
27
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
48
ꢀꢀꢀꢀꢀ
256
ꢀꢀꢀꢀꢀꢀꢀ
1conv3
ꢀꢀꢀꢀꢀꢀ
15
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ3ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
13
ꢀꢀꢀꢀꢀꢀꢀꢀ
256
ꢀꢀꢀꢀ
284
ꢀꢀꢀꢀꢀꢀꢀ
1conv4
ꢀꢀꢀꢀꢀꢀ
15
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ3ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
13
ꢀꢀꢀꢀꢀꢀꢀꢀ
192
ꢀꢀꢀꢀ
284
ꢀꢀꢀꢀꢀꢀꢀ
1conv5
ꢀꢀꢀꢀꢀꢀ
15
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ3ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
13
ꢀꢀꢀꢀꢀꢀꢀꢀ
192
ꢀꢀꢀꢀ
256
ꢀꢀꢀꢀꢀꢀꢀ
1其中,conv1 、conv2、 conv3、 conv4和 conv5表示卷积层;h/w、r/s、e/f、c、m和u表示cnn形状参数。
11.现有的主流cpu难以高性能、高效能地完成卷积计算。相比一般的通用计算,卷积计算中存在的大量数据复用以及计算的规则性,在架构设计和计算优化有很大的优化空间,由此诞生众多针对卷积神经网络加速的芯片。
12.卷积即矩阵乘通用图形处理器(gpgpu)加速器会采用通用矩阵乘(gemm)方式实现卷积加速。gemm的应用在cnn之前已经非常广泛,很多线性代数库充分结合了矩阵计算中的数据复用关系和处理器缓存的层次设计结构,对gemm乘法进行了充分的优化。c = ab + c的矩阵乘法可以表示为:for i = 1 : m
ꢀꢀ
for j = 1 : n
ꢀꢀꢀꢀꢀ
for k = 1 : t
ꢀꢀꢀꢀꢀꢀꢀꢀ
c (i, j) = a(i, k) * b(k, j) + c(i, j)而当前主流的gpgpu会针对矩阵乘做专门的硬件加速,如图10所示。通用矩阵乘法被广泛应用于卷积操作,具体实现方式如下图11所示。输入矩阵m*k和k*n,其中m为行数,n
为列数,m=h*w,k=r*s*c,n=k。一个简单的实例如图12所示。
13.可以看出,从卷积转为矩阵乘,会带来大量的数据重复,例如虚线框重合的部分(数据为2和1),这样就带来无法避免的麻烦:要么大量重复数据带来带宽和功耗的损失,要么带来地址计算的负担。
14.tpu脉动阵列加速器另外一种实现矩阵乘法的方式被称为脉动阵列加速器,典型代表是google tpu。其计算核心为一个256x256的二维脉动阵列,如图13所示,其中的每个运算单元(cell)如图14所示。脉动阵列就是让数据在运算单元的阵列中进行流动,减少访存的次数,并且使得结构更加规整,布线更加统一,提高频率。图15显示了传统计算结构和脉动阵列结构的对比。图15左边是传统计算架构,可用于各种形式的计算,比如cpu,gpu就是这种架构,用寄存器存储数据,一个程序告诉alu(算术逻辑单元)从寄存器中取数,然后执行一种操作(例如加法,乘法或者逻辑操作),然后再把结果写回指定寄存器中。脉动阵列则是,如图15右边所示,第一个alu取数,经过处理后被传递到下一个alu,同时第二个数据进入第一个alu,依次类推。在第一个数据到最后一个alu之后,每个周期都能得到一个结果。
15.这样,脉动阵列可以平衡io读写与运算,在消耗较小内存(memory)带宽的情况下提高吞吐率,有效解决数据存取速度远远大于数据处理速度的结构。脉动阵列本身只是一个有数据流动的结构,根据不同的应用会有不同的数据进行流动以及不同的流动方向。
16.一个y = x * w矩阵乘的tpu脉动阵列实现方式如图17所示。
17.在图16中,5行5列的输入特征图矩阵作为x,5行5列的权重矩阵作为w,进行矩阵乘之后,得到5行5列的输出特征图矩阵y。如前所述,矩阵乘的运算规则为:y00 = x00 * w00 + x01 * w10 + x02 * w20 + x03 * w30 + x04 * x40y01 = x00 * w01 + x01 * w11 + x02 * w21 + x03 * w31 + x04 * x41
……
y44 = x40 * w04 + x41 * w14 + x42 * w24 + x43 * w34 + x44 * x44运算流程如下:1.如图16下方所示,在计算单元(pe cell)中固定权重(weight),并纵向传播输入特征图矩阵的激励元素(activation)以及横向传播部分和(psum)。
18.2.如图17所示,在cycle0这一时钟周期,输入x00到阵列中的第一行第一列,和w00进行相乘得到y00。
19.3.仍如图17所示,在cycle1,输入x10到阵列第一行第一列,传播部分和y00(=x00 * w00)到第一行第二列(w10)。输入x01到阵列第一行第二列,与w10进行相乘并加上传播过来的部分和y00得到新的y00(= x00 * w00 + x01 * w10),并同时传播x00到第二行第一列(w01)。
20.4.如图18所示,在接下来的时钟周期cycle2、cycle3,继续输入x,纵向传播x和横向传播y。
21.5.如图19所示,经过cycle4,到cycle5,y00传播出阵列,此时得到y00 = x00 * w00 + x01 * w10 + x02 * w20 + x03 * w30 + x04 * x40。
22.6.如图20所示,在cycle 6得到y10和y01,cycle 7得到y20、y11和y02。
23.7.如图21所示,在cycle8得到y30、y21、y12、y03,在cycle9得到y40、y31、y22、y13、
y04。
24.8.如图22所示,在cycle10得到y41、y32、y23和y14,在cycle11得到y42、y33、y24。
25.9.如图23所示,在cycle12得到y43、y34,在cycle13得到y44,至此所有结果都已经获得。
26.本领域技术人员应该理解,如上所述的横向和纵向实际上可以互换。因此,可以将其称为在计算单元阵列(脉动阵列)的一个方向上和另一个方向上。
27.更一般地,通过脉动阵列完成y = x * w的矩阵乘运算,其中x为输入特征图矩阵,w为权重矩阵,y为输出特征图矩阵,可以包括如下步骤:1.在计算单元中固定权重矩阵w中的权重元素,如图16中所示。
28.2.在计算单元阵列的一个方向上,按时钟周期依次传播输入特征图矩阵x的各元素。如图16
‑
23中所示,沿纵向传播x的元素。具体地说,x的列(例如x00、x10、x20、x30、x40)与w的行(例如w00、w01、w02、w03、w04)相对准(图中为纵向),并按时钟周期依次传播,从而在每个时钟周期分别完成每两个对应元素的相乘运算。另一方面,x的各列之间相错一个时钟周期再开始传播进入阵列,例如,x的第二列(x01、x11、x21、x31、x41)比x的第一列(x00、x10、x20、x30、x40)晚一个时钟周期,x的第三列比第二列晚一个时钟周期,以此类推,最后是x的第五列。由此,第一个进入阵列的是x的第一行第一列的元素x00,最后一个进入阵列的是x的第五行第五列的元素x44。
29.3)在每个计算单元中,将传播到此计算单元的x的元素与在此计算单元中固定的w的权重元素进行乘法运算,并累加上一计算单元传播而来的上一周期的部分和计算结果,得到当前计算单元在当前时钟周期的部分和计算结果。例如,在cycle1,输入x01到阵列第一行第二列,与w10进行相乘并加上传播过来的部分和y00得到新的y00(= x00 * w00 + x01 * w10)。
30.4.在计算单元阵列的另一个方向上,按时钟周期传播并累加各个计算单元的部分和计算结果。如图17
‑
23中所示,沿横向传播部分和(psum)。具体地说,在w的每列(图中为横向),各个计算单元横向传播部分和,例如y00从w00所在的计算单元,一直向右传播经过w10、w20、w30、w40所在的计算单元,一边传播一边累加在各个计算单元的乘法运算结果,即y00 = x00 * w00 + x01 * w10 + x02 * w20 + x03 * w30 + x04 * x40。
31.5.直到部分和计算结果传播出计算阵列,依次得到输出特征图矩阵y的各个元素。继cycle5得到y00的最终结果之后,以后的时钟周期各有若干y的元素得到最终结果,一直到cycle13得到y44,得到了所有结果。
32.对于卷积运算而言,需要将卷积核与输入数据进行转换,即增加重复数据,并相应进行排列,从而形成矩阵乘的权重矩阵和输入特征图矩阵,以便进行脉动阵列下的矩阵乘优化。
33.一个具体实例针对3x3卷积核的卷积操作实现方式如图24所示。
34.如图24所示,将5x5的输入数据和3x3的卷积核分别都扩展为9x9的矩阵。
35.一般地,在所述卷积神经网络模式下,通过脉动阵列完成卷积运算,包括如下步骤:1.将卷积核按照卷积循环相乘的方式通过循环复制而扩展为权重矩阵w。例如,如上所述,3x3的卷积核被扩展为9x9的权重矩阵,具体的行和列的元素可参见图24。
36.2.将输入数据按照卷积循环相乘的方式通过与权重矩阵元素相对应的循环复制而扩展为输入特征图矩阵x。本领域技术人员应该理解,输入数据为实际的输入特征图矩阵,经过扩展后变为适于进行矩阵乘优化的输入特征图矩阵。这里,如上所述,5x5的输入数据被扩展为9x9的矩阵。
37.3.通过脉动阵列完成y = x * w的矩阵乘运算。
38.关于卷积运算转换为矩阵乘运算的扩展过程,还可以参看本发明说明书背景技术中有关gpgpu加速器以及gemm优化的说明。
39.从图24的实现中不难看出,此架构下最大程度减小了卷积核(或者说权重weight)的移动。
40.shidiannao脉动阵列加速器寒武纪的shidiannao如图25所示,采用的是另外一种脉动阵列方式。
41.1.在计算单元(pe cell)中固定部分和(psum),并横向传播输入激励元素(activation)以及纵向传播权重(weight)。参见图26。
42.2.在cycle0,参见图27,x00和w00分别从第一行和第一列进入计算单元的阵列,在第一行第一列的计算单元中计算x00*w00。
43.在cycle1,仍参见图27,x01、x10分别从第一行和第二行进入计算单元的阵列,w10和w01分别从第一列和第二列进入计算单元的阵列。在第一行第一列的计算单元中计算x01*w10并与之前的部分和x00*w00累加得到x00*w00 + x01*w10。x00传播到第一行第二列,在第一行第二列的计算单元中计算x00*w01。w00传播到第一列第二行,在第一列第二行的计算单元中计算x10*w00。
44.3.在cycle2,参见图28,x02、x11、x20分别从第一行、第二行和第三行进入计算单元的阵列,w20、w11、w02分别从第一列、第二列和第三列进入计算单元的阵列。在第一行第一列的计算单元中计算x02*w20并与之前的部分和x00*w00 + x01*w10累加得到x00*w00 + x01*w10 + x02*w20。x00传播到第一行第三列,在第一行第三列的计算单元中计算x00*w02。x01传播到第一行第二列,在第一行第二列的计算单元中计算x01*w11并与之前的部分和x00*w01累加得到x00*w01 + x01*w11。w00传播到第一列第三行,在第一列第三行的计算单元中计算x20*w00。w10传播到第一列第二行,在第一列第二行的计算单元中计算x11*w10并与之前的部分和x10*w00累加得到x10*w00 + x11*w10。
45.在cycle3,仍参看图28,x03、x12、x21、x03横向传播进入阵列,w30、w21、w12、w03纵向传播进入阵列。类似地,在阵列中各个计算单元上进行乘法与累加运算。
46.4.依次类推,直到cycle12和cycle13。在cycle13之后,x和w都将传播出阵列。也就是说,在cycle13得到所有的输出结果,如图29中所示。即,分别在各个计算单元中通过累加得到了最终的输出矩阵y的各个结果,y00、y01、...、y44。
47.从图26
‑
29的实现中不难看出:shidiannao脉动阵列方式最大程度减小了部分和数据的移动。
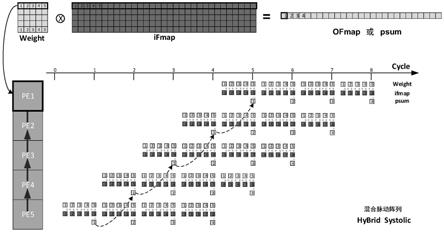
48.卷积神经网络(cnn)因为它的强大精确性广泛应用于现代ai系统,但是也带来了吞吐率和能耗效率的巨大挑战。这是因为,计算需要读取和写入大量的数据,以及芯片中和芯片之间的数据移动,而这些数据移动消耗的功耗甚至会超过计算本身。而在cnn中卷积计算占整个计算(包括推理,测试,训练)90%以上,因此对于任何大小的卷积计算,如何最大程
度地减少数据移动对于吞吐率和功能性能的影响就变得至关重要。现有npu(neuronal processing unit)技术在解决此问题上主要采用两种非常巧妙的方式进行卷积加速:tpu脉动阵列shidiannao脉动阵列现有的架构模型显示,两种架构下,shidiannao会更有能效比的优势,如图30所示,其数值表示了归一化能量。
49.但是,上述两种脉动阵列仍有一定的局限性,即它们都只利用了空域的累积特性,却完全放弃了gpgpu的时域累加特性,使得卷积仍然绕不开矩阵操作。而一旦卷积转换为矩阵则会增加大量的重复数据,使得输入输出数据的移动无法继续减小从而优化能效。
技术实现要素:
50.有鉴于此,本发明提出了一种在计算系统中实现卷积运算的方法及计算系统,结合了gpgpu的时域累加特性和脉动阵列的空域累加特性,直接实现卷积操作,实现一种高效的运算数据传输,从而达到能效的最低。
51.根据本发明的实施例,本发明的第一方面提供一种在计算系统中实现卷积运算的方法。计算系统中的寄存器被配置为多个计算单元,每个计算单元被配置为同时完成一个或多个乘法运算并将乘法运算的结果相加得到每个计算单元的计算结果。所述方法包括:对于一维卷积操作:将卷积核数据的m个元素固定于计算单元中,使输入数据的n个元素按时钟周期依次滑动进入计算单元,其中,m、n为自然数且m≤n;在每个时钟周期,使卷积核数据的m个元素分别一一对应于输入数据的n个元素中的m个数据,使卷积核数据的m个元素与滑动到计算单元中对应位置上的输入数据的对应的m个元素分别进行乘法运算并将乘积相加,存为当前时钟周期的计算结果;依次输出每个时钟周期的计算结果,得到n
‑
m+1个计算结果,作为输出数据的n
‑
m+1个元素。对于二维卷积操作:对于m行m列的卷积核矩阵和nr行nc列的输入矩阵,输出矩阵为nr
‑
m+1行nc
‑
m+1列的矩阵,nr、nc为自然数且m≤nr,m≤nc;使卷积核矩阵的m行元素的每一行分别与输入矩阵的第i到i+m行元素中的对应一行进行m次一维卷积操作,得到m个数据行,每个数据行有nc
‑
m+1个元素,将m个数据行上的对应元素累加,得到输出矩阵的第i行的nc
‑
m+1个元素,其中i=1, 2, ..., nr
‑
m+1。
52.在一种优选实现方式中,对于二维卷积操作,将计算单元组成计算单元阵列。
53.在一种优选实现方式中,对于二维卷积操作,所述计算单元阵列为m行(nr
‑
m+1)列的计算单元阵列,其中第i列计算单元用于得到输出矩阵的第i行的运算。
54.在一种优选实现方式中,对于二维卷积操作,按时钟周期,卷积核矩阵的行在计算单元阵列上的一个方向上复用,输入矩阵的行沿计算单元阵列的对角线传播,计算单元阵列中各个计算单元的计算结果沿计算单元阵列上的另一个方向传播累加。
55.在一种优选实现方式中,对于二维卷积操作,卷积核矩阵的m行分别对应于计算单元阵列的m行,按时钟周期横向复用,与输入矩阵的相应行进行一维卷积操作;输入矩阵从第i行起至第i+m
‑
1行,按时钟周期,依次进入计算单元阵列的第i列中的m个计算单元;计算单元阵列的第i列中的m个计算单元将每个时钟周期的计算结果按时钟周期依次纵向传播到相邻的下一计算单元,从而在同一列的纵向上最后一个计算单元按时钟周期依次输出得到输出矩阵第i行的nc
‑
m+1个元素。
56.在一种优选实现方式中,nr = nc。在此情况下,可以用n来代替nr和nc。
57.在一种优选实现方式中,在人工神经网络中,卷积核数据为网络权重数据,输入数据为输入特征图数据,输出数据为输出特征图数据。
58.在一种优选实现方式中,在人工神经网络中,卷积核矩阵为网络权重矩阵,输入矩阵为输入特征图矩阵,输出矩阵为输出特征图矩阵。
59.在一种优选实现方式中,对于超过二维的卷积,固定部分维度,一次只改变一个维度,由此合成多维卷积运算结果。
60.在一种优选实现方式中,不同的输入矩阵复用相同的卷积核矩阵,分别得到针对不同的输入矩阵的输出矩阵片段,按输入矩阵顺序衔接成最终的输出矩阵。
61.在一种优选实现方式中,不同的卷积核矩阵复用相同的输入矩阵,分别得到针对不同的卷积核矩阵的输出矩阵片段,按卷积核矩阵的组合方式拼凑成最终的输出矩阵。
62.在一种优选实现方式中,对于来自不同通道的输入矩阵和卷积核矩阵,分别得到针对不同通道的输出矩阵片段,将不同通道的输出矩阵片段累加得到最终的输出矩阵。
63.根据本发明的实施例,本发明的第二方面提供一种计算系统,其包括寄存器。寄存器被配置为多个计算单元,每个计算单元被配置为同时完成一个或多个乘法运算并将乘法运算的结果相加得到每个计算单元的计算结果。所述计算单元被配置为在计算系统中实现卷积运算:对于一维卷积操作:将卷积核数据的m个元素固定于计算单元中,使输入数据的n个元素按时钟周期依次滑动进入计算单元,其中,m、n为自然数且m≤n;在每个时钟周期,使卷积核数据的m个元素分别一一对应于输入数据的n个元素中的m个数据,使卷积核数据的m个元素与滑动到计算单元中对应位置上的输入数据的对应的m个元素分别进行乘法运算并将乘积相加,存为当前时钟周期的计算结果;依次输出每个时钟周期的计算结果,得到n
‑
m+1个计算结果,作为输出数据的n
‑
m+1个元素。对于二维卷积操作:对于m行m列的卷积核矩阵和nr行nc列的输入矩阵,输出矩阵为nr
‑
m+1行nc
‑
m+1列的矩阵,nr、nc为自然数且m≤nr,m≤nc;使卷积核矩阵的m行元素的每一行分别与输入矩阵的第i到i+m行元素中的对应一行进行m次一维卷积操作,得到m个数据行,每个数据行有nc
‑
m+1个元素,将m个数据行上的对应元素累加,得到输出矩阵的第i行的nc
‑
m+1个元素,其中i=1, 2, ..., nr
‑
m+1。
64.在一种优选实现方式中,所述计算单元被配置为,对于二维卷积操作,将计算单元组成计算单元阵列。
65.在一种优选实现方式中,所述计算单元被配置为,对于二维卷积操作,所述计算单元阵列为m行(nr
‑
m+1)列的计算单元阵列,其中第i列计算单元用于得到输出矩阵的第i行的运算。
66.在一种优选实现方式中,所述计算单元被配置为,对于二维卷积操作,按时钟周期,卷积核矩阵的行在计算单元阵列上的一个方向上复用,输入矩阵的行沿计算单元阵列的对角线传播,计算单元阵列中各个计算单元的计算结果沿计算单元阵列上的另一个方向传播累加。
67.在一种优选实现方式中,所述计算单元被配置为,对于二维卷积操作,卷积核矩阵的m行分别对应于计算单元阵列的m行,按时钟周期横向复用,与输入矩阵的相应行进行一维卷积操作;输入矩阵从第i行起至第i+m
‑
1行,按时钟周期,依次进入计算单元阵列的第i列中的m个计算单元;计算单元阵列的第i列中的m个计算单元将每个时钟周期的计算结果
按时钟周期依次纵向传播到相邻的下一计算单元,从而在同一列的纵向上最后一个计算单元按时钟周期依次输出得到输出矩阵第i行的nc
‑
m+1个元素。
68.在一种优选实现方式中,nr = nc。在此情况下,可以用n来代替nr和nc。
69.在一种优选实现方式中,在人工神经网络中,卷积核数据为网络权重数据,输入数据为输入特征图数据,输出数据为输出特征图数据。
70.在一种优选实现方式中,在人工神经网络中,卷积核矩阵为网络权重矩阵,输入矩阵为输入特征图矩阵,输出矩阵为输出特征图矩阵。
71.在一种优选实现方式中,对于超过二维的卷积,固定部分维度,一次只改变一个维度,由此合成多维卷积运算结果。
72.在一种优选实现方式中,不同的输入矩阵复用相同的卷积核矩阵,分别得到针对不同的输入矩阵的输出矩阵片段,按输入矩阵顺序衔接成最终的输出矩阵。
73.在一种优选实现方式中,不同的卷积核矩阵复用相同的输入矩阵,分别得到针对不同的卷积核矩阵的输出矩阵片段,按卷积核矩阵的组合方式拼凑成最终的输出矩阵。
74.在一种优选实现方式中,对于来自不同通道的输入矩阵和卷积核矩阵,分别得到针对不同通道的输出矩阵片段,将不同通道的输出矩阵片段累加得到最终的输出矩阵。
75.根据本发明的实施例,本发明的第三方面提供一种用于在计算系统中实现卷积运算的装置。所述装置包括处理器和存储器。所述存储器中存储有计算机程序,当所述计算机程序由所述处理器执行时,使得所述处理器实现根据本发明的第一方面所提供的方法。
附图说明
76.本发明包括说明书附图,其应为视为包含在说明书中并且构成说明书的一部分,且与说明书一起示出了本发明的各种示例性实施例、特征和方面,并且用于解释本发明的原理。
77.图1示出了较为简单的神经网络计算过程。
78.图2示出了神经网络每层的计算。
79.图3示出了一个典型的cnn模型。
80.图4示出了单通道二维卷积操作示例。
81.图5示出了二维卷积对应相乘操作。
82.图6示出了二维卷积滑窗操作。
83.图7示出了多通道卷积操作示例。
84.图8示出了多维卷积操作示例。
85.图9示出了alexnet中的卷积操作示例。
86.图10示出了主流的gpgpu中的矩阵乘操作。
87.图11示出了卷积操作转为矩阵乘操作的方式。
88.图12示出了卷积操作转为矩阵乘操作的示例。
89.图13示出了二维脉动阵列架构。
90.图14示出了二维脉动阵列中运算单元(cell)的结构。
91.图15示出了传统计算结构和脉动阵列结构的对比。
92.图16示出了y = x * w矩阵乘的tpu脉动阵列实现方式。
93.图17示出了脉动阵列进行示例矩阵乘的cycle0和cycle1的情况。
94.图18示出了脉动阵列进行示例矩阵乘的cycle2和cycle3的情况。
95.图19示出了脉动阵列进行示例矩阵乘的cycle4和cycle5的情况。
96.图20示出了脉动阵列进行示例矩阵乘的cycle6和cycle7的情况。
97.图21示出了脉动阵列进行示例矩阵乘的cycle8和cycle9的情况。
98.图22示出了脉动阵列进行示例矩阵乘的cycle10和cycle11的情况。
99.图23示出了脉动阵列进行示例矩阵乘的cycle12和cycle13的情况。
100.图24示出了脉动阵列进行卷积运算的示例。
101.图25示出了作为另一种脉动阵列的shidiannao脉动阵列的架构。
102.图26示出了y = x * w矩阵乘的shidiannao脉动阵列实现方式。
103.图27示出了shidiannao脉动阵列进行示例矩阵乘的cycle0和cycle1的情况。
104.图28示出了shidiannao脉动阵列进行示例矩阵乘的cycle2和cycle3的情况。
105.图29示出了shidiannao脉动阵列进行示例矩阵乘的cycle12和cycle13的情况。
106.图30示出了tpu脉动阵列与shidiannao脉动阵列的能效对比图。
107.图31示出了混合脉动阵列架构的一维卷积操作。
108.图32示出了混合脉动阵列架构一维卷积操作的步骤一。
109.图33示出了混合脉动阵列架构一维卷积操作的步骤二。
110.图34示出了混合脉动阵列架构一维卷积操作的步骤三。
111.图35示出了混合脉动阵列架构二维卷积操作。
112.图36示出了针对5x5的卷积核,pe的内部操作。
113.图37示出了针对5x5的卷积核,混合脉动阵列实现一行卷积操作。
114.图38示出了pe阵列进行多行卷积操作。
115.图39示出了pe阵列卷积操作的示例。
116.图40示出了pe阵列针对alexnet conv2/conv3直接进行卷积操作。
117.图41示出了pe阵列针对alexnet conv1直接进行卷积操作。
118.图42示出了多维卷积的一种处理示例。
119.图43示出了多维卷积的另一种处理示例。
120.图44示出了多维卷积的又一种处理示例。
121.图45示出了tpu脉动阵列、shidiannao脉动阵列以及混合脉动阵列的能效对比图。
具体实施方式
122.下面通过实施例,并结合附图,对本发明的技术方案作进一步详细的说明,但本发明不限于下面的实施例。
123.以下将参考附图详细说明本发明的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
124.在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其他实施例。
125.另外,为了更好的说明本发明,在下文的具体实施方式中给出了众多的具体细节。
本领域技术人员应当理解,没有某些具体细节,本发明同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本发明的主旨。
126.以下将根据本发明的实施例,引入一种在计算系统中实现卷积运算的方法。该方法不用将卷积运算转化为矩阵乘运算,而是直接利用脉动阵列进行卷积运算。
127.本发明的方法的主要目的在于,提出了一种新型脉动阵列的计算方式,结合了gpgpu的时域累加特性和脉动阵列的空域累加特性,直接实现卷积操作,实现一种高效的运算数据传输,从而达到能效的最低,所以这里把这种新型脉动阵列称为“混合脉动阵列”(hybrid
‑
systolic)。
128.在本发明中,计算系统中的寄存器被配置为以混合脉动阵列的卷积方式进行数据存取与运算。
129.本领域技术人员应该理解,这里所说的卷积(convolution)或卷积运算,实际上与相关(correlation)运算或滑窗滤波(filtering)运算具有相同或相似的含义。在人工神经网络领域,本领域技术人员习惯于将这样的操作称为卷积运算,其具体操作方式可以参看下文更详细的示例。
130.本领域技术人员应该理解,如前所述,在脉动阵列或本发明所提出的混合脉动阵列的架构中,第一个alu取数,经过处理后被传递到下一个alu,同时第二个数据进入第一个alu,依次类推。在第一个数据到最后一个alu之后,每个周期都能得到一个结果。这种情况下,每个计算单元既包含运算单元alu,也包含寄存器,以便按照时钟周期的顺序暂存数据,部分求和,从而在某个时钟周期输出卷积运算的部分或全部结果。因此,可以把脉动阵列或混合脉动阵列中的每个计算单元(pe)看作带有寄存器的运算单元,或包含运算单元的寄存器。
131.根据本发明的实施例,计算系统中的寄存器被配置为多个pe,每个pe被配置为同时完成多个乘法运算并将乘法运算的结果相加得到每个计算单元的计算结果。
132.每个pe被配置为同时完成一个或多个乘法运算并将乘法运算的结果相加得到每个计算单元的计算结果。
133.下面来介绍本发明所引入的全新的混合脉动阵列。
134.在人工神经网络的实施例中,为了示例混合脉动阵列的架构,在一维操作中,将网络权重数据表示为卷积核数据,输入特征图数据表示为输入数据,输出特征图数据则表示为输出数据。相应地,在二维操作中,卷积核矩阵为网络权重矩阵,输入矩阵为输入特征图矩阵,输出矩阵为输出特征图矩阵。
135.图31示出了混合脉动阵列的一维卷积操作。
136.一维卷积操作实现方式如下。它会最大程度复用卷积运算,把一行权重(weight)放在寄存器中,滑动输入数据(activation),并保持“部分和”(psum)在寄存器(计算单元)中,如图31所示。
137.下面通过图32
‑
34来分步骤描述一维卷积操作。
138.步骤一:weight值包括w00, w01, w02,移入pe之中。activation数据包括x00, x01, x02,也移入pe。一个时钟周期(cycle)完成乘加操作,如图32所示得到y00。
139.步骤二:weight值仍为w00, w01, w02,移入pe之中。activation数据滑动一格,包括x01, x02, x03,也移入pe。一个时钟周期(cycle)完成乘加操作,如图33所示得到y01。
140.步骤三:weight值仍为w00, w01, w02,移入pe之中。activation数据滑动一格,包括x02, x03, x04,也移入pe。一个时钟周期(cycle)完成乘加操作,如图34所示得到y02。
141.由此,图31
‑
34示例了如何通过本发明所引入的混合脉动阵列实现卷积核w(w00, w01, w02,可看作一个向量)与输入数据x(x00, x01, x02, x03, x04,可看作另一个向量)之间的一维卷积运算,得到输出数据y(y00, y01, y02,输出向量)。
142.更一般地,一维卷积操作可以被描述为遵循如下规则:1.将卷积核数据的m个元素固定于计算单元中,使输入数据的n个元素按时钟周期依次滑动进入计算单元,其中,m、n为自然数且m≤n。在图31
‑
34的示例中,m=3,n=5。
143.2.在每个时钟周期,使卷积核数据的m个元素分别一一对应于输入数据的n个元素中的m个数据。例如,第一时钟周期,w00, w01, w02与x00, x01, x02一一对应;第二时钟周期,w00, w01, w02与x01, x02, x03一一对应;第三时钟周期,w00, w01, w02与x02, x03, x04一一对应。
144.3.使卷积核数据的m个元素与滑动到计算单元中对应位置上的输入数据的对应的m个元素分别进行乘法运算并将乘积相加,存为当前时钟周期的计算结果。如上示例中,w与x相应元素分别进行乘法运算并将乘积相加,分别得到y00, y01, y02。
145.4.依次输出每个时钟周期的计算结果,得到n
‑
m+1个计算结果,作为输出数据的n
‑
m+1个元素。例如,在图31
‑
33的示例中,n
‑
m+1 = 5
‑
3+1 = 3,即,输出数据为y00, y01, y02三个元素。
146.图35示出了混合脉动阵列的二维卷积操作。
147.二维卷积操作实现方式是,weight行在pe阵列上横向复用,activation行在pe阵列上沿对角线传播,psum沿纵向传播并累加。如图35所示,实现的二维卷积操作是,卷积核矩阵weight是3x3的矩阵,输入矩阵activation是5x5的矩阵,输出矩阵即部分和psum是3x3的矩阵。尽管这里示例的输入矩阵的行数与列数相同,但本领域技术人员应该理解,输入矩阵的行数与列数可以不相同。
148.对二维卷积操作进行分解。实际上是针对不同的行,不断重复一维卷积操作,然后进行了求和。在图35的例子中,pe1会执行weight的第一行(卷积运算符“*”左侧的row 1)和activation的第一行(卷积运算符“*”右侧的row 1)的一维卷积操作,pe2会执行weight的第二行(卷积运算符“*”左侧的row 2)和activation的第二行(卷积运算符“*”右侧的row 2)的一维卷积操作,pe3会执行weight的第三行(卷积运算符“*”左侧的row 3)和activation的第三行(卷积运算符“*”右侧的row 3)的一维卷积操作。再将卷积操作的计算结果进行累加,得到部分和的第一行(箭头表示部分和的传播方向,即累加到上方的row 1)。注意到,这里相当于卷积核矩阵weight在输入矩阵activation的第1
‑
3行上滑动。
149.类似地,pe4会执行weight的第一行(卷积运算符“*”左侧的row 1)和activation的第二行(卷积运算符“*”右侧的row 2)的一维卷积操作,pe5会执行weight的第二行(卷积运算符“*”左侧的row 2)和activation的第三行(卷积运算符“*”右侧的row 3)的一维卷积操作,pe6会执行weight的第三行(卷积运算符“*”左侧的row 3)和activation的第四行(卷积运算符“*”右侧的row 4)的一维卷积操作。再将卷积操作的计算结果进行累加,得到部分和的第二行(箭头表示部分和的传播方向,即累加到上方的row 2)。注意到,这里相当于卷积核矩阵weight在输入矩阵activation的第2
‑
4行上滑动。
150.类似地,pe7会执行weight的第一行(卷积运算符“*”左侧的row 1)和activation的第三行(卷积运算符“*”右侧的row 3)的一维卷积操作,pe8会执行weight的第二行(卷积运算符“*”左侧的row 2)和activation的第四行(卷积运算符“*”右侧的row 4)的一维卷积操作,pe9会执行weight的第三行(卷积运算符“*”左侧的row 3)和activation的第五行(卷积运算符“*”右侧的row 5)的一维卷积操作。再将卷积操作的计算结果进行累加,得到部分和的第三行(箭头表示部分和的传播方向,即累加到上方的row 3)。注意到,这里相当于卷积核矩阵weight在输入矩阵activation的第3
‑
5行上滑动。
151.每个pe都会包括一个或多个乘法运算和相应的加法运算操作,即一个时钟周期内完成一个或多个(例如8个)乘法和一个或多个加法操作,针对5x5的卷积核,则需要其中的5个乘法和5个加法操作,如图36所示,即x00*w00 + x01 *w01 + x02*w02 + x03*w03 + x04*w04。
152.更一般地,上述的二维卷积操作可以被描述为遵循如下规则:1.对于m行m列的卷积核矩阵和nr行nc列的输入矩阵,输出矩阵为nr
‑
m+1行nc
‑
m+1列的矩阵。例如,图35的例子中,m=3,nr = nc = n = 5,nr
‑
m+1 = nc
‑
m+1 = n
‑
m+1 = 5
‑
3+1 = 3。即,在nr = nc的情况下,可以用n一个变量来代替nr和nc。
153.2.使卷积核矩阵的m行元素的每一行分别与输入矩阵的第i到i+m行元素中的对应一行进行m次一维卷积操作,得到的m个数据行,每个数据行有nc
‑
m+1个元素。也就是说,卷积核矩阵在输入矩阵的第i到i+m行上滑动。例如,卷积核矩阵weight在输入矩阵activation的第1
‑
3行上滑动(pe1、pe2、pe3),卷积核矩阵weight在输入矩阵activation的第2
‑
4行上滑动(pe4、pe5、pe6),卷积核矩阵weight在输入矩阵activation的第3
‑
5行上滑动(pe7、pe8、pe9)。
154.3.将m个数据行上的对应元素累加,得到输出矩阵的第i行的nc
‑
m+1个元素,其中i=1, 2, ..., nr
‑
m+1。例如,卷积核矩阵weight在输入矩阵activation的第1
‑
3行上滑动(pe1、pe2、pe3)得到psum的第一行,卷积核矩阵weight在输入矩阵activation的第2
‑
4行上滑动(pe4、pe5、pe6)得到psum的第二行,卷积核矩阵weight在输入矩阵activation的第3
‑
5行上滑动(pe7、pe8、pe9)得到psum的第三行。
155.图37示出了针对5x5的卷积核,混合脉动阵列实现一行卷积操作。在图37的上侧,列出了矩阵卷积式。weight表示卷积核矩阵,其每行数据分别标为1
‑
5,且在图37下侧的每个pe中被复用。ifmap或ifmap表示输入特征图矩阵,其每行数据也分别标为1, 2, 3, 4, 5,
ꢀ…
(图37的例子中输入矩阵一行有31个元素)。图24的卷积式的等号右侧是输出特征图矩阵的一行(例如,第一行)。图37的下侧,每个pe中表示了三组数据,从上至下分别为weight、ifmap和psum(或ofmap或ofmap,即输出特征图)。
156.针对5x5卷积核的卷积操作,如图37所示,pe5中在第一时钟周期(cycle1)通过pe内的多个乘加操作得到输出特征图ofmap的元素1(pe5在cycle1进行weight第5行与图中ifmap第5行的前5个元素的相乘,乘积相加后得到ofmap元素1在pe5的部分和),纵向传播(pe间的传播如左侧箭头所示,计算结果的传播如虚线箭头所示)到pe4进行累加(pe4在cycle2进行weight第4行与图中ifmap第4行的前5个元素的相乘,乘积相加后,再与从pe5传播来的部分和累加,得到ofmap元素1在pe4的部分和),这里完成空域的累加,最终在第五时钟周期(cycle5)在pe1中累加得到ofmap的元素1(等式右侧的“1”)。按照顺序,分别在第六
时钟周期(cycle6)在pe1中累加得到ofmap的元素2,在第七时钟周期(cycle7)在pe7中累加得到ofmap的元素3。以此类推,最终得到ofmap的第一行的完整数据结果。
157.pe阵列如图38所示,阵列的每一列都可得到psum的每一行:例如,ifmap为31x31的矩阵,weight为5x5的矩阵,步长为1,卷积结果为27x27,则需要5*27大小的pe阵列来完成卷积操作。pe第一列用来产生ofmap的第一行27个数据,pe第二列用来产生ofmap的第二行27个数据,依次类推,如图39所示。
158.此阵列可根据卷积操作的大小,进行硬件可重构,配置成最优的执行架构,例如针对alexnet的conv2层时,会选取5x27大小的pe阵列进行卷积操作,如图40中的上层框,针对alexnet的conv3层时,会选取3x13大小的pe阵列进行卷积操作,如图40中的下层框。其余的pe阵列可以用于其他卷积操作,如无操作则会被时钟屏蔽掉(clock
‑
gated)。
159.当如果需要做比较大的卷积操作时,例如alexnet的conv1层时,则需要拼接2个16x32的pe阵列,以满足11x55的大小,如图41所示。
160.更一般地,对于二维卷积操作:将计算单元组成计算单元阵列,如图37
‑
41所示。其中,所述计算单元阵列可以为m行(nr
‑
m+1)列的计算单元阵列,其中第i列计算单元用于得到输出矩阵的第i行的运算,如图39所示。
161.按时钟周期,卷积核矩阵的行在计算单元阵列上的一个方向(例如横向)上复用,输入矩阵的行沿计算单元阵列的对角线传播(所谓对角线传播,实际上是加入了时间的维度,即一方面,每行计算单元对应不同的输入矩阵行,另一方面,输入矩阵的同一行也按时钟时期依次滑动从而与weight的相应行元素进行乘加,而且各个pe批次慢一拍,详见下文),计算单元阵列中各个计算单元的计算结果沿计算单元阵列上的另一个方向(例如纵向)传播累加,如图37、37所示。
162.二维卷积操作可以被描述为如下规则:1.卷积核矩阵的m行分别对应于计算单元阵列的m行,按时钟周期横向复用,对输入矩阵的相应行进行一维卷积操作。
163.参见图37,m=5,卷积核weight的第1
‑
5行分别在pe1到pe5中复用。以pe5为例,从第一时钟周期开始,始终是weight的第5行进行乘法运算。如图37所示,在计算输出矩阵第1行的情况下,weight的第5行与输入矩阵的第5行进行一维卷积操作。同样地,在pe1到pe4中,分别是weight的第1行到第4行与输入矩阵的第1行到第4行进行一维卷积操作。但是,从图37中可以看出,pe4的计算是从第二时钟周期开始的,以此类推,各个pe分别慢一拍。也就是说,输入矩阵的行沿计算单元阵列的对角线传播。
164.2.输入矩阵从第i行起至第i+m
‑
1行,按时钟周期,依次进入计算单元阵列的第i列中的m个计算单元。
165.3.计算单元阵列的第i列中的m个计算单元将每个时钟周期的计算结果按时钟周期依次纵向传播到相邻的下一计算单元,从而在同一列的纵向上最后一个计算单元按时钟周期依次输出得到输出矩阵第i行的nc
‑
m+1个元素。
166.如前所述,在图37的例子中,pe5在第一周期进行weight第5行与图中ifmap第5行的前5个元素(1、2、3、4、5)的相乘,乘积相加后得到ofmap元素1在pe5的部分和,纵向传播到pe4。pe4在第二周期进行weight第4行与图中ifmap第4行的前5个元素的相乘,乘积相加后,再与从pe5传播来的部分和累加,得到ofmap元素1在pe4的部分和,这里完成空域的累加。由
此,再经过pe3、pe2。最终在第五时钟周期(cycle5)在pe1中进行weight第1行与图中ifmap第1行的前5个元素的相乘,乘积相加后,再与从pe2传播来的部分和累加,最终累加得到ofmap的元素1。即到第五时钟周期,完成输出矩阵行中第一个元素的累加结果。
167.另一方面,为了得到ofmap的元素2,pe5在第二周期进行weight第5行与图中ifmap第5行滑动1位后的5个元素(第5行第2、3、4、5、6列)的相乘,乘积相加后得到ofmap元素2在pe5的部分和,纵向传播到pe4。pe4在第三周期进行weight第4行与图中ifmap第4行的相应5个元素(第4行第2、3、4、5、6列)的相乘,乘积相加后,再与从pe5传播来的部分和累加,得到ofmap元素2在pe4的部分和,这里完成空域的累加。由此,再经过pe3、pe2。最终在第六时钟周期(cycle6)在pe1中进行weight第1行与图中ifmap第1行的相应5个元素(第1行第2、3、4、5、6列)的相乘,乘积相加后,再与从pe2传播来的部分和累加,最终累加得到ofmap的元素2。即到第六时钟周期,完成输出矩阵行中第二个元素的累加结果。
168.以此类推,后续每个时钟周期均完成输出矩阵行中的一个元素的累加结果;最终得到一行中所有元素的值。
169.这里需要注意的是,图37中所示ifmap的五行,并不一定是从输入矩阵的第1
‑
5行,而有可能是任意连续五行,即可以看作是输入矩阵的第i行到第i+4行,由此得到的是输出矩阵的第i行上的元素。
170.对于超过二维的数据来说,基本思路是将其转换成二维运算,即固定部分维度,一次只改变一个维度,由此合成多维卷积运算结果。比如说:不同的ifmap复用相同的filter,即不同的输入矩阵复用相同的卷积核矩阵,分别得到针对不同的输入矩阵的输出矩阵片段,按输入矩阵顺序衔接成最终的输出矩阵,如图42所示。
171.不同的filter复用相同的ifmap,即不同的卷积核矩阵复用相同的输入矩阵,分别得到针对不同的卷积核矩阵的输出矩阵片段,按卷积核矩阵的组合方式拼凑成最终的输出矩阵,如图43所示。
172.filter和ifmap来自不同channel会累加在一起,即对于来自不同通道的输入矩阵和卷积核矩阵,分别得到针对不同通道的输出矩阵片段,将不同通道的输出矩阵片段累加得到最终的输出矩阵,如图44所示。
173.这样即可解决cnn网络中任意大小的卷积运算,实现真正的卷积即卷积操作。
174.因为集合了时域和空域运算的优点,将部分数据存储在pe的寄存器中,减少了数据流动,平衡了卷积运算中各种类型数据移动所产生的功耗,从模型中得到功耗结果显示,本发明提出的混合脉动阵列(图中标为hybrid)可以在shidiannao脉动阵列基础上优化功耗达25%以上,如图45所示。
175.因此,根据本发明的实施例,本发明所教导的技术可以实现为一种计算系统,其包括寄存器。寄存器被配置为多个计算单元,每个计算单元被配置为同时完成一个或多个乘法运算并将乘法运算的结果相加得到每个计算单元的计算结果。所述计算单元被配置为在计算系统中实现卷积运算:对于一维卷积操作:将卷积核数据的m个元素固定于计算单元中,使输入数据的n个元素按时钟周期依次滑动进入计算单元,其中,m、n为自然数且m≤n;在每个时钟周期,使卷积核数据的m个元素分别一一对应于输入数据的n个元素中的m个数据,使卷积核数据的m个元素与滑动到计算单元中对应位置上的输入数据的对应的m个元素
分别进行乘法运算并将乘积相加,存为当前时钟周期的计算结果;依次输出每个时钟周期的计算结果,得到n
‑
m+1个计算结果,作为输出数据的n
‑
m+1个元素。对于二维卷积操作:对于m行m列的卷积核矩阵和nr行nc列的输入矩阵,输出矩阵为nr
‑
m+1行nc
‑
m+1列的矩阵,nr、nc为自然数且m≤nr,m≤nc;使卷积核矩阵的m行元素的每一行分别与输入矩阵的第i到i+m行元素中的对应一行进行m次一维卷积操作,得到m个数据行,每个数据行有nc
‑
m+1个元素,将m个数据行上的对应元素累加,得到输出矩阵的第i行的nc
‑
m+1个元素,其中i=1, 2, ..., nr
‑
m+1。
176.所述计算单元被配置为,对于二维卷积操作,将计算单元组成计算单元阵列。
177.对于二维卷积操作,所述计算单元阵列为m行(nr
‑
m+1)列的计算单元阵列,其中第i列计算单元用于得到输出矩阵的第i行的运算。
178.对于二维卷积操作,按时钟周期,卷积核矩阵的行在计算单元阵列上的一个方向上复用,输入矩阵的行沿计算单元阵列的对角线传播,计算单元阵列中各个计算单元的计算结果沿计算单元阵列上的另一个方向传播累加。
179.对于二维卷积操作,卷积核矩阵的m行分别对应于计算单元阵列的m行,按时钟周期横向复用,与输入矩阵的相应行进行一维卷积操作;输入矩阵从第i行起至第i+m
‑
1行,按时钟周期,依次进入计算单元阵列的第i列中的m个计算单元;计算单元阵列的第i列中的m个计算单元将每个时钟周期的计算结果按时钟周期依次纵向传播到相邻的下一计算单元,从而在同一列的纵向上最后一个计算单元按时钟周期依次输出得到输出矩阵第i行的nc
‑
m+1个元素。
180.如前示例所述,优选地,nr = nc。即在此情况下,可以用n来代替nr和nc。
181.一维操作的卷积核数据为网络权重数据,输入数据为输入特征图数据,输出数据为输出特征图数据。相应地,二维操作的卷积核矩阵为网络权重矩阵,输入矩阵为输入特征图矩阵,输出矩阵为输出特征图矩阵。
182.对于超过二维的卷积,固定部分维度,一次只改变一个维度,由此合成多维卷积运算结果。
183.优选地,不同的输入矩阵复用相同的卷积核矩阵,分别得到针对不同的输入矩阵的输出矩阵片段,按输入矩阵顺序衔接成最终的输出矩阵。不同的卷积核矩阵复用相同的输入矩阵,分别得到针对不同的卷积核矩阵的输出矩阵片段,按卷积核矩阵的组合方式拼凑成最终的输出矩阵。对于来自不同通道的输入矩阵和卷积核矩阵,分别得到针对不同通道的输出矩阵片段,将不同通道的输出矩阵片段累加得到最终的输出矩阵。
184.下面来看几个实例。
185.实例1:在卷积神经网络alexnet中,卷积层conv1可以采用本发明所述的混合脉动阵列进行直接卷积运算。
186.实例2:在卷积神经网络alexnet中,卷积层conv2可以采用本发明所述的混合脉动阵列进行直接卷积运算。
187.实例3:类似地,在卷积神经网络alexnet中,一共有5个卷积层,都可以采用本发明所述的
混合脉动阵列进行直接卷积运算。
188.实例4:在信号处理中,图像滤波中广泛使用卷积(即滤波、滑窗、或所谓的相关或卷积操作)。由此,可以采用混合脉动阵列进行直接卷积运算。
189.基于本发明的方案可以支持:1.针对卷积运算相比于市场上已有的典型架构tpu和shidiannao有着明显的功耗优势;2.可支持多种大小的卷积运算,针对不同大小的卷积运算,硬件可以迅速可重构。
190.本发明所教导的内容适用于各种计算系统、人工智能应用,特别适用于cpu、gpu、fpga、ai芯片等应用。
191.此外,本领域普通技术人员应该认识到,本发明的方法可以实现为计算机程序。如上结合附图所述,通过一个或多个程序执行上述实施例的方法,包括指令来使得计算机或处理器执行结合附图所述的算法。这些程序可以使用各种类型的非瞬时计算机可读介质存储并提供给计算机或处理器。非瞬时计算机可读介质包括各种类型的有形存贮介质。非瞬时计算机可读介质的示例包括磁性记录介质(诸如软盘、磁带和硬盘驱动器)、磁光记录介质(诸如磁光盘)、cd
‑
rom(紧凑盘只读存储器)、cd
‑
r、cd
‑
r/w以及半导体存储器(诸如rom、prom(可编程rom)、eprom(可擦写prom)、闪存rom和ram(随机存取存储器))。进一步,这些程序可以通过使用各种类型的瞬时计算机可读介质而提供给计算机。瞬时计算机可读介质的示例包括电信号、光信号和电磁波。瞬时计算机可读介质可以用于通过诸如电线和光纤的有线通信路径或无线通信路径提供程序给计算机。
192.例如,根据本发明的一个实施例,可以提供一种用于在计算系统中实现卷积运算的装置。所述装置包括处理器和存储器。所述存储器中存储有计算机程序,当所述计算机程序由所述处理器执行时,可实现如前所述的在计算系统中实现卷积运算的方法。
193.因此,根据本发明,还可以提议一种计算机程序或一种计算机可读介质,用于记录可由处理器执行的指令,所述指令在被处理器执行时,可实现如前所述的在计算系统中实现卷积运算的方法。
194.以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的改进,或者使本技术领域的普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1